近年来,大模型(Large Language Model, LLM)技术发展迅猛,从年初DeepSeek的爆火出圈到日常应用中无处不在的AI助手,其热度有增无减。面对诸如MCP、RAG、Agent等层出不穷的新术语,开发者们难免感到困惑。本文将对一系列大模型相关的核心术语与框架进行梳理,帮助你快速构建知识图谱。
LLM (Large Language Model)
大语言模型究竟多大才算“大”?行业虽无绝对硬性标准,但通常以参数规模和训练数据/算力来衡量。当语言模型的参数量达到 ≥1B(10亿) 时,便常被称为“大模型”。
- GPT-2 拥有 1.5B 参数,是早期具有代表性的较大语言模型。
- GPT-3 的参数规模则达到了 175B。
这里的“B”代表Billion(十亿),参数数量是衡量模型规模与能力的关键指标之一。
Prompt (提示词)
Prompt即提示词,是我们输入给大模型以引导其生成回应的指令或问题。精心设计的Prompt能显著提升模型输出的准确性和相关性。
MCP (Model Context Protocol)
模型上下文协议(MCP)是一个开放协议,旨在为LLM应用提供一个标准化接口,使其能够便捷地连接外部数据源和各种工具。
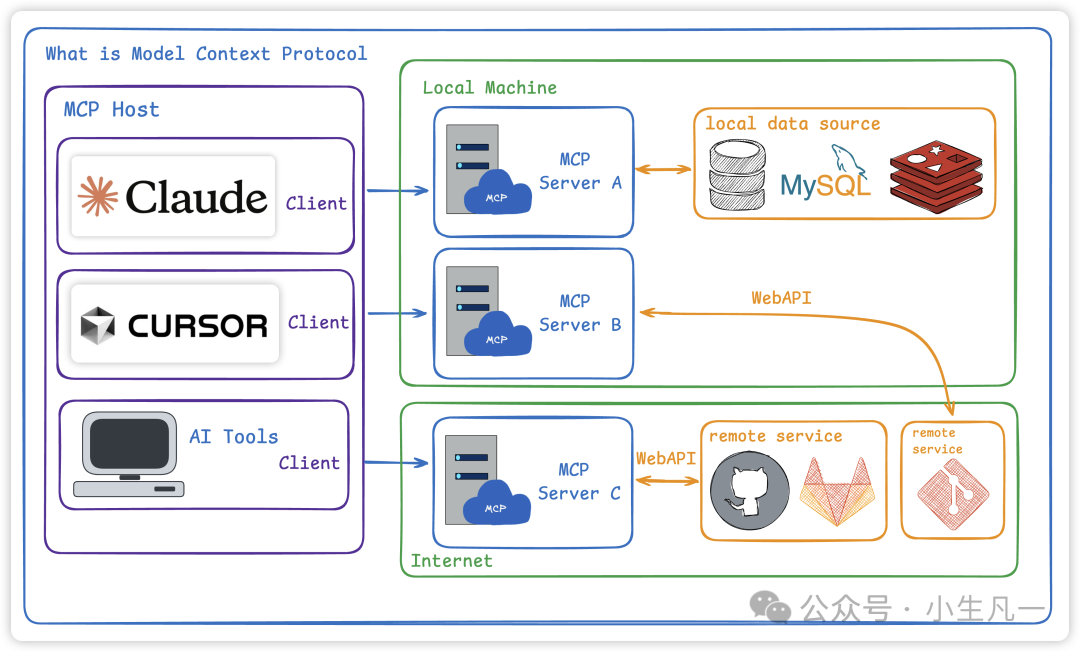
图1:模型上下文协议(MCP)核心架构图,展示了客户端、服务器与外部数据源间的交互。
该协议的核心是建立一个标准化的通信层。当LLM需要访问外部信息或功能时,可通过MCP客户端向MCP服务器发送请求。服务器则负责与相应的外部数据源或工具进行交互,获取数据并按协议格式化后返回给LLM。
关键点在于:大模型本身不会主动调用外部工具,它仅会生成调用建议(如工具名和参数),实际调用动作需由开发者实现。当LLM与MCP结合,便催生了“智能体”的概念。
Agent (智能体)
智能体(Agent)是能够自主理解、规划并执行任务的系统。如上所述,LLM可能仅提供“如何发邮件”的步骤说明,而不会实际执行。将LLM与MCP工具链整合后,才能实现从“知道怎么做”到“真正去做”的跨越。
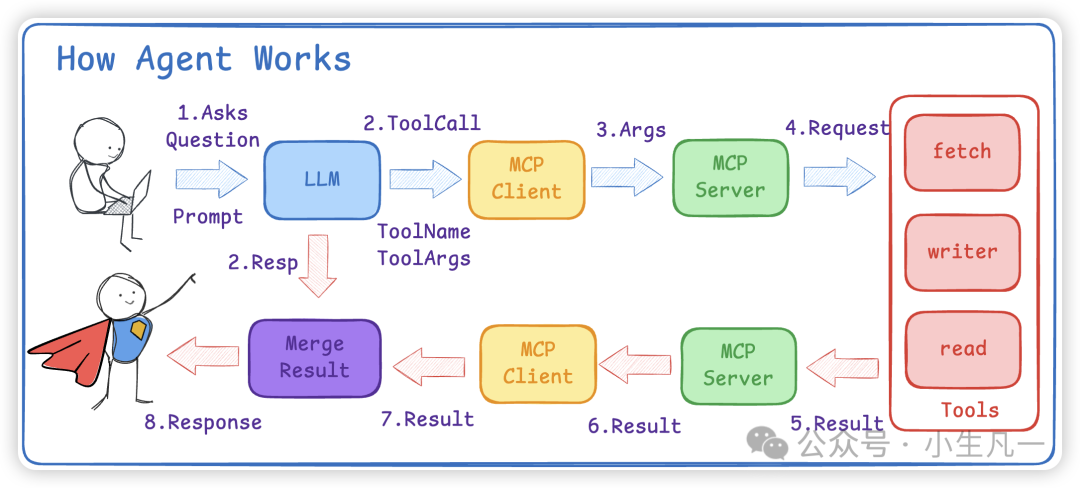
图2:智能体工作流程,展示了从提问、工具调用到结果返回的完整闭环。
其工作流程通常如下:
- 用户输入提示词,例如:“请帮我给xxx发送一封邮件,内容为‘快点更新视频’”,同时将可用的邮件发送工具告知大模型。
- 大模型分析后,返回需要调用的工具名称(ToolName)及参数(Args),例如:
ToolName = 'email_sender',Args = 'email:xxx, content:快更视频'。
- 系统将这些参数传递给对应的MCP服务器。
- MCP服务器执行具体的邮件发送操作。
- 将执行结果返回给用户。
RAG (Retrieval-Augmented Generation)
检索增强生成(RAG)是为了解决大模型“幻觉”(Hallucination)问题而提出的关键技术。模型本质是基于概率预测下一个词,若训练数据未覆盖某些领域,其回答可能看似合理实则错误。
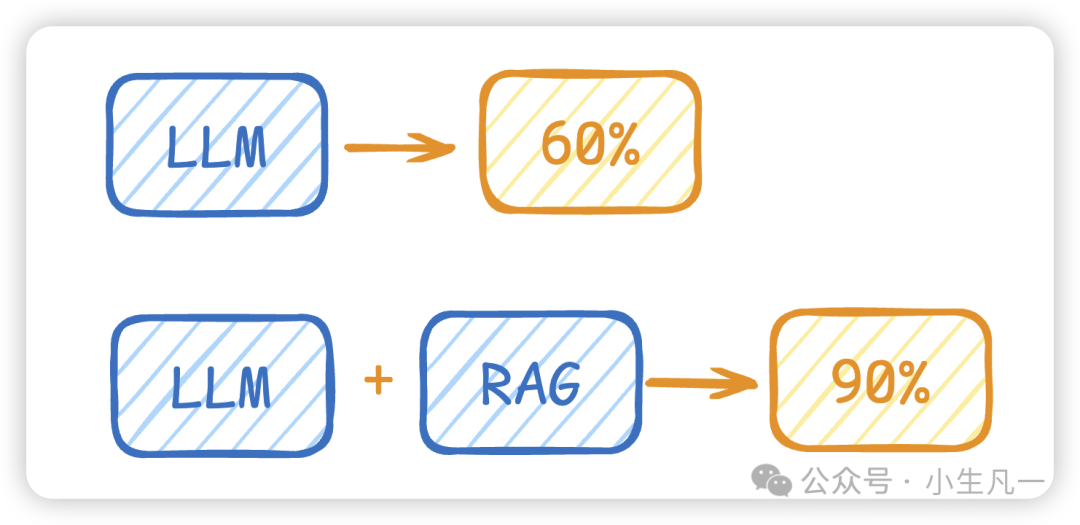
图3:LLM与引入RAG的LLM在回答准确率上的对比示意。
可以这样比喻:LLM如同只复习了部分考纲的考生,面对陌生题目可能瞎蒙。RAG则像开卷考试,允许模型实时检索外部知识库获取“提示”,从而将答案准确率从60%提升至90%。
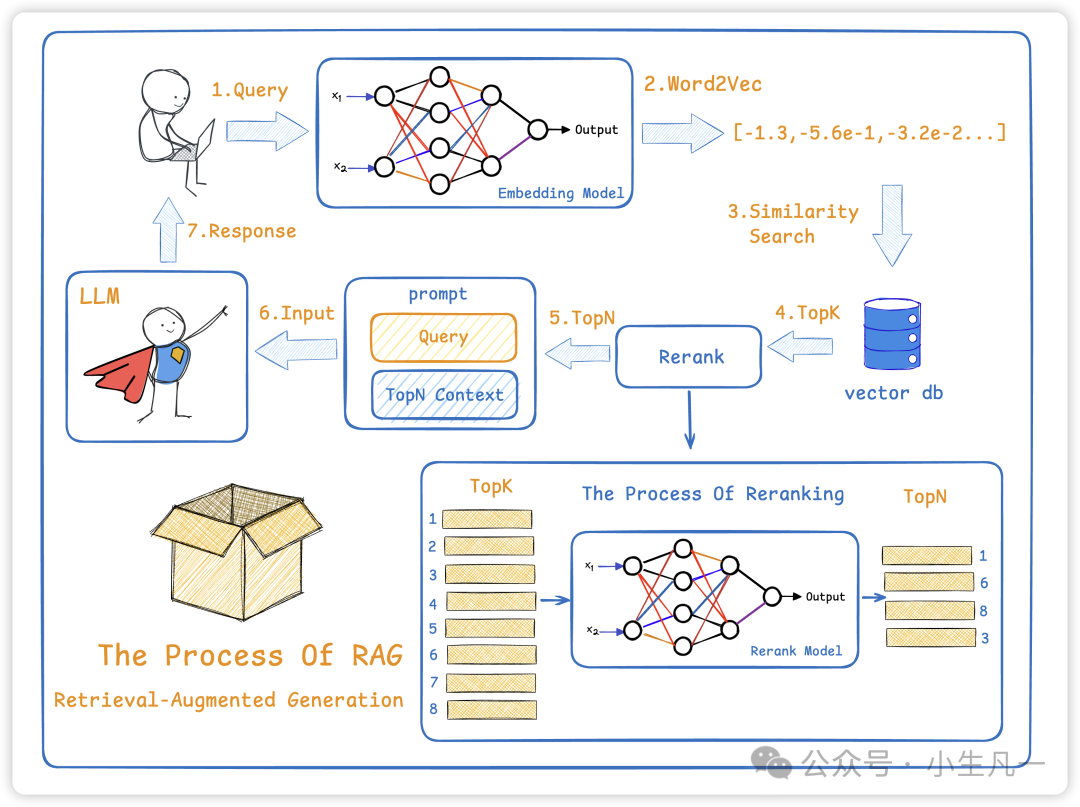
图4:RAG典型流程,包括查询转换、向量检索、结果重排与生成等步骤。
Embedding (向量化)
在大模型中,同一个词在不同语境下含义可能不同(如“苹果”指水果或公司)。如何让模型理解词语关联?将词语转化为一系列浮点数(向量),通过计算向量间的距离来衡量语义相似度。
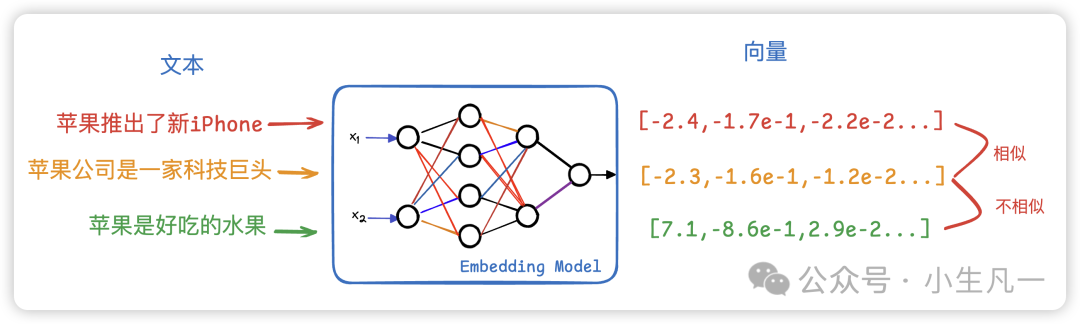
图5:Embedding模型将文本转换为向量空间中的点,语义相近的文本距离更近。
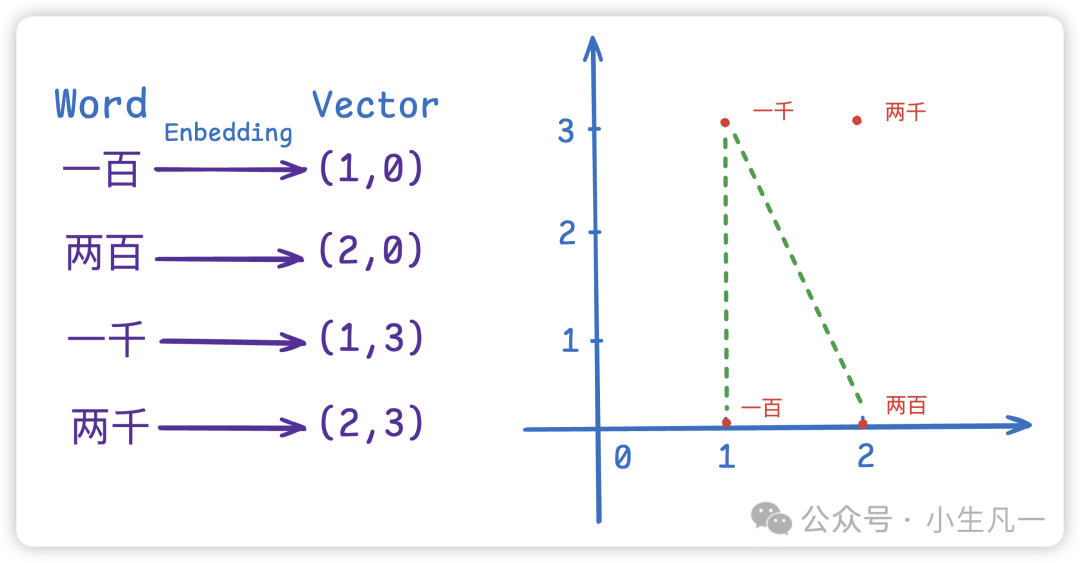
图6:“一百”、“两百”、“一千”、“两千”的词嵌入向量在二维空间的分布,可见数字大小相近的词语义距离更近。
如上图所示,“一百”和“两百”的向量距离远小于“一百”和“一千”,这表明在语义上,“一百”更接近“两百”。
LangChain
LangChain是一个用于快速开发基于LLM应用的框架。它提供了标准化接口,方便开发者将不同的LLM、工具以及数据源链接和集成起来,从而高效构建复杂的智能体(Agent)应用。
vLLM
vLLM是一个开源的高效大语言模型推理和服务框架。其核心目标是通过更优地管理GPU内存,来加速生成式AI应用的推理速度。它主要依赖两大关键技术:PagedAttention (KV Cache管理) 和连续批处理。
KV Cache机制:
在Transformer解码过程中,每个token都会生成用于注意力计算的Key和Value向量。KV Cache通过缓存这些历史K/V向量,避免在生成每个新token时重复计算,从而提升效率。但KV Cache会随着上下文长度增长而占用大量显存。
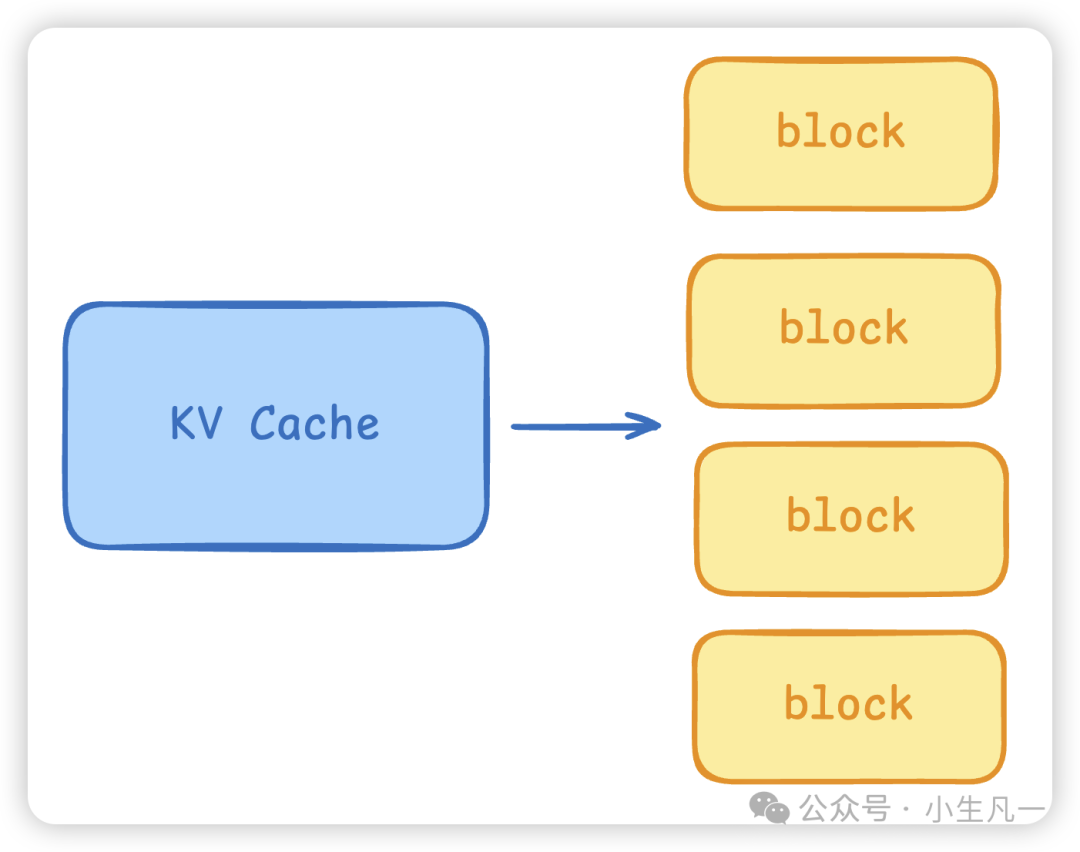
图7:vLLM的PagedAttention将KV Cache分割为固定大小的块(Block)进行管理。
vLLM的解决方案(PagedAttention):
- 分块管理:将KV Cache切分为固定大小的块(Block),采用类似操作系统虚拟内存的页表进行映射管理。这避免了为每个序列分配连续大内存导致的内存碎片和溢出(OOM),同时支持动态请求并发与内存复用。
- 复用共享:在多分支推理(如集束搜索)或请求间存在重复前缀时,可复用已计算的KV块,极大减少预填充时间。
连续批处理:
- 并非等攒够一批请求再处理,而是在每个解码步骤(生成每个token时)动态地将所有活跃请求组装成批,即使序列长度不同也能高效合并,保持GPU高负载。
- 基于PagedAttention的块式内存管理,配合步进级调度器,允许新请求无需等待当前批次完成即可加入下一解码步,减少了短任务被长任务阻塞的情况,提高了吞吐与公平性。
Token (词元)
Token是大模型处理文本的基本单元,可以是一个词、子词或标点。了解Token有助于估算API调用成本和处理长文本。
- 1个英文字符 ≈ 0.3个token。
- 1个中文字符 ≈ 0.6个token。
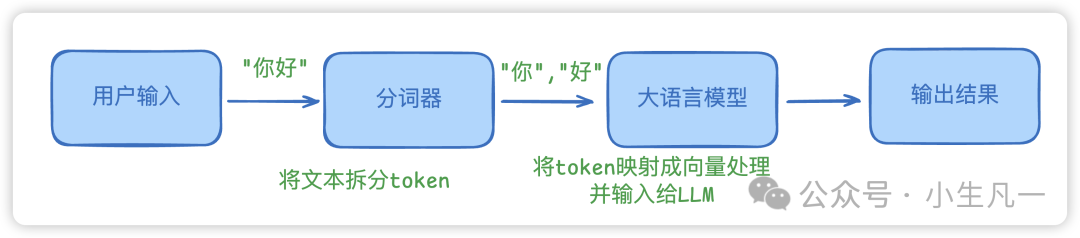
图8:用户输入文本经过分词器拆分为Token,再经由LLM处理并生成输出结果的过程。
数据蒸馏 (Data Distillation)
数据蒸馏是一种模型压缩与知识迁移技术。其核心思想是利用一个高性能的大模型(教师模型)来生成高质量、多样化的训练数据,然后用这些数据去训练一个更小、更高效的模型(学生模型),使学生模型能够逼近甚至达到教师模型的性能,同时降低部署成本与推理延迟。
希望这篇术语解析能帮助你更好地理解人工智能领域这些关键概念。如果你想持续获取此类技术干货,欢迎关注云栈社区的更新。
 发表于 2025-12-30 16:12:20
|
查看: 260|
回复: 0
发表于 2025-12-30 16:12:20
|
查看: 260|
回复: 0
