快到年底了,系统开始频繁出问题。
我有一个非常合理、非常工程师的怀疑:
老板不想发年终奖,所以系统开始搞事。
果不其然——
几年都遇不到一次的 Kafka 消息积压,
在一个本该安静下班的夜晚,
卷土重来了。
今晚,注定是个不眠夜。
原神启动之前,我先启动了 Kafka 面板。
01 事故现场
事情是这样的。
我刚下班,正准备洗洗睡,
组里的小伙伴突然冲过来,语气已经带点颤:
“Kafka 消息积压一直在涨,预览图全出不来!”
我点开监控面板一看,情况不容乐观:
第一反应非常自然,也非常“新手友好”:
是不是消费者慢?那我多加点实例不就完了?
于是我:
越跑越卡
Pod 开始一个接一个挂
这时,我的困意
和不祥的预感
同时达到了顶峰。

图1:事故当晚的真实写照
02 第一层误判
我突然想起一件事:
Spring Cloud Stream 好像支持并发消费?
于是让开发老哥把:
concurrency: 10
一把拉满。
结果呢?
这时候我才反应过来一个致命误解:
concurrency ≠ 并行处理一条消息
而是:
- concurrency = 消费者线程数
- 一个线程 ≈ 一个分区
- 分区本来就不均匀
- 一加线程 流量倾斜直接拉满
- 消息 积压更快
- Pod 直接被打爆
- CPU、内存 一起起飞
我人当场清醒了。
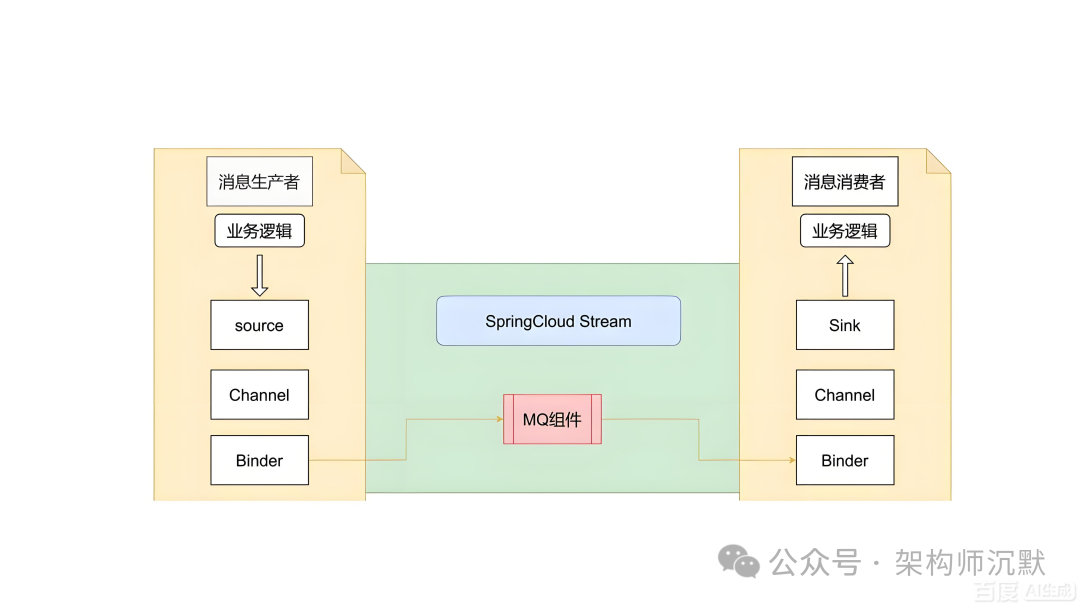
图2:Spring Cloud Stream 消息流架构
03 诡异现象
我把所有 Pod 日志全拉下来,一条一条看。
结果非常魔幻。
监听器日志显示:
全部执行成功
但与此同时:
- Kafka 报 消费超时
- 面板显示 Consumer Group 频繁 Rebalance
我当场愣住。
成功了,又超时?
这是什么?
薛定谔的 Kafka 消费?
但作为一个坚定的唯物主义程序员,
我选择继续往下挖。
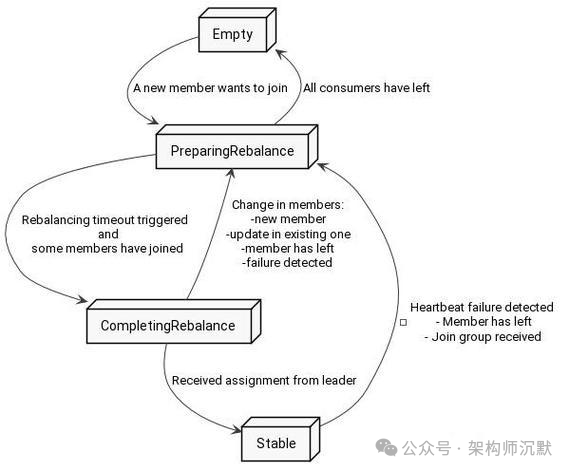
图3:Kafka Consumer Group Rebalance 状态转换过程
04 破案关键
答案,藏在 Kafka 的消费模型 里。
你以为的 Kafka 是这样的:
来一条 → 消费一条 → 确认一条
但实际上,Kafka 是这样的:
一次 poll 一批 → 全部处理完 → 才提交 offset
而 Spring Cloud Stream,为了“好用”,
干了一件非常容易坑人的事:
底层是批量拉取,但监听器只给你一条
我们假设一个真实到不能再真实的配置:
max.poll.records = 500- 单条消息处理:10s
- 处理方式:串行
- 消费超时时间:300s
那会发生什么?
500 × 10s = 5000s
也就是说:
- 一次 poll
- 最多只能处理 30 条
- 后面的消息根本来不及
于是就出现了那一幕:
- 单条逻辑: 成功
- 整批消费: 超时
- Kafka 认为你“失联”
- 触发 Consumer Rebalance
- offset 不提交
- 后面的消息 全部堵死
我当场只想说一句:
我咧个豆,案子破了。
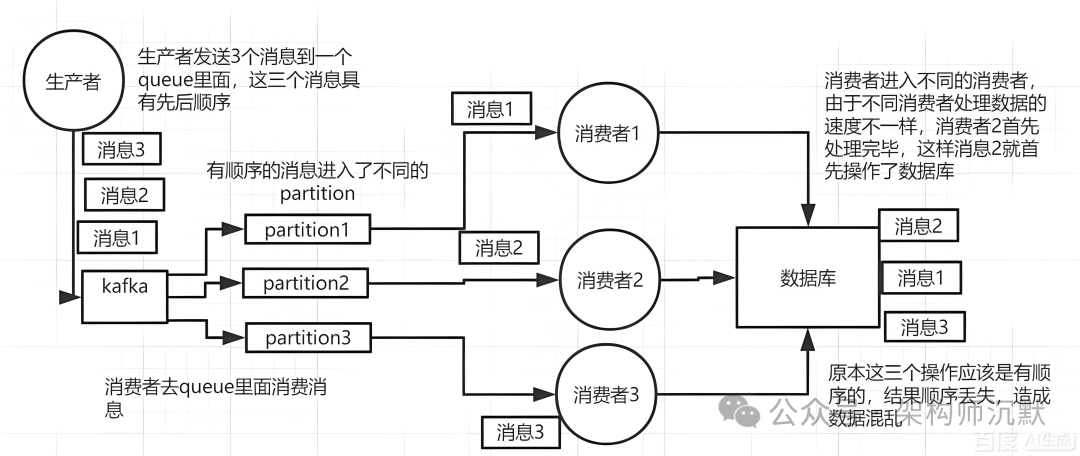
图4:Kafka 生产者发送消息到不同分区,消费者组进行消费
05 两种解决方案
方案一:立刻止血(适合半夜)
ack-mode: RECORD
效果:
- 每条消息处理完立刻提交
- 不再被“批次”拖死
- 改一行就能下班睡觉
代价:
适合场景:
救火
保命
保年终奖
方案二:批量 + 并行(推荐)
思路:
批量要小,并行要真
1. 控制批量大小
max.poll.records: 50
2. 自己并行处理这一批
核心思路是使用 List<byte[]> 接收批量消息,然后利用线程池并发处理。
@StreamListener("<TOPIC>")
public void consume(List<byte[]> payloads) {
List<CompletableFuture<Void>> futures =
payloads.stream().map(bytes -> {
Payload payload =
JacksonSnakeCaseUtils.parseJson(
new String(bytes), Payload.class
);
return CompletableFuture.runAsync(() -> {
// 业务处理
}, batchConsumeExecutor).exceptionally(e -> {
log.error("Thread error {}", bytes, e);
return null;
});
}).collect(Collectors.toList());
// 等待整批完成,再统一提交 offset
CompletableFuture.allOf(
futures.toArray(new CompletableFuture[0])
).join();
}
效果:
- 批次不大,不超时
- 真正并行,吞吐拉满
- offset 提交稳定
- Kafka 安静了,世界也安静了
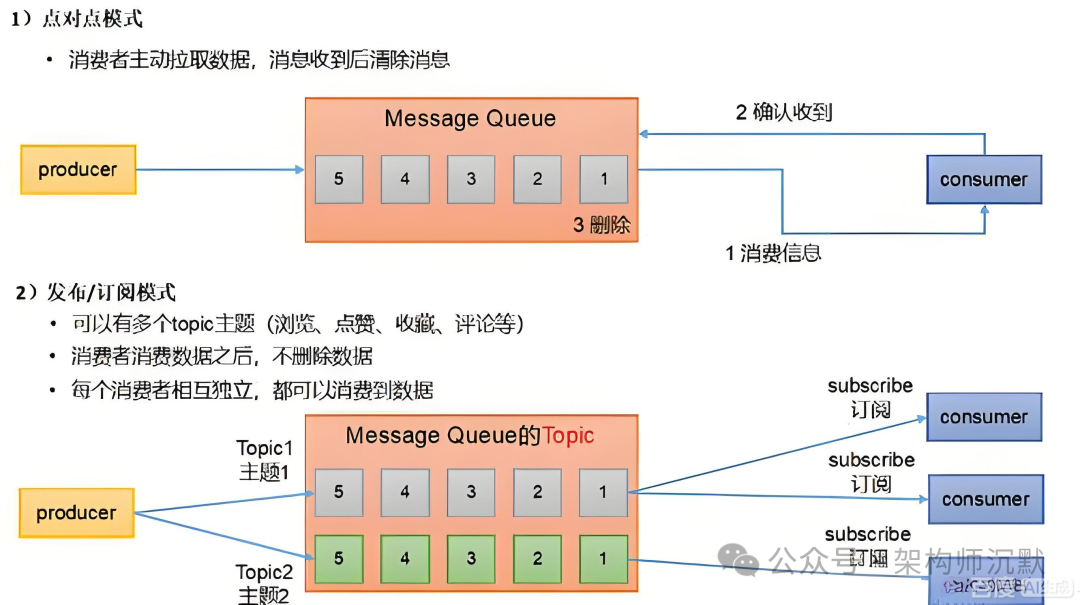
图5:点对点与发布/订阅两种消息队列模式
06 总结
这次事故教会我的三件事
1. Kafka 慢,80% 不是 Kafka 的锅
而是你 消费模型 + 超时配置 + 批量大小
从来没想清楚。
2. Spring Cloud Stream 很友好
但:
越像“队列”的封装,越容易误导你
深入理解 Spring Cloud Stream 等框架的底层机制至关重要,它们虽然简化了开发,但也隐藏了像批量拉取、offset提交时机这样的关键细节。
3. 半夜事故,拼的不是手速
而是你 对底层机制的理解深度
那天问题解决的时候,已经快天亮了。
我终于能安心睡觉了。
如果你也遇到过:
- Kafka 消息积压
- 日志成功但一直超时
- Consumer Rebalance 地狱循环
希望这篇文章,
能帮你 少熬一次夜。

图6:技术人的幽默与无奈
更多关于分布式系统、消息中间件的实战经验和深度讨论,欢迎访问 云栈社区 与开发者们一起交流成长。
 发表于 2025-12-30 17:52:22
|
查看: 298|
回复: 0
发表于 2025-12-30 17:52:22
|
查看: 298|
回复: 0
