在做多入口 Agent 系统时,最容易“看起来没问题”的部分,往往也是最早把系统拖进不确定性的部分。
你上线后会不断遇到这些现象:
- 有时回复顺序对,有时顺序错。
- 有时用户连发三句,你回三次;有时只回一次;有时还会把两次回复拼在一起。
- 有时你以为系统卡住了,结果只是排队;有时你以为只是排队,结果其实是重试风暴。
这些都不是“模型不稳定”的问题。它们更像传统消息系统里那类问题:分区键怎么选、同 key 的有序性怎么保证、队列如何背压、重复投递如何去重、连发如何做微批处理。
今天我们继续来拆 OpenClaw,不展开源码细节,从架构设计角度,把 OpenClaw 在这几个点上的取舍讲清楚。
太长不看版(7 条)
sessionKey 更接近消息系统里的“分区键”:同时承载上下文边界、并发有序性、会话落盘定位。- 直接聊天(DM)默认折叠到主会话是为了连续性;当输入从“单人”变成“多来源”,需要用
session.dmScope 重新划边界。
- 并发治理采用双层队列:同会话串行(
session:<key>),全局 lane 限流(例如 main、subagent)。
- 队列模式是产品行为:
collect/steer/followup/steer-backlog 把“新消息怎么进入当前运行”讲成可解释规则。steer 依赖流式阶段,不满足会回退 followup。
debounceMs/cap/drop 三个旋钮控制微批处理窗口、backlog 上限和溢出策略,先追求可解释,再追求最优。- 入站防抖(
messages.inbound)和队列模式是两层:前者做输入卫生,后者做并发治理。
- 排队状态要可观测:入队触发 typing,日志里有
queue.lane.enqueue/dequeue 和等待时长。
1)把 sessionKey 当分区键,你的系统就开始“可解释”
做过 Kafka 或类似按 key 有序队列系统的人,对“分区键”的重要性不会陌生。OpenClaw 的 sessionKey,在工程语义上更像这个角色:
- 同一 key 内有序:同会话的消息不会并发跑出两个互相踩踏的执行流。
- 跨 key 可并行:不同会话可以并行,提高吞吐,但仍受全局上限约束。
- 状态可定位:会话记录(JSONL)和会话索引能按 key 找到落点。
官方文档里把会话键的映射规则写得很明确:直接聊天按 session.dmScope 分桶;群组/频道有自己的键;其他来源(cron、webhook、node)也有专用 key 前缀。
这类规则的价值是你可以在评审会上用一句话回答:
系统保证的有序性粒度是什么?
2)DM 的默认连续性,在多来源输入下会变成一种“隐形耦合”
OpenClaw 对 DM 的默认策略是把直接聊天折叠到智能体主会话(dmScope: main),这对单人自用非常友好:上下文连续、体验自然。
但当输入从“单人”变成“多来源”(共享收件箱、白名单多人、开放 DM)时,这条默认假设会开始变脆。这时候更合理的做法是用 session.dmScope 重新划边界,例如:
per-channel-peer:按渠道 + 发送者隔离(多用户收件箱常用)。per-account-channel-peer:多账户收件箱进一步隔离。- 需要跨渠道把“同一个人”合并时,再用
session.identityLinks 做显式映射。
架构上我更愿意把这看成“边界前置”的选择:
当这两者冲突时,系统性质优先。
3)双层队列:同 key 有序 + 全局限流
OpenClaw 的队列设计可以用一句传统系统语言概括:
按 key 串行,按 lane 限流。
官方文档对其工作原理的描述很清晰:
- 先按会话键入队(
session:<key>),保证每个会话同时只有一个活动运行。
- 再把会话运行排入全局通道(默认
main),整体并行度受配置限制。
我把它画成一个更“消息系统味”的图:
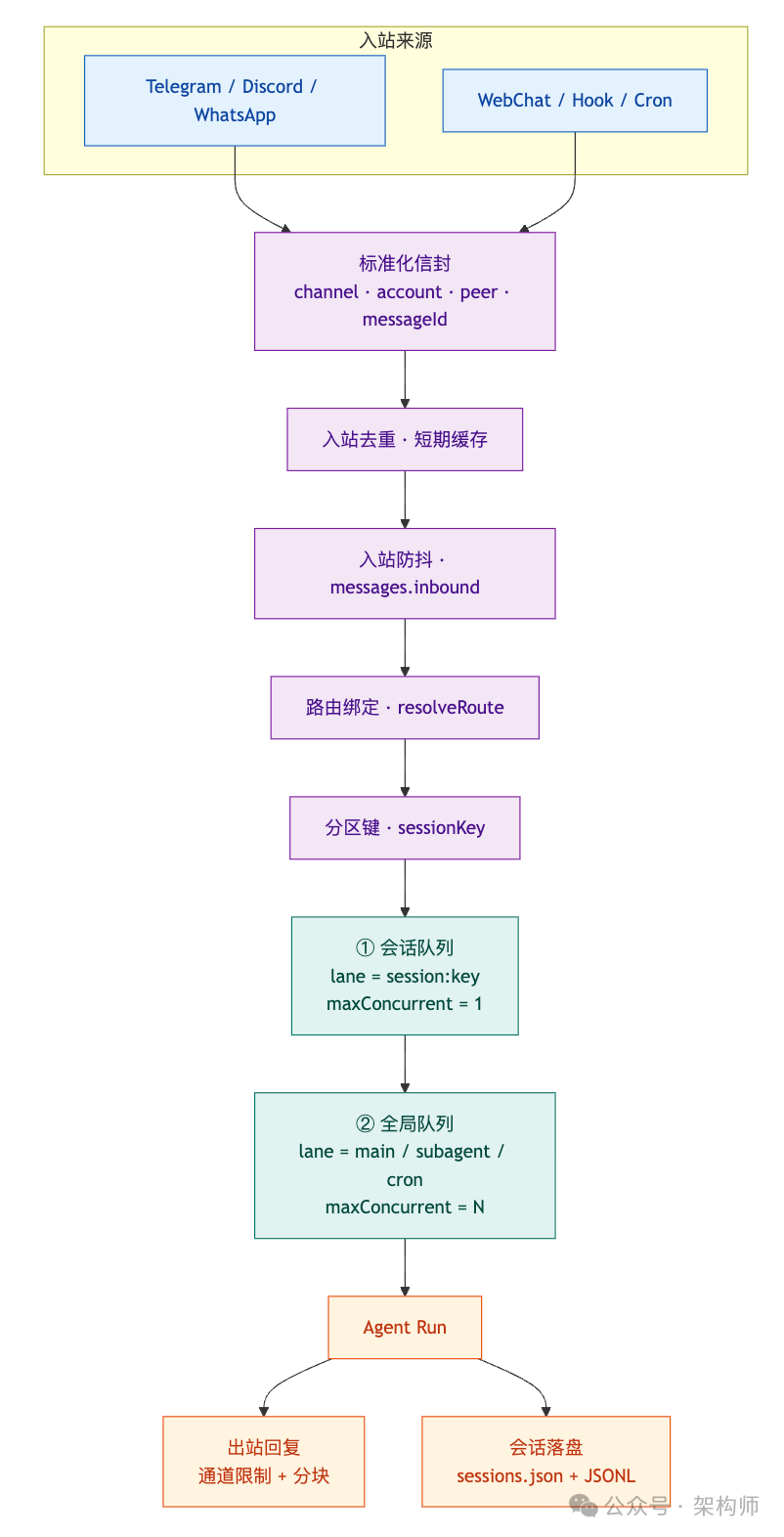
注意这张图里有两个“背压点”:
- 同会话串行,保证有序性。
- 全局限流,保证吞吐不会失控。
这比到处写 async/await 可靠得多。
4)队列模式:把“新消息怎么进入当前运行”变成规则
很多系统有队列,但队列策略不说人话。OpenClaw 把入站队列做成模式,官方定义里最关键的三条是:
collect:把排队消息合并为一个后续轮次(默认)。followup:当前运行结束后再跑下一轮。steer:把新消息注入当前运行;如果不在流式阶段会回退到 followup。
你可以把它理解为三种不同的背压策略:
followup 是“严格 FIFO”,简单,但容易越积越多。collect 是“微批处理”,更适合连发补充与群聊洪水。steer 是“交互式修正方向”,更适合控制类消息,但它并不是抢占式调度。
我补一张更贴近决策树的图,把“steer 回退”这种关键边界写出来:
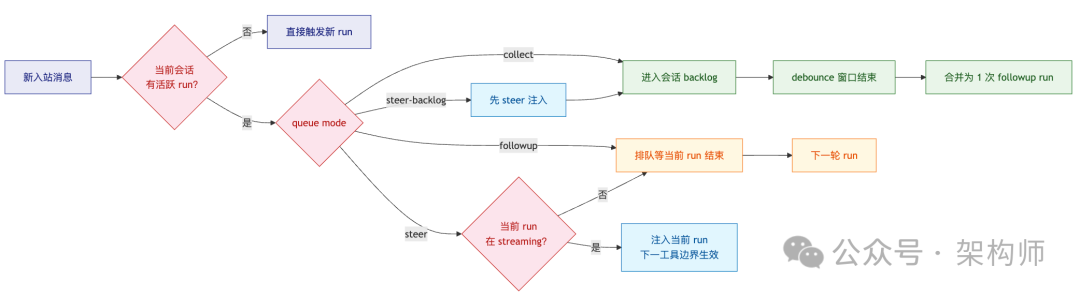
有了这张图,“为什么它只回了一次”可以解释成策略选择,不必归因于模型理解问题。这类将复杂行为拆解为可解释规则的设计,在 云栈社区 的架构讨论中也是备受推崇的实践。
5)debounceMs/cap/drop:别追求最优,先追求可解释
官方给的默认值是:debounceMs: 1000、cap: 20、drop: summarize。
这三个默认值对应三条务实的设计目标:
debounceMs:给“连发补充”一个合并窗口,避免触发多次昂贵运行。cap:保证 backlog 有上限,这是背压,不是体验惩罚。drop: summarize:在不可避免的丢弃时,保留一个“丢弃摘要”注入后续提示,让上下文链条不至于断得太突兀。
这三个参数不需要一开始就调到最优。重点是线上出问题时,你能把行为解释成规则,知道改哪个旋钮。这体现了一种 开源实战 中常见的设计哲学:确定性优于模糊的“智能”。
6)别把“入站防抖”当成“队列模式”
OpenClaw 还有一层入站防抖(messages.inbound.debounceMs),它解决的是“同一发送者快速连发文本”的微批处理。
官方文档明确了边界条件:
- 防抖只对纯文本生效;媒体/附件会立即刷新。
- 控制命令绕过防抖,保持独立。
这意味着你可以把系统拆成两层:
- 输入卫生层:入站防抖、入站去重。
- 并发治理层:会话键、队列模式、双层队列。
两层都需要,但它们解决的问题不同。
7)队列观测:排队发生了什么,要看得到
传统队列系统里,一个常见反模式是“队列里发生了什么没人知道”。OpenClaw 在观测侧给了更硬的抓手:
- 日志与诊断事件里有队列入队/出队、等待时长等信号(例如
queue.lane.enqueue、queue.lane.dequeue,以及队列深度/等待时间的指标)。
- 队列等待时(启用详细日志)超过约 2 秒会有提示。
- 对用户侧的体验,入队后会尽早触发 typing(通道支持时),把“排队”暴露成可感知状态。
这些属于系统自解释能力,不该靠临时加日志解决。详细的日志事件定义和行为追踪,在构建可观测系统时,是 技术文档 需要重点阐述的部分。
|  发表于 2026-2-26 03:31:05
|
查看: 196|
回复: 0
发表于 2026-2-26 03:31:05
|
查看: 196|
回复: 0
