在设计数据库表时,你是否曾犹豫过某个字段是否应该允许为空(NULL)?一个小小的选择,可能会在后续的查询中埋下意想不到的“坑”。今天,我们就通过一个具体的实验,来剖析允许空值可能带来的问题及其背后的原理。
实验准备
首先,我们创建一个简单的用户表,并为 id 字段建立索引。
create table user (
id int,
name varchar(20),
index(id)
)engine=innodb;
【说明】
id 字段:是索引,但非唯一(non unique),并且允许为空(NULL)。
接着,插入三条初始数据:
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
现在,第一个问题来了:执行下面的查询,你认为会返回什么结果?
select * from user where id!=1;
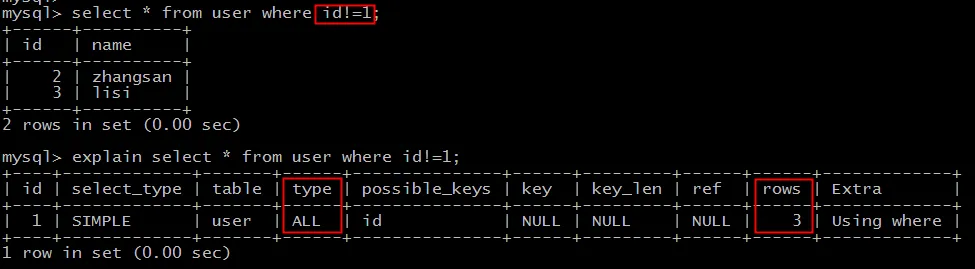
让我们查看这条语句的执行计划:
explain select * from user where id!=1;
从执行计划可以看到:
type=ALL,表示进行了全表扫描。rows=3,扫描了表中的3行数据。
这印证了第一个关键点:在索引字段上使用负向查询(如 !=, NOT IN),通常无法有效利用索引,会导致全表扫描。此时查询返回了 id 为 2 和 3 的两条记录,符合预期。
引入空值(NULL)的陷阱
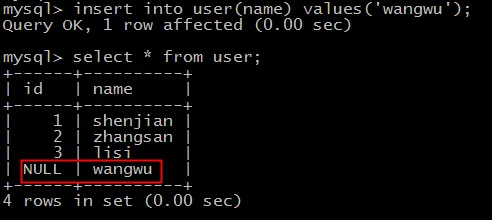
接下来,我们插入一条不指定 id 的记录,这将使 id 字段的值为 NULL。
insert into user(name) values('wangwu');
插入后,表数据如下:
现在,第二个关键问题出现了:再次执行相同的 != 查询,结果会如何?
直觉上,表里共有4条记录(id: 1, 2, 3, NULL),排除 id=1 的记录,应该返回3条(2, 3, NULL),对吗?
select * from user where id!=1;
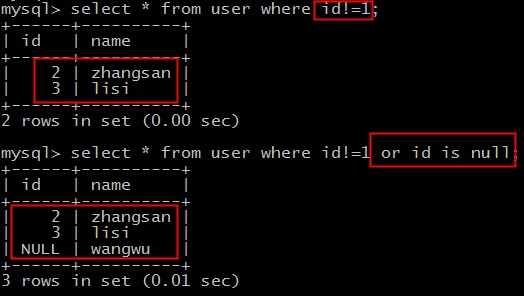
结果出乎意料:只返回了2条记录(id为2和3),那个id为NULL的记录“消失”了!
这就是允许空值带来的一个大坑:在SQL逻辑中,NULL 与任何值(包括 NULL 本身)的比较结果都是 UNKNOWN,而非 TRUE 或 FALSE。 因此,id!=1 这个条件会过滤掉 id=1 的记录,但无法筛选出 id IS NULL 的记录,因为它根本不会对NULL值进行判断。
如果想要得到包含NULL记录的、符合我们业务直觉的结果,必须显式地加上 IS NULL 条件:
select * from user where id!=1 or id is null;
OR 条件可能引发的性能问题及优化
上述方法虽然能得到正确结果,但 OR 连接的条件可能会引发新的性能问题。我们来看另外一组对比。
情况一:等值查询与NULL查询单独执行,都能命中索引。
-
查询 id=1:
explain select * from user where id=1;
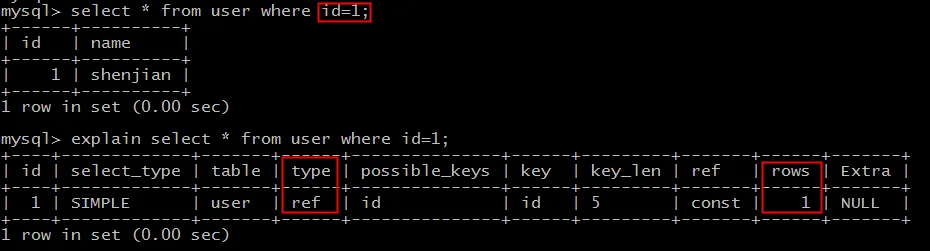
类型为 ref,使用索引,预估扫描1行。
-
查询 id IS NULL:
explain select * from user where id is null;
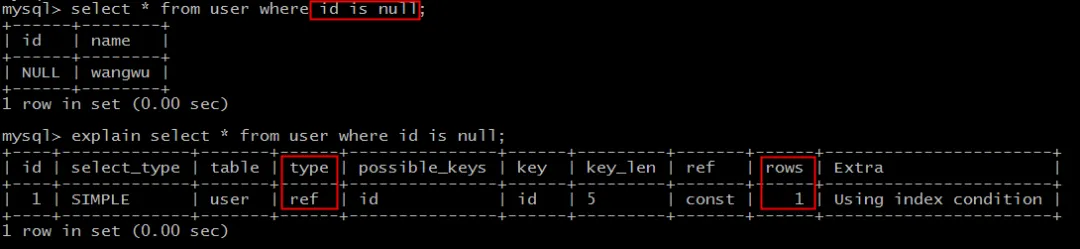
同样为 ref 类型,使用索引,预估扫描1行。
情况二:使用 OR 将两个条件合并,却可能导致全表扫描。
explain select * from user where id=1 or id is null;
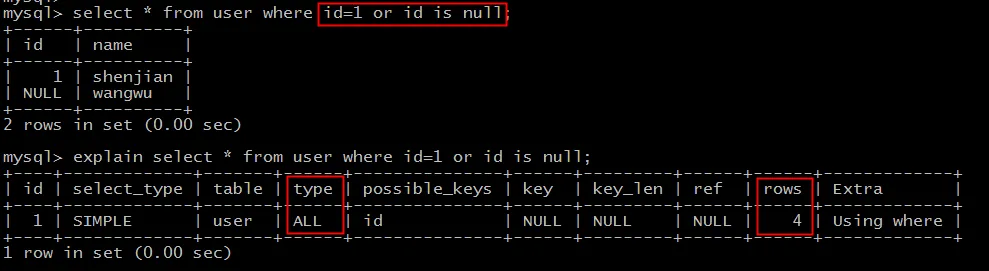
执行计划显示 type=ALL,进行了全表扫描(rows=4)。
情况三:优化方案——使用 UNION 代替 OR。
对于这类场景,一个有效的优化手段是将 OR 拆分为 UNION(或 UNION ALL,视业务需求而定)。
explain
select * from user where id=1
union
select * from user where id is null;
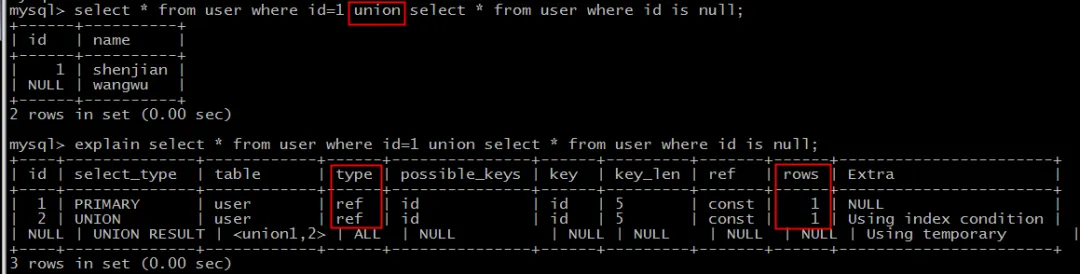
优化后,两个子查询分别命中了索引(type=ref),最后再合并结果。虽然合并过程(第三行)涉及临时表,但整体效率远高于全表扫描。
总结与最佳实践
通过这个小实验,我们可以总结出关于数据库字段空值与索引查询的几个重要结论:
- 慎用负向查询:在索引字段上使用
!=、NOT IN 等负向条件,极易导致全表扫描,在数据库设计初期就应考虑到此类查询的性能影响。
- 警惕 NULL 的逻辑陷阱:
NULL 参与比较运算的结果是 UNKNOWN。column != value 的查询不会包含 column IS NULL 的行,这常常导致查询结果与预期不符。需要正确结果时,务必加上 ... OR column IS NULL。
- 优化 OR 条件:包含多个条件的
OR 语句有时会妨碍索引使用,可以考虑使用 UNION 进行重写,往往能带来性能提升。
- 设置默认值:在表设计时,如果业务允许,为字段设置合理的
DEFAULT 值(如 0, ‘’ 空字符串等)而非允许 NULL,可以从根源上避免许多因三值逻辑(TRUE/FALSE/UNKNOWN)带来的复杂性。
- 善用 EXPLAIN:
EXPLAIN 命令是分析和优化 MySQL 查询性能的必备工具,任何性能相关的调整都应基于对执行计划的分析。
知其然,更要知其所以然。 理解 NULL 在数据库中的特殊语义和索引的工作机制,比单纯记住结论更重要。这能帮助我们在复杂的业务场景和数据库查询中,更从容地避开陷阱,设计出更健壮、高效的SQL语句。
 发表于 2026-2-26 03:29:26
|
查看: 226|
回复: 0
发表于 2026-2-26 03:29:26
|
查看: 226|
回复: 0
