一个值得深思的问题:两座同城机房,每座都部署了完整的服务,日常各承担 50% 的流量,这算同城多活吗?
很多团队会说算。但如果追问一句:当其中一座机房完全故障时,另一座能否承接 100% 的流量?如果答案是能,那这套架构本质上还是主备思维,只不过平时让备机房顺便干点活。
真正的同城多活,恰恰是在单机房无法承载全量流量这个约束下才被逼出来的。而这个约束,通常在系统迈向千万 QPS 时才会真正生效。
同城多活的三个阶段
同城多活的演进,本质上是流量规模对架构韧性要求不断提高的结果。随着 QPS 量级增长,系统对机房的依赖关系、容灾策略、流量调度模型都在发生结构性变化。

三个阶段不是容量的线性增长,而是架构模式的质变。下面逐一展开。
阶段一:主备模式,十万 QPS 的够用就好
十万 QPS 量级,系统的核心诉求是可用而非均衡。典型做法是一个主机房承载全部线上流量,另一个备机房仅做数据同步,故障时手动或半自动切换。

主备模式最大的优点是简单:数据流向单一,不需要处理双写冲突,运维复杂度低。缺点在于备机房长期不承载真实流量,切换时面临冷启动问题,包括缓存为空、连接池未建立、服务未预热等,容易导致切换后短时间内性能波动。
不过在十万 QPS 这个量级,切换过程中几分钟的服务降级,业务通常能够接受。
阶段二:主辅模式,百万 QPS 的有分担但不均等
当系统达到百万 QPS,主备模式的问题开始放大。
首先是成本问题。百万 QPS 对应的服务器规模相当可观,让一整座机房空转的资源浪费不再是小数目。其次是切换风险放大:十万 QPS 时冷启动波动或许只影响数百个请求,百万 QPS 时则可能影响数十万用户。此外,单机房的物理容量(服务器、网络带宽、电力)也开始逼近天花板。
因此,系统走向主辅模式:主机房承载大部分流量(如 70%-80%),辅机房承载一小部分(如 20%-30%)。

主辅模式的核心改进在于:辅机房时刻承载真实流量,缓存是热的,连接是活的,服务是预热过的。故障切换时,辅机房已经具备立即承接更多流量的能力,不再有冷启动风险。
但主辅模式有一个重要的隐含假设:任何一座机房都具备独立承载全量流量的能力。辅机房日常虽然只承载 20%-30% 的流量,但其容量规划必须按 100% 来做,否则主机房故障时无法完成接管。
在百万 QPS 量级,这个假设虽然成本高昂,但技术上仍然可行。这种为高可用而进行的冗余设计,是分布式系统架构中常见的权衡。
阶段三:均衡多活,千万 QPS 的谁也离不开谁
当系统达到千万 QPS,任何一座机房可以独立承载全量的假设开始瓦解。
千万 QPS 所需的服务器规模、网络带宽、存储吞吐、电力供应,已经超出单一机房的合理容量范围。即便物理上能堆出这样的机房,其网络拓扑复杂度、故障域集中度、运维管理难度,也会让系统的可靠性大打折扣。
系统必须走向真正的均衡多活:多个机房共同承载流量,每个机房承担大致均等的份额,且任何单一机房的故障不会导致系统全面不可用。
均衡多活与主辅模式的本质差异:
下图展示均衡多活架构下,故障发生时的流量再分配:

均衡多活的核心设计挑战
从主辅走向均衡多活,需要在多个维度上重新设计系统。以下几个挑战是实践中最容易被低估的。
容量规划:冗余模型的根本转变
主辅模式的容量逻辑是N+1:两个机房,每个都按全量部署,一个故障另一个完全接管。简单但浪费。
均衡多活的逻辑不同。3 个机房均分流量时,每个承载 33%;一个故障后剩余两个各自承担 50%,即每个机房需要预留约 50% 的冗余容量,而非 100%。
冗余比例随机房数量的变化关系如下:
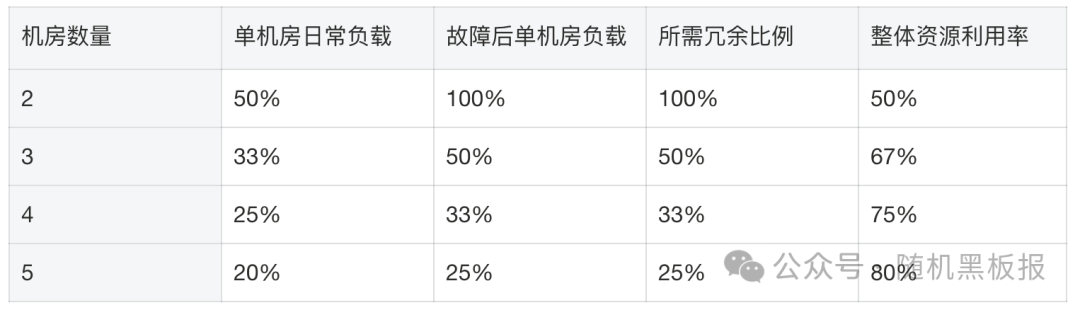
机房数量越多,冗余比例越低,整体资源利用率越高。这也是千万 QPS 系统倾向于部署 3 个或更多机房的原因之一。
需要注意的是:上表假设只容忍单机房故障。如果需要同时容忍两个机房故障,冗余比例会大幅上升,3 机房方案甚至无法满足要求。实际规划中,机房数量和冗余策略需要根据业务的容灾等级来确定。
另一个容易忽略的问题是:容量冗余不仅仅是 CPU 和内存的冗余,还包括网络带宽、数据库连接数、消息队列吞吐等各种资源的冗余。某个维度的冗余不足,就可能成为故障接管时的瓶颈。
流量调度:从粗粒度切换到精细化均衡
主辅模式下,流量调度相对粗放:日常比例相对固定,故障时的操作是大开关式的整体切换,人工决策即可。
均衡多活要求的调度精细得多。当一个机房故障时,不是各自多扛一些这么简单,而是需要综合考虑多个因素:
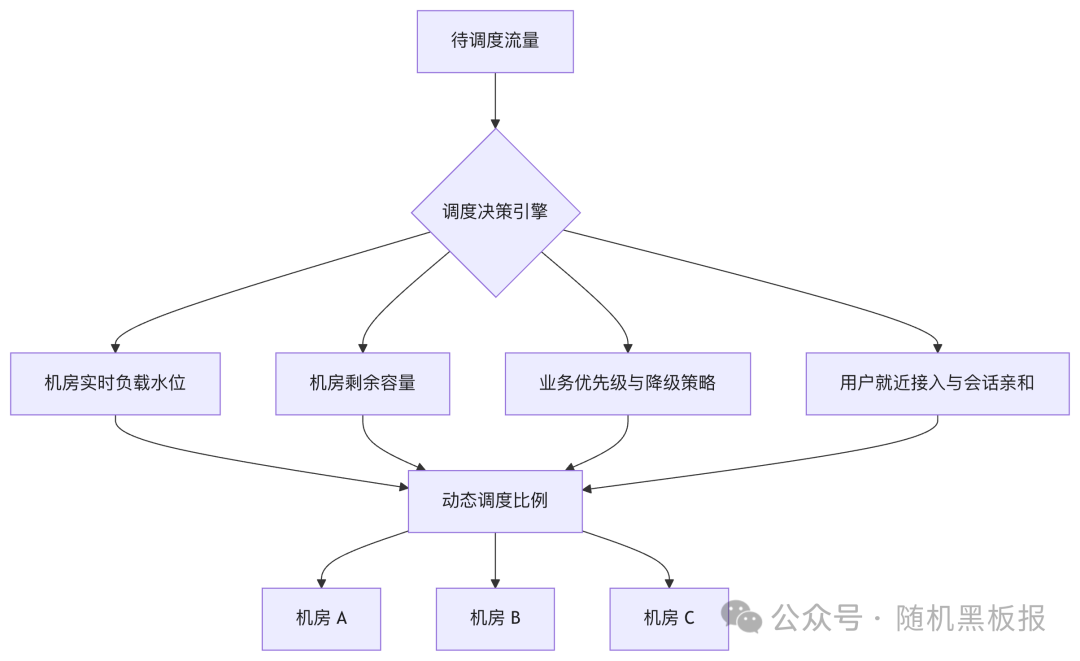
在千万 QPS 的均衡多活中,流量调度必须具备以下能力:
- 实时感知每个机房的健康状态和负载水位,而不是依赖人工巡检。
- 根据预设策略自动调整流量比例,将人工决策环节从分钟级压缩到秒级。
- 支持渐进式调整。一次性将 33% 的流量涌入另一个机房,极有可能触发缓存击穿或连接池耗尽。正确的做法是分钟级逐步提升,边调边观察。
- 具备回滚能力。当目标机房在接收额外流量后也出现异常时,需要能快速回退。
这其中,渐进式调整是主辅模式中不存在的概念。主辅模式的切换是全有或全无,而均衡多活的调度是持续的、动态的再平衡。
数据一致性:从主从复制到分片写入
主辅模式下,数据架构通常是经典的主从复制:主机房负责写入,辅机房通过异步或半同步复制获取副本。辅机房的读请求读本地副本,写请求转发到主机房。
均衡多活模式下,如果所有写请求都集中到某一个机房,那个机房就成了事实上的主,违背了均衡的初衷。因此需要将写入分散到多个机房。常见方案有三种:
- 方案一:按用户维度分片写入。 同一用户的写请求始终路由到同一个机房,从根本上避免写冲突。这是实践中最常见的方案。
- 方案二:按业务类型分区写入。 不同业务的写入指向不同机房,减少跨机房写冲突。
- 方案三:多点并发写入加冲突解决。 采用 CRDT 或 Last-Write-Wins 等机制,允许多点写入,事后解决冲突。适用于一致性要求不严格的场景。
其中用户维度分片最为普遍,其架构如下:
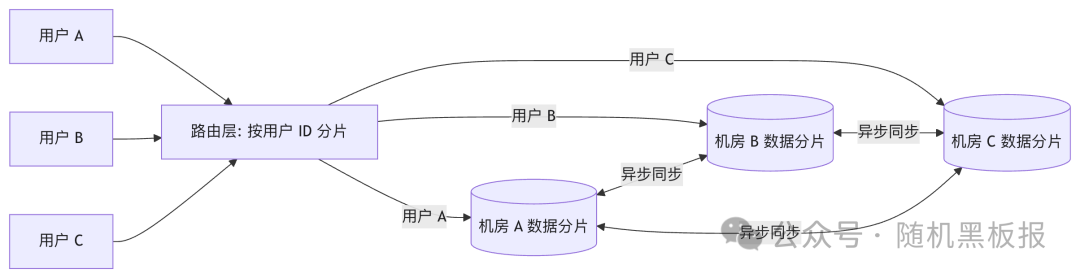
每个机房是自己负责的那部分用户数据的主,同时持有其他机房数据的副本用于读取。
但用户分片方案并非没有代价,几个在实践中常遇到的问题值得注意:
- 热点用户问题。 少数高频用户(如大 V、企业账号)的请求量可能远超均值,导致某个机房的负载显著高于其他机房。需要在分片策略上做热点识别和特殊处理。
- 跨用户查询问题。 当业务需要查询多个用户的聚合数据时(如社交关系链、排行榜),请求可能需要扇出到多个机房再聚合,增加了延迟和复杂度。
- 分片迁移问题。 当需要增加或减少机房、或调整分片策略时,部分用户的数据归属会发生变化。迁移期间的数据一致性保障是一个复杂的工程问题。
缓存一致性:容易被忽视的性能陷阱
同城多活场景下有一个容易被忽视的问题:缓存命中率下降。
在单机房或主辅模式下,同一个用户的请求基本都落在同一组缓存节点上,缓存命中率较高。进入均衡多活后,如果用户请求被分散到不同机房,每个机房都需要独立建立和维护自己的缓存,同一份热点数据可能在多个机房各缓存一份。
这本身不是问题,但在以下两种场景下会引发困扰:
- 缓存更新的一致性。 用户在机房 A 更新了数据,机房 B 和 C 的缓存中可能还是旧数据。如果后续读请求被路由到了机房 B,就会读到过期数据。
- 故障切换后的缓存冷启动。 当一个机房故障,其流量迁移到其他机房时,目标机房的缓存中并没有这部分用户的热数据。大量缓存未命中会瞬间传导到数据库层。
采用用户维度分片能有效缓解第一个问题:同一用户的读写始终在同一机房,缓存天然一致。但第二个问题依然存在,需要在故障切换的渐进式调度中预留缓存预热的时间窗口。这时,一个统一的分布式数据库缓存(如 Redis)集群的规划就变得尤为重要。
故障处理:从非黑即白到灰度应对
主辅模式的故障处理逻辑清晰:主机房挂了切辅,辅机房挂了影响有限。故障判定是相对明确的黑白题。
均衡多活面临的更大挑战在于灰色故障。所谓灰色故障,是指机房没有完全不可用,但出现了部分异常:某些服务响应变慢、部分网络链路丢包率升高、数据库主从延迟突然增大等。
灰色故障之所以棘手,是因为它处在切与不切之间:
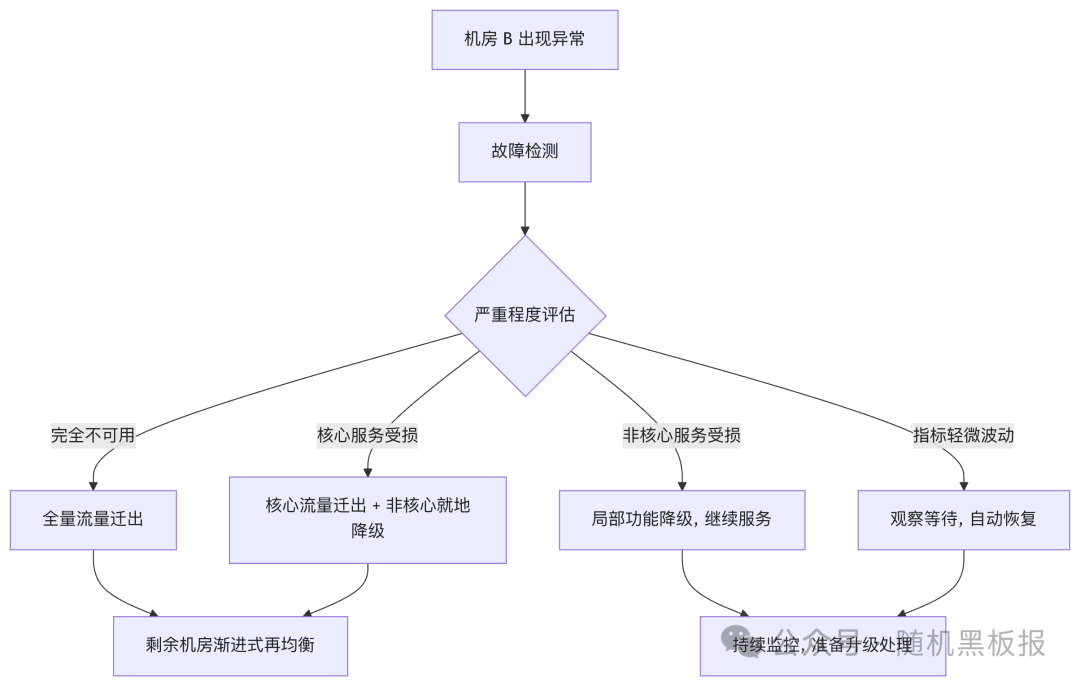
如果贸然将流量全部迁出,可能造成不必要的连锁反应,因为接收额外流量的机房也会面临压力骤增。如果不迁移,用户又在持续受到影响。
因此,均衡多活需要更精细的故障分级机制:
- 区分故障影响面。 是整个机房不可用,还是部分服务降级?不同影响面对应不同的处置策略。
- 支持局部降级。 不是所有故障都需要大搬迁,有时关闭某些非核心功能、限制部分写入,比全量迁移更安全。
- 渐进式迁移。 即便需要迁出流量,也应该分批进行,避免对目标机房形成冲击。
- 自动化判定。 灰色故障的判定依赖多个指标的综合分析(延迟 P99、错误率、丢包率等),靠人工盯监控在千万 QPS 下不现实。
多活验证:如何证明多活不是一句口号
均衡多活架构有一个特殊的工程挑战:它的核心价值体现在故障时刻,但平时没有故障的时候,你很难确信它真的能在故障时正常工作。
主辅模式的验证相对简单:定期做一次主备切换演练即可。均衡多活的验证则复杂得多,因为需要验证的场景组合呈指数级增长:任意一个机房故障、任意两个服务同时故障、某个机房的某条链路出现延迟抖动等等。
实践中常用的验证手段包括:
- 常态化故障演练。 定期在生产环境中模拟机房级故障,验证流量调度和数据一致性是否符合预期。这不是年度演练,而是需要形成常态化机制,至少月度频率。
- 流量录制与回放。 录制线上流量,在测试环境中模拟多机房故障场景进行回放,验证系统行为的正确性。
- 持续的数据一致性校验。 在多机房之间持续运行数据比对任务,确保数据同步没有静默丢失。数据不一致的问题往往不会立即暴露,可能在数天甚至数周后才被发现。
没有经过验证的多活架构,本质上是薛定谔的多活。想深入了解这些技术细节的演进和更多实战讨论,可以来云栈社区看看,这里汇聚了许多关于架构与高可用的深度分享。
总结
同城多活的演进,核心变量只有一个:单机房能否承载全量流量。
当答案是能的时候,无论系统看起来多么多活,本质上都还是主备思维。主辅模式让备机房热起来,解决了冷启动问题,但架构的容灾底线仍然建立在单机房兜底的假设之上。
当答案变成不能的时候,系统不得不在容量规划、流量调度、数据分片、缓存一致性、故障处理、多活验证等多个维度进行系统性重构。这些变化不是渐进式的优化,而是架构模式的质变。
从实际演进路径来看,这通常不是一步到位的。先让备机房热起来(解决冷启动),再逐步提升流量占比(验证承载能力),然后引入用户分片(打破单点写入),接着扩展到 3 个以上机房(实现均衡),最后建设自动化调度和常态化演练体系(保障持续可靠)。
每一步都需要在上一步充分验证后再推进。架构演进最忌讳跳跃式前进,在主备阶段的基础设施和运维体系还不成熟时,就试图直接跳到均衡多活,往往会引入更大的风险。
 发表于 2026-2-26 03:33:03
|
查看: 166|
回复: 0
发表于 2026-2-26 03:33:03
|
查看: 166|
回复: 0
