在早期的计算机系统中,程序直接访问物理内存。这种简单直接的方式就像所有人共享一个没有隔断的大通间,容易导致内存碎片化、程序间相互干扰以及安全性低下等诸多问题。
为了有效解决这些问题,现代操作系统引入了虚拟内存概念。虚拟内存为每个进程提供了一个独立、连续且受保护的地址空间,如同给每个住户分配了带锁的独立公寓单元。Linux系统实现虚拟内存主要依赖于两种相辅相成的核心技术:分段 和 分页。理解这些底层机制,是深入学习操作系统原理与内存管理的基础。
我们可以通过一个简单的比喻来区分两者:假设你需要给朋友寄信(访问内存)。分段机制类似于邮政编码系统,它根据地址的不同功能区域(如代码区、数据区、栈区)将整个城市(地址空间)划分为不同的邮区;而分页机制则像邮递员的具体配送过程——无论信封上写的地址(虚拟地址)多么理想化,最终都必须找到具体的物理门牌号(物理地址)。

图1:Linux内存管理机制概览,展示分段与分页流程
第一章: 分段机制详解
1.1 分段的核心思想
分段的概念源于程序本身的自然逻辑划分。一个典型的程序通常包含以下几个逻辑部分:
- 代码段:存放可执行的机器指令。
- 数据段:存放已初始化的全局变量和静态变量。
- BSS段:存放未初始化的全局变量和静态变量。
- 栈段:存放函数调用信息、返回地址和局部变量。
- 堆段:用于程序运行时动态分配的内存区域。
分段机制旨在为每个这样的逻辑段提供独立的地址空间和保护机制。x86架构在硬件层面原生支持分段,它通过一组段寄存器(CS代码段、DS数据段、SS栈段等)和称为段描述符的数据结构来实现这一机制。
1.2 段描述符与全局描述符表(GDT)
段描述符是分段机制的核心数据结构,每个描述符定义了一个内存段的关键属性。
// Linux内核中段描述符的简化表示
struct segment_descriptor {
u16 limit_low; // 段界限的低16位
u16 base_low; // 段基址的低16位
u8 base_middle; // 段基址的中间8位
u8 type:4; // 段类型(代码/数据,可读/可写等)
u8 s:1; // 描述符类型(0=系统段,1=代码/数据段)
u8 dpl:2; // 描述符特权级(0-3)
u8 present:1; // 段是否存在于内存中
u8 limit_high:4; // 段界限的高4位
u8 avl:1; // 可供系统软件使用
u8 l:1; // 64位代码段标志
u8 d_b:1; // 默认操作数大小(0=16位,1=32位)
u8 g:1; // 粒度标志(0=字节,1=4KB页)
u8 base_high; // 段基址的高8位
} __attribute__((packed));
所有段描述符集中存放在全局描述符表(GDT)中,GDT可以看作是一个系统级的“段目录”。CPU通过GDTR寄存器来定位GDT在内存中的位置。
// GDT指针结构(指向GDT本身)
struct gdt_ptr {
u16 limit; // GDT表的大小-1
u32 base; // GDT的基地址
} __attribute__((packed));
1.3 地址转换过程
在分段机制下,逻辑地址到线性地址的转换过程可以概括为以下两步:
逻辑地址 → [段选择符 + 偏移量] → 线性地址
具体步骤如下:
- 选择段描述符:CPU根据指令提供的16位段选择符(其高13位为索引),在GDT或LDT(局部描述符表)中找到对应的段描述符。
- 计算线性地址:从获取的段描述符中取出32位的段基址,然后加上指令中给出的偏移量,最终得到线性地址。
- 检查权限:在此过程中,硬件会验证当前代码的当前特权级(CPL)是否满足段描述符所要求的描述符特权级(DPL),以此实现内存保护。
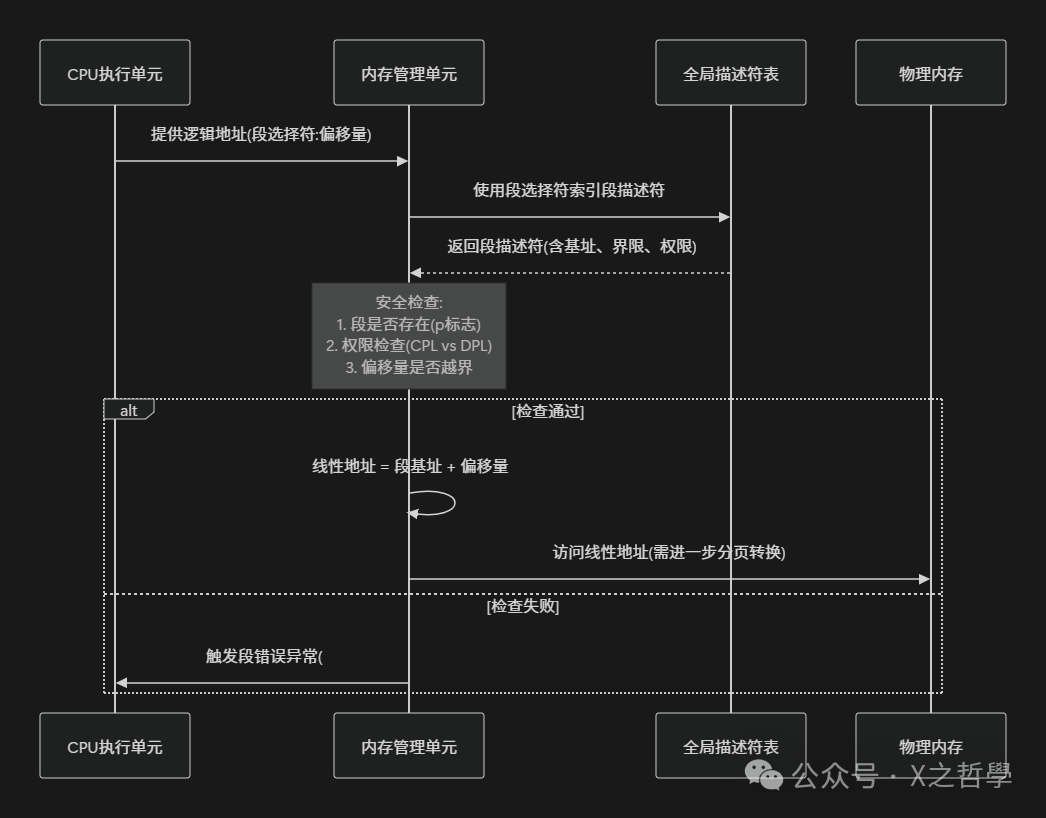
图2:CPU执行单元与内存管理单元(MMU)交互流程,展示分段地址转换与安全检查
1.4 Linux对分段的特殊处理
尽管x86硬件强制使用分段机制,但Linux出于可移植性和简化管理的考虑,采用了独特的“扁平模型”来最小化其影响。
// Linux内核GDT布局的简化示意
static struct gdt_entry gdt_table[] = {
/* 0x00: 空描述符(必须为0) */
GDT_ENTRY(0, 0, 0, 0),
/* 0x08: 内核代码段 */
GDT_ENTRY(0xc09b, 0, 0xfffff, 0), // 基址0,界限4GB,可读/执行,DPL=0
/* 0x10: 内核数据段 */
GDT_ENTRY(0xc093, 0, 0xfffff, 0), // 基址0,界限4GB,可读/写,DPL=0
/* 0x18: 用户代码段 */
GDT_ENTRY(0xc0fb, 0, 0xfffff, 3), // 基址0,界限4GB,可读/执行,DPL=3
/* 0x20: 用户数据段 */
GDT_ENTRY(0xc0f3, 0, 0xfffff, 3), // 基址0,界限4GB,可读/写,DPL=3
// ... 其他系统段(如TSS、LDT)
};
在这种设计中,所有段的基址都被设置为0,段界限设为4GB。这意味着逻辑地址中的偏移量直接等于线性地址,分段机制在地址转换层面实际上被绕过了。Linux选择这种设计主要基于以下原因:
- 简化内存管理:为内核和用户空间提供统一的4GB线性地址空间视图。
- 提高可移植性:许多现代处理器架构(如ARM、RISC-V)并不原生支持分段机制。
- 性能优化:避免了复杂的段址计算,减少了地址转换的开销。
第二章: 分页机制深度解析
2.1 分页的基本原理
如果说分段是按照程序的逻辑意义来划分内存,那么分页就是按照固定大小来划分内存。分页机制将虚拟地址空间和物理地址空间都切割成大小相等的块,称为“页”(通常为4KB)。这就像图书馆将所有书籍都放入相同尺寸的盒子中,便于管理和存放。
分页机制的核心优势包括:
- 消除外部碎片:所有物理内存页框大小相同,只有内部碎片(页内未用完的空间)。
- 简化内存分配:内存分配器只需维护一个空闲页框的列表。
- 高效实现虚拟内存:允许将暂时不用的页面交换到磁盘(如Swap分区),实现比物理内存更大的地址空间。
- 精细的权限控制:可以针对每一个物理页单独设置读、写、执行等访问权限。
2.2 多级页表结构
现代操作系统使用多级页表来管理巨大的虚拟地址空间(例如x86_64支持48位地址空间)。以经典的x86 32位分页(未开启PAE)为例,一个32位的虚拟地址被分解为三部分:
虚拟地址 (32位) = [10位页目录索引] + [10位页表索引] + [12位页内偏移]
其三级转换过程如下:
- 页目录:每个进程拥有一个页目录,包含1024个页目录项(PDE),其物理地址存放在CR3寄存器中。
- 页表:每个PDE指向一个页表,每个页表同样包含1024个页表项(PTE)。
- 物理页:每个PTE指向一个4KB大小的物理页框(页帧)。
// Linux内核中页表项结构的简化表示
typedef struct {
unsigned int present:1; // 页是否在物理内存中 (1=在,0=不在,触发缺页)
unsigned int rw:1; // 读写权限 (0=只读,1=可读可写)
unsigned int user:1; // 访问权限 (0=仅内核,1=用户态可访问)
unsigned int pwt:1; // 写通(Write-Through)缓存策略
unsigned int pcd:1; // 缓存禁用(Cache Disable)
unsigned int accessed:1; // 页是否被访问过(用于页面替换算法)
unsigned int dirty:1; // 页是否被写入过(脏页标志)
unsigned int pat:1; // 页属性表索引
unsigned int global:1; // 全局页(TLB刷新时通常不失效)
unsigned int avail:3; // 供操作系统自由使用
unsigned int frame:20; // 页框号(物理地址的高20位)
} page_table_entry;
2.3 地址转换详细过程
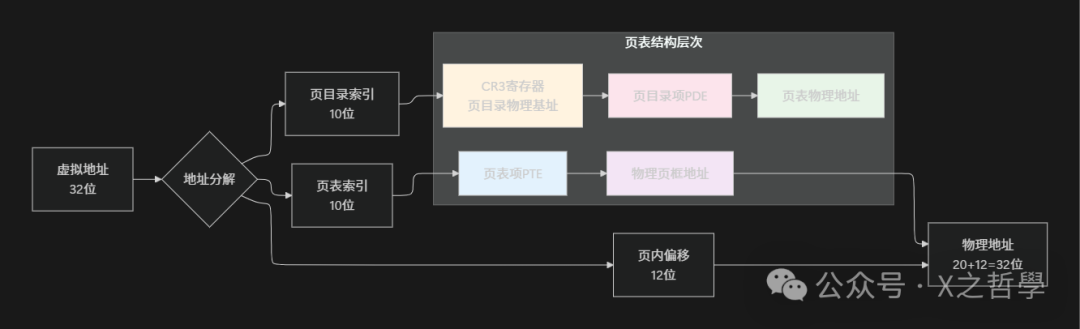
图3:x86 32位分页模式下,虚拟地址通过页目录、页表转换为物理地址的详细过程
转换步骤详解:
- 获取页目录基址:MMU从CR3寄存器中读取当前进程页目录的物理地址。
- 查找页目录项:使用虚拟地址的高10位作为索引,在页目录中找到对应的PDE。
- 获取页表地址:从PDE中提取出页表的物理基地址。
- 查找页表项:使用虚拟地址的中间10位作为索引,在上一步找到的页表中定位到对应的PTE。
- 获取页框地址:从PTE中提取出物理页框的基地址(页框号)。
- 组合物理地址:将物理页框基地址与虚拟地址的低12位(页内偏移)相加,得到最终的物理地址。
这个过程由硬件内存管理单元(MMU)自动完成,内核负责建立和维护页表结构。
2.4 页错误处理机制
当CPU尝试访问一个其PTE中present位为0的页面时,会触发一个缺页异常。Linux的缺页异常处理程序handle_mm_fault非常复杂,需要区分多种情况。
// 缺页异常处理的简化逻辑框架
static void handle_page_fault(struct pt_regs *regs, unsigned long error_code) {
unsigned long address = read_cr2(); // 获取触发异常的线性地址
struct task_struct *tsk = current;
struct mm_struct *mm = tsk->mm;
// 检查是否为内核空间地址访问错误
if (unlikely(address >= TASK_SIZE_MAX)) {
do_kernel_fault(error_code, address);
return;
}
// 用户空间缺页处理
if (error_code & PF_USER) {
if (error_code & PF_PROT) {
// 保护错误:权限不足(例如写只读页)
handle_protection_fault(address);
} else if (error_code & PF_WRITE) {
// 写时复制(Copy-on-Write)缺页
handle_cow_fault(mm, address);
} else {
// 常规缺页:分配新页或从swap调入
handle_pte_fault(mm, address);
}
} else {
// 内核模式访问用户空间(例如copy_from_user)
handle_user_access_fault(address);
}
}
常见缺页类型及处理方式:
| 缺页类型 |
触发条件 |
处理方式 |
| 匿名页缺页 |
访问未分配的堆/栈内存 |
分配一个新的填充为零的物理页(零页) |
| 文件映射缺页 |
访问内存映射文件中尚未加载的页 |
从文件系统读取相应数据块到物理页 |
| 写时复制缺页 |
尝试写入一个只读的共享页(如fork后) |
复制物理页内容,为新进程建立私有映射 |
| 交换缺页 |
访问已被换出到Swap分区的页 |
从Swap分区读回数据到内存,可能需换出其他页 |
| 权限缺页 |
违反页面权限(如向只读页执行写入) |
向进程发送SIGSEGV段错误信号 |
2.5 现代扩展: 大页与透明大页
为了减少TLB缺失率、提高内存访问性能,现代处理器支持大页(如2MB、1GB)。使用大页意味着一个TLB条目可以覆盖更大的内存范围。
// 检查CPU是否支持大页并设置
if (cpu_has_pse) { // 页大小扩展(Page Size Extension)
// 可以设置2MB大页
pse_entry = create_large_page(addr, PAGE_SIZE_2M);
}
// 透明大页(Transparent Huge Pages, THP)的启用(用户态)
static int enable_transparent_hugepage(void) {
// 通过sysfs接口控制
write_to_file("/sys/kernel/mm/transparent_hugepage/enabled", "always");
return 0;
}
大页的优势:
- 减少TLB压力:相同数量的TLB条目可以映射更大的物理内存范围,降低TLB缺失率。
- 降低页表开销:映射相同大小的内存,需要的页表项更少,节省内存并减少页表遍历层级。
- 提高内存访问效率:连续的大块内存更有利于硬件预取(Prefetch)机制工作。
第三章: 内存管理核心数据结构
3.1 进程地址空间描述符: mm_struct
在Linux中,每个进程(或线程组)都有一个mm_struct结构体,它完整描述了该进程的虚拟地址空间。
struct mm_struct {
struct vm_area_struct *mmap; // 指向虚拟内存区域(VMA)链表的头
struct rb_root mm_rb; // VMA红黑树的根(用于快速查找)
pgd_t *pgd; // 页全局目录(Page Global Directory)
atomic_t mm_users; // 使用该地址空间的用户计数(如线程)
atomic_t mm_count; // 主引用计数
unsigned long start_code, end_code; // 代码段的起止地址
unsigned long start_data, end_data; // 数据段的起止地址
unsigned long start_brk, brk, start_stack; // 堆和栈的边界
unsigned long total_vm; // 总映射的虚拟内存大小(以页为单位)
unsigned long locked_vm; // 被锁定在RAM中不可换出的页数
// ... 更多字段(如信号量、锁、列表头等)
};
3.2 虚拟内存区域: vm_area_struct
vm_area_struct(简称VMA)描述了进程地址空间中一个连续的、具有相同访问权限和属性的区间(例如一个内存映射文件、一块堆空间或一个共享库)。
struct vm_area_struct {
unsigned long vm_start; // 区域起始地址(包含)
unsigned long vm_end; // 区域结束地址(不包含)
struct mm_struct *vm_mm; // 所属的地址空间描述符
pgprot_t vm_page_prot; // 该区域内页的访问权限
unsigned long vm_flags; // 区域标志(如VM_READ, VM_WRITE, VM_SHARED)
struct rb_node vm_rb; // 红黑树节点,用于在mm_rb中链接
// 链表和树结构,用于管理共享和私有映射
struct list_head anon_vma_node;
struct anon_vma *anon_vma;
// 操作函数集(例如处理缺页、销毁映射等)
const struct vm_operations_struct *vm_ops;
unsigned long vm_pgoff; // 在映射文件中的偏移(以页为单位)
struct file *vm_file; // 指向映射的文件对象(如果为文件映射)
// ... 其他字段
};
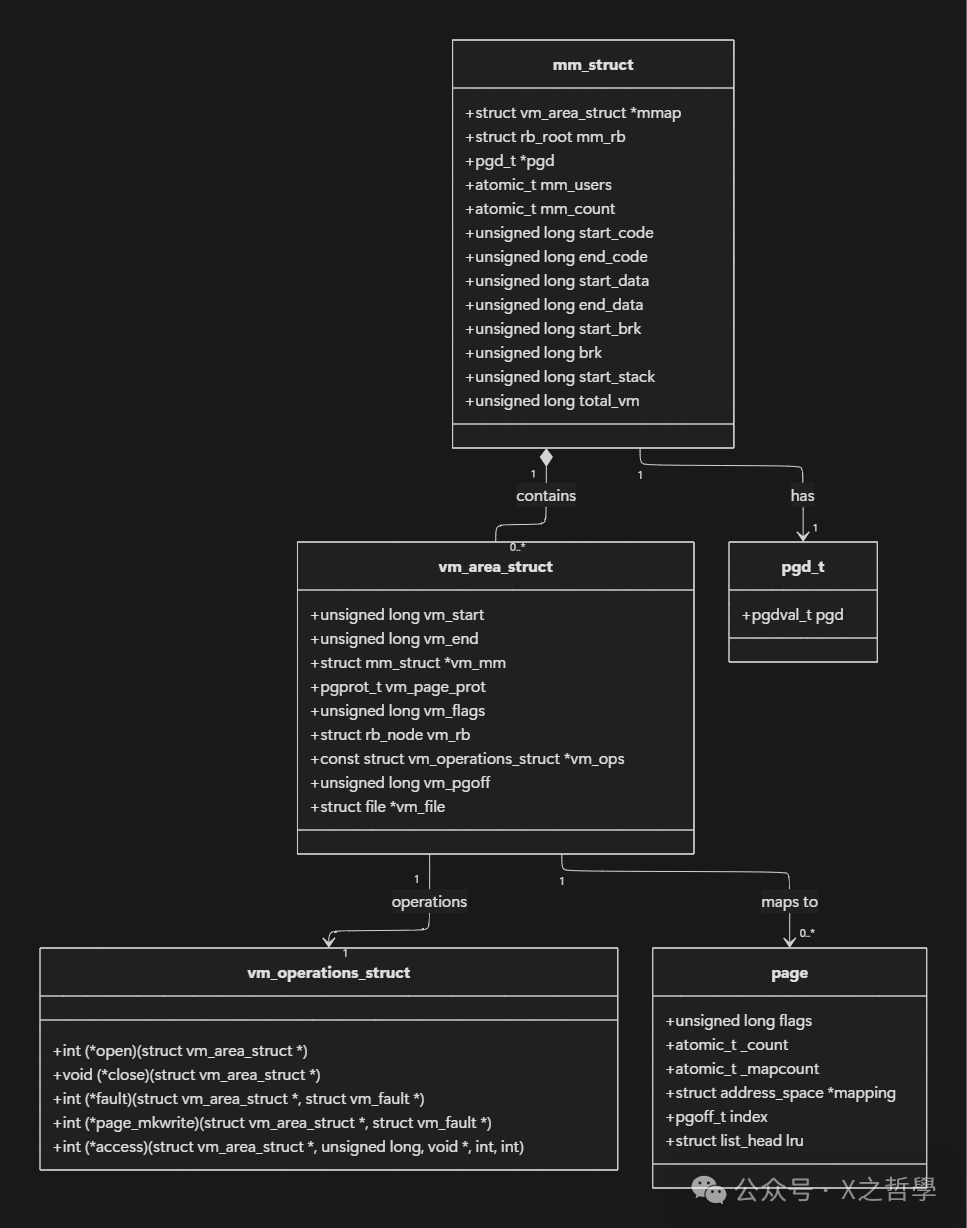
图4:mm_struct, vm_area_struct, vm_operations_struct 与物理页 page 之间的关系
3.3 页表层级结构
以x86_64架构为例,它使用四级页表管理48位虚拟地址空间。
// x86_64四级页表结构定义
typedef struct { pgdval_t pgd; } pgd_t; // 页全局目录
typedef struct { p4dval_t p4d; } p4d_t; // 页四级目录(在x86_64中通常等同于pgd)
typedef struct { pudval_t pud; } pud_t; // 页上级目录
typedef struct { pmdval_t pmd; } pmd_t; // 页中间目录
typedef struct { pteval_t pte; } pte_t; // 页表项
// 地址分解宏(48位地址)
#define PG_DIR_SHIFT 39
#define P4D_SHIFT 39
#define PUD_SHIFT 30
#define PMD_SHIFT 21
#define PAGE_SHIFT 12 // 4KB页
#define PTRS_PER_PGD 512
#define PTRS_PER_P4D 512
#define PTRS_PER_PUD 512
#define PTRS_PER_PMD 512
#define PTRS_PER_PTE 512
// 页表遍历辅助宏:根据地址计算各级页表的索引
#define pgd_index(addr) (((addr) >> PG_DIR_SHIFT) & (PTRS_PER_PGD - 1))
#define p4d_index(addr) (((addr) >> P4D_SHIFT) & (PTRS_PER_P4D - 1))
#define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1))
#define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1))
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
第四章: 分页机制实现实例
4.1 页表遍历示例代码
以下是一个简化的函数,演示了如何通过软件遍历页表,将虚拟地址转换为物理地址。
/**
* 遍历页表查找虚拟地址对应的物理地址(简化示例,忽略锁和错误处理)
* @param mm 进程的内存描述符
* @param vaddr 要查找的虚拟地址
* @return 对应的物理地址,0表示查找失败或页面不存在
*/
unsigned long vaddr_to_paddr(struct mm_struct *mm, unsigned long vaddr) {
pgd_t *pgd; p4d_t *p4d; pud_t *pud; pmd_t *pmd; pte_t *pte;
struct page *page;
unsigned long paddr = 0;
pgd = pgd_offset(mm, vaddr);
if (pgd_none(*pgd) || pgd_bad(*pgd)) goto out;
p4d = p4d_offset(pgd, vaddr);
if (p4d_none(*p4d) || p4d_bad(*p4d)) goto out;
pud = pud_offset(p4d, vaddr);
if (pud_none(*pud) || pud_bad(*pud)) goto out;
if (pud_large(*pud)) { // 处理1GB大页
paddr = pud_pfn(*pud) << PAGE_SHIFT;
paddr |= vaddr & ~PUD_PAGE_MASK;
goto out;
}
pmd = pmd_offset(pud, vaddr);
if (pmd_none(*pmd) || pmd_bad(*pmd)) goto out;
if (pmd_large(*pmd)) { // 处理2MB大页
paddr = pmd_pfn(*pmd) << PAGE_SHIFT;
paddr |= vaddr & ~PMD_PAGE_MASK;
goto out;
}
pte = pte_offset_map(pmd, vaddr);
if (!pte_present(*pte)) goto unmap_out;
page = pte_page(*pte);
if (!page) goto unmap_out;
paddr = page_to_phys(page);
paddr |= vaddr & ~PAGE_MASK;
unmap_out:
pte_unmap(pte);
out:
return paddr;
}
4.2 创建页表映射示例
此函数展示了如何在页表中建立一个新的映射。
/**
* 建立虚拟地址到物理地址的页表映射
* @param mm 进程内存描述符
* @param vaddr 虚拟地址
* @param paddr 物理地址
* @param prot 页面保护权限
* @return 成功返回0,失败返回错误码
*/
int map_page(struct mm_struct *mm, unsigned long vaddr,
unsigned long paddr, pgprot_t prot) {
pgd_t *pgd; p4d_t *p4d; pud_t *pud; pmd_t *pmd; pte_t *pte, entry;
int ret = 0;
// 逐级获取页表项,若不存在则分配新页表
pgd = pgd_offset(mm, vaddr);
if (pgd_none(*pgd)) {
if (p4d_alloc(mm, pgd, vaddr)) return -ENOMEM;
}
// ... 类似地为 p4d, pud, pmd 检查并分配
pmd = pmd_offset(pud, vaddr);
if (pmd_none(*pmd)) {
if (pte_alloc_map(mm, pmd, vaddr)) return -ENOMEM;
}
// 创建页表项
pte = pte_offset_map(pmd, vaddr);
if (pte_present(*pte)) { // 映射已存在
ret = -EBUSY;
goto out;
}
entry = pfn_pte(paddr >> PAGE_SHIFT, prot); // 组合物理页帧号和权限
set_pte_at(mm, vaddr, pte, entry); // 写入页表项
flush_tlb_page(vaddr); // 刷新TLB,使新映射生效
out:
pte_unmap(pte);
return ret;
}
第五章: 性能优化与高级特性
5.1 转换后备缓冲区(TLB)
TLB是页表转换的硬件缓存,用于加速虚拟地址到物理地址的转换。理解TLB行为对优化程序内存访问模式至关重要。
TLB管理策略:
- 局部刷新:当修改单个页表项时(如取消映射),只刷新与该页相关的TLB条目(例如使用
invlpg指令)。
- 全局刷新:在进程上下文切换时,可能需要刷新所有非全局(non-global)TLB条目(通过加载新的CR3)。
- 延迟刷新:使用地址空间标识符(ASID) 或 进程上下文标识符(PCID) 来标记TLB条目属于哪个进程,从而在上下文切换时避免不必要的TLB刷新。
// 上下文切换时加载新地址空间
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk) {
if (likely(prev != next)) {
// 加载新进程的页目录基址到CR3
load_cr3(next->pgd);
// 如果CPU支持PCID,可以进一步优化TLB管理
if (static_cpu_has(X86_FEATURE_PCID)) {
load_current_id(); // 加载当前进程的PCID
}
}
}
5.2 反向映射(Reverse Mapping)
反向映射机制是为了解决“给定一个物理页,快速找到所有映射了它的虚拟地址”的问题。这对于页框回收、迁移和交换操作至关重要。
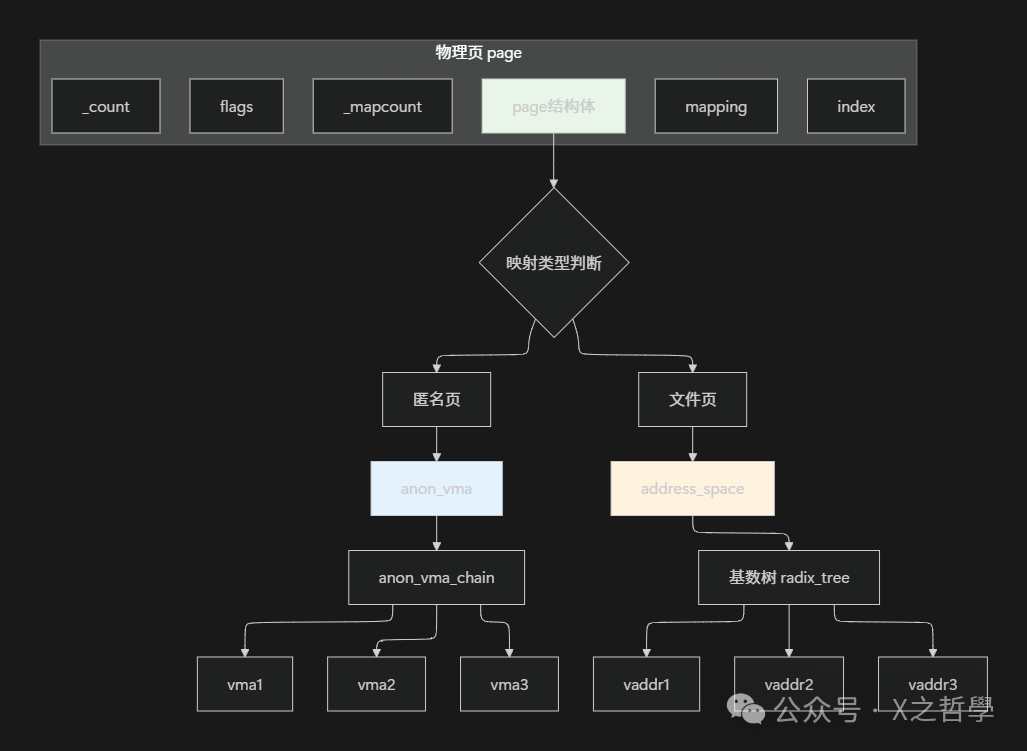
图5:物理页page的反向映射结构,用于区分匿名页与文件页,并找到所有映射此页的VMA
5.3 页面回收与交换
Linux内核使用复杂的LRU算法和交换机制来应对内存压力。当空闲内存低于阈值时,内核的“kswapd”线程或直接回收路径会被触发,尝试回收一些页面。
// 页面回收逻辑的极度简化示意
static unsigned long shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc) {
LIST_HEAD(free_pages);
unsigned long nr_reclaimed = 0;
struct page *page;
while (!list_empty(page_list)) {
page = lru_to_page(page_list);
list_del(&page->lru);
if (!trylock_page(page)) continue;
// 检查页面状态:是否为脏页、是否正在回写等
if (PageDirty(page)) {
// 将脏页写回磁盘
int result = pageout(page, page->mapping);
if (result == PAGE_KEEP) goto keep_locked;
}
// 如果是匿名页,尝试加入交换缓存
if (PageAnon(page) && !add_to_swap(page)) goto activate_locked;
// 关键步骤:通过反向映射解除所有PTE对该物理页的映射
if (page_mapped(page) && !try_to_unmap(page, TTU_UNMAP)) {
goto activate_locked;
}
// 从页面缓存或匿名链表中彻底移除,并放入空闲列表
__remove_mapping(page->mapping, page, true);
list_add(&page->lru, &free_pages);
nr_reclaimed++;
continue;
activate_locked:
// 激活页面,将其移出不活跃列表
unlock_page(page);
list_add(&page->lru, &page_list);
continue;
keep_locked:
unlock_page(page);
}
// 批量释放已回收的页面到伙伴系统
free_hot_cold_page_list(&free_pages, true);
return nr_reclaimed;
}
第六章: 调试与性能分析工具
6.1 常用调试命令
# 1. 查看进程内存映射布局
cat /proc/self/maps # 查看当前进程
cat /proc/<pid>/maps # 查看指定进程
pmap -x <pid> # 更详细的内存映射报告
# 2. 查看系统内存状态
cat /proc/meminfo # 内存统计摘要(包括Swap、缓存、大页等)
cat /proc/vmstat # 更详细的内核内存事件统计
# 3. 查看大页使用情况
cat /proc/meminfo | grep -i huge
# 4. 使用perf跟踪缺页异常
perf record -e page-faults -a -g -- sleep 5
perf report
6.2 内核调试技巧
// 在内核代码中添加调试打印(缺页示例)
static void debug_page_fault(unsigned long address, unsigned long error_code) {
printk(KERN_DEBUG "Page fault at 0x%lx, error_code: 0x%lx\n", address, error_code);
printk(KERN_DEBUG "CR2: 0x%lx\n", read_cr2());
if (current) {
printk(KERN_DEBUG "Process: %s (pid: %d)\n", current->comm, current->pid);
}
}
6.3 性能分析工具
| 工具名称 |
主要功能 |
使用场景 |
优点 |
| perf |
性能事件采样、统计 |
CPU性能剖析、缓存命中率分析、缺页统计 |
功能强大、系统开销小、Linux原生支持 |
| ftrace |
内核函数调用跟踪 |
分析内核函数执行路径、耗时 |
内置跟踪框架,无需额外模块 |
| eBPF/bpftrace |
动态、可编程跟踪 |
实时监控、自定义指标统计、安全审计 |
灵活性极高,性能开销低,安全 |
| SystemTap |
动态跟踪与探测 |
复杂的内核或用户空间行为分析 |
提供脚本语言,功能丰富 |
| Valgrind |
内存调试与分析 |
检测内存泄漏、越界访问(用户空间) |
对用户态程序检测非常准确 |
# 使用bpftrace快速统计缺页异常
bpftrace -e 'kprobe:handle_mm_fault { @[comm] = count(); }'
# 使用perf stat统计程序运行时的TLB和缓存表现
perf stat -e page-faults,dtlb-load-misses,dtlb-store-misses,cache-misses ./your_program
第七章: 实际应用案例
7.1 内存映射文件示例
内存映射文件是分页机制的典型应用,它允许程序像访问内存一样访问文件。
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
if (argc < 2) return 1;
int fd = open(argv[1], O_RDONLY);
struct stat sb;
fstat(fd, &sb);
// 将文件映射到进程地址空间,但尚未分配物理页
char *mapped = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (mapped == MAP_FAILED) { perror("mmap"); return 1; }
// 首次访问文件内容会触发缺页异常,内核按需从磁盘加载数据页
printf("File size: %ld bytes\n", sb.st_size);
printf("First byte: %c\n", mapped[0]); // 触发缺页,加载第一页
// 访问文件另一部分,可能触发新的缺页加载其他数据页
if (sb.st_size > 4096) {
printf("Byte at offset 4096: %c\n", mapped[4096]);
}
munmap(mapped, sb.st_size);
close(fd);
return 0;
}
工作原理:
- 建立映射:
mmap()仅在进程的VMA链表中创建一个新的区域,记录文件偏移和权限,并不立即分配物理内存或读取文件。
- 延迟加载:当进程首次访问该映射区域的某个地址时,触发缺页异常。
- 按需加载:内核的缺页处理程序识别出这是文件映射缺页,于是从磁盘读取对应的文件块到一个物理页框中,并建立页表映射。
- 页面缓存:读取的文件内容会留在内核的页面缓存中,后续其他进程访问同一文件部分时可直接复用,无需再次读盘。
7.2 自定义内存分配器
理解分页机制后,可以实现一个基于页的简单内存分配器。
// 一个极简的、基于预分配内存池的分配器示例框架
#include <sys/mman.h>
#define POOL_SIZE (1024*1024*10) // 10MB 内存池
static void *mem_pool = NULL;
void mem_init() {
// 使用 mmap 匿名映射分配一大块连续虚拟内存
mem_pool = mmap(NULL, POOL_SIZE, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 在此内存池上实现自己的块管理逻辑(如链表、位图)
}
void *my_malloc(size_t size) {
// 在自己的内存池中查找和分配合适大小的块
// ...
}
void my_free(void *ptr) {
// 将块标记为空闲,可能合并相邻空闲块
// ...
}
void mem_cleanup() {
if (mem_pool) munmap(mem_pool, POOL_SIZE);
}
第八章: 总结与展望
8.1 分段与分页对比总结
| 特性维度 |
分段机制 |
分页机制 |
| 划分单位 |
逻辑单元(代码段、数据段等) |
固定大小的页(如4KB) |
| 地址空间 |
二维地址(段选择符 + 偏移量) |
一维线性地址 |
| 碎片问题 |
产生外部碎片 |
仅有内部碎片(页内浪费) |
| 保护机制 |
段级保护(读/写/执行权限,特权级) |
页级保护(读/写/执行权限,用户/内核态) |
| 实现复杂度 |
硬件支持要求高,管理复杂 |
相对简单,通用性强,被多数现代OS采用 |
| 在Linux中的角色 |
被弱化,主要用于权限隔离(内核/用户态)和兼容性 |
核心的虚拟内存管理机制 |
| 主要优点 |
符合程序逻辑视图,便于模块化保护 |
高效管理物理内存,消除外部碎片,简化交换 |
| 主要缺点 |
易产生内存碎片,不灵活,移植性差 |
页表可能占用大量内存,TLB管理复杂 |
8.2 现代内存管理发展趋势
- 异构内存系统:随着非易失性内存、高性能显存等不同特性的内存介质出现,操作系统需要更智能地管理数据在不同介质间的放置和迁移。
- 安全增强:
- 内存标签扩展:为每次内存访问增加标签检查,防御缓冲区溢出等漏洞。
- 影子栈:保护函数返回地址,防御ROP攻击。
- 虚拟化优化:
- 大页自动化与智能化:
- 透明大页的决策算法更加智能,能更好平衡大页带来的TLB收益和内存浪费(内部碎片)风险。
8.3 核心要点回顾
- 互补而非对立:分段与分页在历史上是两种不同的内存管理方案,在现代x86架构上硬件同时支持两者,Linux巧妙地结合了它们(分段用于权限基础,分页用于物理管理)。
- Linux的务实选择:出于可移植性和简化性的考虑,Linux采用“扁平分段”模型,实质上绕过了分段在地址转换中的作用,将分页作为虚拟内存管理的绝对核心。
- 按需分页是虚拟内存的灵魂:程序可以运行在比物理内存大得多的地址空间上,这得益于“缺页异常”机制和页面交换技术,只有被真正访问的页面才会占用物理内存。
- 性能与空间的永恒权衡:多级页表是为了节省页表本身占用的内存空间,但增加了地址转换的步骤;TLB正是为了加速这个多步转换过程而存在的硬件缓存。
- 管理的复杂性:高效的内存管理远不止地址转换,还包括页面回收、交换、反向映射、内存压缩等一系列复杂机制,共同构成了现代操作系统内存子系统的基石。
 发表于 2025-12-30 20:54:28
|
查看: 299|
回复: 0
发表于 2025-12-30 20:54:28
|
查看: 299|
回复: 0
