一、XDP 技术概览
1.1 XDP 诞生的技术背景
如今,10G、40G乃至100G的高速网卡已很常见,但很多开发者会发现,带宽上去了,Linux系统处理数据的速度却没跟上来。核心症结在于Linux内核协议栈在处理海量数据包时显得“力不从心”——其处理逻辑繁复,如同一条狭窄的巷子,即使有再多的数据流,也只能缓慢通过,直接成为网络性能的瓶颈。
为了解决这一瓶颈,内核旁路(Kernel Bypass)技术应运而生。通俗地讲,就是为数据包开辟一条“绿色通道”,跳过复杂的内核协议栈,直接交由用户程序处理,减少中间环节,性能自然得到提升。
而XDP,正是Linux内核旁路技术中的“尖子生”。相较于另一种流行的方案DPDK,XDP最大的优势在于其深度融入Linux原生生态,无需复杂的额外环境适配,相当于为Linux量身定制的高性能工具,上手和部署都更为便捷,这也是近年来它愈发受到关注的原因。
1.2 到底什么是 XDP?
XDP,全称 eXpress Data Path(快速数据路径),是一项基于 eBPF(Extended Berkeley Packet Filter)机制的Linux内核技术。它就像一位驻守在内核网络驱动层的“高速数据处理员”,能够在数据包进入系统的最早阶段对其进行高性能处理和转发。通过巧妙利用eBPF的强大能力,XDP实现了对网络数据流的早期干预。
XDP为用户提供了一个极为灵活的编程接口,这好比为开发者开辟了一个“网络可编程实验室”。在这个“实验室”里,开发者可以根据实际需求,自由编写自定义的网络功能,无论是精准的流量过滤、高效的转发策略,还是复杂的网络监控与分析,XDP都能胜任。相比传统的用户空间包处理方式,XDP如同一位短跑冠军,能显著降低处理延迟,同时像节能大师一样,有效降低CPU占用率。
1.3 XDP 核心价值与适用场景
XDP的核心价值体现在三个关键维度。首先,它能大幅提升网络性能,面对海量数据时,XDP高效的处理机制如同拓宽了网络“高速公路”,避免拥堵。其次,它在降低延迟方面表现卓越,对于实时通信、在线游戏等对时效性要求苛刻的场景至关重要。最后,它能有效降低CPU占用,将系统资源从繁重的包处理任务中解放出来。
基于这些特性,XDP的应用场景非常广泛。例如,在DDoS防御中,它能快速识别并丢弃恶意流量,相当于为服务器安装了一个“高速防火墙”;日常的防火墙、负载均衡功能也能借助XDP获得效率提升;此外,在数据中心进行流量调度时,XDP能从容应对突发性的流量高峰。
二、AF_XDP 核心工作原理
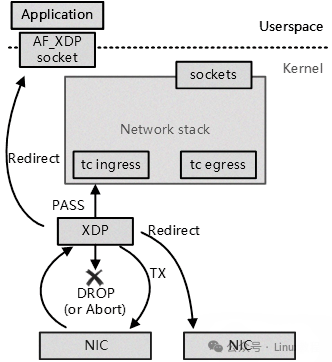
在深入了解AF_XDP之前,首先要明确它在XDP技术体系中的定位。AF_XDP,是XDP技术的一种关键应用,是一种专为实现高性能网络数据收发而设计的Linux socket。它犹如一座桥梁,连接用户程序与网络数据,其设计绕过了复杂的内核协议栈,极大减少了数据处理的中间环节,从而显著提升性能。
2.1 AF_XDP 整体架构设计
AF_XDP的整体架构设计精巧,需要与XDP程序紧密配合。XDP程序就像一个智能的网络数据筛选器,依据MAC地址、五元组等信息对数据包进行过滤和重定向。只有经过筛选的数据包,才会被传递给AF_XDP进行后续处理。
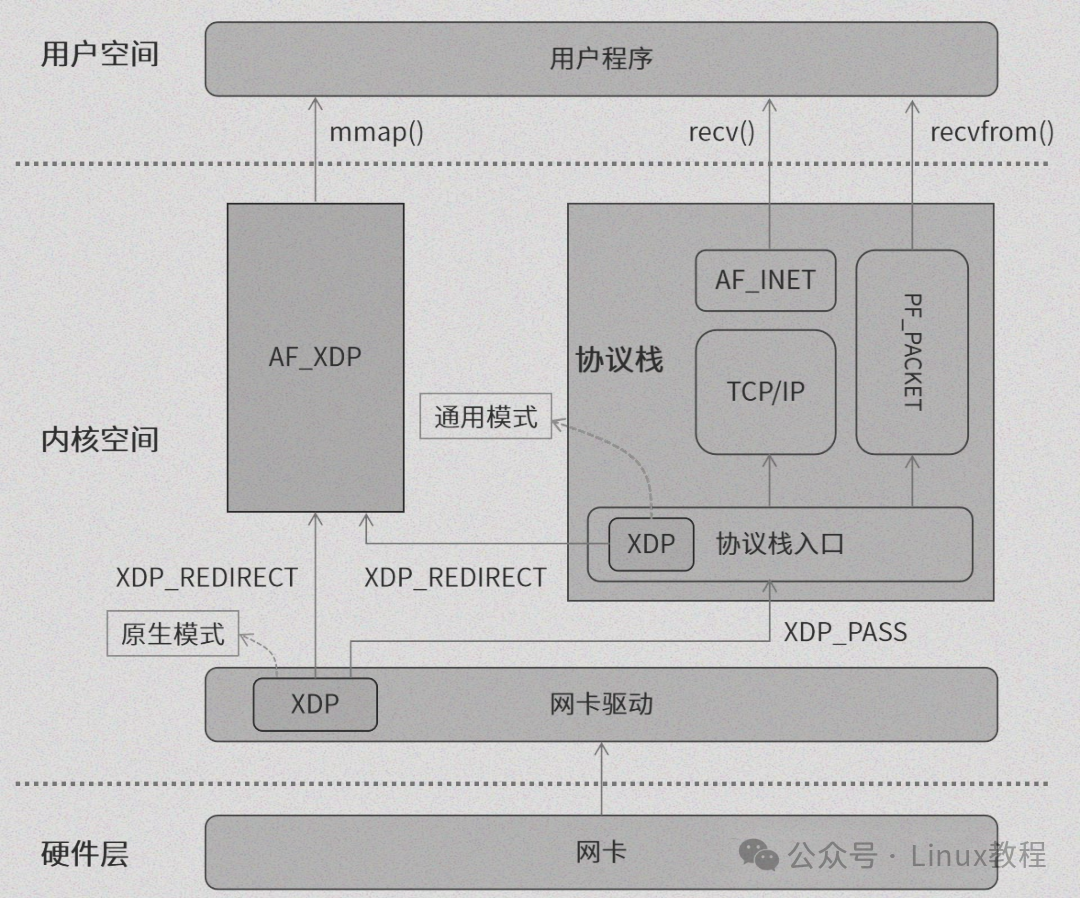
在此架构中,用户程序、AF_XDP和XDP共同操作一个至关重要的共享内存区域——UMEM(用户空间内存)。UMEM如同数据交换的“中央仓库”,收发数据包都暂存于此。而整个数据包的收发过程,则依赖于4个无锁环形队列的高效协同。
2.2 UMEM 共享内存机制
UMEM共享内存通过 setsockopt 函数申请。这如同在内存中划出一片专属区域,供用户程序和内核共享。UMEM通常以4K大小为一个单元(frame),每个单元可存储一个数据包。一个典型的UMEM可能包含4096个这样的单元。
用户程序和内核均可直接操作UMEM内存区域。这意味着在收发数据包时,仅需简单的内存拷贝,无需复杂的系统调用,效率极高。不过,用户程序需要负责维护UMEM的使用记录,并为其分配一个相对地址,以便快速定位。
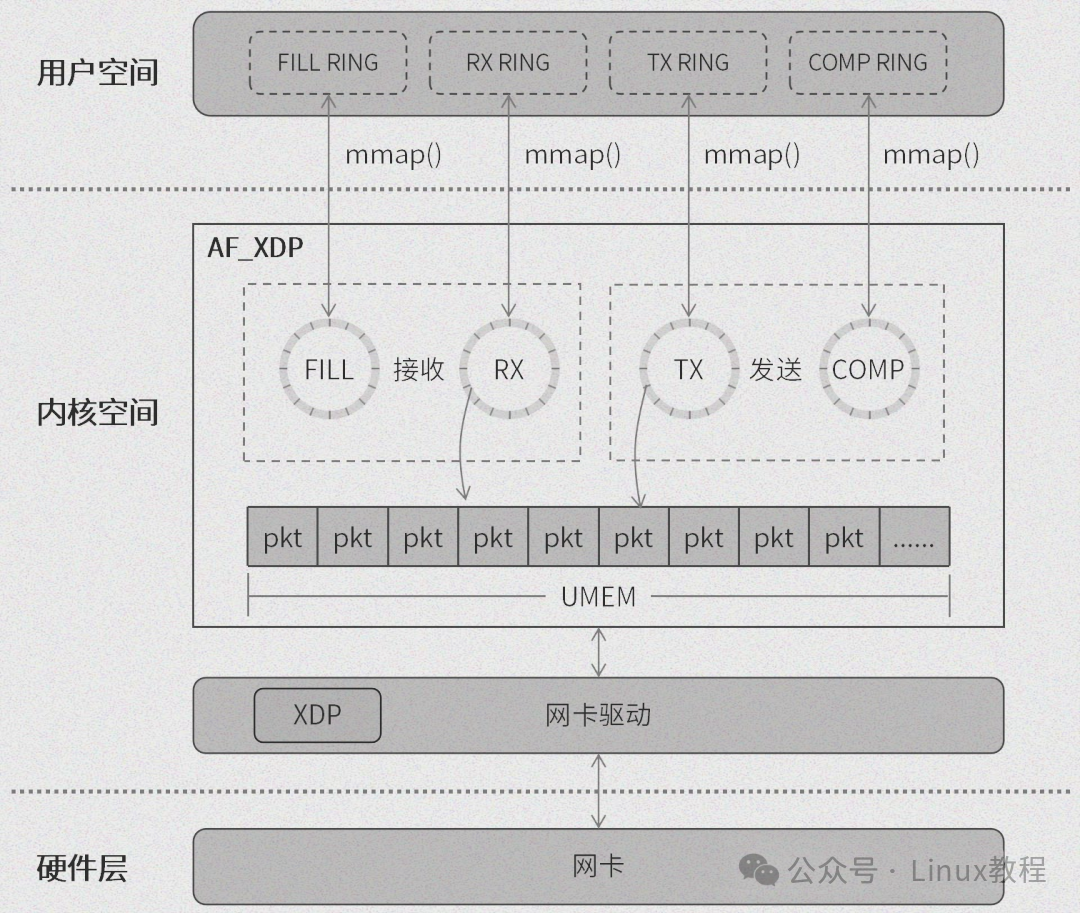
2.3 无锁环形队列实现
AF_XDP socket 包含4个分工明确的无锁环形队列。填充队列(FILL RING)如同“原料供应站”,为接收数据包提供可用的UMEM单元;完成队列(COMPLETION RING)如同“成品验收处”,标识内核已完成传输、可复用的数据包;发送队列(TX RING)是数据包的“出发站”;接收队列(RX RING)则是数据包的“终点站”。
这些环形队列通过 setsockopt 创建。以创建FILL RING为例:
setsockopt(fd, SOL_XDP, XDP_UMEM_FILL_RING, &umem->config.fill_size, sizeof(umem->config.fill_size));
环形队列本质上是对数组的封装,包含五个关键部分:生产者序号(producer)、消费者序号(consumer)、队列长度(len)、队列掩码(mask,值为 len-1)以及固定长度的数组。数组元素记录了UMEM单元的相对地址,若存有数据包,还会记录其长度。
2.4 AF_XDP 数据包接收流程
AF_XDP的数据包接收流程环环相扣:
- 填充可用单元:用户程序根据UMEM使用记录,将可用的UMEM单元地址填入FILL RING。
- 驱动接收与入队:XDP程序消费FILL RING中的地址,将接收到的数据包存入对应UMEM单元,然后将该单元地址和数据包长度信息填入RX RING。
- 用户程序消费:用户程序检测RX RING,消费其中的数据包信息,将数据从UMEM拷贝至自有缓冲区。处理完毕后,将该UMEM单元地址再次填回FILL RING,以接收新数据。
2.5 AF_XDP 数据包发送流程
发送流程同样高效有序:
- 用户程序准备:用户程序将待发送数据写入UMEM的某个单元。
- 通知内核发送:用户程序将该UMEM单元地址填入TX RING,以此通知内核有待发送数据。
- 内核发送与确认:内核消费TX RING,从指定UMEM单元读取数据并发送。发送完成后,内核将该UMEM单元地址填入COMPLETION RING,通知用户程序该单元已可复用。
三、XDP 三种工作模式详解
XDP有三种工作模式,并无绝对优劣,关键在于硬件条件和使用场景。开发者应根据实际情况选择,无需盲目追求最高性能。
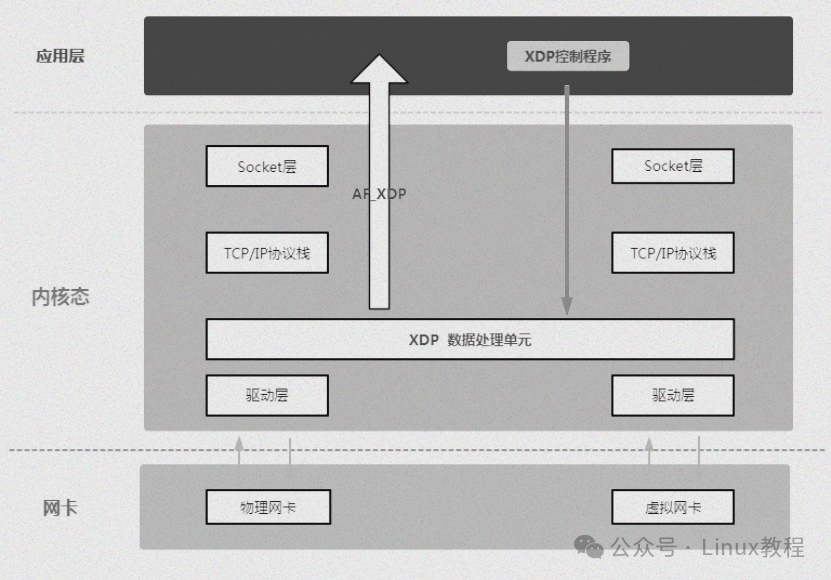
3.1 原生驱动模式 XDP_DRV
原生驱动模式(Native XDP)是XDP的默认模式。在此模式下,XDP BPF程序直接运行在网络驱动的早期接收路径中,如同站在数据入口的“第一道关卡”,性能表现极佳。
但其对网卡驱动有较高要求,并非所有驱动都支持。常见的如Intel的ixgbe、i40e系列以及Mellanox的mlx5_core驱动都提供了良好支持。可以使用 ethtool -i eth0 命令查看驱动信息,若输出中包含 supports-xdp: true,则表明支持该模式。
3.2 通用 SKB 模式 XDP_SKB
通用SKB模式(Generic XDP)兼容性极强。XDP程序运行在驱动之后、内核协议栈入口之前。其最大优点是不需要网卡驱动的专门支持,只要内核版本满足要求即可运行,门槛极低。
这种通用性是以性能为代价的。相比原生模式,它需要进行额外的操作(如分配套接字缓冲区SKB),因此性能较低,通常更适用于功能测试和验证场景。
3.3 硬件卸载模式 XDP_HW
硬件卸载模式(Offloaded XDP)代表了性能的极致追求。在此模式下,XDP BPF程序被直接卸载到网卡硬件中执行,数据包处理完全不占用主机CPU资源,性能最高。
然而,该模式对硬件要求极为苛刻,目前仅少数网卡支持,如Netronome的网络流处理器。因此,它通常只适用于对网络性能有极端要求且具备特定硬件的专业场景。
3.4 三种模式对比与切换验证
- 性能:XDP_HW > XDP_DRV > XDP_SKB。
- 硬件要求:XDP_HW要求最高(特定网卡),XDP_DRV次之(特定驱动支持),XDP_SKB要求最低(仅需内核支持)。
- 适用场景:XDP_HW用于极致性能场景;XDP_DRV用于大多数高性能生产环境;XDP_SKB用于测试、验证及兼容性场景。
模式切换可通过 iproute2 工具指定参数实现:
- 原生驱动模式:
ip link set dev eth0 xdpdrv obj xdp_pass_kern.o
- 通用SKB模式:
ip link set dev eth0 xdpgeneric obj xdp_pass_kern.o
切换后,可使用 iperf 等工具验证网络性能是否符合预期。
四、AF_XDP 核心组件:xsk 与 umem
4.1 xsk 与 umem 基础关系
在AF_XDP体系中,xsk与umem是两个核心组件,它们的紧密协作为高性能数据收发奠定了基础。
xsk(AF_XDP socket)是用户程序与网络数据交互的关键接口,如同一扇通往网络的“高速大门”。umem(用户空间内存)则是共享的“数据仓库”,用于暂存收发的数据包。xsk通过与umem协同,实现数据包的快速存取。
4.2 收发包队列体系设计
AF_XDP的高性能离不开其精巧的队列体系:FILL RING(供)、COMPLETION RING(完)、TX RING(发)、RX RING(收)。这四个无锁环形队列相互协作,形成高效的数据流水线。
4.3 BPF 相关核心 API
4.3.1 xsk/umem 操作 API
创建AF_XDP socket的基础API:
int sock = socket(AF_XDP, SOCK_RAW, 0);
if (sock < 0) {
perror("socket");
exit(EXIT_FAILURE);
}
配置并注册UMEM的示例:
struct xsk_umem_config umem_config = {
.fill_size = 8192,
.comp_size = 2048,
.frame_size = 2048,
.frame_headroom = 2
};
struct xsk_umem *umem;
int ret = xsk_umem__create(&umem, buffer, size, &umem_config.fill, &umem_config.comp, &umem_config);
if (ret) {
perror("xsk_umem__create");
return ret;
}
ret = setsockopt(sock, SOL_XDP, XDP_UMEM_REG, umem, sizeof(*umem));
if (ret) {
perror("setsockopt XDP_UMEM_REG");
xsk_umem__destroy(umem);
return ret;
}
4.3.2 队列交互与控制 API
操作环形队列的API示例(以填充FILL RING为例):
uint32_t idx;
int ret = xsk_ring_prod__reserve(&umem->fq, num_elements, &idx);
if (ret != num_elements) {
perror("xsk_ring_prod__reserve");
return ret;
}
for (int i = 0; i < num_elements; i++) {
*xsk_ring_prod__fill_addr(&umem->fq, idx + i) = element_address;
}
xsk_ring_prod__submit(&umem->fq, num_elements);
类似的,xsk_ring_cons__peek 和 xsk_ring_cons__pop 等API用于从RX/TX队列中消费数据。
五、AF_XDP 高性能的底层秘密
AF_XDP卓越性能的背后,是一系列底层技术的强力支撑。
5.1 零拷贝与内核旁路
传统网络中,数据包需在用户态与内核态间多次拷贝。AF_XDP通过零拷贝机制,让数据包经由DMA直接进入用户空间预分配的UMEM,避免了拷贝开销。同时,其实现的内核旁路技术,让数据包绕过复杂的协议栈,由用户程序直接处理,极大提升了效率。
5.2 无锁并发设计
传统并发编程中的锁竞争是性能杀手。AF_XDP的四个核心环形队列均采用无锁设计,利用CAS等原子指令实现安全高效的并发访问,允许多个线程/进程并行处理数据,充分发挥多核优势。
5.3 轻量级报文处理路径
AF_XDP的XDP程序运行在驱动层,处理路径极其轻量。它能在数据包进入系统的最早时刻,根据预设规则进行快速决策(如过滤、转发),省去了传统协议栈逐层解析的开销。
5.4 与传统协议栈的性能差异
实测数据清晰展示了性能差距。在吞吐量上,AF_XDP可达传统协议栈的数倍,更能逼近物理带宽极限。在延迟上,AF_XDP可将延迟从几十微秒降低至几微秒甚至更低。在CPU占用率上,AF_XDP也能显著降低CPU负载,释放资源给其他任务。
六、XDP 实践与总结
6.1 基础使用要点
理论学习后,上手实践需注意几个关键点,避免踩坑:
- 环境准备:内核版本建议5.0+,使用
ethtool -i eth0 确认网卡驱动支持XDP。
-
编写XDP程序:遵循eBPF规范,从简单程序开始。例如,一个丢弃所有包的XDP程序:
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_tracing.h>
SEC("xdp")
int xdp_drop_all(struct xdp_md *ctx)
{
return XDP_DROP; // 丢弃所有数据包
}
char _license[] SEC("license") = "GPL";
- 编译与加载:
- 编译:
clang -O2 -target bpf -c xdp_drop_all.c -o xdp_drop_all.o
- 加载:
ip link set dev eth0 xdp obj xdp_drop_all.o sec xdp
- 卸载:
ip link set dev eth0 xdp off
- AF_XDP收发包:重点配置UMEM及队列大小,需根据业务流量调整,避免过小丢包或过大浪费内存。收发过程中要及时回收UMEM单元,防止内存泄漏。
6.2 技术局限与优化方向
XDP虽强,亦有局限:
- 无缓存队列:应对突发流量时可能因处理不及而丢包。
- 对IP分片不友好:处理分片数据包时可能出错。
- 程序专用性强:为特定场景(如DDoS防御)编写的程序,改造成其他用途(如负载均衡)成本较高。
相应的优化与研究热点包括:在用户空间实现缓存机制应对突发流量;开发专门的IP分片预处理模块;探索通用化的XDP编程框架以提升开发效率。未来,XDP可能与AI/ML结合实现智能流量分析,并持续完善对复杂网络协议和场景的支持。
希望这篇关于XDP与AF_XDP的深度解析,能帮助你在Linux内核高性能网络编程的道路上更进一步。如果你想与更多开发者交流网络编程或内核技术,欢迎来到云栈社区探讨。
 发表于 2026-2-26 03:19:52
|
查看: 200|
回复: 0
发表于 2026-2-26 03:19:52
|
查看: 200|
回复: 0
