不知道你有没有这样的经历:翻看一张几十年前的老照片,虽然上面满是噪点、颜色也失真了,但你依然能感受到画面里那份真挚的情感,并觉得“这张照片真好”。
或者,当你看到一张被过度美颜、磨皮到五官模糊的自拍时,即使没有原图对比,你也能立刻判断出“这图P过头了,质量不行”。
你靠的是什么?不是旁边摆着一张完美无瑕的“标准答案”,而是你大脑里多年积累下来的视觉经验库。这个库里有你看过的无数清晰与模糊、自然与失真的画面,像一个内部“记忆库”,让你能在没有参考的情况下做出质量判断。
这个简单的日常现象,恰恰是当前 AI 进行 图像质量评估 时面临的巨大挑战。现有的顶级方法,大多严重依赖一张完美的“参考图”,一旦参考图不完美或者干脆没有,AI 就会懵圈。这在图像压缩、传输、修复等真实场景中,局限性很大。
现在,一项发表在 IEEE 上的新研究从认知心理学中汲取灵感,为 AI 引入了“记忆”机制。这项名为 MQAF (Memory-driven Quality-Aware Framework) 的工作,让我们离让 AI “像人一样”评估图像质量的目标,又近了一大步。
打破参考依赖:记忆如何让 AI 像人一样评估图像质量?
在深入了解 MQAF 之前,我们先快速搞懂两种图像质量评估的基本模式:
全参考图像质量评估:就像考试有标准答案。有一张完美的原图作为参考,然后拿待评测的失真图去对比,计算它们之间的差异。差异越小,失真图质量越高。这种方法精度高,但前提是“标准答案”必须完美无缺。
无参考图像质量评估:就像开卷考试没答案。直接看一张图,就判断它质量好不好。这非常难,因为缺乏直接的比较基准。现有方法要么试图从失真图中“脑补”出一张伪参考图,要么直接学习失真特征和主观评分的映射。
现实世界很骨感:完美的参考图往往是奢侈品。图像在网络上传输会压缩,存储久了会老化,这时候,依赖完美参考图的方法就不好用了。而纯粹的无参考方法,精度又往往比不上有参考的方法。
论文作者们观察到了一个关键点:人脑不是这么干的!我们之所以能无参考评估质量,是因为我们大脑里有一个不断更新的视觉记忆库。这个库里存储着各种类型的失真模式。当看到一张新图时,我们的大脑会快速将其与记忆库中的模式进行匹配和比较,从而形成一个质量感知。
受此启发,MQAF 的核心思想就是:给 AI 模型也造一个可学习的“记忆库”,用来存储典型的失真模式特征。 这个记忆库不是静态的,它会在训练中不断更新和优化。有了它,模型就能在一定程度上摆脱对单一完美参考图的绝对依赖。

双模切换:一个框架如何搞定有无参考两种场景?
MQAF 最巧妙的设计之一就是它的 “双模”自适应能力。它可以根据参考图是否可用,智能地切换评估策略,真正做到“进可攻,退可守”。整个框架流程如下图所示:
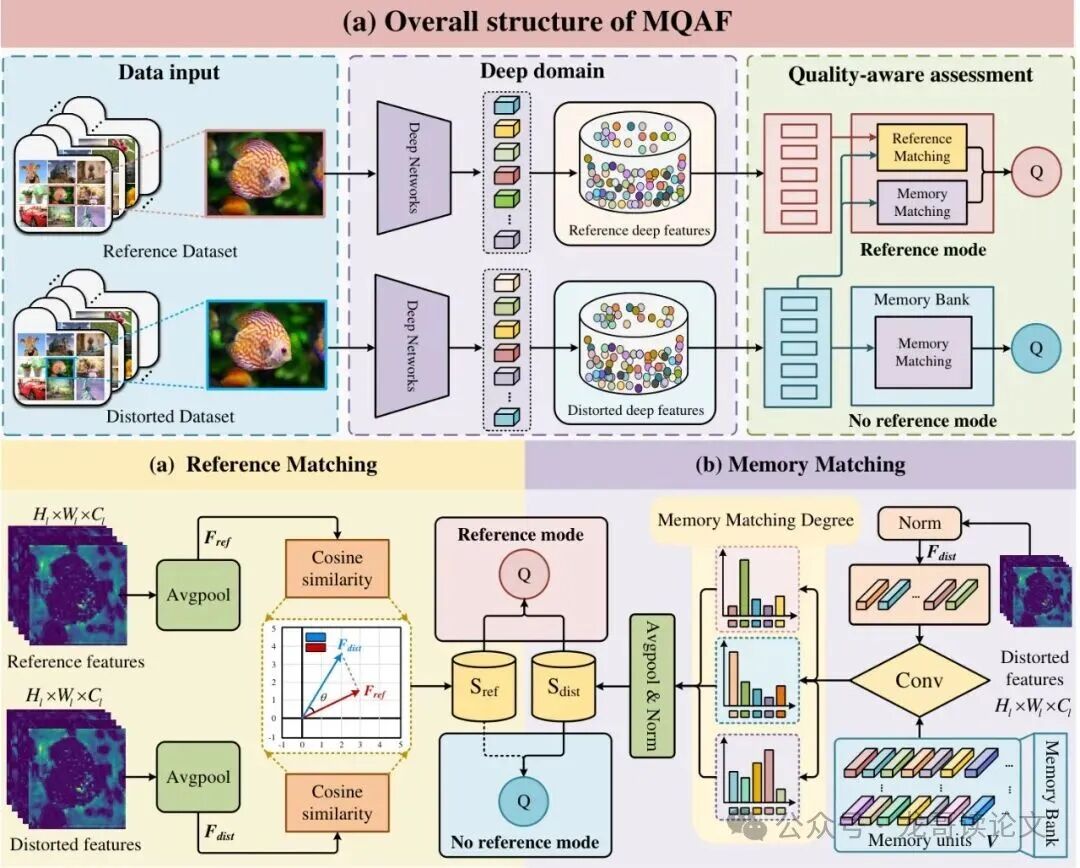
模式一:有参考模式 (MQAF-R)
当参考图存在时,模型同时进行两种匹配:
- 参考匹配:计算失真图和参考图在深度特征空间的距离(
S_ref),这是传统全参考方法的做法。
- 记忆匹配:将失真图与记忆库中存储的所有失真模式进行匹配,得到一个质量分数(
S_dist)。这相当于问问记忆库:“这张图看起来像哪种失真?程度如何?”
最后,不是简单地将两个分数相加,而是通过一个可学习的权重 α 进行自适应融合:
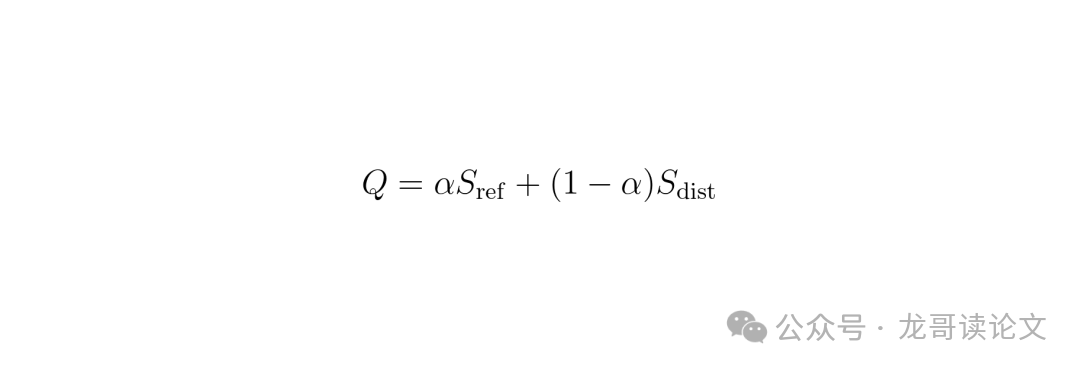
这个 α 非常智能!如果当前参考图质量很高,那么模型就会更信任参考匹配的分数(α 趋近于 1)。如果参考图本身也有问题,那么模型就会更多地依赖记忆匹配的分数(α 趋近于 0)。这样,即使参考图不完美,MQAF-R 也能通过记忆库进行“校准”,得到更稳健的评估结果。
模式二:无参考模式 (MQAF-NR)
当参考图完全缺失时,模型直接切换到纯记忆匹配模式,此时 α = 0,最终质量分数完全由记忆匹配分数 S_dist 决定。也就是说,模型完全依靠它“脑子”里学到的失真模式知识库来给图像打分。
一个框架,两套逻辑,无缝切换。这就是 MQAF 解决现实世界图像质量评估痛点的核心设计。
记忆库揭秘:失真模式如何被存储、匹配与更新?
上面一直提到的“记忆库”是 MQAF 的灵魂。它不是一个黑箱,而是一个显式的、可解释的数据结构。
记忆库的构成
你可以把它想象成一个表格,里面有 256 个“记忆单元”。每个单元存储了一个 2048 维的向量,这个向量代表了一种失真模式的原型特征。比如,可能有一个单元专门代表“严重的高斯模糊”,另一个单元代表“轻微的 JPEG 压缩块效应”。这些原型不是在设计时手动定义的,而是在训练过程中,模型从海量的失真图像数据中自动学习、聚类和总结出来的。
记忆匹配的魔法
当一张失真图输入进来,模型会先用一个深度学习特征提取网络提取其高级特征。然后,它用一种巧妙的方式进行匹配:将记忆库视为一个卷积核,对提取的失真特征进行“卷积”操作。这个操作的本质,是计算失真特征与每一个记忆单元的相似度。
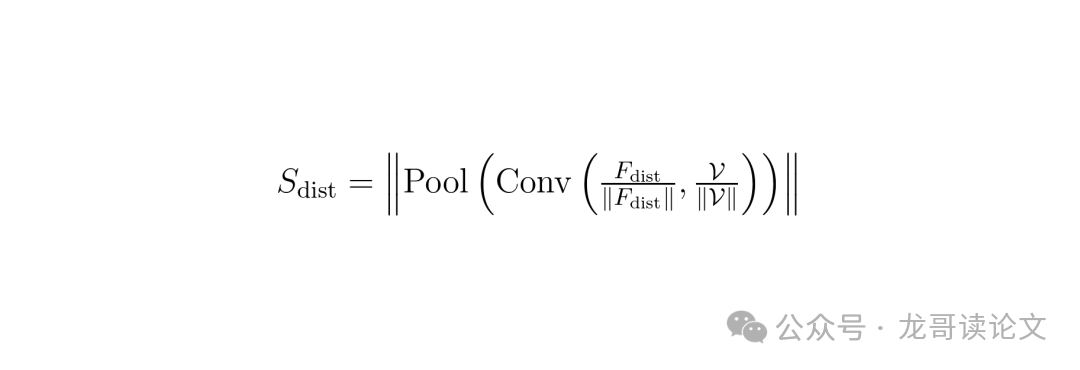
简单理解,就是模型拿着失真图的“指纹”,去记忆库的“指纹库”里快速比对了一圈,看看它跟哪些已知的失真类型最像,最后综合所有比对结果得出一个匹配分数。
让记忆库保持“清醒”
如果记忆库里的 256 个单元学到的特征都差不多,那这个库就没什么用了。为了避免这种情况,论文引入了一个 “记忆损失” 。这个损失函数的作用是降低不同记忆单元之间的相关性,鼓励它们去学习多样化、有区分度的失真模式。
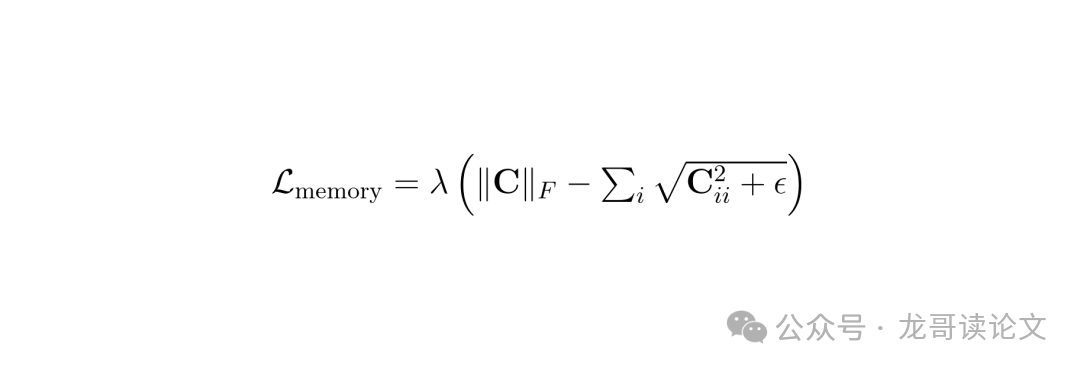
此外,还有用于学习自适应权重 α 的置信度损失,以及最基础的预测分数与真实主观分数之间的回归损失。这三个损失共同作用,驱动整个模型(包括记忆库)进行优化。
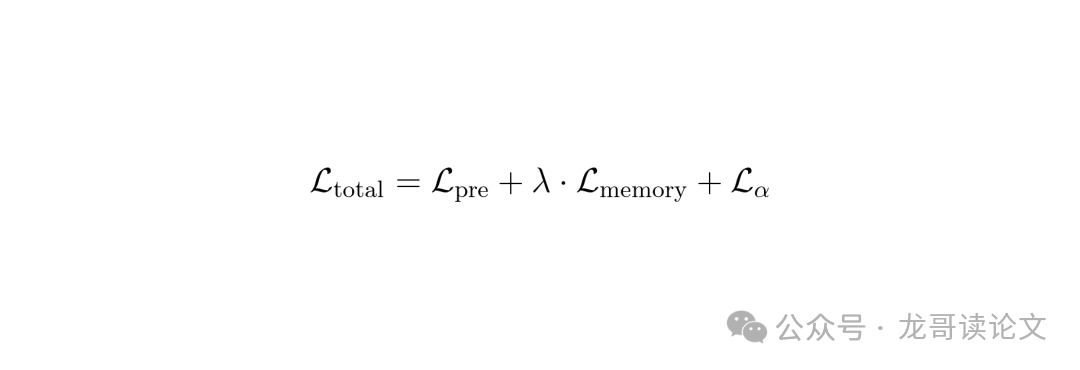
实验为王:MQAF 在各大基准上表现如何?
理论再好,也得看疗效。论文在多个权威的图像质量评估数据集上进行了详尽的测试。评价指标主要看两个:皮尔逊线性相关系数 和 斯皮尔曼等级相关系数。简单说,就是看模型打的分和人类感觉是否一致,以及排序是否正确。
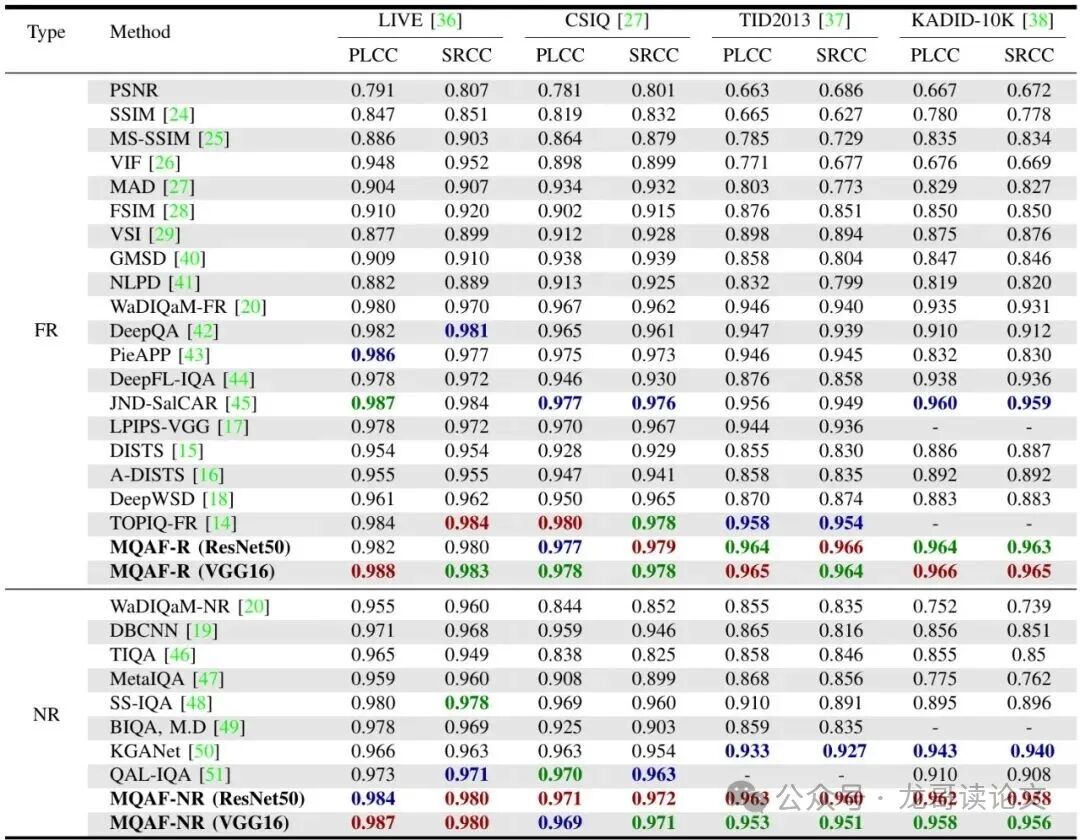
这张大表信息量很大!我们来划重点:
- MQAF-R 表现强悍:在几乎所有数据集和指标上,MQAF-R 都达到了第一或第二的水平,全面超越了许多知名的全参考方法。这说明即使在有完美参考图的理想情况下,引入记忆库进行协同评估,也能进一步提升精度。
- MQAF-NR 令人惊喜:更惊人的是,在无参考模式下,MQAF-NR 的性能竟然能够媲美甚至超越许多专门设计的无参考方法,并且在多个数据集上杀入了前三。这意味着,仅仅依靠记忆库,MQAF 就能达到专业无参考模型的水平。
- 双模优势尽显:一个模型,同时具备了顶级的全参考评估能力和一流的无参考评估能力。这在实用中是巨大的优势。
我们还可以通过散点图直观地感受一下 MQAF-R 的预测能力。下图展示了在 KADID-10K 数据集上,几种方法的预测分数与真实主观评分的分布。点越集中在对角线附近,说明预测越准。

超越指标:可视化与对抗竞赛中的真实战力
数字指标很高,但模型会不会是“高分低能”?为了进一步验证,论文进行了一项非常有趣的 “最小可觉差”竞赛。
这个竞赛的规则是这样的:从数据集中找出那些对于某个评估模型来说“最难区分”的图片对(即模型认为质量几乎一样,但事实上人类能看出细微差别)。然后用这个模型认为的“难兄难弟”图片对,去挑战另一个模型,看后者能否正确判断出哪张更好。这就像用 A 模型的“知识盲区”去考 B 模型,非常考验模型的鲁棒性和与人类感知的一致性。

结果非常直观!对于其他方法精心挑选出来的“难题”,MQAF-R 大部分都能做出正确判断。这说明 MQAF-R 的感知判断与人类更加吻合,不易被其他模型的盲区所误导,展现了更强的鲁棒性和可靠性。

论文核心问题解答
下面是对于大家可能的一些问题的解答:
这篇论文解决的核心问题是什么?
它主要解决了传统全参考图像质量评估方法对“完美参考图”的过度依赖问题。通过引入一个可学习的“记忆库”来存储失真模式,让模型能够像人一样借助“经验”进行评估,从而在有参考和无参考两种场景下都能实现高质量的评价,提升了方法的实用性和鲁棒性。
记忆库和普通的神经网络参数记忆有什么区别?
普通神经网络的参数在学习过程中也会“记忆”数据分布,但那是隐式的、黑箱的。MQAF 中的记忆库是一个显式的、结构化的存储。它由固定数量的记忆单元构成,每个单元代表一种学到的失真原型。这种设计使得模型在推理时可以主动、快速地从库中检索和匹配模式,不仅提高了效率,也增加了模型决策过程的可解释性。
自适应权重 α 是如何学习的?它真的有效吗?
α 是通过一个轻量的自适应权重网络生成的,其目标值由参考匹配分数和记忆匹配分数各自与真实质量分数的误差决定。哪个分数更接近真值,α 就会倾向于信任哪个分数。消融实验证明,使用自适应权重的模型性能稳定优于固定权重或仅使用单一分数的模型,这表明动态融合策略确实有效。
这项研究为计算机视觉领域的图像质量评估提供了一种降低参考依赖的新思路。其“记忆驱动”的思想非常具有启发性,可能会影响到未来多媒体处理技术的发展。如果你对 AI、图像质量评估或其他前沿技术感兴趣,欢迎到 云栈社区 与更多开发者交流探讨。
 发表于 2026-2-26 03:17:29
|
查看: 183|
回复: 0
发表于 2026-2-26 03:17:29
|
查看: 183|
回复: 0
