想象一下,你拿着一台能每秒拍摄10万张照片的相机,这速度足以看清子弹穿行的轨迹。但代价是,每张照片都漆黑一片,每个像素点可能只捕捉到零星的几个光子,充斥着雪花般的噪声和诡异的色彩斑块。这可不是科幻,这是单光子雪崩二极管(SPAD)传感器面临的现实。如何从这片“光子荒漠”中,重建出高清、色彩准确且时间连贯的视频,是计算成像领域的圣杯级难题。
就在最近,威斯康星大学麦迪逊分校和Snap公司的研究团队,把当下最火的大模型“王牌”——Stable Diffusion,成功地“嫁接”到了这个极限场景中,提出了名为 gQIR的方法。他们不仅让AI从几乎看不见的噪声中“画”出了清晰图像,甚至还能处理高速运动,重建出流畅的视频。这背后的技术巧思,堪称一场“教大模型理解量子世界”的精彩教学。
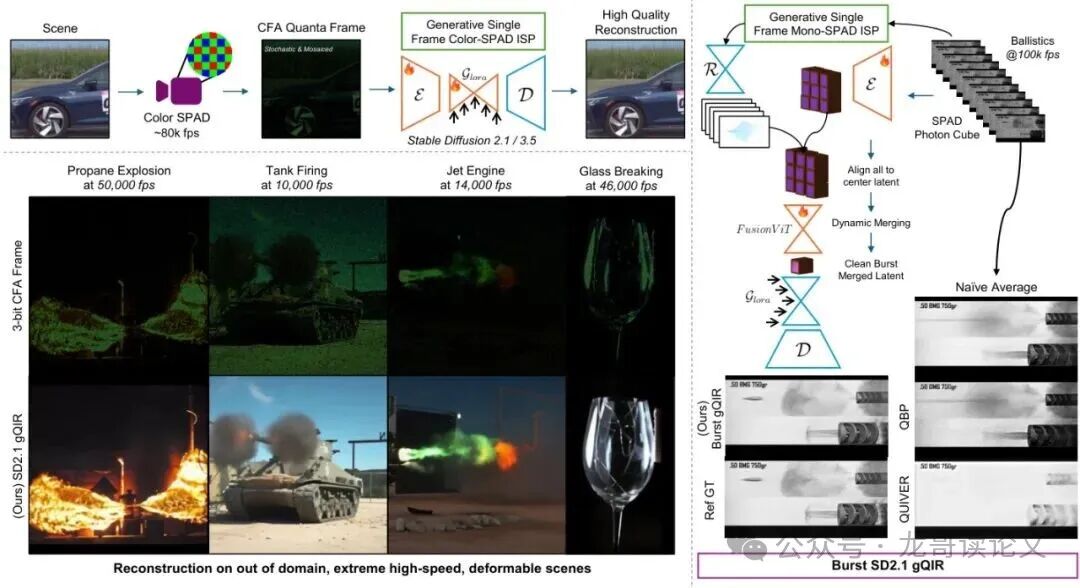
图1:gQIR从超高速彩色SPAD传感器中进行逼真单图像及序列重建。左:从3位彩色SPAD原始数据重建高质量RGB图像;右:将SPAD光子数据块合并为时间一致的序列。
当相机每秒捕捉十万帧:量子成像的极限挑战
首先,我们得搞清楚SPAD传感器和普通相机有啥根本不同。普通相机(比如你手机里的CMOS)记录的是连续的光强度,像素值可以是0到255之间的任意数字。而SPAD传感器工作在量子极限,它像个极其敏感的光子计数器,每个像素在极短的曝光时间内只回答一个“是非题”:有光子到达吗? 有,就记1;没有,就记0。
这就导致原始数据是二值的、稀疏的、充满泊松噪声的。为了获得更多信息,SPAD会以超高帧率(比如每秒数万甚至十万帧)连续拍摄,得到一长串0和1的“二进制帧”。把连续几个二进制帧叠加,就能得到一个“多比特”的帧(例如,7帧二值图叠加成一个3比特图,即0-7的整数)。这个过程被称为形成纳米爆发。
问题来了:
- 噪声极其“非主流”。这噪声不是普通相机那种高斯或泊松-高斯噪声,而是遵循伯努利分布。光子到达是随机的,导致图像信号极其微弱且不稳定。想象一下在一场暴风雪中试图看清路牌,大部分时间眼前都是雪花。
- 运动是“隐形杀手”。当拍摄高速运动物体时,相邻帧之间物体会发生位移。传统的光流算法需要清晰的图像特征来估计运动,但在SPAD的噪声图上,特征点几乎淹没在噪声里,运动估计直接失效。对齐做不好,后续的帧融合就会产生重影和模糊。
- 彩色是“地狱难度”。为了获得彩色信息,SPAD传感器前也需要加拜耳滤光片。这意味着每个像素只接收红、绿、蓝其中一种颜色的光子,本来就少得可怜的光子还被分到了三个通道,数据变得更加稀疏,去马赛克的难度呈指数级上升。
大模型直接上?NO!
这时候你可能想,现在大模型这么牛,直接把Stable Diffusion拿过来微调一下不行吗?答案是:不行,而且会死得很惨。大模型是在互联网海量清晰图像上训练的,它“认识”的是干净的、连续的自然图像。当你把一堆0和1、噪声比信号还强的SPAD数据塞给它时,它完全无法理解。简单微调的结果,往往是模型学到一个“作弊”的捷径:无视输入,直接输出一个模糊的平均图像,因为这样损失函数下降得最快。这被称为灾难性遗忘或捷径学习。

化繁为简:三阶段框架如何“教”AI从光子噪声中画画
gQIR的聪明之处在于,它没有蛮干,而是设计了一个循序渐进的三阶段教学课程,一步步引导大模型理解量子噪声,并最终完成高质量重建。整个过程就像教一个只会画油画的艺术家,如何去修复一张被墨水泼得一塌糊涂的草稿。
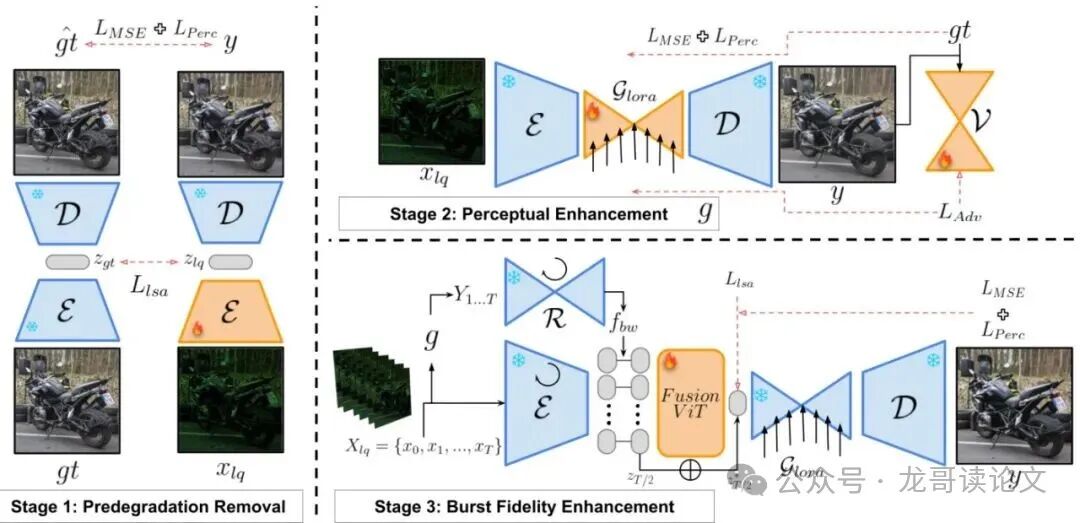
图2:gQIR三阶段框架总览。(S1)量子对齐VAE,用于SPAD纳米爆发的联合去噪与去马赛克;(S2)对抗性微调的LoRA潜在U-Net,用于感知增强;(S3)潜在爆发FusionViT,用于运动感知的时空融合。
第一阶段(S1):打好基础——“翻译官”VAE的对齐训练
Stable Diffusion这类潜扩散模型(Latent Diffusion Model, LDM)并非直接在像素上操作,而是先通过一个变分自编码器(Variational Autoencoder, VAE)把图像压缩到一个低维的潜空间。VAE包括一个编码器(把图像变潜码)和一个解码器(把潜码变回图像)。
第一阶段的目标,是训练VAE的编码器,让它学会把充满噪声的SPAD输入(3位纳米爆发),“翻译”成一个干净的潜码,这个潜码应该和从清晰真实图像编码得到的潜码尽可能接近。这样一来,后续的扩散模型U-Net接收到的就是一个已经初步“净化”过的信号,任务就轻松多了。
这个过程被称为退化预去除。但要小心,直接做会让编码器“学坏”,走捷径输出恒定值(如图4所示)。
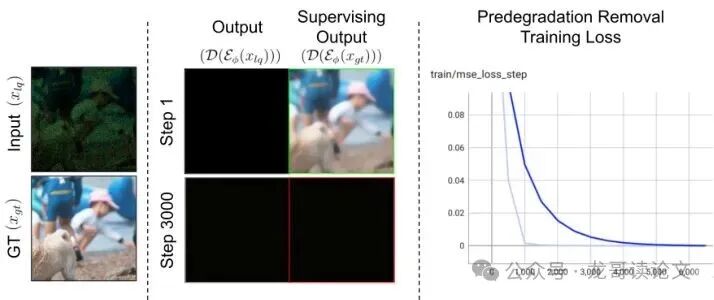
图4:在预退化去除损失下编码器的崩溃。编码器学会了一个无意义的捷径,从而产生恒定输出。
第二阶段(S2):提升质感——“美术老师”U-Net的对抗微调
经过第一阶段,我们得到了一个能产生结构正确但可能有点平淡(偏向MSE损失导致的平滑)的重建图像的流程。第二阶段的目标是增强感知质量,让图像看起来更锐利、更真实、细节更丰富。
这里用了一个巧妙的技巧:对抗性蒸馏。他们不直接使用需要多步迭代采样的原始扩散U-Net,而是用一个生成对抗网络(GAN)来训练一个单步生成器。这个生成器的网络权重用预训练的扩散U-Net初始化,并用LoRA(Low-Rank Adaptation,低秩适应)技术进行轻量级微调。同时,一个判别器负责判断生成的图像是否足够真实。
这样做的好处是:1. 速度快,单步生成,适合SPAD产生海量数据的需求。2. 质量高,对抗训练能逼出更生动的纹理和细节。
第三阶段(S3):稳定画面——“剪辑师”FusionViT的时空融合
前两个阶段处理的是单帧或纳米爆发。要处理视频序列,必须利用时间信息。传统量子爆发重建方法是“对齐然后合并”:先估计帧间运动(光流),把所有帧对齐到参考帧,然后取平均。
gQIR将这一思想升华到了潜空间。它先用前两阶段模型重建序列中的每一帧,得到初步清晰的图像,然后用一个预训练的光流模型(如RAFT)在这些清晰帧上估计运动,这比在噪声帧上估计准得多。接着,将所有帧的潜码根据光流对齐。
但简单平均对齐的潜码会模糊(图5)。于是,他们祭出了FusionViT:一个轻量级的伪3D视觉Transformer。它像一位聪明的剪辑师,通过时空注意力机制,动态地分析和对齐后的潜码序列进行加权融合,考虑运动大小和与参考帧的接近程度,最终输出一个既清晰又时间一致的中心帧潜码。

图5:动态时空潜在爆发合并。对光流对齐的爆发潜在进行朴素平均会在场景运动下产生模糊。FusionViT则根据运动和与参考帧的接近程度自适应地加权潜在,产生更锐利的输出。
核心突破:对抗“遗忘”,让大模型读懂量子世界
整个gQIR框架中最核心、最精妙的技术创新,就隐藏在第一阶段VAE的对齐训练中。如果不加以约束,编码器会迅速“躺平”,学会那个作弊的捷径。gQIR用了两招来防止这种情况:
第一招:确定性均值编码
VAE编码器通常输出一个高斯分布的均值和方差,然后从中采样得到潜码。在噪声极大的SPAD输入下,这种随机采样会引入额外的不稳定性。gQIR选择绕过采样,直接使用均值作为潜码。这让训练过程更稳定,目标更明确。
第二招:潜空间对齐损失
这是防止遗忘的关键锚点。他们设计了一个潜空间对齐损失。这个损失要求:从噪声SPAD输入编码得到的潜码(均值),要和从对应的清晰真实图像编码得到的潜码(来自一个冻结的、预训练的VAE编码器)尽可能接近。
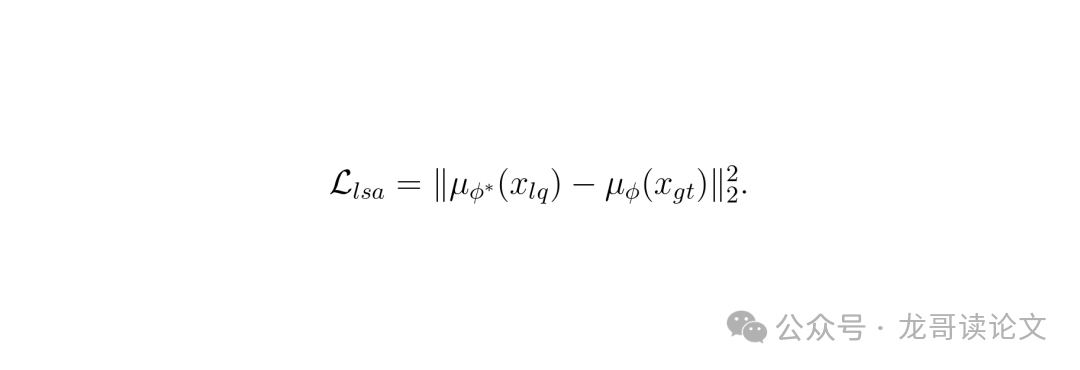
潜空间对齐损失公式:L_lsa = || μ_φ(x_lq) - μ_φ(x_gt) ||₂²。其中μ_φ是可训练编码器对噪声输入的编码均值,μ_φ是冻结编码器对清晰图像的编码均值。
妙处何在? 这个冻结的预训练编码器,就像一个永不移动的灯塔。它代表着干净自然图像在潜空间中“应该”在的位置。可训练的编码器必须努力把噪声输入映射到同一个灯塔附近,而不能自己随便找个地方躺下。这就强制编码器必须去理解噪声之下的真实结构,完成真正的去噪和去马赛克任务。

FusionViT的设计是gQIR能处理高速运动的另一大亮点。传统方法对齐后直接平均,在运动区域必然模糊。FusionViT作为一个时空注意力网络,其工作逻辑更智能:
- 它看的不是像素,是潜码。 在压缩后的潜空间进行操作,计算效率更高,且语义信息更集中。
- 它动态决定“信谁”。 对于序列中的每一帧潜码,FusionViT通过自注意力机制,学习它对于重建中心帧的“贡献权重”。离参考帧时间近的、运动估计更可靠的帧,可能会获得更高的权重;而由于遮挡或大运动导致对齐很差的帧,权重则会被降低。
- 它是“润色”而非“重画”。 FusionViT的输出不是直接替代中心帧潜码,而是作为一个残差调制信号,以一个很小的初始系数(0.05)加到中心帧潜码上。这种设计非常稳定,确保融合过程是增强细节和一致性,而不是引入不可控的变动,从而有效减轻了视频中常见的闪烁和内容漂移问题。
实验结果:合成与真实数据双重验证,性能全面领先
论文在大量合成数据和真实采集的SPAD数据上进行了验证。结果一句话概括:gQIR在感知质量上碾压了所有基线方法,并且在保真度与时间稳定性上取得了最佳平衡。
单帧重建:细节与真实的胜利
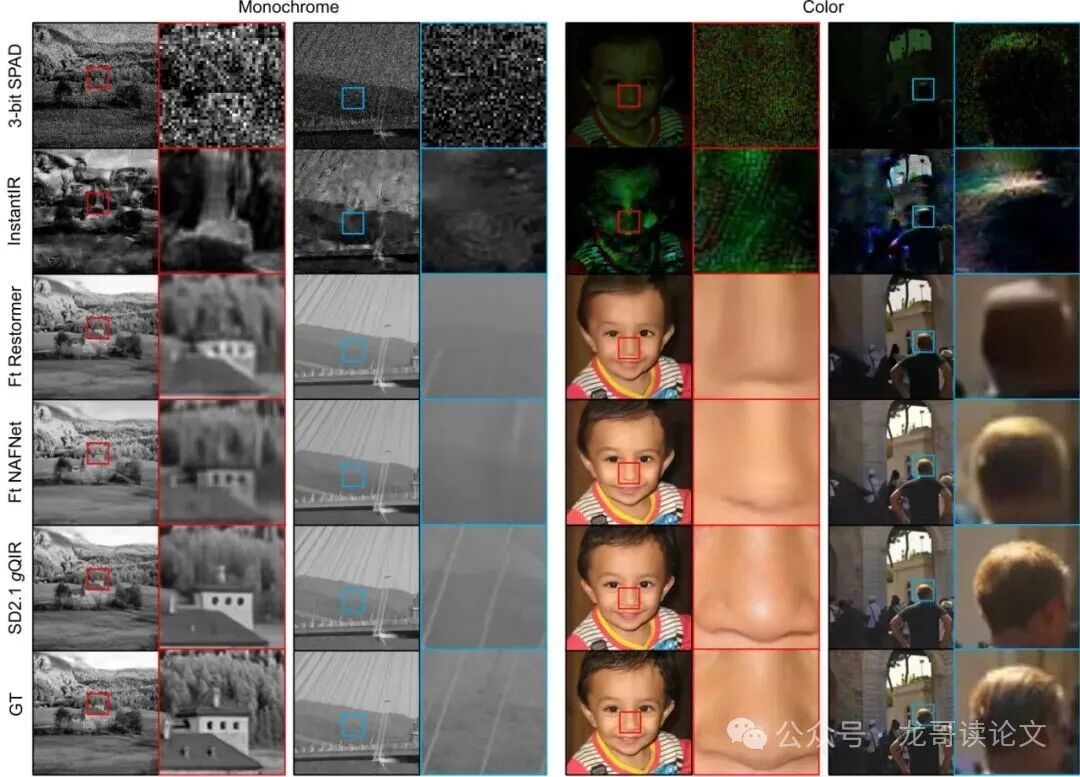
图3:单帧3位输入重建的定性对比。传统微调基线过度平滑高频结构,而gQIR保留了更锐利的细节和更忠实的面部特征。
从图3可以直观看到,基于传统架构微调的Restormer和NAFNet虽然PSNR可能略高(因为它们优化了均方误差,倾向于输出平滑结果),但重建结果丢失了大量纹理细节,人脸显得塑料感十足。而gQIR重建的图像,无论是皮肤纹理、毛发细节还是远处景物的结构,都更加锐利和真实。
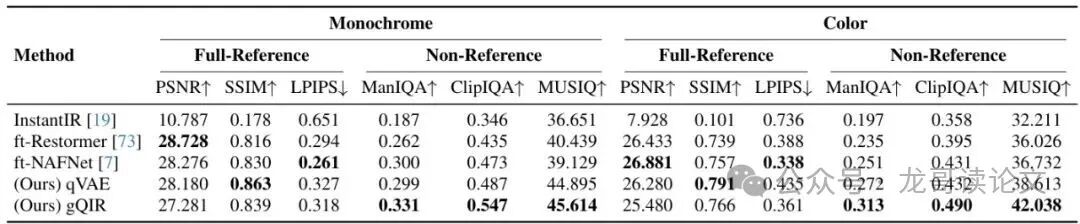
表1:3位纳米爆发输入单RGB帧重建的保真度与感知质量。gQIR在非参考感知指标(ManIQA, ClipIQA, MUSIQ)上全面领先。
序列重建:征服极端运动

图6:爆发重建的定性对比。在从1000到100k fps的极端运动状态下,我们的爆发重建流程始终能恢复出更清晰的结构和更高的保真度。
在序列重建任务中(图6),传统方法QBP在快速运动下产生严重模糊,而另一学习基线QUIVER因为采用了不够真实的训练数据生成方式(无运动模糊的纳米爆发),在面对真实采样产生的运动模糊时直接崩溃。只有Burst-gQIR能够稳定输出清晰、高保真的帧,成功处理了高达每秒10万帧的极端运动。

表2:极端运动下的爆发重建保真度。我们的方法在具有挑战性的XD数据集上优势尤其明显。
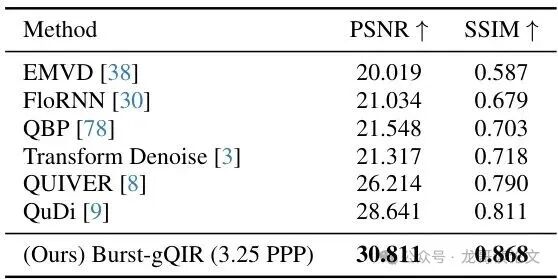
表3:在I2-2k基准测试上的爆发保真度。尽管存在PPP(每像素光子数)不匹配,我们的方法仍达到卓越的保真度。
消融实验:证明每个设计的价值
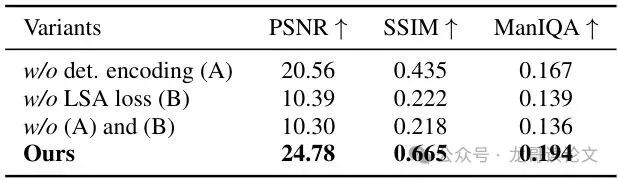
表4:第一阶段设计选择与损失的消融实验。我们的潜空间对齐损失和确定性采样给出了最高的保真度。
表4的消融实验铁证如山:移除潜空间对齐损失或确定性采样中的任何一个,性能都会急剧下降。两者结合才是让VAE编码器学会正确“翻译”量子噪声的关键。
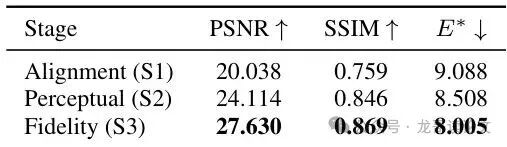
表5:消融:所有阶段——保真度与时间稳定性。第三阶段在重建质量和时间稳定性之间提供了最佳的整体权衡。
表5则清晰展示了三阶段的演进:S1提供基础对齐,S2提升感知质量但略微增加了时间上的内容漂移,S3通过时空融合,在显著提升保真度的同时,还拥有了最好的时间稳定性。
真实世界测试:从实验室走向应用

图8:真实彩色SPAD重建结果。在6k fps下用100万像素被动彩色SPAD原型捕获的二进制爆发上的定性结果。
最令人信服的证据来自真实SPAD传感器捕获的数据(图8)。无需复杂的暗计数或热像素校正,仅进行简单的白平衡后,gQIR就能从原始的二进制爆发数据中重建出色彩自然、细节丰富的图像,甚至保留了传感器固有的暗角特征,证明了其强大的泛化能力和对物理信号的忠实度。
未来之路:局限与展望,量子视觉的无限可能
当然,gQIR并非完美。论文也坦诚了其局限性,并指明了未来方向:
- 运动线索的脆弱性: 在非常微妙的帧间漂移下,第二阶段提供的运动线索可能退化。未来可以探索使用视频级或多帧扩散先验来进一步提升时间连贯性。
- 光照条件泛化: 当前训练固定了平均每像素光子数(PPP=3.5)。在极低光(PPP≤1) 下鲁棒性可能不足。将PPP作为条件信号输入模型,可能增强对不同光照和传感器特性的适应性。
- 高动态范围的挑战: SPAD本身具有原生高动态范围潜力,但预训练VAE解码器被限制在8位输出。开发HDR兼容的解码器是释放SPAD全部能力的关键下一步。
尽管如此,gQIR无疑为“AI+量子视觉”打开了一扇全新的大门。它证明了大规模生成先验能够被成功迁移到与传统图像截然不同的量子传感领域。这对于自动驾驶(在近乎全黑的环境下感知)、生物显微成像(观察不惧光漂白的活体样本)、科学高速摄影以及消费电子(极暗光拍照)等领域,都具有不可估量的应用前景。
对于人工智能如何深度赋能物理世界感知这类前沿交叉话题,云栈社区上也有不少技术同仁在持续探讨。gQIR的实践,为如何巧妙“驯服”大模型,让其服务于特定、严苛的专业领域,提供了一个极具启发性的范例。
参考文献
[1] gQIR: Generative Quanta Image Reconstruction. Aryan Garg, Sizhuo Ma, Mohit Gupta. arXiv:2602.20417v1, 2026.
[2] Stable Diffusion. Rombach et al. CVPR 2022.
[3] Quanta Burst Photography. Gupta et al. ACM TOG 2020.
原文链接:https://arxiv.org/pdf/2602.20417v1.pdf
开源代码:https://github.com/Aryan-Garg/gQIR
 发表于 2026-2-26 03:15:21
|
查看: 164|
回复: 0
发表于 2026-2-26 03:15:21
|
查看: 164|
回复: 0
