如果Spring MVC Controller的某个方法有一个HttpServletRequest入参,我们通常可以调用request.getInputStream()来获取请求体数据。其背后的is.read(bytes)方法,具体是如何将数据从网卡一步步送达应用层的呢?本文将自底向上,为你解析Tomcat中HTTP请求体的完整读取链路。
数据读取的起点:从NIO到JVM
Tomcat的I/O处理建立在JDK NIO包之上。NIO的核心SocketChannel用于网络通信,其read(ByteBuffer dest)方法负责将操作系统Socket缓冲区中的数据读取到Java的ByteBuffer中。
public abstract class SocketChannel {
public abstract int read(ByteBuffer dest) throws IOException;
}
该方法的返回值具有特定含义:-1代表连接关闭;>0代表实际读取的字节数;而返回0则意味着此刻网卡缓冲区为空,没有数据可读。这正是非阻塞I/O的关键——当没有数据时,方法会立即返回,不会阻塞线程。
深入SocketChannelImpl.read(ByteBuffer)的实现,会发现它最终调用了IOUtil.read方法。这个方法内部有一个关键逻辑:如果入参的ByteBuffer是堆外内存的DirectBuffer,则数据可直接写入;否则,需要先申请一个临时的DirectBuffer作为中转。这是因为DirectBuffer存在于JVM堆外,操作系统内核可以安全地直接进行DMA操作,避免了数据在用户态与内核态之间的额外拷贝。
最终,通过一个Native调用read0,数据从文件描述符(fd)指向的Socket缓冲区,被写入到指定内存地址。当Socket被设置为非阻塞模式时,若缓冲区为空,此调用会立即返回,这构成了NIO实现非阻塞的基石。
与BIO的对比
传统的BIO通过Socket.getInputStream()获得SocketInputStream,其read(byte[])最终调用Native方法socketRead0。该方法内部会将当前线程阻塞,并注册到操作系统的poll/epoll队列中等待数据到达,整个读取过程是同步阻塞的。
连接层:在非阻塞之上的缓冲与调度
Tomcat在SocketChannel之上封装了连接层,其核心类为NioSocketWrapper。它内部维护着读/写两个ByteBuffer,核心职责是在底层NIO的非阻塞能力之上,为上层协议提供可阻塞亦可非阻塞的灵活读取接口。
数据流向遵循:SocketChannel -> 连接层ByteBuffer (readBuffer) -> 上层协议ByteBuffer。
NioSocketWrapper.read(boolean block, ByteBuffer to)方法是关键,其逻辑清晰体现了性能优化:
- 首先尝试将连接层
readBuffer中已有的数据直接复制到上层Buffer。
- 若
readBuffer为空,则判断上层Buffer剩余空间是否足够大。如果足够,则绕过readBuffer,直接通过SocketChannel将数据读入上层Buffer,减少一次内存拷贝。
- 若上层Buffer空间较小,则先通过
SocketChannel将数据填充到自身的readBuffer,再复制给上层。
其中的fillReadBuffer方法实现了阻塞/非阻塞的控制逻辑。在阻塞模式下,若SocketChannel.read()返回0,当前线程会通过wait()方法挂起,并注册读就绪事件。当数据到达、I/O线程唤醒它后,循环会继续尝试读取。这个过程巧妙地在NIO的非阻塞系统调用之上,模拟出了阻塞语义。
协议层:解析HTTP与过滤器链
连接层负责字节搬运,协议层(Http11InputBuffer)则负责解析这些字节的语义,区分请求行、请求头和请求体。
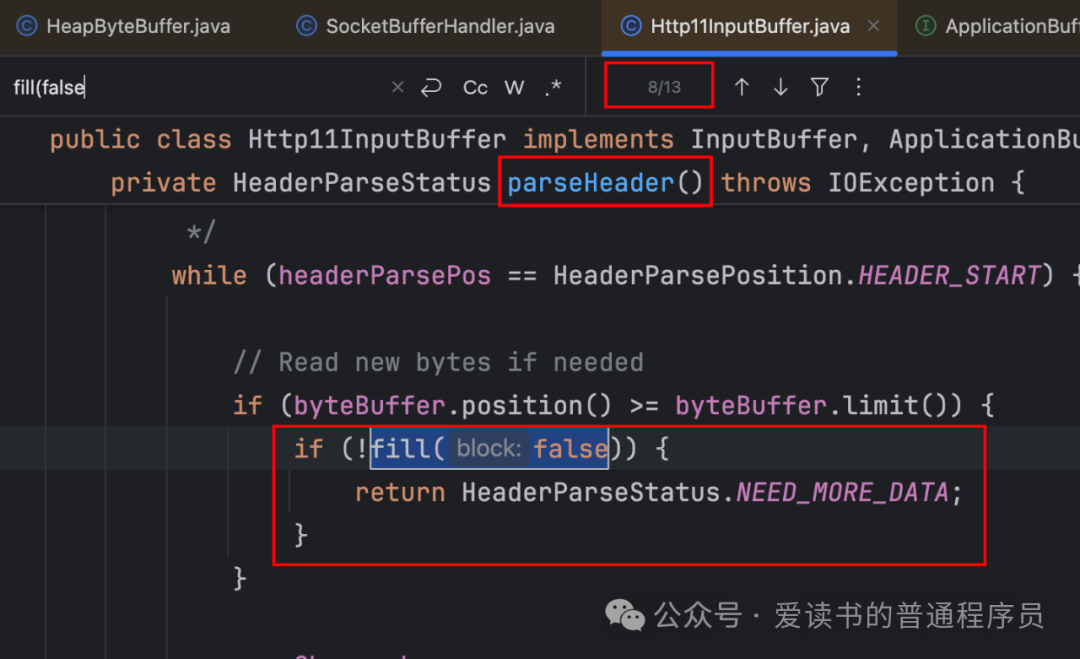
Http11InputBuffer内部持有一个ByteBuffer用于暂存从连接层读取的原始数据。在解析请求行和请求头时,它使用非阻塞读(block=false),若未读到足够数据,则注册读事件并释放Worker线程,避免了因单个请求头未发送完整而阻塞线程池,这是Tomcat支持高并发的重要设计。
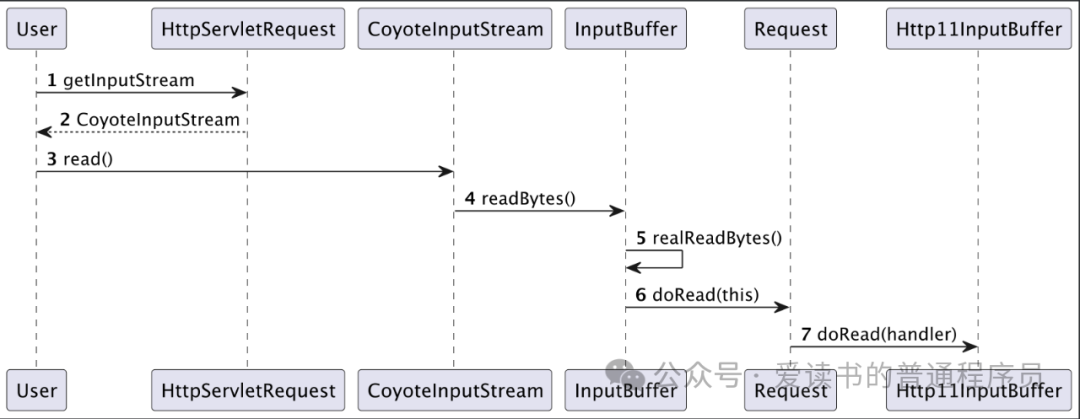
请求体的读取与过滤器链
请求体的读取默认使用阻塞读(block=true)。Http11InputBuffer内部类SocketInputBuffer的doRead方法是核心。当自身ByteBuffer的数据被消费完后,它会调用fill(true)方法向连接层获取更多数据。
这里有一个关键优化:它通过byteBuffer.duplicate()将自身的ByteBuffer视图直接“交给”上层(通过ApplicationBufferHandler回调接口),两者共享底层数据数组,从而实现了零拷贝的数据传递,极大提升了性能。
// 在SocketInputBuffer.doRead方法中
handler.setByteBuffer(byteBuffer.duplicate()); // 共享数据,零拷贝
byteBuffer.position(byteBuffer.limit()); // 移动自身指针,标记数据已交付
更为精妙的是请求体过滤器链机制。在准备请求阶段(prepareInputFilters),Tomcat会根据Content-Encoding、Transfer-Encoding等请求头,动态组装一个过滤器链(如GzipFilter)。Http11InputBuffer.doRead()方法会从链的最后一个过滤器开始执行。每个过滤器的doRead会先调用其下游(下一个过滤器或最终的SocketInputBuffer)获取原始数据,再进行解压缩等处理,最终将结果传递给应用层。这种责任链模式优雅地分离了数据获取与数据处理的逻辑。
应用层:Servlet API的适配与对接
最上层是我们熟悉的Servlet API。CoyoteInputStream(即ServletInputStream的实现)的read()方法,会调用Tomcat内部适配器InputBuffer的相应方法。
InputBuffer类扮演了桥梁角色。它实现了ApplicationBufferHandler接口,其setByteBuffer(ByteBuffer buffer)方法正是被协议层的SocketInputBuffer所调用,用于接收共享的ByteBuffer数据。随后,InputBuffer再通过其read方法将字节或字符数据提供给CoyoteInputStream。
内部请求对象org.apache.coyote.Request持有指向Http11InputBuffer的引用。当InputBuffer需要更多数据时,会调用request.doRead(this),从而将请求向下传递到协议层,触发整个读取链条的运转。
总结:一次HttpServletRequest.getInputStream().read()调用,背后是数据从网卡驱动,经操作系统内核缓冲区,由JDK NIO的非阻塞SocketChannel读出,再经过Tomcat连接层的缓冲与调度、协议层的解析与过滤链处理,最终通过适配器层零拷贝或高效拷贝地交付给Servlet应用层的复杂旅程。理解这个过程,对于深入掌握Java Web服务的高性能处理机制至关重要。
想了解更多关于网络协议、系统调用的底层原理,欢迎访问 云栈社区 的网络与系统板块进行深入探讨。
 发表于 2026-1-3 06:26:39
|
查看: 201|
回复: 0
发表于 2026-1-3 06:26:39
|
查看: 201|
回复: 0
