概览摘要
早期的 Linux 0.11 是典型的单 CPU 内核,不支持 SMP(Symmetric Multi-Processing,对称多处理)。真正在 PC 平台上较稳定、系统化地支持 SMP,大概是 2.0 之后的事。下面的分析会以现代 Linux 内核(2.6 以后为主)为参照,但所探讨的都是内核中真实运行的核心机制。
我们可以将单核系统想象成只有一个厨师的小厨房:所有菜都得排队做。而 SMP 则是有多名厨师、多个灶台,但共享同一套菜谱(内核代码)和冰箱(物理内存)。真正的难点并不在于“多找几个厨师”,而在于协调他们高效、正确地工作:
- 如何分配任务(调度)?
- 如何避免他们抢错食材(并发冲突与锁)?
- 如何保证大家看到的库存是一致的(缓存一致性与内存屏障)?
- 当某个厨师出问题时,如何协调其他人(IPI、CPU热插拔)?
本文将深度剖析涉及CPU启动、CPU间通信、调度与负载均衡、锁与并发控制、内存一致性与屏障、per-CPU数据结构等在内的一系列关键技术点。
核心概念详解
关键术语
| 术语 |
含义 |
在 SMP 中的角色 |
| SMP (Symmetric MP) |
对称多处理,每个 CPU 权限对等 |
所有 CPU 共享同一内核与内存 |
| AP (Application Processor) |
除 BSP 外的其他 CPU |
需要由 BSP 唤醒和初始化 |
| BSP (Bootstrap Processor) |
系统上电后首先启动的 CPU |
负责内核引导、其他 CPU 启动 |
| IPI (Inter-Processor Interrupt) |
处理器间中断 |
用于跨 CPU 通知、TLB 刷新等 |
| Local APIC / IO APIC |
本地/IO 中断控制器 |
管理中断路由和分发 |
| Per-CPU 变量 |
每个 CPU 独立的一份变量副本 |
避免多核竞争、提高缓存命中 |
| Spinlock |
自旋锁 |
短时加锁,不睡眠,常用于中断/底半部 |
| RCU |
Read-Copy-Update |
读多写少的高并发读优化机制 |
| Memory Barrier |
内存屏障 |
控制 CPU/编译器重排序,保障时序关系 |
举个栗子
-
单核 vs SMP
- 单核:一个收银员 + 一条队伍,所有顾客排队结账。
- SMP:多个收银员共用一个收银系统和一个库存数据库,顾客可以去任意收银台。这里的问题在于:
- 库存扣减要一致(缓存一致性)
- 有活动时要所有收银台一起参与(IPI 广播)
-
Spinlock
- 好比办公室里的一把“签字笔”,谁拿到笔,谁就能在文件上签字。
- 如果笔正在别人手里,你只能在旁边干等(自旋),不能离开(不能睡眠)。
-
Per-CPU 数据
- 每个收银台桌上都放一只小钱盒(每 CPU 单独一份统计)。
- 最终结算时再把所有小钱盒里的钱加总。
- 平时没人抢一个盒子用,冲突少、效率高。
与其它模式对比
| 模式 |
特点 |
优点 |
缺点 |
| UP(单处理器) |
只有一个 CPU |
实现简单,无锁或少锁 |
无法利用多核 |
| SMP |
所有 CPU 对等,统一内存 |
编程模型简单(统一视图) |
锁竞争、缓存抖动 |
| NUMA |
非一致内存访问,多节点 |
可扩展到很多 CPU |
内存访问成本差异大,调度复杂 |
Linux 主流内核在抽象层以 SMP 为基准模型,底层则会针对 NUMA、超线程、CPU 拓扑进行复杂的优化。
实现机制深度剖析
数据结构概览
以 x86 架构为例,SMP 相关的核心数据结构大致分布在以下内核文件中:
arch/x86/kernel/smp.c:CPU 启动、IPI、smp_call_function 系列函数kernel/sched/core.c / kernel/sched/fair.c:调度器与多队列负载均衡kernel/locking/*.c:自旋锁、读写锁、RCU 等kernel/cpu.c:CPU hotplug 相关arch/x86/mm/tlb.c:TLB shootdown IPI 相关
下面我们用一些简化版的结构来说明设计思路(非内核原样代码):
// 典型的 CPU 描述结构 (简化)
struct cpu_info {
int id; // 逻辑 CPU ID
int online; // 是否在线
int apic_id; // 对应的 APIC ID
int numa_node; // 所在 NUMA 节点
struct rq *rq; // 调度就绪队列
void *percpu_data; // per-CPU 数据基址
};
// 每 CPU 运行队列 (调度器核心数据之一,简化自 rq)
struct rq {
raw_spinlock_t lock; // 保护该队列的自旋锁
struct task_struct *curr; // 当前在此 CPU 运行的进程
struct cfs_rq cfs; // CFS 调度队列 (红黑树等)
unsigned long nr_running; // 就绪进程数量
int cpu; // 所属 CPU
};
// IPI 处理相关 (高度简化)
typedef void (*smp_fn)(void *info);
struct smp_call_item {
smp_fn func;
void *info;
struct list_head list;
};
struct smp_call_queue {
raw_spinlock_t lock;
struct list_head list; // 待执行的函数队列
};
CPU 启动流程
BSP 启动 AP 的整体流程
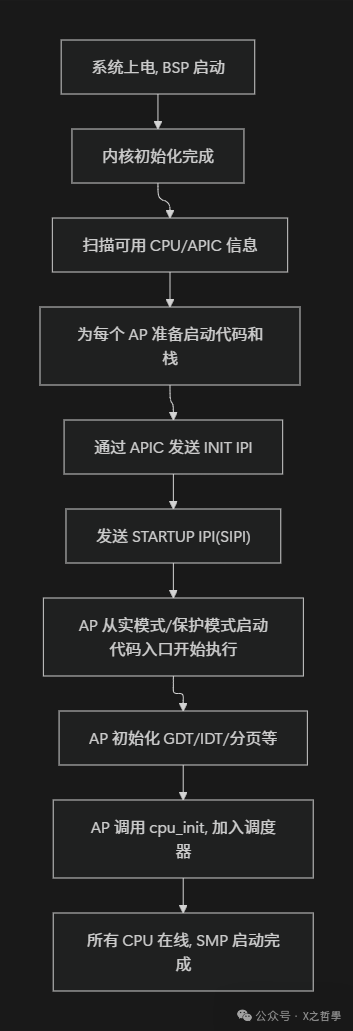
整个过程可以概括如下:
- BSP 完成常规的内核启动(类似 0.11 的单核起步流程)。
- 探测硬件,构建 CPU 拓扑结构(通过ACPI/MADT、MP Table等)。
- 为每个即将启动的 AP 准备栈、页表、启动跳板代码。
- 通过 Local APIC 向对应地址写寄存器,发送 IPI 给目标 AP:
INIT IPI:复位 AP 到已知状态。SIPI(Startup IPI):告诉 AP 从某段物理地址开始执行。
- AP 跳到一段汇编启动代码,逐步切换到保护模式/长模式、加载 GDT/IDT、页表。
- AP 调用
start_secondary() 一类的函数,执行本地初始化(如本地定时器、中断、per-CPU 结构等),最终进入调度循环。
启动入口的简化代码示意
相关文件大致位于:arch/x86/kernel/head_64.S / smpboot.c 等。
// 伪代码:AP 启动主流程
void start_secondary(void)
{
cpu_init(); // 初始化 CPU 本地状态,per-CPU 结构
smp_callin(); // 与 BSP 同步,通知自己已经在线
setup_local_APIC(); // 本地 APIC 初始化
calibrate_delay(); // BogoMIPS 校准,delay loop 相关
notify_cpu_starting(); // 通知其他子系统 (如 RCU) 本 CPU 启动
scheduler_start(); // 进入调度循环,开始执行进程
}
注:这段是高度抽象的示意代码,仅为了说明流程关联。
CPU 间通信:IPI 与 smp_call_function
IPI 类型
常见的 IPI 类型(以 x86 为例)包括:
- TLB shootdown IPI:当某个 CPU 修改页表后,需要通知其他 CPU 刷新对应的 TLB 项。
- reschedule IPI:让另外一个 CPU 尽快重新调度,例如在负载均衡或优先级更新时。
- call_function IPI:让其他 CPU 执行某个回调函数(如刷新某些 per-CPU 状态)。
- stop IPI:在停机、panic 等场景中,让所有 CPU 停在安全位置。
smp_call_function 伪代码
相关文件大致位于:kernel/smp.c / arch/x86/kernel/smp.c。
// 向其他 CPU 广播调用 func(info)
int smp_call_function(smp_fn func, void *info, bool wait)
{
struct smp_call_item item;
item.func = func;
item.info = info;
for_each_online_cpu(cpu) {
if (cpu == smp_processor_id())
continue;
enqueue_call(cpu, &item); // 加入目标 CPU 的队列
send_IPI(cpu, IPI_CALL_FUNC); // 触发 IPI
}
if (wait)
wait_for_all_cpu_done();
return 0;
}
// 目标 CPU 的 IPI 处理函数 (高度简化)
void handle_call_function_ipi(void)
{
struct smp_call_item *item;
while ((item = dequeue_call(this_cpu))) {
item->func(item->info); // 在当前 CPU 上执行回调
}
notify_caller_if_needed();
}
这套机制把“在某个 CPU 上执行某个函数”抽象成了通用服务,其他子系统(如 TLB、RCU、时钟同步)都基于它构建更高层的逻辑。
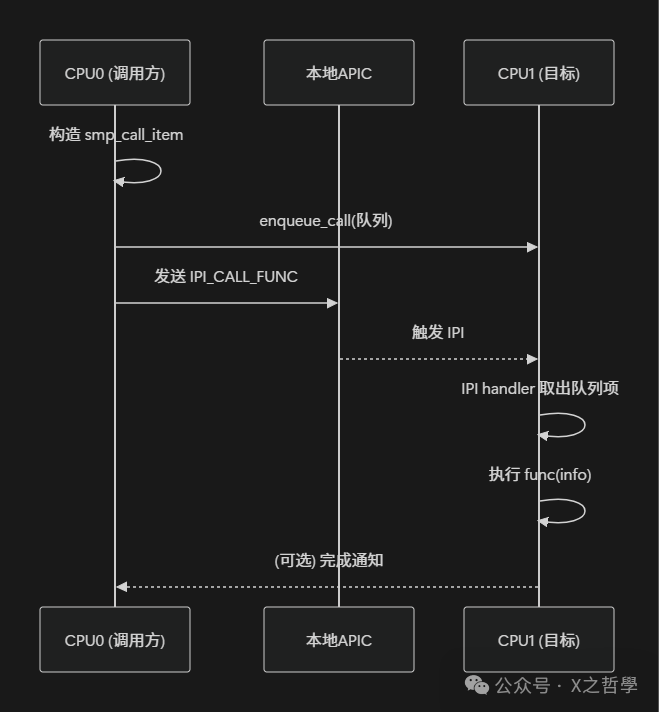
调度与负载均衡:多运行队列模型
多队列调度器
从 2.6 时代开始,Linux 内核调度器演进为每 CPU 一个就绪队列的模型(struct rq),再通过周期性的负载均衡实现跨 CPU 的任务迁移:
- 每个 CPU 有独立的
rq,极大地减少了锁竞争。
- 普通情况下,任务尽量留在本 CPU 运行(保持缓存友好性)。
- 周期性检查各 CPU 负载,必要时从繁忙 CPU 把任务“偷”到空闲 CPU(即工作窃取,work stealing)。
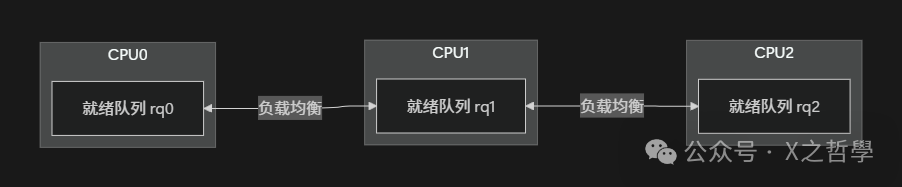
核心调度循环伪代码
// 伪代码,概念类似 schedule()
void schedule(void)
{
struct rq *rq = this_rq();
struct task_struct *prev = rq->curr;
struct task_struct *next;
raw_spin_lock(&rq->lock);
put_prev_task(rq, prev); // 把当前进程放回就绪队列
next = pick_next_task(rq); // 从就绪队列选择下一个
rq->curr = next;
context_switch(prev, next); // 切换寄存器、栈、地址空间等
raw_spin_unlock(&rq->lock);
}
// 周期性负载均衡 (高度简化)
void rebalance_domains(int cpu)
{
struct rq *rq = cpu_rq(cpu);
raw_spin_lock(&rq->lock);
if (rq->nr_running < threshold) {
int src = find_busiest_cpu();
if (src >= 0)
steal_tasks(cpu, src); // 从繁忙 CPU 偷几个任务过来
}
raw_spin_unlock(&rq->lock);
}
这里的设计难点在于:
- 锁粒度:避免使用全局大锁,尽量使用每 CPU 自旋锁。
- 拓扑感知:在 NUMA 或多级缓存拓扑下,优先在“物理距离近”的 CPU 之间进行平衡。
- 实时进程/亲和性:调度器必须尊重进程的 CPU 亲和性设置、实时优先级等约束条件。
锁与并发控制:Spinlock / RCU / seqlock
自旋锁基础实现
相关文件大致位于:kernel/locking/spinlock.c 或 arch/*/include/asm/spinlock.h。
typedef struct {
volatile int locked;
} raw_spinlock_t;
// 简化版 test-and-set 自旋锁
void raw_spin_lock(raw_spinlock_t *lock)
{
while (1) {
// 原子交换,xchg 返回旧值
if (xchg(&lock->locked, 1) == 0)
break; // 拿到锁
// 没拿到锁,就自旋等一会
cpu_relax(); // 提示 CPU 做 pause 等优化指令
}
smp_mb(); // 获取锁后的内存屏障
}
void raw_spin_unlock(raw_spinlock_t *lock)
{
smp_mb(); // 释放前的屏障
lock->locked = 0; // 简化:写 0 即释放
}
实现要点:
xchg 是硬件提供的原子指令(如 x86 上的 lock xchg)。- 在多核环境下,自旋锁保证同一时刻只有一个 CPU 能进入临界区。
smp_mb() 等内存屏障防止指令和内存访问在锁操作前后被非法重排序。
RCU / seqlock 简要对比
| 机制 |
使用场景 |
读路径开销 |
写路径开销 |
典型特点 |
| Spinlock |
读写都需要互斥 |
中 |
中 |
简单直接,容易死锁 |
| RW lock |
读多写少 |
低(多读共享) |
高(独占写) |
写时阻塞所有读 |
| Seqlock |
读多写少,读可重试 |
无需锁,但可能重试 |
中 |
读不阻塞写,适合时间戳类 |
| RCU |
极端读多写少 |
非常低 |
高且复杂 |
读几乎无锁,写需要分期回收 |
例如 seqlock 的简化版实现:
typedef struct {
volatile unsigned seq;
raw_spinlock_t lock;
} seqlock_t;
unsigned read_seqbegin(seqlock_t *sl)
{
unsigned s;
do {
s = sl->seq;
} while (s & 1); // 奇数表示正在写
smp_rmb();
return s;
}
int read_seqretry(seqlock_t *sl, unsigned start)
{
smp_rmb();
return (start != sl->seq);
}
void write_seqlock(seqlock_t *sl)
{
raw_spin_lock(&sl->lock);
sl->seq++;
smp_wmb();
}
void write_sequnlock(seqlock_t *sl)
{
smp_wmb();
sl->seq++;
raw_spin_unlock(&sl->lock);
}
读者端完全不加锁,只是检查 seq 序列号在读期间是否发生了变化;如果变了,就再读一遍。这种机制典型应用于时间戳、jiffies、统计信息这类读远多于写的场景。
内存一致性与屏障
在多核系统中,即使有硬件缓存一致性协议(如MESI),仍然会因为:
- CPU 的乱序执行优化
- 编译器的优化重排序
导致 “代码顺序” ≠ “真正生效的内存访问顺序”。
Linux 提供了跨架构统一的内存屏障接口:
smp_mb():全内存屏障smp_rmb():读屏障smp_wmb():写屏障- 以及带依赖的、RCU 专用的屏障等。
典型例子是 发布-订阅(producer-consumer) 模式:
// 生产者 CPU
data = new_value;
smp_wmb(); // 确保 data 写入在前
ready = 1; // 通知消费者
// 消费者 CPU
while (!ready)
cpu_relax();
smp_rmb(); // 确保下面读 data 不会被提前
use(data);
如果没有屏障,可能出现消费者看到 ready == 1,但 data 仍是旧值的错误情况。
用更形式化的语言描述,smp_wmb() 和 smp_rmb() 在代码中建立了一个偏序关系:
$$
\text{write}(data) \xrightarrow{\text{wmb/rmb}} \text{read}(data)
$$
这个关系防止了硬件或编译器将这条“因果链”打乱。
Per-CPU 数据与 cache 友好设计
问题:多 CPU 同时频繁读写同一个全局变量,会导致:
- cache line 在 CPU 间不断迁移(伪共享,false sharing);
- 性能抖动严重,锁竞争加剧。
解决方案:将一些高频访问的变量改为 per-CPU 形式,每个 CPU 维护一份独立的副本,只在必要时进行汇总。
// 声明一个 per-CPU 计数器 (概念性示例)
DEFINE_PER_CPU(unsigned long, packets_processed);
// 在某个 CPU 上增加本地计数
void inc_packets(void)
{
unsigned long *cnt = this_cpu_ptr(&packets_processed);
(*cnt)++;
}
// 汇总所有 CPU 上的计数
unsigned long sum_packets(void)
{
unsigned long total = 0;
int cpu;
for_each_online_cpu(cpu) {
total += per_cpu(packets_processed, cpu);
}
return total;
}
这样的设计带来了显著的优势:
- 常规路径(增加计数)完全本地化,无需加锁、无竞争。
- 汇总路径调用频率较低,即使需要遍历所有 CPU,其开销也是可接受的。
设计思想与架构
为什么采用这样的 SMP 方案?
其核心设计目标可以总结为三点:
-
对上保持简单的“统一系统”抽象:
- 对用户态和大多数内核子系统而言,系统看起来就像一个更快的单机。
- 不要求应用程序显式感知多核(除非进行亲和性或 NUMA 优化)。
-
对下充分榨干硬件能力:
- 充分利用 APIC / IPI / per-CPU / cache 等各种硬件特性。
- 尽量减少跨 CPU 的数据共享,避免 cache line 抖动。
-
在可维护性和性能之间取得平衡:
- 一味使用全局锁很简单但性能糟糕。
- 完全无锁(lock-free)算法性能虽高,但难以验证正确性并普及。
- Linux 采用了“多种工具组合”的策略:自旋锁、读写锁、RCU、seqlock、per-CPU 等,针对不同场景选择最合适的机制。
解决了哪些痛点?
- 实现了从单核向多核的横向扩展,充分利用多核 CPU 提升系统吞吐量。
- 避免了早期大内核锁(BKL)成为性能瓶颈,通过细粒度锁和 per-CPU 数据将锁粒度拆小。
- 在高并发 I/O 或网络处理场景中,允许多个 CPU 并行处理不同的连接或软中断。
局限性与代价
-
复杂性:
- SMP 相关的代码路径极其复杂,涉及调度、内存管理、锁、架构细节等多个子系统。
- 相关的 bug 一般为竞态条件和死锁,复现与调试都异常困难。
-
NUMA 下的扩展问题:
- SMP 模型在统一内存延迟的假设下工作良好。
- 但在 NUMA 大规模多核系统上,单纯的 SMP 抽象已显不足,需要额外的调度域和内存亲和性策略。
-
调试难度:
- 多核竞态问题可能只在极端高负载、特定硬件拓扑、罕见时序下才会触发。
- 传统的“单步调试”手段在这里很难直接应用。
替代方案对比
| 方案 |
思想 |
优点 |
缺点 |
| 大内核锁 (BKL) |
整个内核一把大锁 |
实现简单 |
完全无法扩展,多核几乎浪费 |
| 细粒度锁 + per-CPU |
当前 Linux 内核路径 |
折中可维护性与性能 |
设计难度高 |
| 微内核 + 消息传递 |
通过 IPC 串联服务 |
模块隔离好 |
上下文切换/IPC 成本高 |
| 用户态多线程 + 单核内核 |
内核不支持 SMP |
内核简化 |
性能受限,应用负担大 |
Linux 选择的是一条以单体内核 + 细粒度并发控制为主轴的渐进式演化路线。
实践示例:构造一个极简“多核友好计数器”
下面给出一个小型示例,演示如何使用 per-CPU 计数器结合 IPI,模拟“在所有 CPU 上统计某事件次数”的场景。示例代码为可编译运行的内核模块伪代码风格(省略了宏和API细节,仅示意核心结构)。
场景描述
- 每个 CPU 本地独立计数一个事件(比如一次特定的软中断触发)。
- 用户通过
/proc 或 debugfs 可以读取到全局总和以及每 CPU 的分布情况。
- 当某个 CPU 发起“刷新”请求时,通过
smp_call_function() 让其他所有 CPU 将其本地计数值刷到一个共享数组中,然后统一打印。
核心代码
// 示例文件: kernel/smp_demo.c (假想路径)
#define NR_CPUS 64
static DEFINE_PER_CPU(unsigned long, local_cnt);
static unsigned long snapshot[NR_CPUS];
// 在收到IPI时,被其他CPU执行的刷新函数
static void flush_local_cnt(void *info)
{
int cpu = smp_processor_id();
unsigned long v = this_cpu_read(local_cnt);
snapshot[cpu] = v;
}
// 事件发生时,在当前CPU上增加计数
void event_occurs(void)
{
this_cpu_inc(local_cnt);
}
// 由某个 CPU 发起全局刷新
void flush_all_cpus(void)
{
// 先刷新自己的计数值到共享数组
flush_local_cnt(NULL);
// 再通过IPI让其他所有在线CPU执行刷新函数
smp_call_function(flush_local_cnt, NULL, 1);
// 此时 snapshot[] 中已包含所有 CPU 的最新计数值
// 可以安全地在当前 CPU 上进行统计和输出
unsigned long total = 0;
int cpu;
for_each_online_cpu(cpu)
total += snapshot[cpu];
pr_info("total=%lu\n", total);
}
真正的内核模块需要 module_init / module_exit、procfs/debugfs 接口、错误处理等,这里为突出SMP核心逻辑而略去。
编译运行思路
在真正的内核源码树中,可以:
- 将上述文件加入对应的 Makefile。
- 启用 SMP 配置编译内核,或将其编译为独立模块。
- 在运行的 SMP Linux 系统上加载该模块,并通过某个触发接口(如
echo 1 > /sys/.../flush)调用 flush_all_cpus() 函数。
预期效果:
- 在多核系统上,无论哪个 CPU 上发生了多少次
event_occurs() 调用。
- 每次执行
flush_all_cpus() 时,都能准确统计到当前时刻所有 CPU 上的事件计数之和。
工具与调试
调试 SMP 问题离不开一些经典工具:
| 工具/命令 |
用途 |
示例 |
top / htop |
观察多核 CPU 利用率 |
htop,按 1 展开 per-CPU 视图 |
perf |
性能采样、锁竞争分析 |
perf record -g -a sleep 10 |
ftrace / trace-cmd |
内核函数/事件跟踪 |
trace-cmd record -e sched* |
lockstat / perf lock |
锁竞争统计 |
perf lock record ./app |
gdb + qemu |
内核单步/断点调试 |
在 qemu 中运行 SMP 内核,gdb 远程连接调试 |
sysctl kernel.sched_* |
调整调度器参数 |
sysctl kernel.sched_migration_cost_ns |
调试并发问题的常用套路:
- 利用
ftrace 记录 sched_switch、IPI 处理、RCU 回调等关键内核事件。
- 用
perf 或 lockstat 分析热点,查看某个自旋锁是否成为瓶颈。
- 在 qemu/kvm 测试环境中复现竞态条件,并配合
CONFIG_DEBUG_LOCKDEP、CONFIG_PROVE_LOCKING 等内核调试选项进行验证。
架构总览
最后用一张整体架构图,将前面拆解的知识点串联起来。
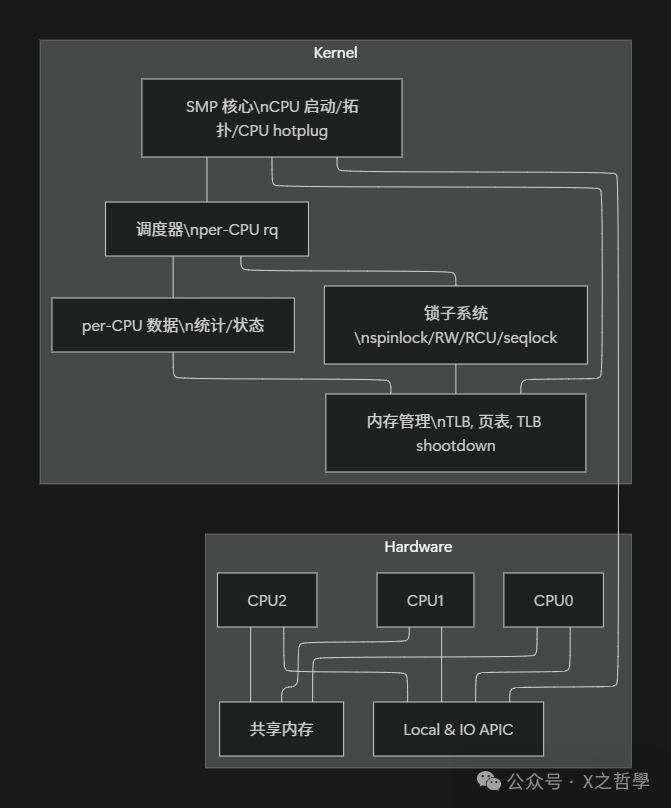
图中的逻辑连接可以简化为:
- SMP 核心 (SMPCore) 负责:
- 多 CPU 启动、CPU 在线/下线(热插拔)、拓扑信息提供、IPI 基础设施。
- 调度器 (Sched):
- 使用 per-CPU 运行队列和锁,并基于 CPU 拓扑结构进行负载均衡。
- 内存子系统 (MM):
- 通过 IPI 机制实现 TLB shootdown,使用锁或 RCU 保证页表映射更新的一致性。
- 锁子系统 (Locking):
- 提供自旋锁、RCU 等并发控制原语,供全内核使用。
- per-CPU 子系统 (PerCPU):
- 提供性能友好的本地化存储区域,有效减少多核间的共享数据冲突。
总结
最后用一个小表格,对本文覆盖的关键操作系统核心机制做简要回顾:
| 技术点 |
关键作用 |
核心要点 |
| CPU 启动 & APIC |
多 CPU 上电和初始化 |
BSP 唤醒 AP,APIC 负责 IPI 与中断路由 |
| IPI & smp_call_function |
CPU 间通信 |
让某个函数在另一 CPU 上执行,是高层同步的基础设施 |
| 多队列调度器 |
多核负载均衡 |
每 CPU 一条就绪队列 + 周期性工作窃取 (work stealing) |
| 自旋锁 / seqlock / RCU |
并发控制 |
根据读写比例和实时性要求选择合适的同步机制 |
| 内存屏障 |
时序保证 |
防止 CPU/编译器对关键的内存读写操作进行重排序 |
| per-CPU 数据 |
性能优化 |
将“共享变量”拆分为“每 CPU 各一份”,极大降低竞争 |
| CPU 拓扑 & NUMA |
扩展到多插槽多节点 |
调度器和内存分配必须感知物理拓扑,优化访问延迟 |
归纳几点核心结论:
- Linux SMP 的实现不是单一模块,而是一整套从CPU启动、APIC、IPI到调度器、锁、内存模型的协同设计。
- 真正的难点在于在性能、复杂性和可维护性之间找到平衡点,而不是简单地加几把锁。
- per-CPU 数据、细粒度锁、RCU、seqlock 等机制,分别对应不同的并发场景,是 Linux 内核多年演化的智慧结晶。
- 调度器的“每 CPU 运行队列 + 拓扑感知负载均衡”设计,是现代 SMP 系统充分利用多核能力的关键。
- 内存屏障和内存模型是所有并发原语的底层基石,对此理解不透彻,上层应用极易出错。
- 在调试和优化 SMP 性能时,要善用
perf、ftrace、lockdep 等专业工具进行量化分析,而非盲目猜测。
希望这篇深度解析能帮助你构建起对 Linux SMP 机制的系统性理解。欢迎在云栈社区继续探讨内核与系统架构的更多奥秘。
 发表于 2026-1-4 03:38:52
|
查看: 234|
回复: 0
发表于 2026-1-4 03:38:52
|
查看: 234|
回复: 0
