在技术面试中,一旦提到 Caffeine 本地缓存,面试官往往会展开深入的技术探讨。今天通过一个亿级用户平台的真实案例,分析什么时候该用 Caffeine,什么时候应该避免使用。
面试场景还原
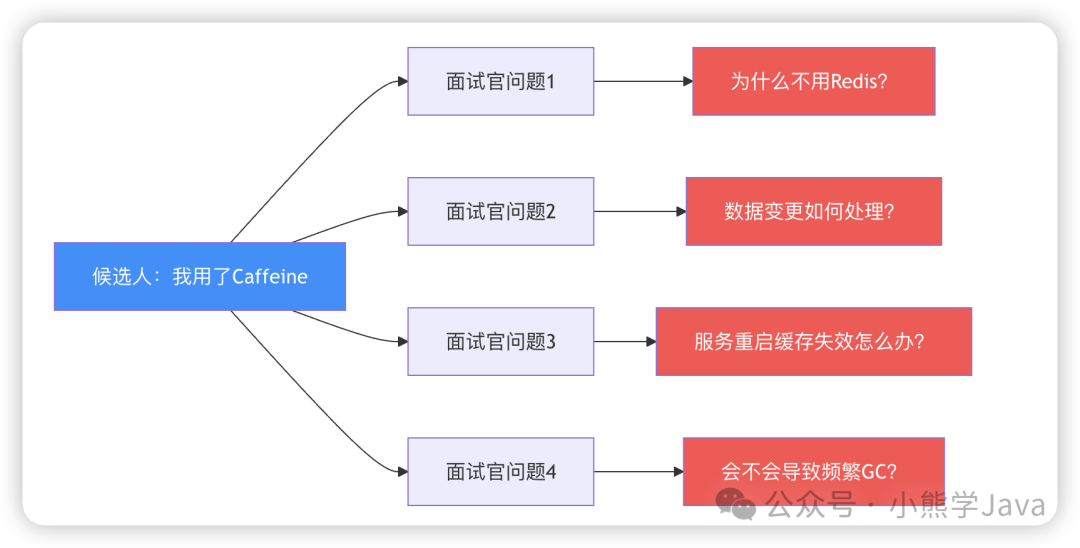
在最近一次技术面试中,当提到项目中使用了 Caffeine 本地缓存时,面试官立即提出了一系列问题:
面试官:"为什么不用 Redis?"
候选人:"因为..."
面试官:"数据变更如何处理?"
候选人:"这个..."
面试官:"服务重启后缓存丢失怎么办?数据库压力不会激增吗?"
候选人:"呃..."
面试官:"大量数据存储在内存中,不会导致频繁 Full GC 吗?"
候选人:"......"
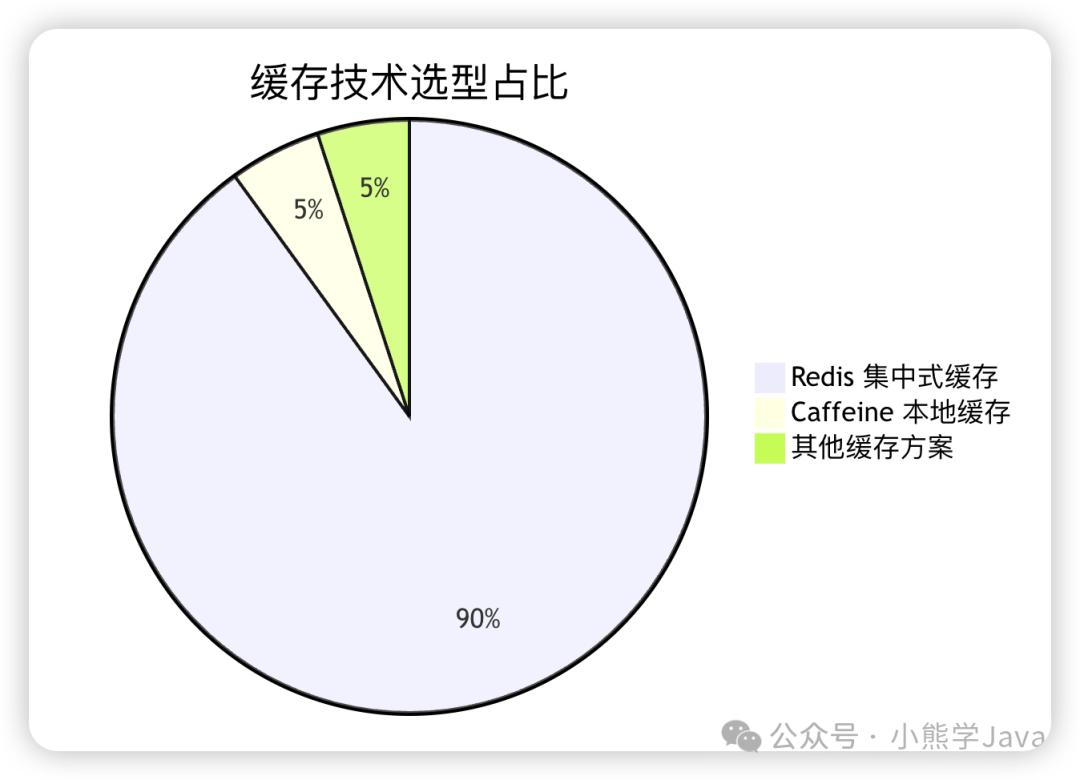
其实面试官的质疑很有道理。在 90% 的业务场景中,直接使用 Redis 就能满足需求,它简单可靠且不易出错。但 Caffeine 作为本地缓存解决方案,确实有其特定的适用场景。如果能清晰阐述选择它的理由和逻辑,反而会成为技术面试的加分项。
真实案例:POI 服务的性能瓶颈
服务背景介绍
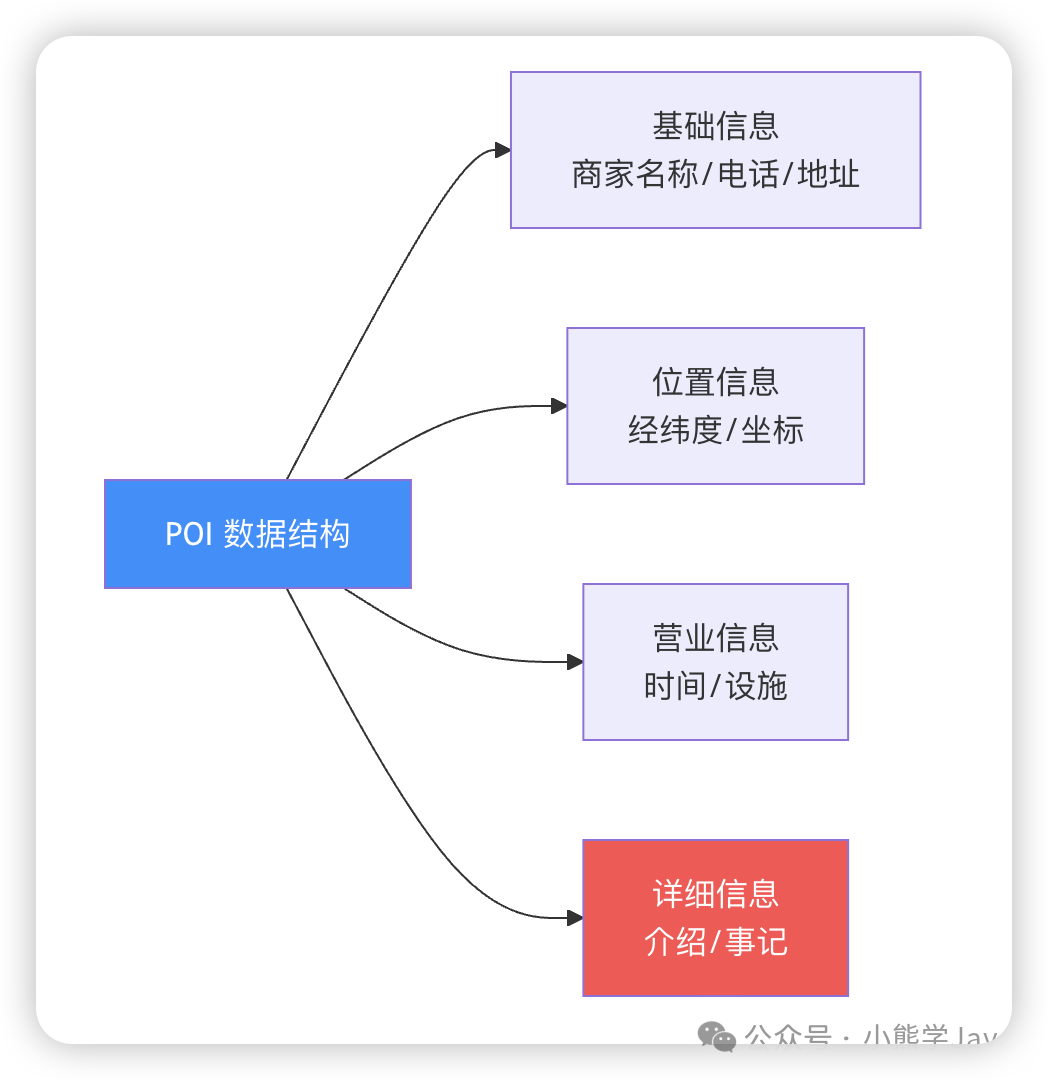
某大型外卖平台(用户量达亿级)的核心 POI 服务(Point of Interest)负责管理商家信息,包括肯德基、星巴克、海底捞等商家的详细信息。
这个服务的重要性不言而喻:QPS 峰值超过 10000,数十个上游系统依赖它(外卖、到店、酒旅、搜索、推荐等),一旦服务不可用,整个平台将陷入瘫痪。

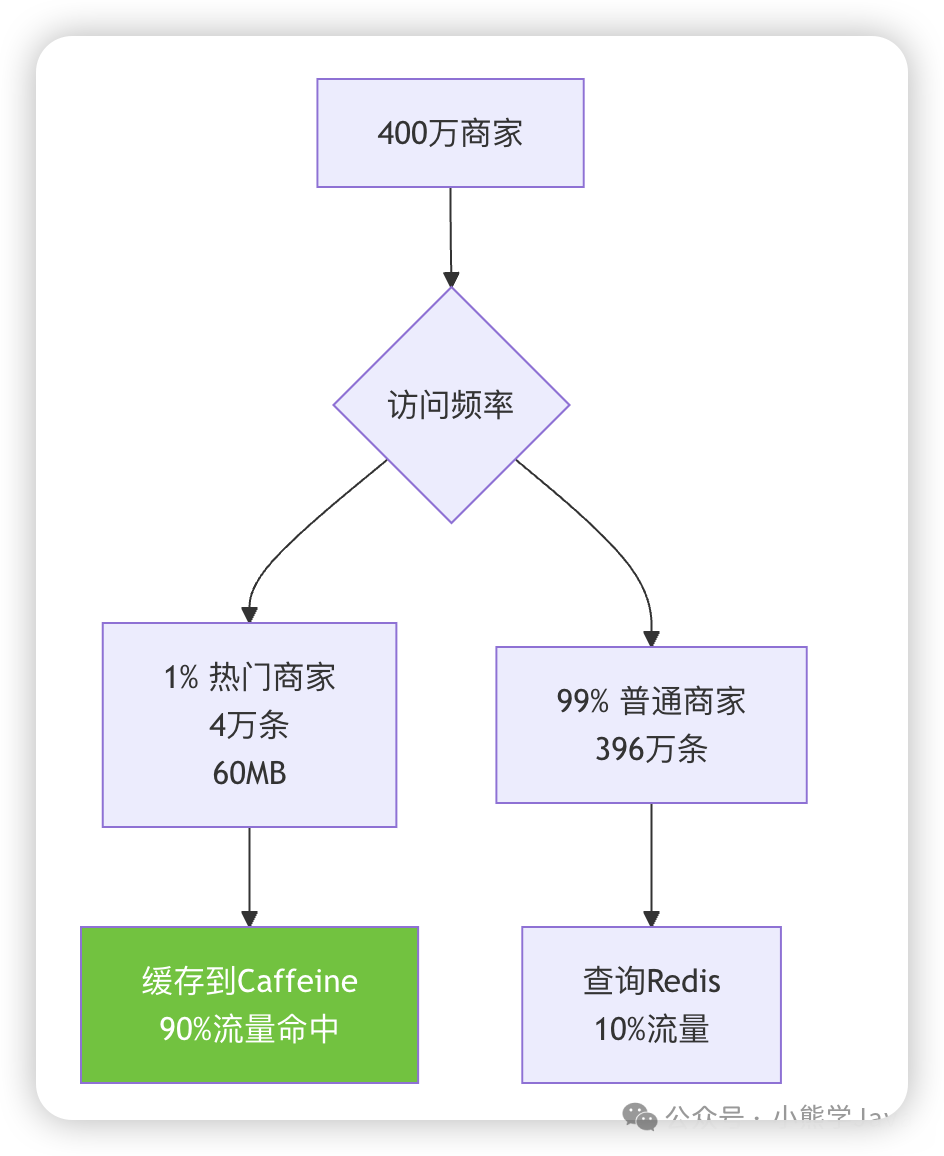
POI 服务存储的商家信息包含商家名称、联系电话、地址、经纬度坐标、营业时间、整体介绍等 30 多个字段。总数据量为 400 万条商家记录,每条记录平均 1.3KB,总数据量约 6GB。这些数据原本全部存储在 3 主 3 从的 Redis Cluster 中。
核心问题:Redis 网络带宽瓶颈
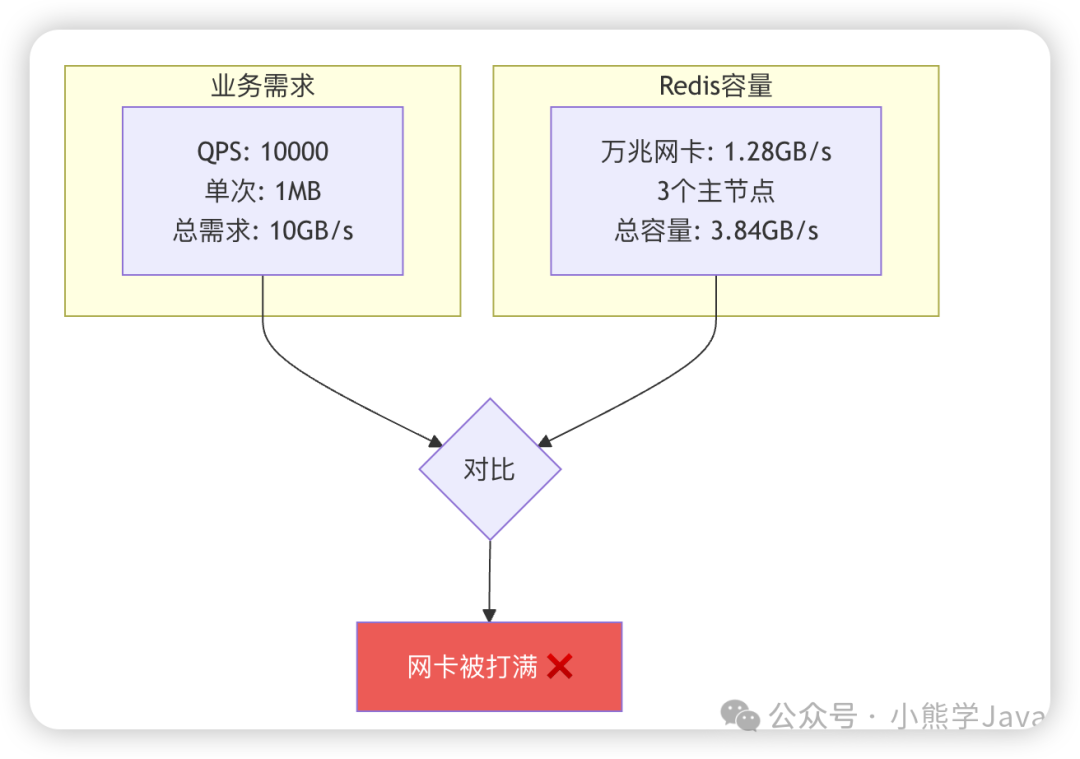
上游系统调用 POI 服务时通常采用批量查询方式(每次请求查询几十到上百个商家),平均每次请求返回 1MB 数据。在 QPS 峰值 10000 的情况下,所需网络带宽为 10000 × 1MB = 10GB/s。
而 Redis Cluster(3 主 3 从)的网络容量如何?万兆网卡理论速度为 1.28GB/s,只有 3 个主节点接收请求,总容量为 3 × 1.28 = 3.84GB/s。
结论:需求 10GB/s,实际容量只有 3.84GB/s,网络带宽成为瓶颈!
面对这个问题,我们考虑了两种解决方案。
方案一:Redis 扩容
从 3 主 3 从扩展到 12 主 12 从,网络容量提升到 15.36GB/s。这个方案简单直接,数据一致性有保障,但服务器成本增加 4 倍(从 6 台增加到 24 台)。
方案二:引入 Caffeine 本地缓存
利用现有的 12 台应用服务器,将热点数据缓存在应用服务器内存中。这个方案成本不变,响应速度更快,Redis 压力显著降低,但需要解决数据一致性和内存占用问题。
我们最终选择了方案二,关键原因在于我们发现了一个重要规律。
关键洞察:1% 的热点数据承载 90% 流量
通过分析一个月的访问日志,我们发现了一个显著规律:每个城市中 1% 的热门商家,承接了 90% 的访问流量。
以北京为例,虽然有 10 万家商家,但用户经常访问的只有约 1000 家(如肯德基、麦当劳、星巴克、海底捞等)。这是典型的二八定律,甚至可以说是一九定律。
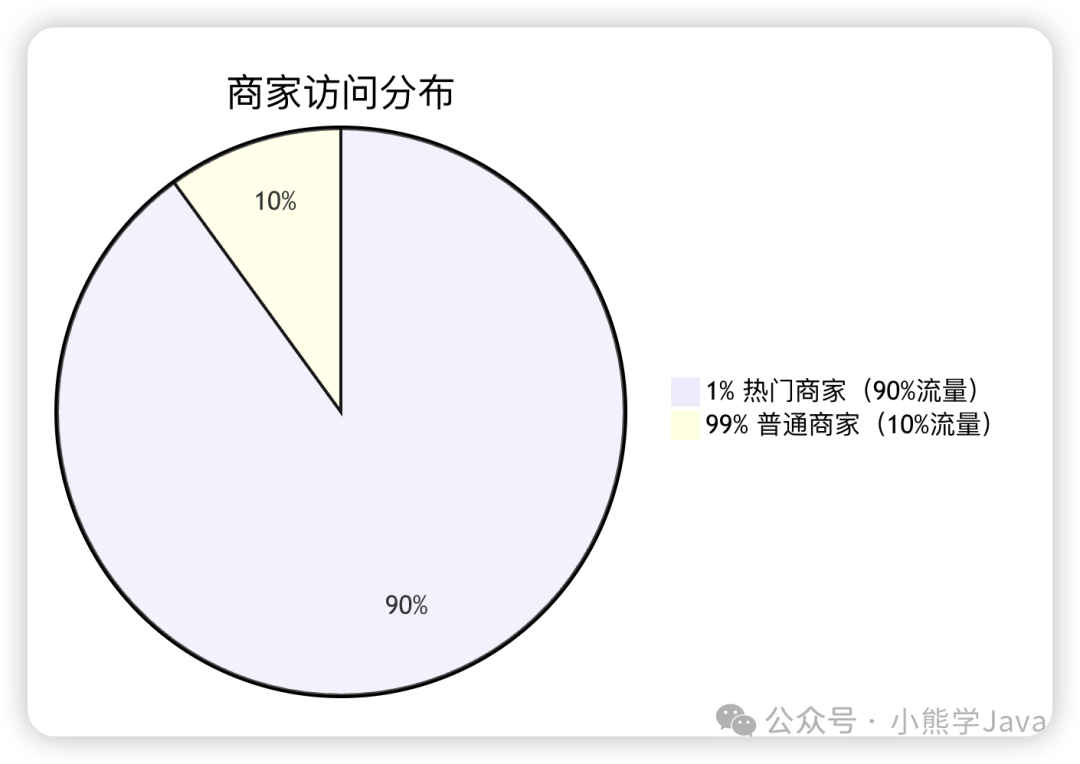
这个发现意味着我们只需要缓存这 1% 的热门商家数据即可:
| 项目 |
全量数据 |
热点数据(1%) |
| 数据量 |
400 万条 |
4 万条 |
| 内存占用 |
6GB |
60MB |
| 缓存命中率 |
100% |
90%+ |
用 60MB 内存换取 90% 的请求不经过网络,这个 trade-off 非常划算!
应用服务器配置为 4C8G,60MB 内存占用完全在可接受范围内。而且 Caffeine 使用 W-TinyLFU 算法,能够自动淘汰冷数据、保留热数据,无需手动维护。
三大技术挑战与解决方案
挑战一:数据一致性保障
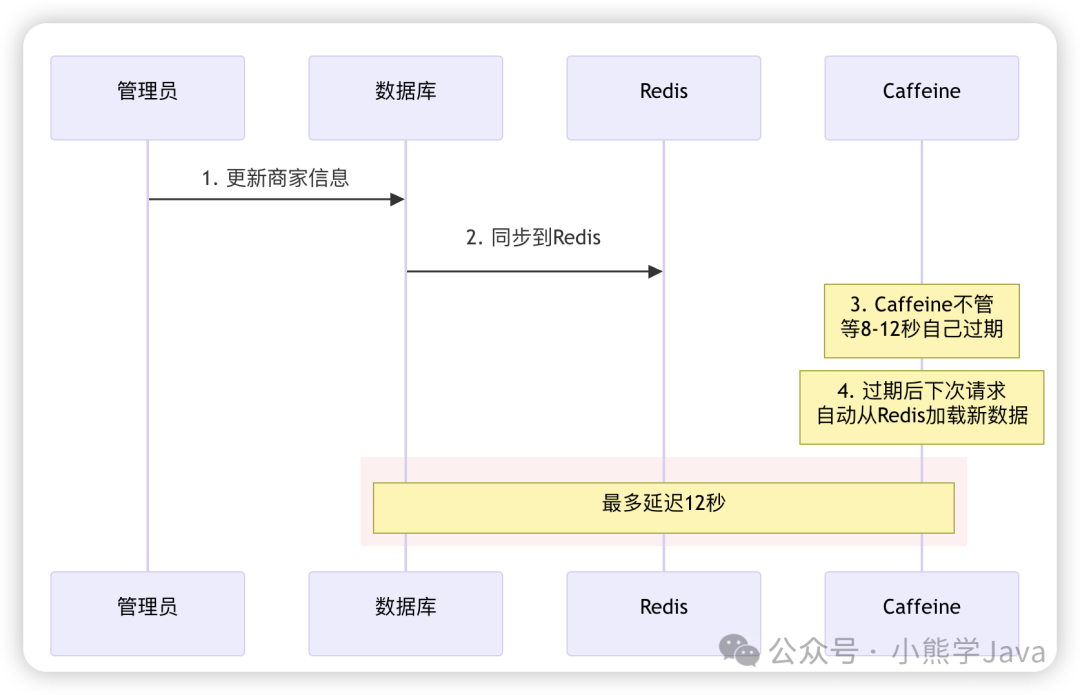
商家信息会发生变更(如修改营业时间、更新联系电话)。如果使用 Redis,只需在一个地方更新即可。但使用 Caffeine 后,数据分散在 12 台服务器上,如何保证数据同步?
传统做法是使用广播机制,在数据变更时通知所有服务器更新缓存,但这需要引入消息队列或发布订阅系统,增加了系统复杂度。
我们的解决方案:设置合理的过期时间
商家信息对实时性要求不高,营业时间变更延迟几秒生效是可以接受的。因此我们设置了 8-12 秒的随机过期时间:
Random random = new Random();
int expireSeconds = random.nextInt(5) + 8; // 8-12秒随机
Cache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.maximumSize(50_000)
.recordStats() // 开启统计
.build();
为什么使用随机过期时间?如果所有数据都在同一时刻过期,会导致大量请求同时打到 Redis,引发缓存雪崩。随机 8-12 秒的过期时间让数据分散过期,流量更加平滑。
挑战二:服务重启缓存预热
应用服务器重启后,Caffeine 缓存会丢失。如果预热 6GB 全量数据,需要数分钟时间。但我们只需要预热 60MB 的热点数据,3-5 秒即可完成!
@Component
public class CacheWarmUp implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
private PoiMapper poiMapper;
@Autowired
private Cache<String, Poi> cache;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
log.info("开始预热缓存...");
long start = System.currentTimeMillis();
// 只加载热门商家(按访问量排序,取前4万条)
List<Poi> hotPois = poiMapper.selectHotPoi(40000);
for (Poi poi : hotPois) {
cache.put(poi.getId(), poi);
}
long cost = System.currentTimeMillis() - start;
log.info("预热完成,加载 {} 条数据,耗时 {} ms", hotPois.size(), cost);
}
}
实际运行中,预热 4 万条数据仅需 3 秒左右,对服务启动时间影响很小。
挑战三:GC 性能影响
这是面试官最关心的问题。60MB 数据存放在堆内存中,是否会导致频繁 Full GC?
答案是:不会,因为数据量较小。
我们进行了压力测试,在 4C8G 的服务器上,60MB 的 Caffeine 缓存对 GC 的影响微乎其微。Young GC 频率没有明显变化,Full GC 几乎不会发生。
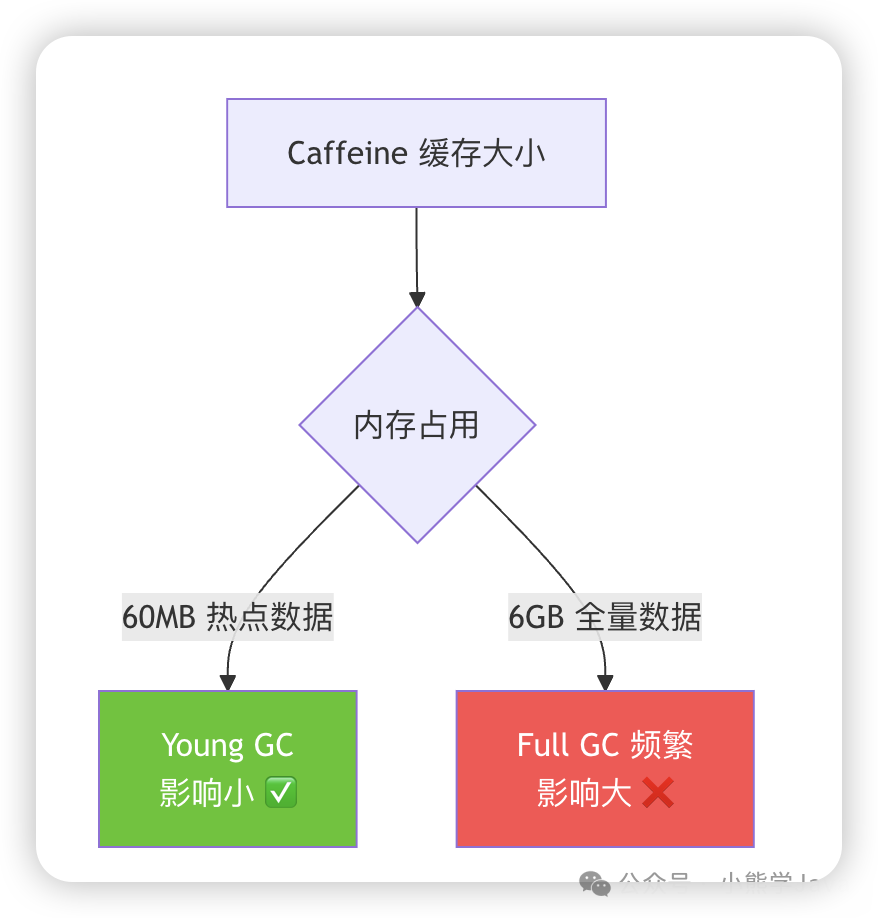
但如果需要缓存几个 GB 的数据,就需要谨慎考虑了。这时候可以使用堆外内存方案:
// 使用堆外内存(需要序列化)
Cache<String, byte[]> cache = Caffeine.newBuilder()
.maximumWeight(500 * 1024 * 1024) // 500MB
.weigher((key, value) -> value.length)
.build();
// 存储时序列化
cache.put(poiId, serialize(poi));
// 读取时反序列化
byte[] bytes = cache.getIfPresent(poiId);
Poi poi = deserialize(bytes);
但这会增加 CPU 开销(序列化/反序列化),需要根据具体场景权衡。对于我们的场景,60MB 数据直接存放在堆内存中已经足够。
完整代码实现
1. Caffeine 配置类
基于 Spring 框架的 Caffeine 配置
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String, Poi> poiCache() {
Random random = new Random();
int expireSeconds = random.nextInt(5) + 8; // 8-12秒随机
return Caffeine.newBuilder()
// 最大缓存 5 万条
.maximumSize(50_000)
// 写入后 8-12 秒过期
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
// 开启统计
.recordStats()
// 移除监听器(可选)
.removalListener((key, value, cause) -> {
log.debug("缓存移除:key={}, cause={}", key, cause);
})
.build();
}
}
2. 多级缓存查询实现
@Service
public class PoiService {
@Autowired
private Cache<String, Poi> cache;
@Autowired
private RedisTemplate<String, Poi> redisTemplate;
@Autowired
private PoiMapper poiMapper;
public Poi getPoi(String poiId) {
// 第一层:Caffeine 本地缓存
Poi poi = cache.getIfPresent(poiId);
if (poi != null) {
log.debug("命中 Caffeine 缓存:{}", poiId);
return poi;
}
// 第二层:Redis 缓存
String redisKey = "poi:" + poiId;
poi = redisTemplate.opsForValue().get(redisKey);
if (poi != null) {
log.debug("命中 Redis 缓存:{}", poiId);
// 回写到 Caffeine
cache.put(poiId, poi);
return poi;
}
// 第三层:数据库
poi = poiMapper.selectById(poiId);
if (poi != null) {
log.debug("查询数据库:{}", poiId);
// 回写到 Redis 和 Caffeine
redisTemplate.opsForValue().set(redisKey, poi, 1, TimeUnit.HOURS);
cache.put(poiId, poi);
}
return poi;
}
// 批量查询(上游系统常用)
public List<Poi> batchGetPoi(List<String> poiIds) {
List<Poi> result = new ArrayList<>();
List<String> missIds = new ArrayList<>();
// 先从 Caffeine 批量获取
for (String poiId : poiIds) {
Poi poi = cache.getIfPresent(poiId);
if (poi != null) {
result.add(poi);
} else {
missIds.add(poiId);
}
}
if (missIds.isEmpty()) {
return result;
}
// 未命中的从 Redis 批量获取
List<Poi> redisPois = redisTemplate.opsForValue().multiGet(
missIds.stream().map(id -> "poi:" + id).collect(Collectors.toList())
);
// 回写到 Caffeine
for (Poi poi : redisPois) {
if (poi != null) {
result.add(poi);
cache.put(poi.getId(), poi);
}
}
return result;
}
}
3. 缓存预热机制
@Component
public class CacheWarmUp implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
private PoiMapper poiMapper;
@Autowired
private Cache<String, Poi> cache;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
log.info("开始预热缓存...");
long start = System.currentTimeMillis();
// 只加载热门商家
List<Poi> hotPois = poiMapper.selectHotPoi(40000);
for (Poi poi : hotPois) {
cache.put(poi.getId(), poi);
}
long cost = System.currentTimeMillis() - start;
log.info("预热完成,加载 {} 条数据,耗时 {} ms", hotPois.size(), cost);
}
}
4. 缓存监控统计
@Component
public class CacheMonitor {
@Autowired
private Cache<String, Poi> cache;
@Scheduled(fixedRate = 60000) // 每分钟统计一次
public void monitorCache() {
CacheStats stats = cache.stats();
log.info("Caffeine 缓存统计:" +
"命中率={}, " +
"命中次数={}, " +
"未命中次数={}, " +
"加载成功次数={}, " +
"加载失败次数={}, " +
"驱逐次数={}",
String.format("%.2f%%", stats.hitRate() * 100),
stats.hitCount(),
stats.missCount(),
stats.loadSuccessCount(),
stats.loadFailureCount(),
stats.evictionCount()
);
// 命中率过低告警
if (stats.hitRate() < 0.8) {
log.warn("⚠️ Caffeine 缓存命中率过低:{}", stats.hitRate());
}
}
}
实施效果对比
上线后的性能改善非常显著:
| 指标 |
优化前(纯Redis) |
优化后(Caffeine+Redis) |
提升 |
| 平均响应时间 |
5ms |
1ms |
↓ 80% |
| P99 响应时间 |
15ms |
3ms |
↓ 80% |
| Redis QPS |
10000 |
1000 |
↓ 90% |
| Redis 网络流量 |
10 GB/s |
1 GB/s |
↓ 90% |
| Caffeine 命中率 |
- |
92% |
- |
| 服务器成本 |
需扩容到24台 |
保持12台 |
节省50% |
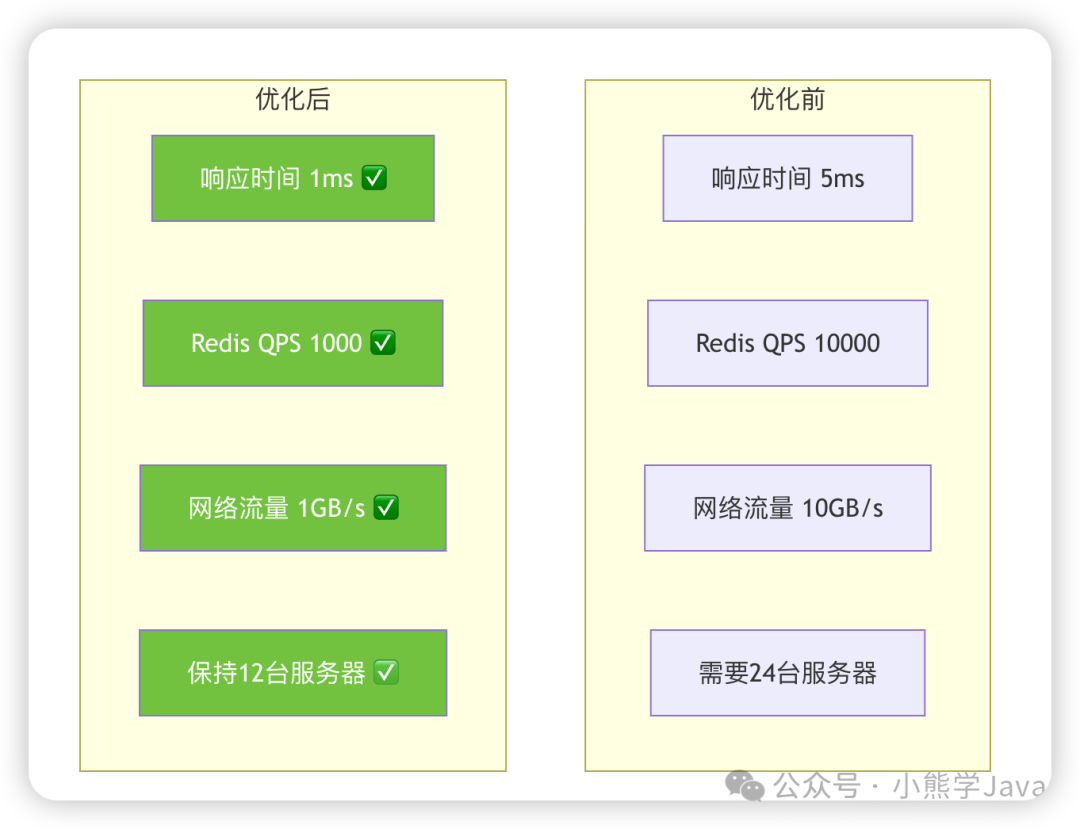
更重要的是,Redis 的压力降低了 90%,为后续业务增长预留了充足的容量空间。
Caffeine 适用场景分析
通过这个案例,我们总结了 Caffeine 的适用场景,必须同时满足三个条件:
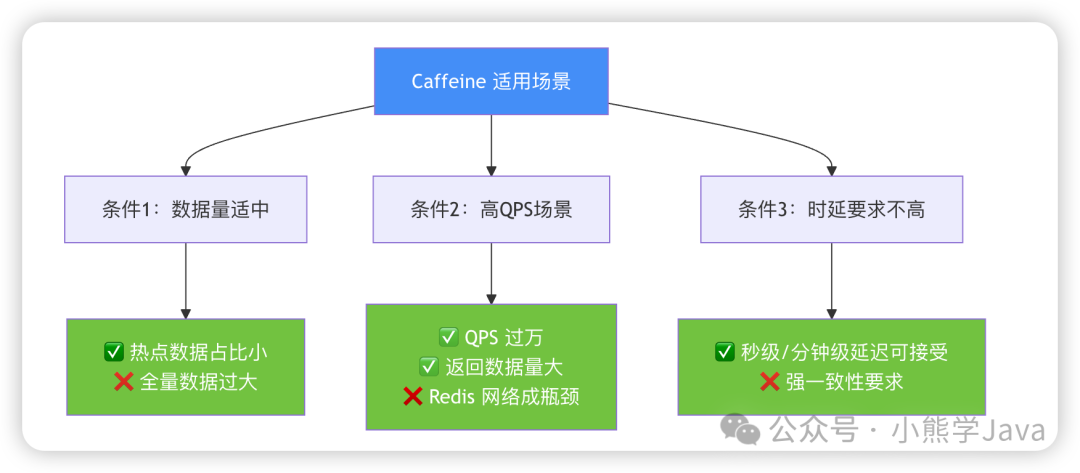
条件一:热点数据占比小
业务数据必须符合二八定律,少量热点数据承载大部分访问流量。如果数据访问分布均匀,每条数据都可能被访问,那么 Caffeine 就不适合。
判断方法:分析访问日志,查看 Top 1% 的数据占了多少流量。如果超过 80%,就符合条件。
内存占用限制:热点数据缓存后,内存占用不应超过 500MB,否则会影响 GC 性能。
条件二:高 QPS 且单次返回数据量大
Caffeine 的优势在于减少网络开销,因此只有在网络成为瓶颈时才有意义。
QPS 要求:至少 10000+,否则 Redis 完全能够满足需求。
数据量要求:单次请求返回数据 > 100KB,否则网络开销可以忽略不计。
计算公式:网络流量 = QPS × 单次数据量
如果计算出的网络流量超过了 Redis 集群的容量,就应该考虑使用 Caffeine。
条件三:对实时性要求不高
Caffeine 是本地缓存,数据更新后需要等待过期才能生效,因此只适合对实时性要求不高的场景。
可接受的延迟:秒级或分钟级
不适合的场景:强一致性要求(如金融交易、库存扣减、订单状态)
典型场景对比
| 场景 |
是否适合 Caffeine |
原因 |
| 商品详情页 |
✅ 非常适合 |
热点商品少,QPS高,延迟可接受 |
| 商家信息(POI) |
✅ 非常适合 |
本文案例 |
| 配置信息 |
✅ 非常适合 |
变更少,数据量小 |
| 字典数据 |
✅ 非常适合 |
几乎不变,数据量小 |
| 用户信息 |
⚠️ 看情况 |
需要考虑一致性 |
| 订单信息 |
❌ 不适合 |
强一致性要求 |
| 库存信息 |
❌ 不适合 |
实时性要求高 |
| 支付信息 |
❌ 不适合 |
强一致性要求 |
注意事项与最佳实践
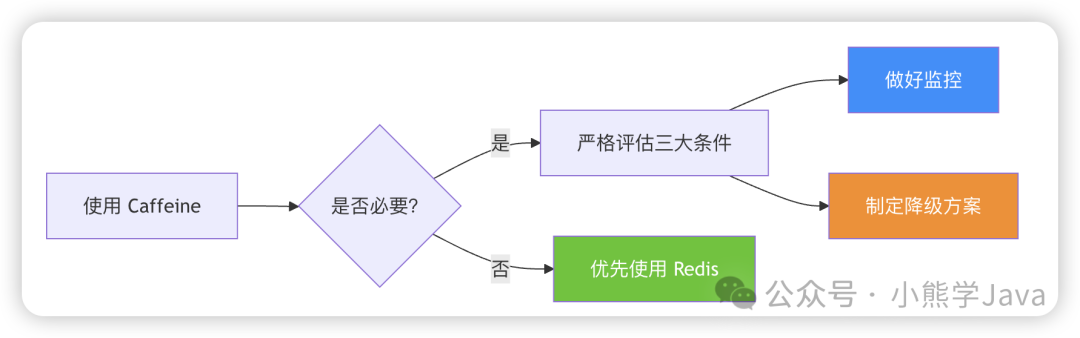
1. 完善的监控体系
Caffeine 的效果需要通过监控数据来验证。必须监控的关键指标:
@Component
public class CacheMonitor {
@Autowired
private Cache<String, Poi> cache;
@Scheduled(fixedRate = 60000)
public void monitorCache() {
CacheStats stats = cache.stats();
// 命中率
double hitRate = stats.hitRate();
log.info("Caffeine 命中率:{}", String.format("%.2f%%", hitRate * 100));
// 命中率过低告警
if (hitRate < 0.8) {
log.warn("⚠️ Caffeine 缓存命中率过低:{}", hitRate);
// 发送告警通知
}
// 驱逐次数
long evictionCount = stats.evictionCount();
if (evictionCount > 1000) {
log.warn("⚠️ Caffeine 驱逐次数过多:{}", evictionCount);
}
}
}
2. 降级方案准备
如果 Caffeine 出现异常(如命中率骤降、内存占用过高),需要能够快速切换回 Redis:
@Service
public class PoiService {
@Value("${cache.caffeine.enabled:true}")
private boolean caffeineEnabled;
public Poi getPoi(String poiId) {
try {
// 如果 Caffeine 开关关闭,直接查 Redis
if (!caffeineEnabled) {
return getFromRedis(poiId);
}
// 先查 Caffeine
Poi poi = cache.getIfPresent(poiId);
if (poi != null) {
return poi;
}
// 再查 Redis
poi = getFromRedis(poiId);
if (poi != null) {
cache.put(poiId, poi);
}
return poi;
} catch (Exception e) {
log.error("Caffeine 查询失败,降级到 Redis", e);
// 降级:直接查 Redis
return getFromRedis(poiId);
}
}
private Poi getFromRedis(String poiId) {
String redisKey = "poi:" + poiId;
Poi poi = redisTemplate.opsForValue().get(redisKey);
if (poi == null) {
poi = poiMapper.selectById(poiId);
if (poi != null) {
redisTemplate.opsForValue().set(redisKey, poi, 1, TimeUnit.HOURS);
}
}
return poi;
}
}
配置文件中的开关设置:
cache:
caffeine:
enabled: true # 可以通过配置中心动态调整
3. 防止缓存穿透
对于不存在的数据查询,缓存空对象避免每次请求都访问数据库:
private static final Poi NULL_POI = new Poi(); // 空对象标记
public Poi getPoi(String poiId) {
// 从 Caffeine 获取
Poi poi = cache.getIfPresent(poiId);
if (poi == NULL_POI) {
return null; // 之前查过,数据不存在
}
if (poi != null) {
return poi;
}
// 从 Redis 获取
poi = getFromRedis(poiId);
if (poi == null) {
// 数据不存在,缓存空对象
cache.put(poiId, NULL_POI);
return null;
}
cache.put(poiId, poi);
return poi;
}
4. 防止缓存击穿
热点数据过期时,可能瞬间有大量请求访问 Redis。Caffeine 提供 refreshAfterWrite 机制,可以异步刷新缓存:
LoadingCache<String, Poi> cache = Caffeine.newBuilder()
.maximumSize(50_000)
.expireAfterWrite(10, TimeUnit.SECONDS)
// 8秒后异步刷新,不会阻塞请求
.refreshAfterWrite(8, TimeUnit.SECONDS)
.build(key -> {
// 从 Redis 加载数据
return getFromRedis(key);
});
这样在数据即将过期时,Caffeine 会异步加载新数据,避免缓存击穿。
5. 合理设置过期时间
过期时间设置需要平衡:
- 过短(< 5秒): 缓存命中率低,频繁加载数据,失去缓存意义
- 过长(> 30秒): 数据更新延迟太大,影响用户体验
推荐:8-12 秒随机过期时间,既保证命中率,又控制延迟。
Random random = new Random();
int expireSeconds = random.nextInt(5) + 8; // 8-12秒
Cache<String, Poi> cache = Caffeine.newBuilder()
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build();
6. 内存占用监控
虽然只缓存 60MB 数据,但仍需定期检查内存使用情况:
@Scheduled(fixedRate = 300000) // 每5分钟检查一次
public void checkMemory() {
Runtime runtime = Runtime.getRuntime();
long totalMemory = runtime.totalMemory();
long freeMemory = runtime.freeMemory();
long usedMemory = totalMemory - freeMemory;
double usedPercent = (double) usedMemory / totalMemory * 100;
log.info("内存使用情况:总内存={}MB, 已用={}MB, 使用率={}%",
totalMemory / 1024 / 1024,
usedMemory / 1024 / 1024,
String.format("%.2f", usedPercent));
// 内存使用率超过 80% 告警
if (usedPercent > 80) {
log.warn("⚠️ 内存使用率过高:{}%", String.format("%.2f", usedPercent));
}
}
7. 灰度发布策略
引入 Caffeine 是重要架构变更,建议采用灰度发布:
第一步:在 1-2 台服务器上开启 Caffeine,观察效果
第二步:效果良好后,逐步扩展到 50% 的服务器
第三步:最终全量上线
配置中心控制:
cache:
caffeine:
enabled: true
gray-ratio: 0.1 # 10% 的流量使用 Caffeine
@Service
public class PoiService {
@Value("${cache.caffeine.gray-ratio:0}")
private double grayRatio;
public Poi getPoi(String poiId) {
// 根据灰度比例决定是否使用 Caffeine
boolean useCaffeine = Math.random() < grayRatio;
if (useCaffeine) {
return getFromCaffeine(poiId);
} else {
return getFromRedis(poiId);
}
}
}
Caffeine 与 Redis 的选型对比
很多人会问:既然 Caffeine 性能这么好,为什么不完全替代 Redis?答案是:Redis 和 Caffeine 解决的是不同维度的问题。
Redis 的核心价值
Redis 是分布式缓存,所有服务器共享同一份数据,数据更新立即生效,无需考虑同步问题。它可以存储几十 GB 甚至上百 GB 数据,不受应用服务器内存限制。同时支持复杂数据结构(List、Set、Hash、ZSet)、分布式锁、发布订阅等功能,运维体系成熟,具备完善的监控和高可用方案。
简而言之:Redis 稳定、可靠、功能全面,90% 的场景使用它就足够了。
Caffeine 的核心价值
Caffeine 是本地缓存,基于内存访问,响应时间达到纳秒级,没有网络开销和序列化成本。它能让 90% 的请求不经过网络,显著降低 Redis 压力,而且不需要额外服务器,充分利用现有应用服务器内存。
简而言之:Caffeine 速度快、成本低,但只适合特定场景。
技术选型决策逻辑
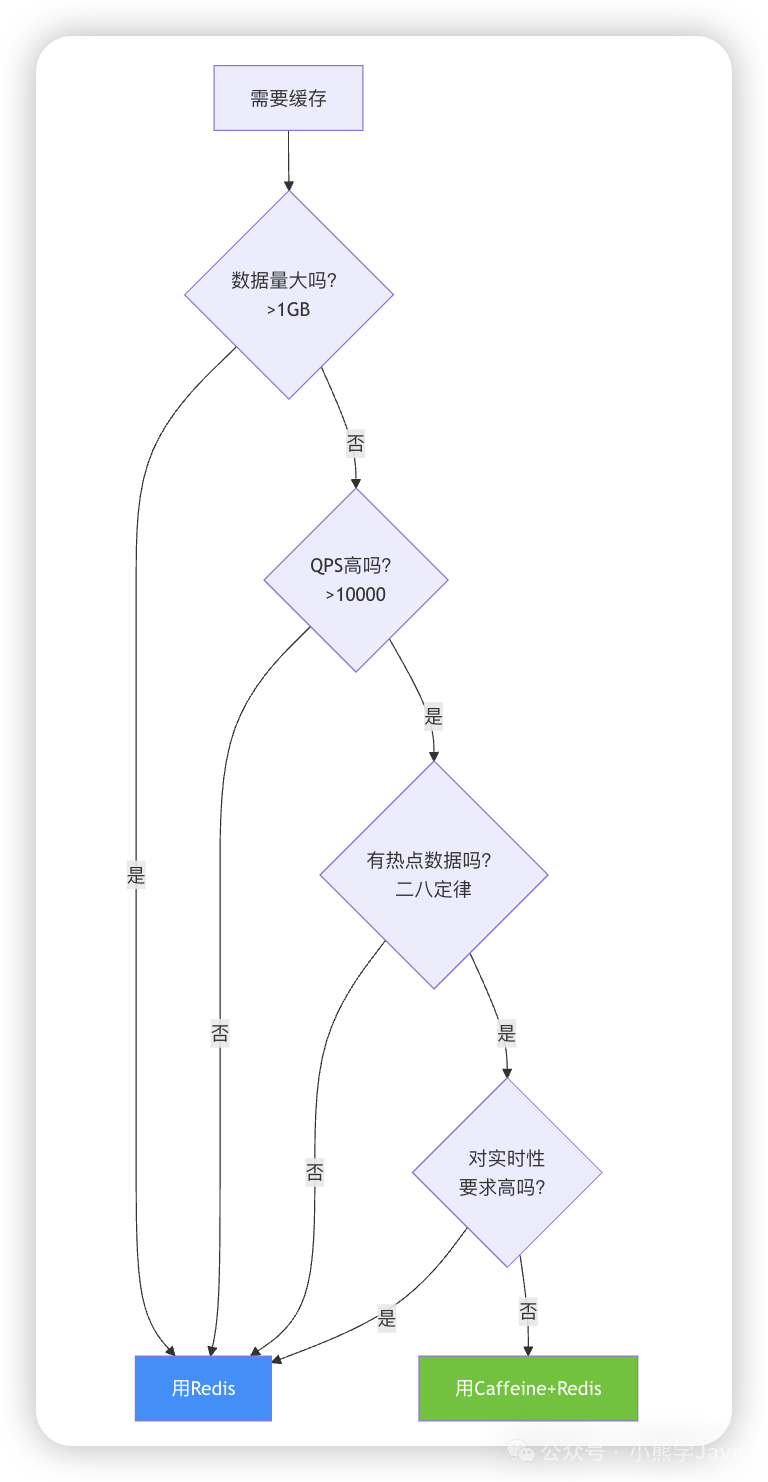
判断标准:
- 数据量 > 1GB?选择 Redis
- QPS < 10000?选择 Redis
- 数据访问分布均匀(无热点)?选择 Redis
- 要求强一致性?选择 Redis
- 以上条件都不满足?考虑 Caffeine + Redis 组合
最佳实践:两级缓存架构
在实际项目中,最优方案是 Caffeine + Redis 两级缓存:
第一层 Caffeine:缓存热点数据,承载 90% 流量,响应时间 < 1ms
第二层 Redis:缓存全量数据,承载 10% 流量,响应时间 < 5ms
第三层 MySQL:持久化存储,仅在缓存未命中时查询,响应时间 < 50ms
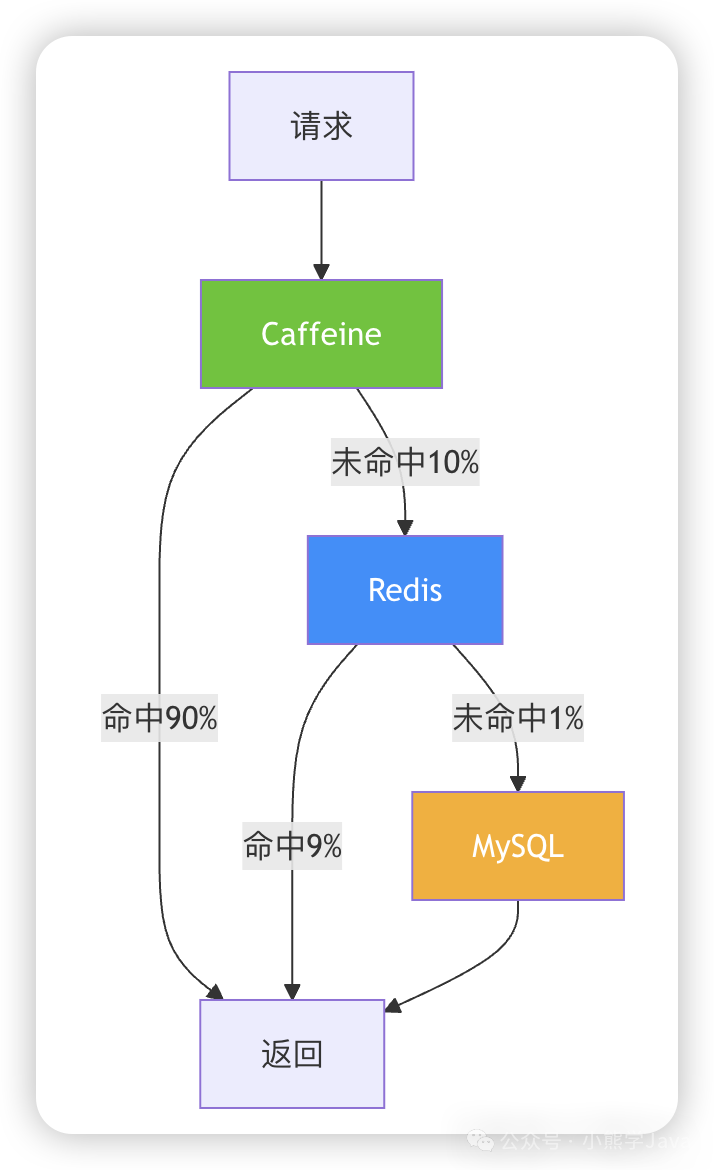
这种架构既保证了性能,又确保了数据一致性,同时还控制了成本。记住:Caffeine 不是要替代 Redis,而是要与 Redis 配合使用。
面试回答技巧
回到文章开头的面试场景,现在你知道该如何专业地回答这些问题了吗?
面试官:"为什么不用 Redis?"
欠佳回答:"因为 Caffeine 更快。"
专业回答:
"我们的业务场景具有以下特点:POI 服务 QPS 峰值超过 10000,单次请求返回 1MB 数据,需要 10GB/s 的网络带宽,但 Redis 集群只有 3.84GB/s 的容量,网络带宽成为瓶颈。
如果选择 Redis 扩容方案,需要从 6 台服务器扩展到 24 台,成本增加 4 倍。
我们通过分析访问日志发现,1% 的热门商家承载了 90% 的访问流量,符合二八定律。因此引入 Caffeine 缓存这 1% 的热点数据,仅需 60MB 内存就能让 90% 的请求不经过网络,Redis 压力降低 90%。
这样既解决了性能瓶颈问题,又避免了成本的大幅增加。"
面试官:"数据变更如何处理?"
欠佳回答:"使用消息队列通知所有服务器更新缓存。"
专业回答:
"商家信息对实时性要求相对宽松,营业时间变更延迟几秒生效是可以接受的。因此我们设置了 8-12 秒的随机过期时间,让缓存自然过期。
使用随机过期时间的原因是:如果所有数据在同一时刻过期,会导致大量请求同时访问 Redis,引发缓存雪崩。8-12 秒的随机过期让数据分散过期,流量更加平滑。
如果业务对实时性要求极高,我们会考虑使用 Redis 的发布订阅机制或消息队列进行数据同步,但这会增加系统复杂度。"
面试官:"服务重启怎么办?"
欠佳回答:"重启后缓存丢失,只能慢慢预热。"
专业回答:
"我们只缓存 60MB 的热点数据,服务启动时会自动执行预热流程,从数据库加载访问量最高的 4 万条商家信息,整个过程只需 3-5 秒。
如果缓存全量数据,确实需要较长的预热时间。但由于我们只缓存热点数据,预热速度很快,对服务启动时间影响很小。"
面试官:"会不会导致频繁 Full GC?"
欠佳回答:"应该不会吧..."
专业回答:
"我们进行了充分的压力测试,60MB 的 Caffeine 缓存对 GC 的影响可以忽略不计。应用服务器配置为 4C8G,60MB 只占堆内存的不到 1%,Young GC 频率无明显变化,Full GC 几乎不会发生。
如果需要缓存几个 GB 的数据,确实需要考虑 GC 问题。这时候可以使用堆外内存方案,但会增加序列化/反序列化的 CPU 开销。
对于我们的具体场景,60MB 数据直接存放在堆内存中是完全可行的。而且 Caffeine 使用 W-TinyLFU 算法,能够自动淘汰冷数据,避免缓存无限增长。"
核心总结
关键观点
1. 90% 的场景 Redis 已足够
不要为了技术炫技而引入 Caffeine。Redis 简单、可靠、运维成熟,在大多数场景下都是最优选择。
2. Caffeine 不是万能解决方案
只有在 Redis 网络带宽成为瓶颈,且数据访问符合二八定律,且对实时性要求不高的特定场景下,才考虑使用 Caffeine。
3. 三个必要条件必须同时满足
- 热点数据占比小(< 5%)
- QPS 高且单次数据量大(网络成为瓶颈)
- 对实时性要求不高(秒级延迟可接受)
4. 完善的监控和降级机制
引入 Caffeine 后,必须严格监控命中率、内存占用、GC 情况。一旦出现问题,要能够快速切换回 Redis。
典型场景快速参考
| 场景 |
推荐方案 |
原因 |
| 电商商品详情 |
Caffeine + Redis |
热点商品少,QPS高,延迟可接受 ✅ |
| 外卖商家信息 |
Caffeine + Redis |
本文案例,完美匹配 ✅ |
| 系统配置信息 |
Caffeine |
几乎不变,数据量小 ✅ |
| 字典数据 |
Caffeine |
变更少,数据量小 ✅ |
| 用户基本信息 |
Redis |
数据量大,访问均匀 ⚠️ |
| 用户会话信息 |
Redis |
需要分布式共享 ⚠️ |
| 订单信息 |
Redis |
强一致性要求 ❌ |
| 库存信息 |
Redis |
实时性要求高 ❌ |
| 支付信息 |
Redis |
强一致性要求 ❌ |
| 实时排行榜 |
Redis |
需要 ZSet 数据结构 ❌ |
常见问题解答
Q1:Caffeine 是否会导致数据不一致?
A: 会存在数据不一致,但在可控范围内。
Caffeine 作为本地缓存,数据更新后需要等待过期才能生效,最大延迟为 12 秒。如果业务对实时性要求很高(如订单状态、库存信息),就不适合使用 Caffeine。
但对于商家信息、商品详情等对实时性要求不高的场景,12 秒的延迟是可以接受的。
Q2:多台服务器的 Caffeine 缓存如何同步?
A: 不需要主动同步,依靠过期机制即可。
如果要求同步,需要引入消息队列或发布订阅系统,这会显著增加系统复杂度。而且即使进行同步,也无法保证强一致性(存在网络延迟、消息丢失等风险)。
因此最简单的方案是:不进行同步,让缓存自然过期。反正最大延迟只有 12 秒,用户通常感知不到。
Q3:Caffeine 缓存的数据是否会丢失?
A: 会丢失,但这不影响系统功能。
Caffeine 是基于内存的缓存,服务重启后数据会丢失。但我们有 Redis 和数据库作为后备存储,缓存丢失只会影响性能,不会影响系统功能。
而且我们设计了预热机制,服务启动后 3-5 秒即可恢复正常性能。
Q4:Caffeine 适合缓存大对象吗?
A: 不适合。
如果单个对象超过 1MB(如图片、视频等),不建议使用 Caffeine 缓存,原因包括:
- 内存占用过大
- 序列化/反序列化开销大
- 容易引发 Full GC
大对象建议直接存储在 Redis 或对象存储(OSS)中。
Q5:Caffeine 和 Redis 哪个性能更好?
A: Caffeine 性能更好,但不能替代 Redis。
Caffeine 基于内存访问,响应时间达到纳秒级,比 Redis 快约 1000 倍。但 Caffeine 是本地缓存,无法跨服务器共享,也不能保证数据一致性。
因此两者不是竞争关系,而是互补关系。最佳实践是 Caffeine + Redis 的两级缓存架构。
Q6:Caffeine 是否会导致内存溢出?
A: 不会,因为有完善的淘汰机制。
Caffeine 配置了 maximumSize 参数,超过设定大小时会自动淘汰访问频率较低的数据。而且使用 W-TinyLFU 算法,会优先淘汰访问频率低的数据。
只要合理设置 maximumSize 参数,就不会出现内存溢出的问题。
Q7:Caffeine 适合缓存用户信息吗?
A: 需要根据具体情况判断。
如果用户信息变更频率较低(如用户昵称、头像等),可以考虑使用 Caffeine。
如果用户信息变更频率较高(如用户余额、积分等),不建议使用 Caffeine,因为数据一致性问题会比较严重。
Q8:Caffeine 和 Spring Cache 有什么区别?
A: Spring Cache 是抽象层,Caffeine 是具体实现。
Spring Cache 提供了 @Cacheable、@CacheEvict 等注解,简化了缓存的使用。底层可以使用 Caffeine、Ehcache、Redis 等多种实现。
如果项目使用 Spring 框架,建议采用 Spring Cache + Caffeine 的组合,代码更加简洁。
技术选型要基于实际业务场景,而不是为了技术炫技。
除非业务场景确实需要,否则不要盲目将 Redis 和 Caffeine 混合使用。
因为这会引入新的数据一致性问题,可能得不偿失。
记住:简单的方案往往是最优的方案。
 发表于 2025-11-27 02:57:30
|
查看: 244|
回复: 0
发表于 2025-11-27 02:57:30
|
查看: 244|
回复: 0
