背景与挑战
随着人工智能技术的飞速发展,大模型训练规模正迅速从千卡向万卡级别演进。在这一过程中,算力基础设施面临的主要瓶颈已不再单纯是“GPU 规模不足”,而是转向了更为复杂的“算力调度与资源利用效率不足”。
在实际生产环境中,我们普遍面临着以下严峻挑战:
- 资源浪费严重:GPU 利用率长期徘徊在 60% 以下,大量昂贵的算力资源处于“空跑”状态。
- SLA 难以保障:高价值的训练任务常被低优先级任务排队挤占,导致关键业务无法按时交付。
- 通信性能抖动:多机 NCCL 通信极易受网络拓扑影响,造成训练性能大幅波动。
- 使用门槛高:GPU 的各类共享机制复杂,普通开发者难以高效利用。
- 调度感知局限:NUMA 亲和性调度往往仅在单节点内生效,集群级调度器无法感知全局 NUMA 资源分布。
当集群规模达到千卡、万卡级别时,传统的 Kubernetes 调度能力已无法支撑大模型训练对稳定性与效率的苛刻需求。基于多年在大规模算力调度领域的实战积累,360 AI 开发平台内部打造了一套高效、稳定且易用的 HBox 算力调度平台,旨在支撑万卡乃至更大规模的算力集群。
HBox 算力调度平台概览
HBox 是面向大规模 AI 集群的一体化算力调度平台。它的目标并非单点提升 GPU 的共享能力,而是系统性地解决算力调度难题。HBox 整合了多种核心调度功能:
- 算力池化:实现资源的灵活分配与复用。
- SLA 调度保障:确保关键任务的资源供给。
- 网络感知调度:优化分布式训练的通信效率。
- GPU 虚拟化整合:提供多层次的资源隔离与共享方案。
- NUMA 亲和性调度:最大化硬件性能。
- 国产化芯片支持:适配多元化的算力生态。
- 自动故障检测:构建高可用的运行环境。
通过多维度的调度协同,HBox 实现了在保证任务稳定性的前提下,大幅提高 GPU 资源的整体利用率。
资源分类与算力池化
随着集群规模与业务类型的快速增长,算力平台需要同时承载大规模训练、在线部署、弹性计算、关键生产及测试验证等多种类型的工作负载。这些任务在性能稳定性、资源独占性、调度灵活性及成本敏感度方面存在显著差异。若采用单一的资源分配模型,极易导致高优任务受资源争抢影响、普通任务资源浪费或整体利用率下降,难以兼顾 SLA 保障与运营收益。
HBox 算力调度平台对集群资源进行了分类管理,针对异构业务负载的差异,将集群统一划分为三类资源池:
| 资源类型 |
适用场景 |
资源特点 |
| 公共资源 |
普通计算任务、测试任务 |
• 所有用户可访问
• 高峰期无法保证稳定的资源分配
• 适合对延迟/专属硬件要求不高的任务 |
| 池化资源 |
生产任务、弹性任务、无需占用整机资源的任务 |
• 为用户提供基本的资源保障,同时允许超额使用空闲资源
• 支持闲时共享、弹性调度,提高利用率
• 可设置优先级/抢占策略 |
| 独占资源 |
延迟敏感业务、关键生产任务、大规模训练任务、需整机运行的任务 |
• 强隔离保证性能稳定
• 不受其他任务干扰
• 提高 SLA 和预测性 |
对比传统集群调度:
| 维度 |
传统统一集群 |
HBox 三池模型 |
| SLA 保障 |
不稳定 |
按池级保障 |
| 资源利用率 |
30~60% |
70~90% |
| 算力弹性 |
不可控 |
按任务精细复用 |
| 运维成本 |
高 |
平台统一治理 |
HBox 的三池模型能够在保障高性能的前提下,兼顾业务灵活性、资源利用率和收益提升:
- 分级隔离:资源隔离程度由低到高依次为:公共资源 < 池化资源 < 独占资源。
- 按需匹配:不同任务可根据需求选择最合适的资源池,避免资源浪费或性能受限,提升用户体验。
- 降本增效:合理划分集群资源,不仅降低了闲置成本,还能通过弹性调度和多租户管理提高集群整体收益。
基于优先级的抢占调度
在同一部门的共享资源池中,生产任务、测试任务和开发任务通常并存,资源竞争在所难免。为了保障关键业务的服务等级协议(SLA),HBox 引入了基于队列与优先级的调度模型,实现了业务的天然隔离与等级保障。
调度机制详解:
- 独立资源队列:每个部门对应独立的资源队列。
- 三级优先级划分:
- 高优先级:可抢占低优任务,自身不可被抢占。
- 中优先级:拥有固定保障,不参与抢占。
- 低优先级:可以被高优任务抢占。
下图展示了高优先级任务抢占低优先级任务的逻辑:
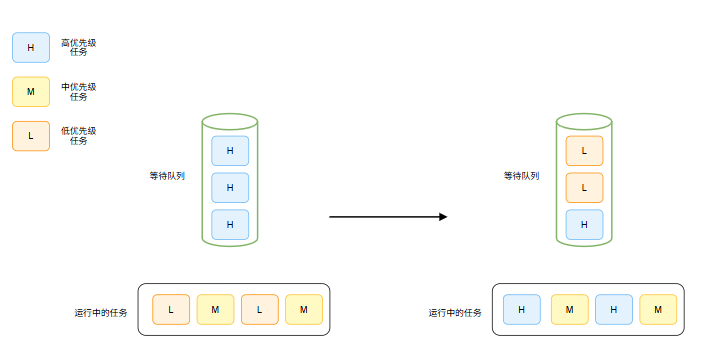
在 360 AI 开发平台内部启用抢占调度功能后,达成如下效果:
- 核心业务抢占成功,无需排队等待。
- 开发、调试任务自动利用碎片算力。
- SLA 的可预测性显著提升。
网络拓扑感知调度
在网络密集型的 AI 大模型训练与推理场景中,传统的资源调度策略往往仅关注计算资源(GPU、内存、CPU)的可用性,而忽视了计算节点间的网络拓扑结构对整体性能的关键影响。为此,我们设计并实现了基于网络拓扑感知的调度策略,将集群网络结构纳入调度决策的核心考量。
HBox 算力调度平台通过以下两个组件来实现网络拓扑感知调度:
- 网络拓扑探测器:
- 利用 NVIDIA UFM 实时采集 IB 交换机与端口链路信息。
- 构建全局通信拓扑树。
- Network Topology Aware Scheduler:
- 调度时综合评估节点通信收益。
- 优先将同一作业的 Pods 分配至通信最优路径的节点。
网络拓扑探测器工作原理:使用 UFM 收集 IB 交换机、IB 网卡的连接情况,基于此生成网络拓扑树。树的叶子节点是物理机,非叶子节点是交换机。一个物理节点可能含有多个 IB 网卡,从而连接到多个交换机上。
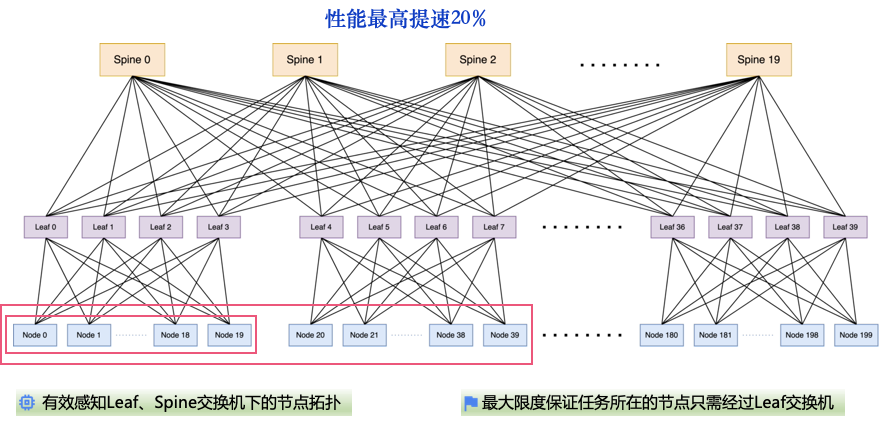
K8s 调度器策略:HBox 的 K8s 调度器组件在为分布式任务分配资源时,会依据网络拓扑树进行决策。用户创建任务时,可选择以下几种网络拓扑策略:
- none:无需网络感知。
- bestEffort:尽量分配通信最优节点。
- singleSwitch:任务的所有 Pod 必须运行在同一个交换机连接的节点上。如果集群无法满足,则禁止分配资源。
实测收益:
- NCCL 通信延迟(latency)下降 20%。
- 集群调度的稳定性显著提高。
GPU 虚拟化
在使用 GPU 进行大规模 AI 模型训练时,海量数据通过 GPU 并行批处理,资源利用率较高。然而,对于交互式 Notebook、小规模或低负载的模型推理服务,往往只需要 GPU 的部分算力。此时,若能让多个计算任务共享同一张 GPU,将极大地提高资源利用率和投资回报率。
6.1 背景:NVIDIA 共享策略
目前主流的 NVIDIA GPU 提供了几种常见的共享机制:
Time-Slicing(时间片轮转)
- 描述:多个容器/进程轮流占用物理 GPU 的计算时间片。GPU 不做物理切分,每个 Pod 看到“完整 GPU”,由驱动进行上下文切换。
- 优点:部署成本低,调度弹性强,零硬件门槛。
- 缺点:无资源隔离(显存不可控),无显存限额(易导致 OOM 连锁崩溃)。
MPS(Multi-Process Service)
- 描述:进程级并发共享机制,通过 MPS Server 合并多个 CUDA 进程的 context,减少切换开销。
- 优点:支持进程显存限制,性能优于 Time-Slicing,零硬件门槛。
- 缺点:无容器级别显存限制(只能限制进程级)。
MIG(Multi-Instance GPU)
- 描述:硬件级切片,单个 GPU 分割为最多 7 个独立实例(独立 SM、显存、Cache)。
- 优点:强硬件隔离,可叠加其他共享技术,支持分区监控。
- 缺点:硬件门槛高(A 系列及以上),切片规格固定且变更成本大。
vGPU
- 描述:虚拟化技术,借助 Hypervisor + vGPU Manager 将物理 GPU 映射为多个虚拟 GPU。
- 优点:完整虚拟化,强隔离性(独立显存配额、地址空间),支持动态切分。
- 缺点:性能损耗较大(10–20%+),管理复杂,商用授权昂贵。
6.2 HBox 虚拟化策略
HBox 算力调度平台集成 NVIDIA MIG 与 HAMi vGPU 两种主流方案,构建了一套互补的 GPU 资源管理体系,提供从物理级隔离到虚拟化共享的全栈解决方案。
NVIDIA MIG 策略
HBox 将 MIG 实例作为底层的、可被调度的离散资源单元进行管理。
- 特点:硬件隔离、安全可靠、性能稳定。
- 适用场景:核心业务推理、多租户环境、HPC 与高性能训练。
HAMi vGPU 策略
HBox 引入 HAMi 作为软件定义的虚拟化层,通过拦截 CUDA API 指令和显存管理,实现细粒度资源切分。
- 特点:
- 细粒度切分:支持以 1% 为单位的算力切分和以 MB 为单位的显存切分,拒绝资源虚占。
- 使用灵活:用户按标准化规格(如“8GB-算力型”)申请,无需感知底层硬件。
- 广泛兼容:支持多种类型显卡。
- 适用场景:开发与调试环境(Notebook)、中小规模推理与边缘场景。
推荐的 GPU 使用方案:
| 场景 |
推荐方案 |
| Notebook |
HAMi |
| 轻量推理 |
HAMi |
| SLA 严格推理 |
MIG |
| 大规模训练 |
独占 GPU |
通过统一的 GPU 设备插件与资源模型,HBox 屏蔽了底层实现差异,用户仅需按标准化 vGPU 规格申请资源,即可覆盖全场景算力需求。
NUMA 拓扑感知调度
在 GPU 显存和 CPU 内存频繁交互的场景下,跨 NUMA 节点的资源访问会导致高延迟和低带宽,严重影响效率。HBox 平台对此进行了深入优化。
7.1 现状:单节点 NUMA 感知
目前,HBox 已在单节点范围内启用 NUMA 拓扑感知调度,通过精细化配置 Kubernetes 节点资源管理组件,实现 CPU、内存、GPU 在 NUMA 节点内的就近分配。
关键配置与实践:
- Kubelet 配置:
CPU Manager Policy: static:实现精确的 CPU 绑定。Topology Manager Policy: best-effort:尽可能对齐资源的 NUMA 拓扑关系。
- 用户任务约束:
- Pod 需满足 Guaranteed QoS。
- CPU 资源以整数核申请。
- 实战经验:
- 关闭 lxcfs:lxcfs 会虚拟化
/proc 与 /sys,可能导致用户态程序误判 NUMA 拓扑,建议在敏感场景关闭。
- 合理配置 NPS (NUMA Per Socket):根据硬件拓扑和业务特性,在 BIOS 层设置合适的 NPS 值,优化底层 NUMA 结构。
7.2 计划:集群级 NUMA 调度
未来,HBox 将实现集群级的 NUMA 调度能力。调度器将全局感知 CPU 与 GPU 的 NUMA 拓扑状态,精确筛选满足拓扑约束的最优节点。
设计架构:
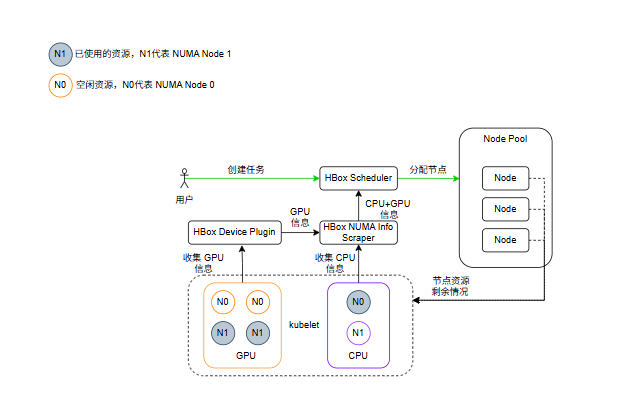
实现原理:
- 拓扑状态采集:HBox 组件持续采集节点侧 CPU 和 GPU 在各 NUMA node 上的可用资源及拓扑关系。
- 感知决策:集群调度器在筛选节点时,对候选节点进行 NUMA 亲和性打分,优先选择能最大化 CPU–GPU 本地性和资源连续性的节点。
GPU 与 CPU 灵活配比调度
在传统 AI 基础设施中,GPU 节点上的 CPU 与内存资源通常静态绑定,导致 GPU 密集型任务(如大模型推理)运行时,大量 CPU 核心处于闲置状态。
HBox 计划引入 GPU/CPU 灵活配比调度 能力,在集群中划分出特定节点,支持混合运行:
- GPU 任务:以 GPU 计算为主(训练/推理),分配有限 CPU。
- CPU 任务:以 CPU 计算为主(数据预处理、特征工程、Proxy 等),利用剩余 CPU 资源。
这种机制能充分利用闲置 CPU 算力,缩短任务排队周期,并大幅提升集群整体的资源投资回报率。
国产化芯片调度支持
HBox 在国产化芯片适配方面积累了丰富经验,特别是在昇腾 910B 和 310P 系列的调度上。
针对昇腾 AI 处理器内部 HCCS 互联的特点(同一 HCCS 内处理器通信效率高),HBox 基于 ascend-for-volcano 插件进行了深度优化。在创建任务时,调度器会尽可能将任务分配到同一个 HCCS 互联的处理器上,最大化计算性能。
未来,HBox 将持续丰富对海光 DCU 等国产芯片的支持,并在虚拟化与资源共享方面深入探索,助力国产算力落地。
稳定性建设
为保障大规模 GPU 集群的高可用性,HBox 构建了一套覆盖硬件、驱动、通信与调度层的全链路监控体系,核心组件为 qihoo-smi。
10.1 异构算力深度适配
HBox 全面适配了 NVIDIA A100、A800、H800、H100、H200、L20 等主流机型,通过 K8s 标签精确控制监控组件部署。
10.2 多维度故障监测与 运维
- GPU 故障处理:
- 掉卡/NVLink 异常:每分钟检测,发现异常立即 Cordon 节点并报警。
- ECC 错误:针对双位不可校验错误隔离节点,闲时尝试重置自愈。
- 关键服务保活:自动拉起崩溃的
Nvidia-Fabricmanager。
- XID 错误捕捉:实时监控典型 XID 错误并隔离。
- 网络与扩展资源:
- 网卡监控:检测 Mellanox 网卡降级或断连,恢复后自动 Uncordon。
- 模块自愈:自动加载缺失的
nvidia_peermem 内核模块。
- 性能与稳定性:
- 慢节点检测:通过 NCCL-Tests 发现性能“长尾”节点。
- API-Server 连接:监测节点与控制面通信,触发自愈逻辑。
通过智能化告警、豁免机制及数据分析,HBox 实现了故障的快速感知与闭环处理。
总结与展望
HBox 算力调度平台通过三池模型、优先级抢占、网络与 NUMA 双感知、虚拟化融合及灵活配比等关键技术,构建了一套面向万卡规模 AI 集群的高效调度体系。它成功在复杂多变的负载环境中平衡了资源利用率、业务稳定性与调度公平性。
展望未来,HBox 将从目前的 Kubernetes Device Plugin 模式向 动态资源分配(Dynamic Resource Allocation, DRA) 机制演进。通过声明式资源请求与调度器的原生协同,实现对硬件资源更精细、动态的管理,以支撑未来更加多样化的算力场景。
 发表于 2026-1-5 19:13:18
|
查看: 289|
回复: 0
发表于 2026-1-5 19:13:18
|
查看: 289|
回复: 0
