当启动一个数据库时,我们总是希望它能迅速就绪以提供查询服务。然而,你是否遇到过这种情况:执行启动命令后,数据库却长时间无法响应连接请求。
如果是异常关闭后崩溃恢复,因需要重放大量 REDO 日志而导致等待,这尚可理解。但如果是正常关闭的状态,启动时为何也需要漫长的等待时间?这背后可能与一个关键的机制——RESTARTPOINT有关。
PostgreSQL启动的核心:检查点
PostgreSQL的启动依赖检查点。在数据库运行期间,系统会定期(根据时间或WAL日志积累量)触发检查点。主库的检查点负责将共享缓冲区中的脏页刷入磁盘,并写入一条检查点WAL记录,同时将最新的检查点信息更新到控制文件 pg_control 中。当主库重启时,便可以从WAL日志中读取这个检查点,并据此找到重做点,以此作为崩溃恢复或正常启动的起点。
那么,备库是如何处理的呢?备库没有检查点,但有一个类似的机制叫 RESTARTPOINT。它同样承担刷脏页的重任,但备库本身并不产生WAL日志。这就引出一个问题:备库的 RESTARTPOINT 如何将自己执行的信息记录到控制文件中?或者说,备库在将来重启时,如何知道应该从哪个位点开始回放日志?
RESTARTPOINT 机制详解
PostgreSQL启动时会从 pg_control 文件中读取检查点信息,其中记录了重做点,启动过程便从此点开始回放WAL日志。
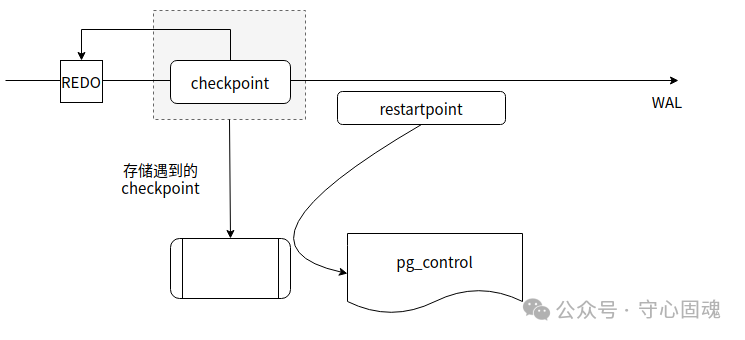
对于主库而言,每次成功执行完一个检查点,都会自动将其信息写入 pg_control。
对于备库而言,其机制有所不同。当备库回放WAL日志遇到一个来自主库的检查点时,它并不会立即执行 RESTARTPOINT,而是先将这个检查点的信息暂存在内存中。随后,当备库根据自身参数状态(如 wal_receiver_status_interval, checkpoint_timeout 等)判断需要执行一次刷盘操作时,才会启动创建 RESTARTPOINT 的任务。此时,备库会将内存中保存的最新的检查点信息,写入到 pg_control 文件中,从而完成一个“重启点”的标记。
问题根源分析
现在,让我们回到最初的问题:为何备库在正常关闭后启动,仍可能需要漫长等待?
关键在于,备库正常关闭时,会执行 RESTARTPOINT 任务来刷写脏页。但它推进的检查点(即重启时的重做点)完全依赖于其在WAL日志流中遇到的最后一个检查点。如果这个最后的检查点位置,与备库实际已经应用到的最大LSN位置之间间隔了很长的日志,那么备库在启动时,就必须从那个可能“落后”很多的检查点开始回放,直至追赶上关闭前的状态。这个过程就会导致启动时间变长。
因此,备库的启动延迟,实际上与主库的检查点频率紧密相关。假设主库承受着较高的写入压力,并且 max_wal_size 和 checkpoint_timeout 参数设置得较大,导致检查点间隔很长,那么备库就有较大概率遇到启动延迟巨大的问题。如果主备之间没有复制延迟,一个简单的缓解方法是:在主库上手动执行一次检查点,然后再关闭备库,这样备库内存中保存的检查点信息就是最新的,其 RESTARTPOINT 也会基于此最新点进行标记。
总结
理解 RESTARTPOINT 机制,有助于我们更深入地排查 PostgreSQL 备库的启动性能问题。它揭示了即使在正常关闭流程中,数据库的启动时间也可能受到上游主库行为的影响。在运维高可用架构时,合理配置检查点相关参数,对于保障服务的快速恢复至关重要。
希望这篇关于 RESTARTPOINT 的解析,能为你带来一些新的启发。欢迎在云栈社区与其他开发者交流更多数据库运维经验。 |  发表于 2026-1-6 00:53:57
|
查看: 164|
回复: 0
发表于 2026-1-6 00:53:57
|
查看: 164|
回复: 0
