
在Web开发与网络编程中,HTTP协议的GET和POST请求是最常用且易混淆的两个方法。本文将从协议规范出发,深入解析它们的核心区别、各自特点及适用场景,帮助开发者正确选择和使用。
HTTP请求报文结构
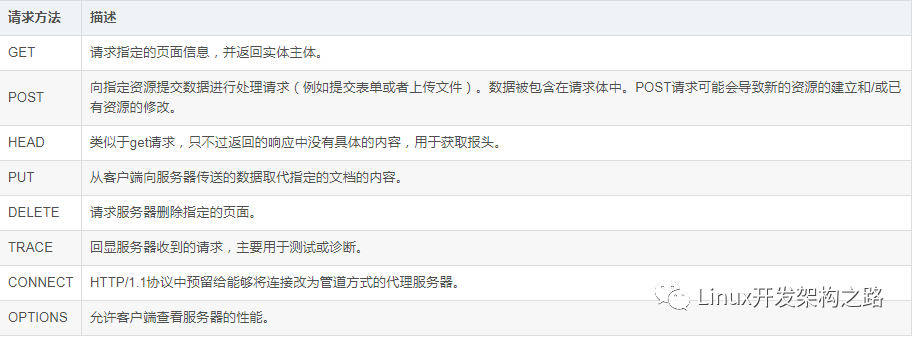
首先,我们需要明确GET和POST是什么?它们都是HTTP协议定义的请求方法。HTTP/1.1规范中共定义了8种请求方法,除了GET和POST,还包括HEAD、PUT、DELETE、TRACE、CONNECT和OPTIONS。
那么,这些请求方法在报文中如何体现呢?这需要了解HTTP请求报文的基本格式。一个完整的HTTP请求报文由三部分组成:请求行、请求头部和请求数据。

- 请求行:包含请求方法(Method)、请求URL和HTTP协议版本,各部分由空格分隔,以回车符和换行符结束。请求方法就定义在此处。
- 请求头部:位于请求行之后,由若干个“头部字段名: 值”对组成,每个对以回车换行结束,用于传递附加信息。
- 请求数据:可选部分,通常在POST请求中用于携带表单数据等负载。
为了更直观地理解,我们来看一个实际的GET请求示例。以下是通过抓包工具捕获的访问 https://api.github.com/search/users?q=JakeWharton 的请求报文:
GET /search/users?q=JakeWharton HTTP/1.1
Host: api.github.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _octo=GH1.1.1623908978.1549006668; _ga=GA1.2.548087391.1549006688; logged_in=yes; dotcom_user=GoMarck; _gid=GA1.2.17634150.1554639136; _gat=1
重点关注请求行:GET /search/users?q=JakeWharton HTTP/1.1。这表明使用了GET方法,请求URL包含查询参数q=JakeWharton,协议为HTTP/1.1。该示例没有请求数据部分。
相比之下,POST请求的报文结构有所不同。以下是一个典型的POST请求示例:
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
在这个例子中,请求行指定方法为POST。关键区别在于,其请求参数name=Professional%20Ajax&publisher=Wiley位于请求数据部分,并且请求头部与请求数据之间必须有一个空行。这正是HTTP协议规范所定义的格式差异。
GET方法的核心特点
GET请求在设计上有几个鲜明的特点,这些特点源于其“获取资源”的定位:
- 参数置于URL:GET请求的参数会以查询字符串(Query String)的形式附加在URL之后,格式为
?key1=value1&key2=value2。例如前面提到的/search/users?q=JakeWharton。
- 安全性与幂等性:根据HTTP规范,GET被设计为安全(Safe)和幂等(Idempotent)的方法。
- 安全:意味着操作不应产生副作用,仅用于获取信息,不应修改服务器上的数据,类似于数据库的查询操作。
- 幂等:指无论进行多少次相同的GET请求,结果都应该是一致的(当然,前提是资源本身未发生变化)。在实际应用中,如新闻列表更新,虽然内容变了,但每次请求都是获取当前状态,仍被视为幂等。
- 浏览器缓存:GET请求容易被浏览器主动缓存。如果后续请求的URL完全相同,浏览器可能会直接返回缓存的响应,以提升页面加载速度。
- 长度限制:HTTP协议本身并未规定GET URL的长度上限,但实际限制来自浏览器和Web服务器的实现。不同浏览器(如Chrome、Firefox)对URL长度有各自的规定,过长的URL可能导致请求被截断或拒绝。
- TCP数据包:GET请求在发送时,通常会将请求头和请求数据(即URL中的参数)一并放入一个TCP数据包发送出去,服务器响应200 OK并返回数据。
POST方法的核心特点
POST请求则用于向指定资源提交数据,通常会导致服务器状态的变化:
- 修改服务器资源:POST的设计初衷是“可能修改服务器上的资源”。例如,在社交媒体上点赞、提交表单、上传文件等操作,都会改变服务器端的数据,因此常用POST方法实现。
- 非安全与非幂等:由于可能修改资源,POST不符合安全性和幂等性的定义。重复提交同一个POST请求(如多次点击“提交订单”),可能会产生多个副作用的操作(如创建多个订单)。
- 参数置于请求体:POST请求的参数通常放在请求数据(即请求体)中发送,而不是URL里。这避免了参数暴露在地址栏,但请注意,这并不等同于“更安全”,因为通过抓包工具依然可以清晰看到明文数据。
- 无长度限制:因为数据放在请求体中,理论上POST提交的数据量没有限制,实际限制取决于服务器的配置和处理能力。
- TCP数据包:部分浏览器在发送POST请求时,会先发送请求头,服务器返回
100 Continue状态码后,再发送请求体数据。这相当于使用了两个TCP数据包。但在网络良好的情况下,这种差异对用户体验的影响微乎其微。
GET与POST的本质区别与联系
看到这里,你可能会觉得GET和POST在外在表现上差异显著。然而,从网络底层来看,它们的本质都是基于TCP/IP的连接,并无根本不同。
为什么这么说?HTTP是应用层协议,建立在传输层TCP之上。无论是GET还是POST,最终都是通过TCP链接来传输数据。理论上,你完全可以把GET的参数放到请求体里,或者把POST的参数拼接到URL上——技术上可行,但违背了HTTP协议的设计规范和业界约定。
那么,HTTP为何要严格区分二者?答案是为了语义清晰和易于管理。将“只读”操作和“写入”操作从协议层面区分开,使得浏览器、服务器、中间代理(如缓存服务器)能够根据方法类型做出正确的处理。例如,缓存服务器通常只缓存GET请求的响应。
这种规范也带来了实际开发中的约束:
- 服务器行为依赖:如果你不按规范使用(例如用GET携带请求体),虽然请求能发出,但服务器端可能无法正确解析。有些Web框架或服务器会忽略GET的请求体,而有些则会读取。结果不可预测,因此强烈建议遵循规范。
- 浏览器与服务器限制:正是由于浏览器和服务器对HTTP协议的实现遵循了这些规范,才导致了我们在应用层面看到的各种“区别”。
所以,关于GET和POST最准确的总结是:它们本质都是TCP连接,但由于HTTP协议的规定以及浏览器/服务器的共同约定,在应用行为上表现出不同。 开发者应该根据操作语义(获取资源用GET,提交数据用POST)而非表面的“安全性”或“长度”来选择方法。

理解TCP/IP底层原理与HTTP上层协议的协作,是掌握网络编程的关键。希望本文能帮助你清晰区分GET与POST。想了解更多网络协议、Web开发等深度技术内容,欢迎访问云栈社区,与广大开发者一起交流学习。
 发表于 2026-1-6 05:51:30
|
查看: 236|
回复: 0
发表于 2026-1-6 05:51:30
|
查看: 236|
回复: 0
