在现代Java开发中,处理HTML数据是一项常见需求,无论是抓取网页数据、解析HTML文档,还是操作DOM树,Jsoup 都是一个强大的工具。它是一个基于Java的HTML解析库,支持从URL、文件或字符串中解析HTML,提供类似于jQuery的API,便于选择和操作DOM元素。
本文将介绍Jsoup的基本功能,并通过一个爬取特定编程学习网站资源页面的代码示例,来展示如何使用它解析和操作HTML。
一、为什么选 Spring Boot + Jsoup?
(一)技术组合优势
- Spring Boot:简化Java项目配置,快速搭建工程,无需复杂XML配置,让开发者能够专注于爬虫逻辑的开发。
- Jsoup:Java界的HTML解析利器,不仅能轻松爬取网页内容,还支持DOM查询和CSS选择器,如同使用jQuery操作网页一般简便,处理HTML比正则表达式高效得多。
(二)爬取目标
选择资源分类清晰、HTML结构规整的网站作为爬虫入门实战案例,有助于快速掌握核心解析技巧。
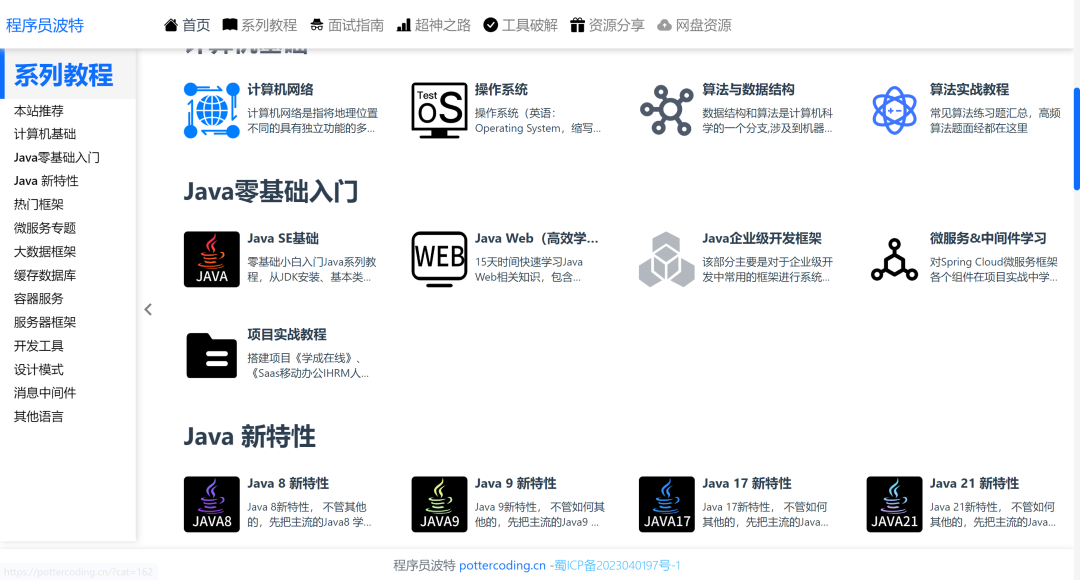
二、环境搭建:3步搞定集成
(一)前置准备
- JDK 1.8+(若使用Spring Boot 3.x则需JDK 17+)
- Maven 3.6+
- 开发工具:IDEA(推荐)
(二)创建Spring Boot项目
使用Spring Initializr创建新项目,选择「Spring Web」依赖即可(仅需基础web支持)。
(三)引入Jsoup依赖
在 pom.xml 中添加Jsoup依赖,轻量高效:
<!-- Jsoup HTML解析器 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.17.2</version><!-- 最新稳定版 -->
</dependency>
三、核心代码实战:爬取宝藏资源
(一)爬虫核心逻辑
- 使用Jsoup连接目标网站,获取HTML文档对象。
- 分析网页DOM结构,利用CSS选择器精准提取资源分类、名称及链接。
- 格式化输出爬取结果,亦可存入数据库(本文简化为控制台输出)。
(二)完整代码实现
创建 ResourceCrawler 类,根据目标网站的DOM结构进行解析:
package cn.pottercoding.utils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class ResourceCrawler {
// 目标网站地址
private static final String TARGET_URL = "https://pottercoding.cn/";
/**
* 爬取程序员波特网站的所有教程资源
*/
public void crawlLearningResources() {
try {
// 1. 模拟浏览器请求,避免被拦截
Document document = Jsoup.connect(TARGET_URL)
.timeout(15000) // 超时时间15秒
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.header("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8")
.get();
System.out.println("===== 程序员波特网站 - 全量教程资源爬取结果 =====");
System.out.println("爬取时间:" + new java.util.Date());
System.out.println("=============================================\n");
// 2. 先爬取顶部核心导航(系列教程/面试指南等)
crawlTopNavigation(document);
// 3. 爬取所有分类教程(核心部分)
crawlCategoryResources(document);
} catch (IOException e) {
System.err.println("爬取失败!原因:" + e.getMessage());
}
}
/**
* 爬取顶部导航栏的核心入口(系列教程、面试指南等)
*/
private void crawlTopNavigation(Document document) {
System.out.println("【核心导航入口】");
System.out.println("----------------");
// 定位顶部导航按钮区域
Elements topActions = document.select("div.ddkk-info .actions a.action-button");
for (Element action : topActions) {
String name = action.text().trim(); // 按钮名称
String url = action.attr("href"); // 链接
System.out.println("名称:" + name + " | 链接:" + url);
}
System.out.println(); // 空行分隔
}
/**
* 爬取所有分类的教程资源(本站推荐、计算机基础、Java零基础等)
*/
private void crawlCategoryResources(Document document) {
// 定位所有教程分类区块(features-zhuanlan)
Elements categoryBlocks = document.select("main.main-content div.features-zhuanlan");
if (categoryBlocks.isEmpty()) {
System.out.println("未找到任何教程分类区块!");
return;
}
// 遍历每个分类区块
for (Element block : categoryBlocks) {
// 提取分类标题(h2标签)
Element titleElement = block.selectFirst("h2");
if (titleElement == null) {
continue; // 无标题的区块跳过
}
String categoryName = titleElement.text().trim();
System.out.println("【" + categoryName + "】");
System.out.println("----------------");
// 提取该分类下的所有教程链接
Elements tutorialLinks = block.select("div.features a.link");
if (tutorialLinks.isEmpty()) {
System.out.println("该分类暂无教程资源");
System.out.println();
continue;
}
// 遍历每个教程项
for (Element link : tutorialLinks) {
// 教程名称
String tutorialName = link.selectFirst("div.pro-item-desc > div").text().trim();
// 教程链接(拼接完整URL)
String tutorialUrl = link.attr("href");
if (!tutorialUrl.startsWith("http")) {
tutorialUrl = TARGET_URL + tutorialUrl.replaceFirst("^//", "");
}
// 教程简介(可选)
String tutorialDesc = link.selectFirst("div.pro-item-desc p").text().trim();
// 输出结果(格式规整)
System.out.println("📌 教程名称:" + tutorialName);
System.out.println("🔗 访问链接:" + tutorialUrl);
System.out.println("💡 教程简介:" + tutorialDesc);
System.out.println(); // 空行分隔
}
System.out.println("=============================================\n");
}
}
}
(三)测试爬取结果
创建测试类或在Controller中调用:
package cn.pottercoding.config;
import cn.pottercoding.utils.ResourceCrawler;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class CrawlerTest implements CommandLineRunner {
private final ResourceCrawler resourceCrawler;
// 构造注入爬虫实例
public CrawlerTest(ResourceCrawler resourceCrawler) {
this.resourceCrawler = resourceCrawler;
}
@Override
public void run(String... args) throws Exception {
// 启动爬虫
resourceCrawler.crawlLearningResources();
}
}
启动Spring Boot项目,控制台会输出结构化的爬取结果:
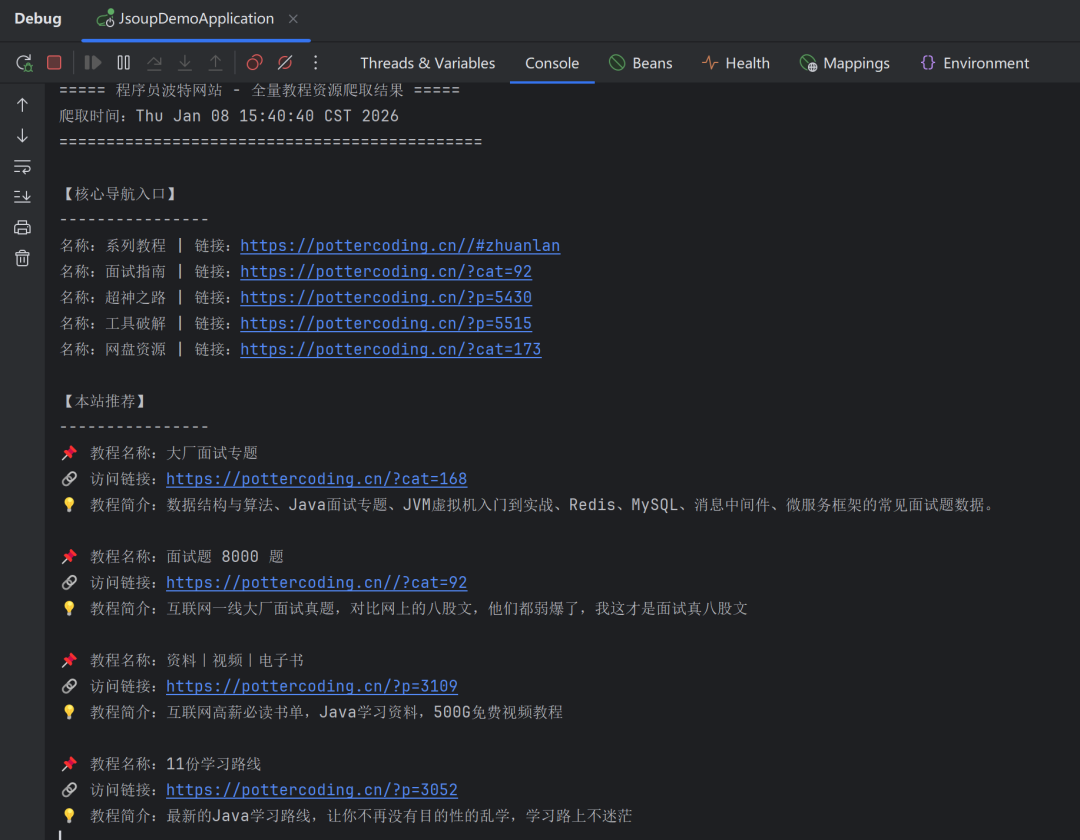
四、进阶玩法:让爬虫更实用
(一)保存爬取结果
- 存入数据库:创建Resource实体类,利用JPA或MyBatis-Plus将资源分类、名称、链接持久化到MySQL等数据库中。
- 导出Excel:集成EasyExcel等库,将爬取结果导出为Excel文件,方便离线查看与分享。
- 写入本地文件:使用Java IO或NIO将结果写入txt或JSON文件,示例代码如下:
// 追加到本地文件
try (FileWriter writer = new FileWriter("学习资源.txt", true)) {
writer.write("【" + category + "】\n");
writer.write("名称:" + resourceName + " | 链接:" + resourceUrl + "\n");
} catch (IOException e) {
e.printStackTrace();
}
(二)优化爬虫性能与健壮性
- 设置合理超时:根据目标网站响应速度和网络状况调整
timeout 参数。
- 添加重试机制:使用Guava Retryer或编写自定义重试逻辑,以应对临时性的网络波动或服务器不稳定。一个简单的实现示例如下:
// 简单重试逻辑
int maxRetry = 3;
int retryCount = 0;
while (retryCount < maxRetry) {
try {
// 执行爬取逻辑
break;
} catch (Exception e) {
retryCount++;
System.out.println("第" + retryCount + "次重试...");
Thread.sleep(1000); // 重试间隔1秒
}
}
五、注意事项:合法爬虫的底线
- 遵守robots.txt协议:在爬取前,务必查看目标网站的
robots.txt 文件(例如 https://target-site.com/robots.txt ),确认其允许爬虫访问的路径和频率限制。
- 控制爬取频率:避免高频请求,可在请求间添加适当的休眠(如
Thread.sleep(500) ),以减轻目标服务器的负载,体现技术善意。
- 明确用途限制:确保爬取行为仅限于个人学习、研究或获取公开信息,严禁用于商业盈利或任何非法用途。
- 识别并尊重反爬机制:若目标网站设有登录验证、验证码等反爬措施,需在法律允许和技术伦理范围内寻找解决方案,或考虑放弃爬取。
六、总结
Spring Boot与Jsoup的结合,为Java开发者提供了一套高效、便捷的网页数据抓取与解析方案。通过本文的实战教程,你可以快速掌握从环境搭建、目标分析到代码实现的全流程。
实际上,Jsoup的功能远不止于简单的爬取。它还能用于修改HTML元素、处理本地HTML文件以及数据清洗等场景。无论是构建数据采集系统、进行竞品分析,还是处理历史HTML数据存档,这个技术组合都能显著提升开发效率。
动手实践是掌握技术的关键。如果在实现过程中遇到问题,或想了解如何将数据导出至Excel、存入数据库等进阶功能,欢迎在技术社区进行交流与探讨。期待你利用这项技术,高效地获取并管理所需的学习资源。
 发表于 2026-1-10 04:19:40
|
查看: 220|
回复: 0
发表于 2026-1-10 04:19:40
|
查看: 220|
回复: 0
