在系统设计与面试准备中,缓存模式几乎是后端工程师和架构师的必考题。然而,多数候选人在面对“如何解决数据一致性问题”这一追问时,常因知识面不全或理解不深而陷入困境。事实上,许多缓存模式本身就可能是一致性问题的制造者。
本文将系统性地拆解 Cache Aside、Read Through、Write Through、Write Back、Refresh Ahead、Singleflight 等主流缓存模式,剖析其核心逻辑、潜在的一致性风险及优化方案,帮助你在技术面试与项目实践中构建清晰、深刻的认知体系。
1. 面试准备策略
准备缓存相关的面试,不能止步于死记硬背。作为资深开发者或架构师,你需要:
- 能够绘制每种模式的时序图,理解其数据流转。
- 反思所在项目的实际应用:采用了哪些模式?是否因此引发过生产事故?如何解决?
- 思考缓存更新与数据库更新的编排顺序是否存在一致性隐患。
透彻理解缓存模式,不仅是应对数据一致性难题的关键,更是后续解决缓存穿透、击穿与雪崩等技术挑战的基石。为便于理解,我们建立一个简化的模型:应用服务同时操作缓存(Cache)和数据库(DB)。
2. Cache Aside(旁路缓存)
这是业界应用最广泛的模式。其核心思想是:缓存仅作为辅助存储,应用程序作为“总指挥”,直接与数据库交互,并全权负责维护缓存状态。
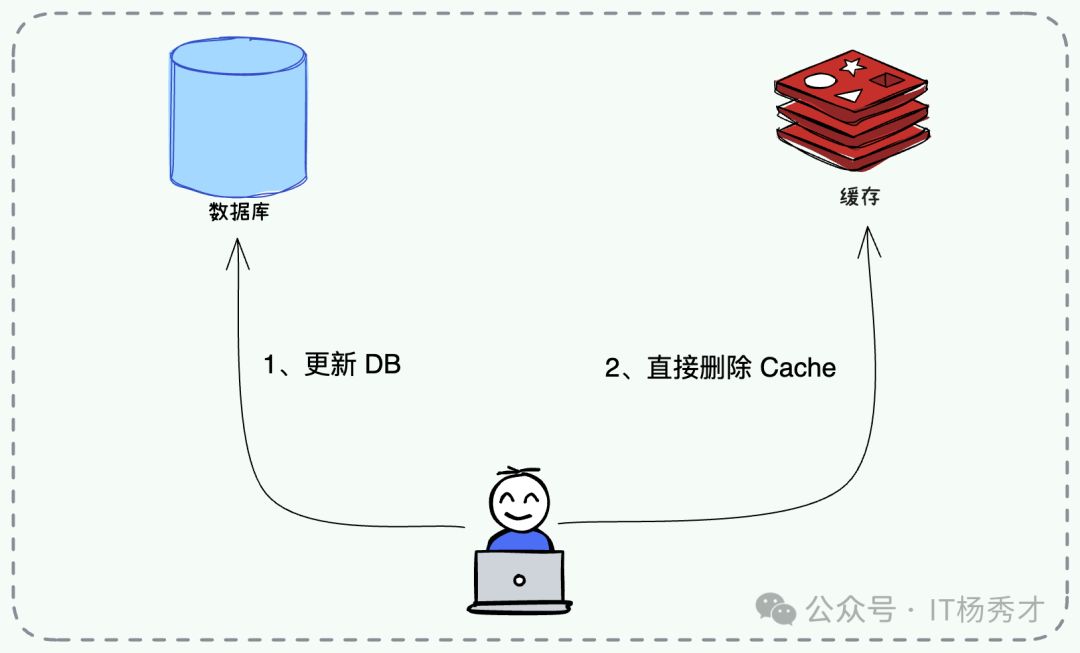
写操作流程
- 更新数据库:先将数据变更持久化到数据库。
- 删除缓存:随后直接删除对应的缓存 Key,而非更新。
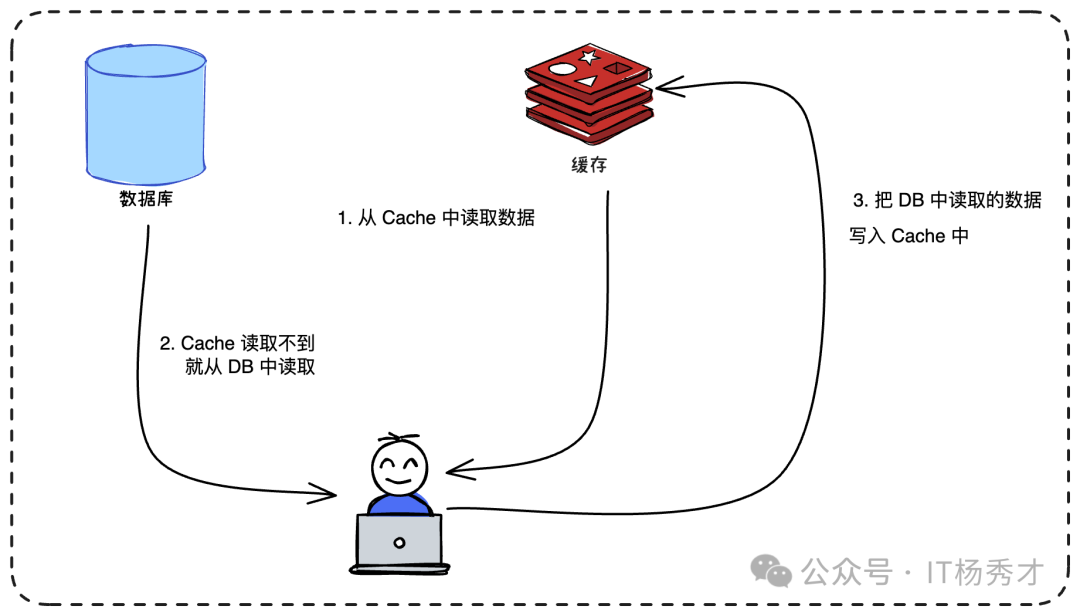
读操作流程
- 查询缓存:首先尝试从缓存获取数据。
- 缓存命中:命中则直接返回。
- 缓存回填:若未命中,则查询数据库,由应用程序显式地将数据写入缓存,再返回结果。
亮点与深度追问
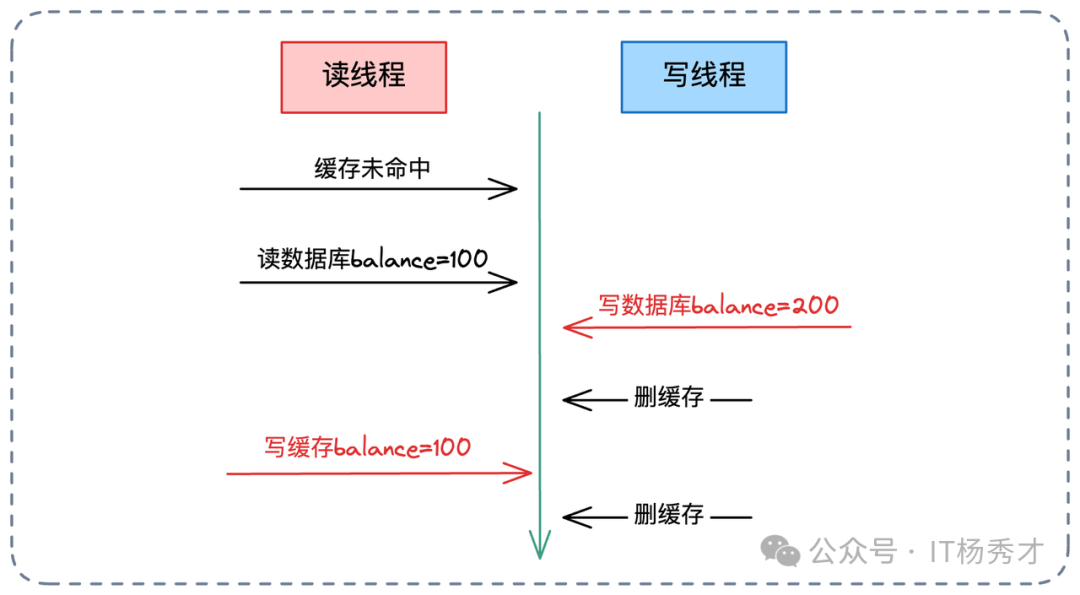
问题一:写操作为何必须“先更新DB,后删除Cache”?顺序能否颠倒?
绝对不能颠倒。采用“先删缓存,后更新DB”在高并发下极易导致脏数据难以自动恢复。
假设库存为100,线程A(写)欲改为99,线程B(读)并发查询:
- 线程A删除缓存。
- 线程B缓存未命中,查询DB(此时A尚未更新DB),读到旧值100。
- 线程B将旧值100回填缓存。
- 线程A更新DB为99。
结果:DB=99,Cache=100,缓存脏数据直至过期。
问题二:“先更新DB,后删除Cache”就能保证强一致吗?
理论上仍存在极低概率的不一致,但工程上可忽略。这发生在缓存刚好失效且并发读写的极端时序下:
- 线程A(读)缓存未命中,读DB得旧值100。
- 线程B(写)在A读库后、回填前介入,完成DB更新(改为99)并删除缓存。
- 线程A将旧值100回填缓存。
结果:DB=99,Cache=100。由于数据库写操作(涉及I/O、锁)通常远慢于内存操作,这种时序发生的概率极低。
3. 同步更新模式
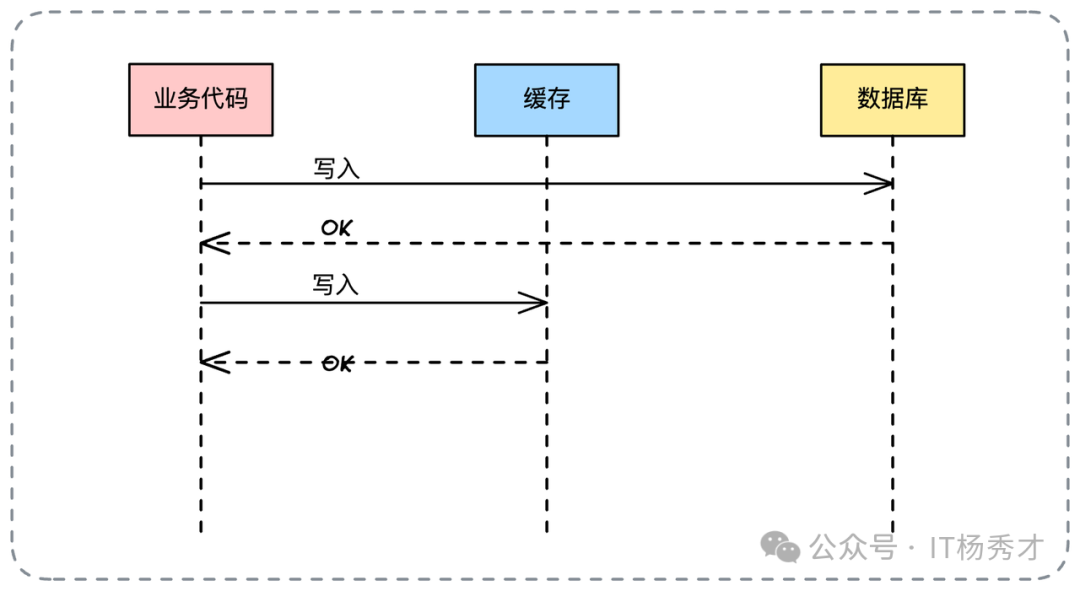
此模式并非标准设计模式,而是业务代码直接操作缓存与数据库的“自然写法”。业务代码将缓存视为独立数据源。
写操作:业务代码控制写入顺序,通常优先写数据库。
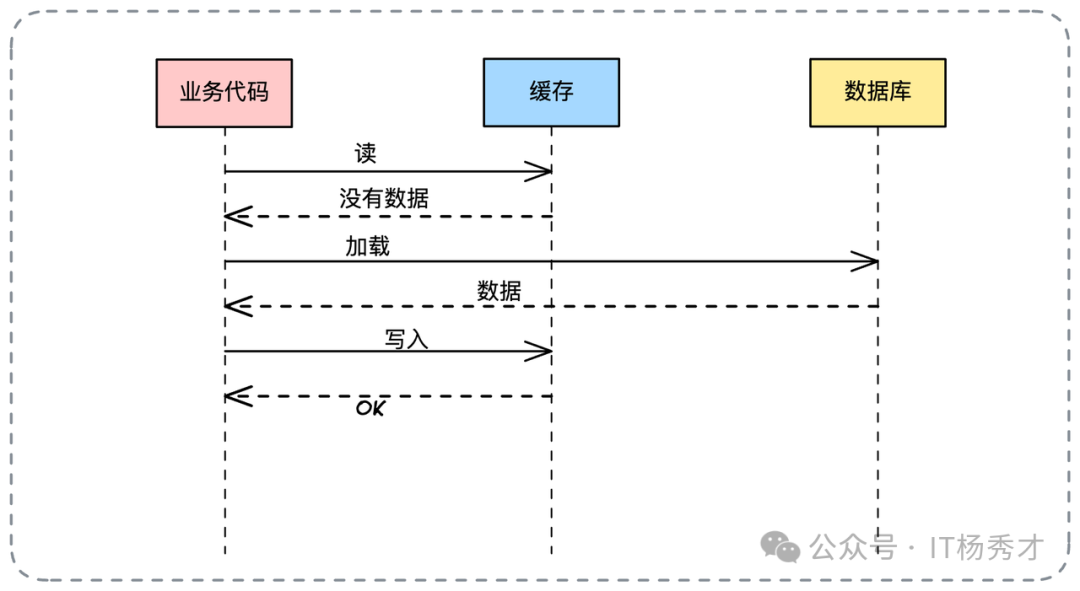
读操作:同样由业务代码处理缓存命中与回填逻辑。
为何优先写库? 因为数据库是数据的“最终真理源”。只要DB写入成功,业务即告成功。缓存写入失败可通过过期或下次读取恢复,这体现了最终一致性思想。
然而,同步更新无法解决并发写导致的一致性问题。看以下场景:
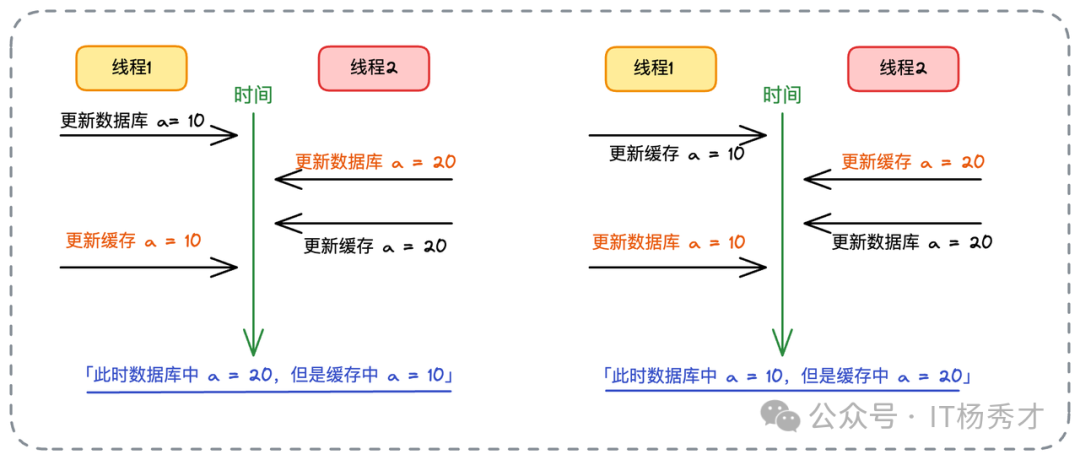
假设库存初始为100:
- 线程1更新DB为10。
- 线程2快速更新DB为20并更新缓存为20。
- 线程1更新缓存为10。
结果:DB=20,Cache=10,数据不一致。
4. Read Through(读穿透)
为减轻业务代码负担,Read Through 模式诞生。业务方只向缓存要数据,若缓存未命中,则由缓存组件自身负责从数据库加载并更新自己。
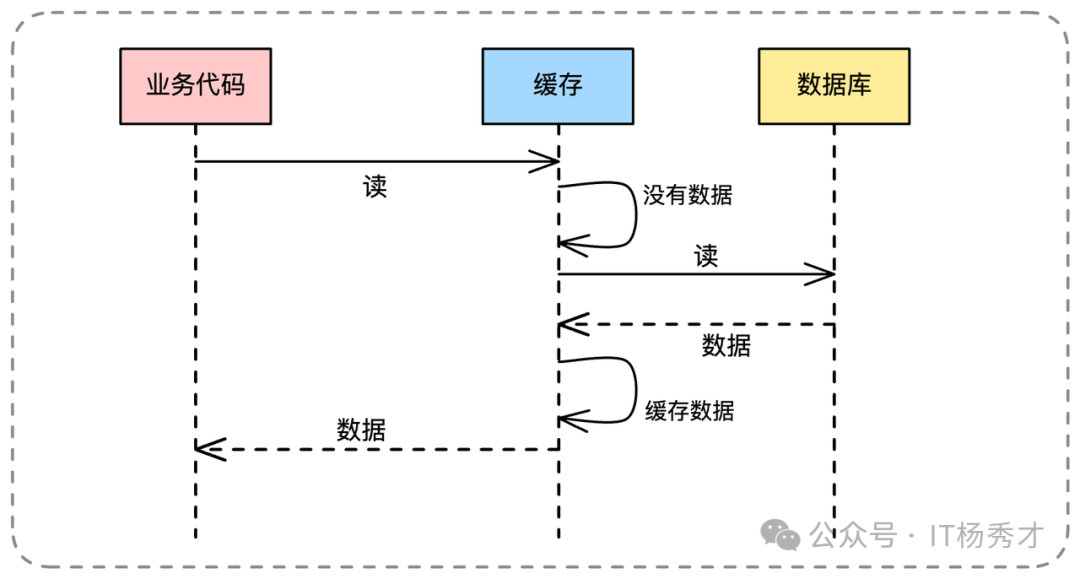
其写操作通常与“同步更新”保持一致,因此在数据一致性方面面临相同挑战。但其高光点在于异步化改造。
异步加载方案
变种一:异步回写
从数据库查询到数据后,立刻返回给业务,然后异步将数据写入缓存。
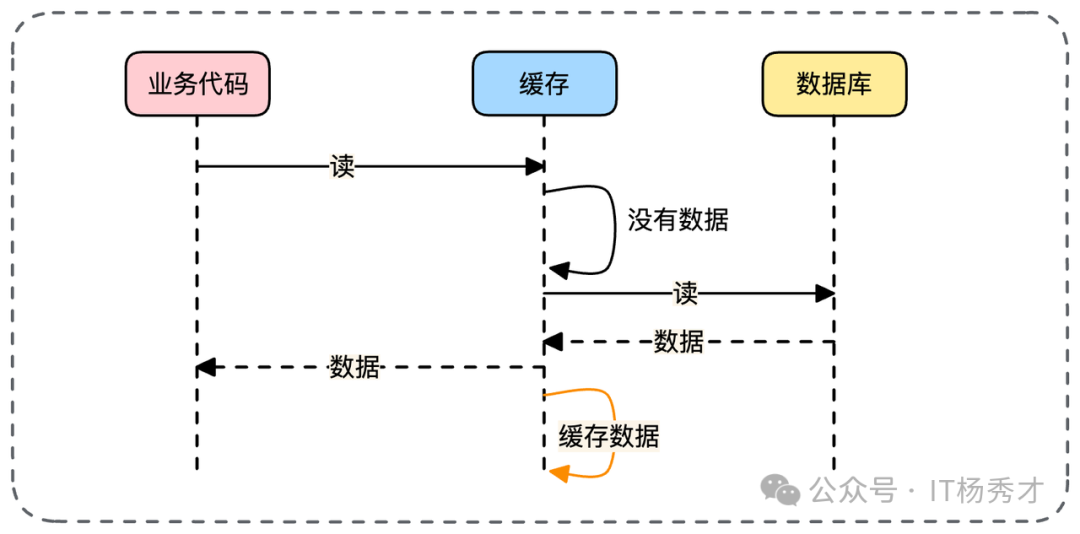
变种二:全异步加载
缓存未命中时,直接返回默认值或错误码,由缓存组件在后台异步完成数据加载与缓存更新。
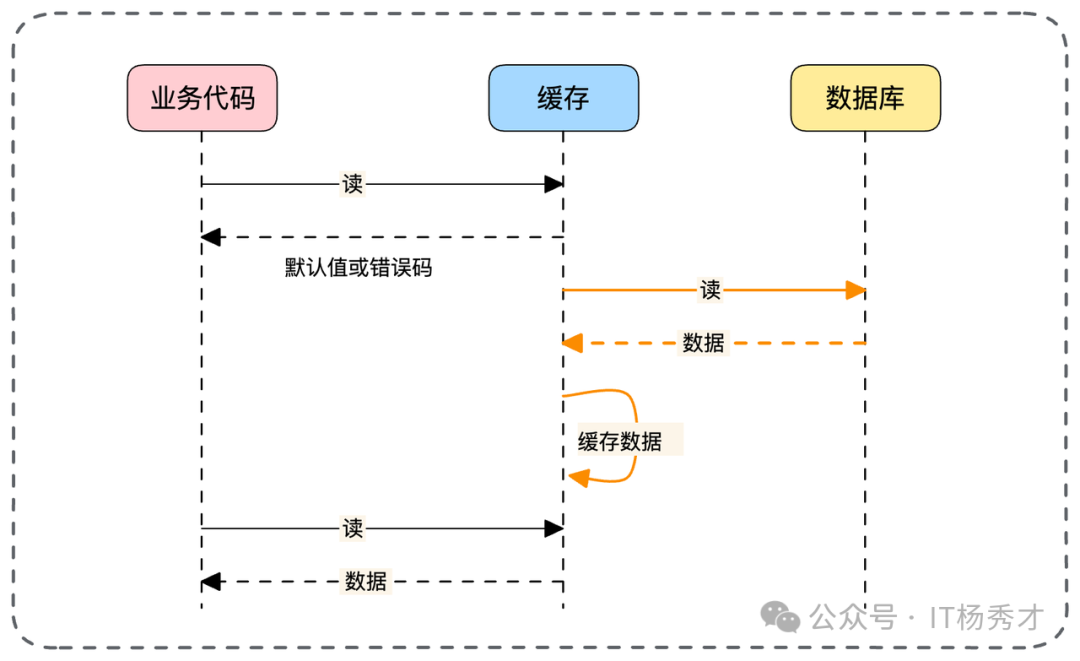
场景选择:变种二对响应时间极致优化,但业务需容忍短暂数据降级。变种一适用于缓存写入操作本身很耗时的场景。
5. Write Through(写穿透)
与读穿透对应,Write Through 模式下,业务方只写入缓存,然后由缓存组件代理完成数据库的更新。
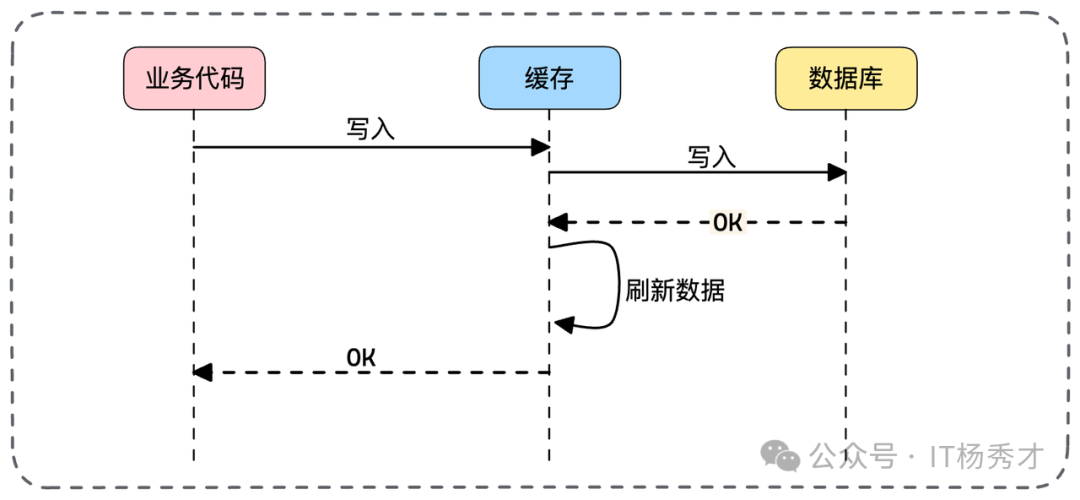
其读操作与 Cache Aside 一致。该模式同样面临并发写的一致性问题,且同样可引入异步机制。
异步写的权衡
异步写库:写入缓存后立刻返回成功,后台异步写库。风险是若缓存组件宕机,数据会永久丢失。
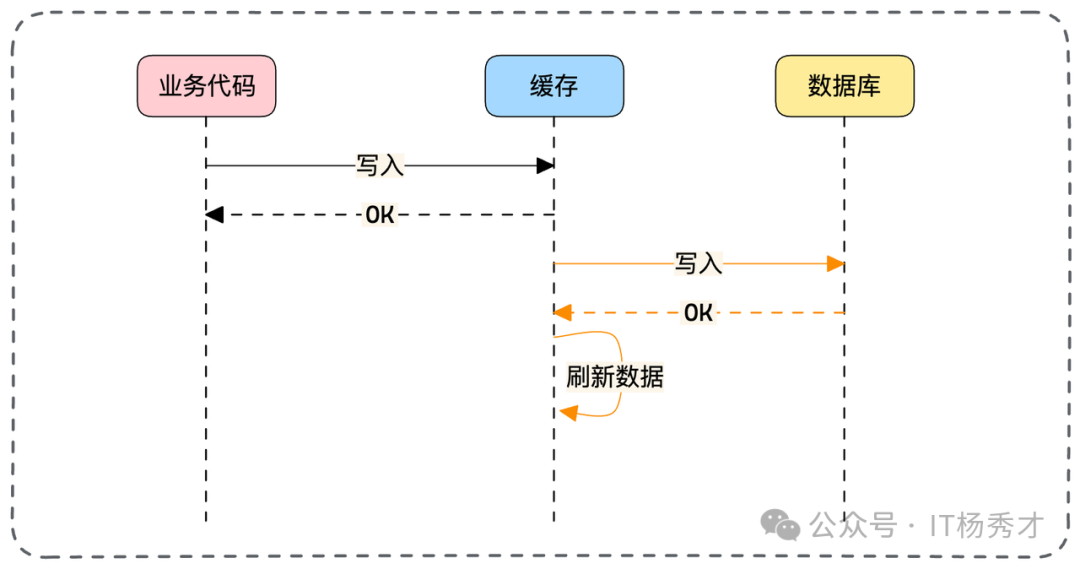
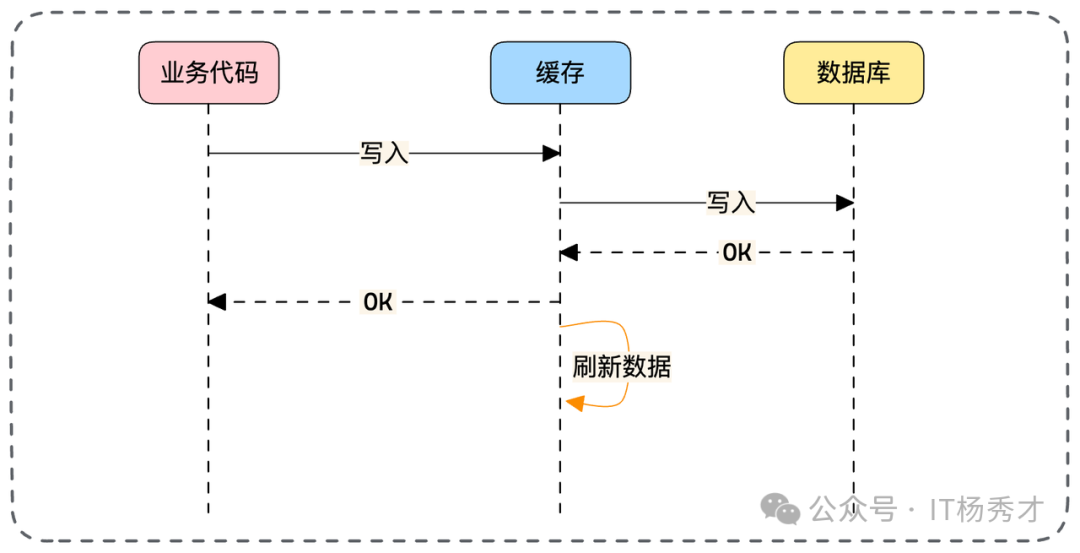
异步刷缓存:同步写库保证安全,但异步刷新缓存。适用于“写库快,刷缓存慢”的特殊场景。
6. Write Back(回写)
为追求极致写性能,Write Back 模式诞生:写操作只更新缓存并立即返回,数据库的更新被推迟到缓存数据过期或被逐出时,由后台守护组件触发。
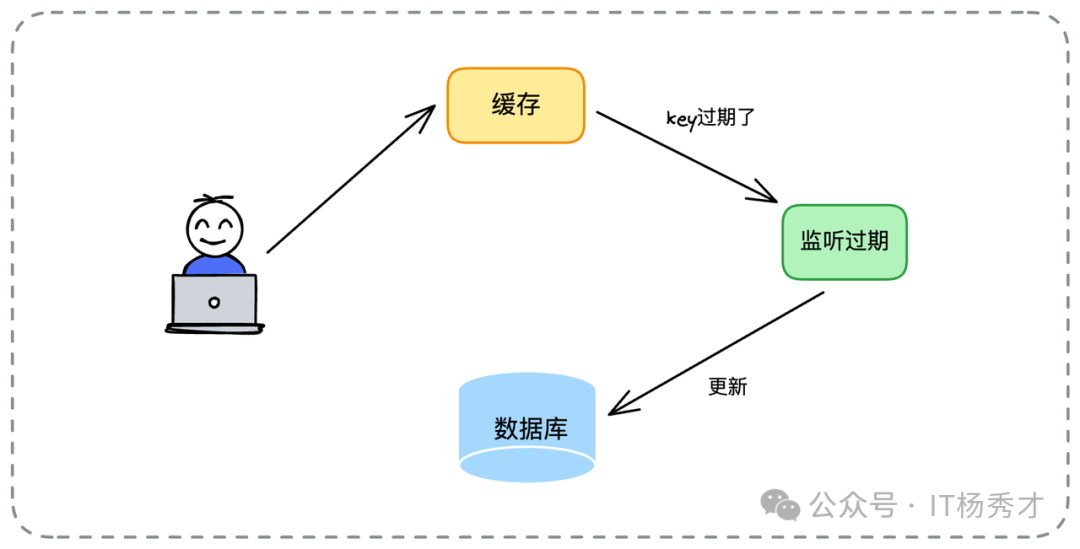
其最大风险是缓存宕机会导致未刷盘的脏数据丢失,故适用于对数据丢失有一定容忍度的场景。
但一个反直觉的亮点是:在集中式缓存(如Redis)下,Write Back 在一致性表现上可能优于其他模式。
逻辑分析:
- 写一致性:所有读写都在缓存闭环内完成,业务方读写自洽。数据库虽滞后,但对业务无感。
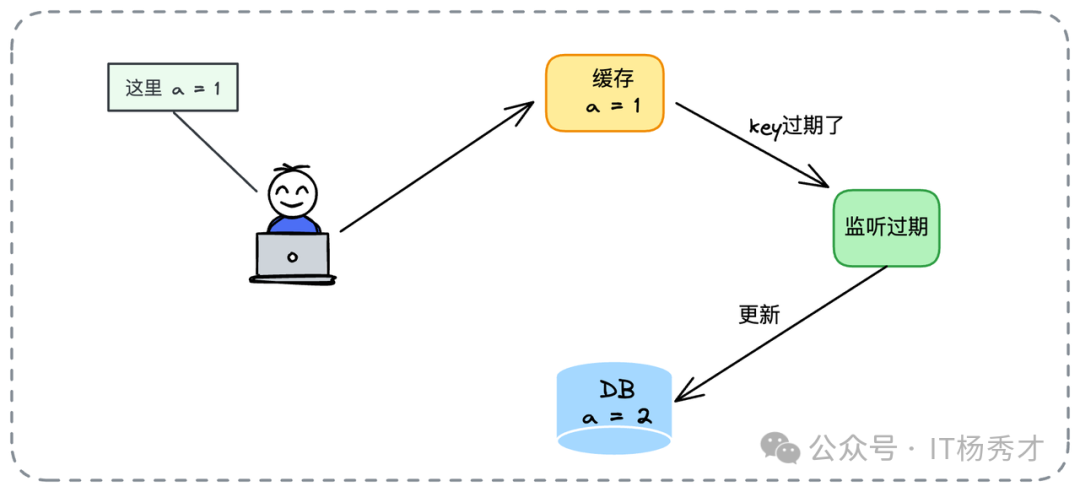
- 读一致性隐患:当缓存失效,读请求需回源数据库时,可能发生经典读写并发冲突。
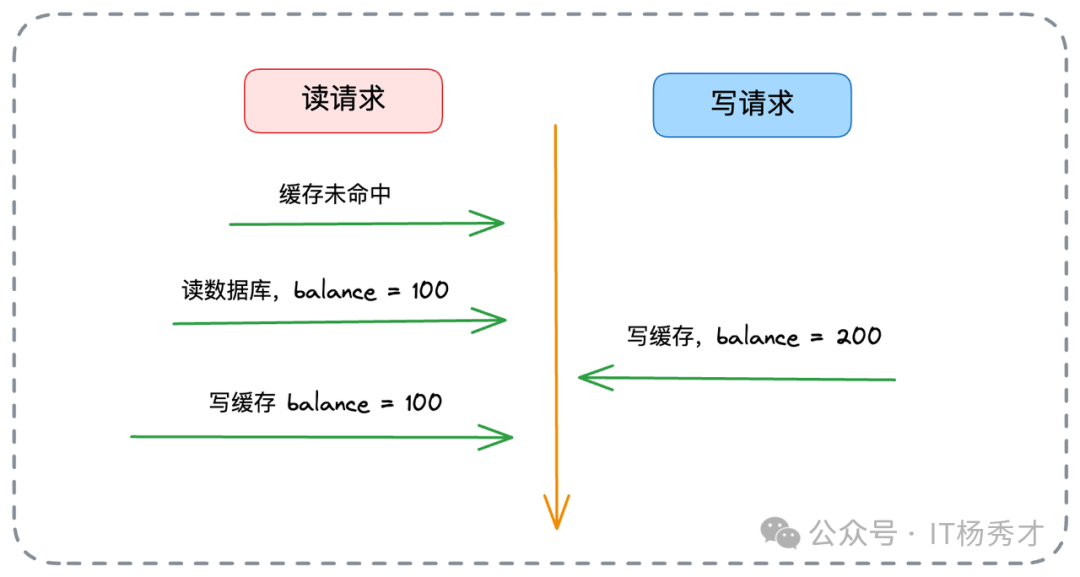
- 解决方案:使用 Redis 的
SETNX 指令。读请求回填缓存时,仅当 Key 不存在才执行写入,避免覆盖写请求已更新的新值。
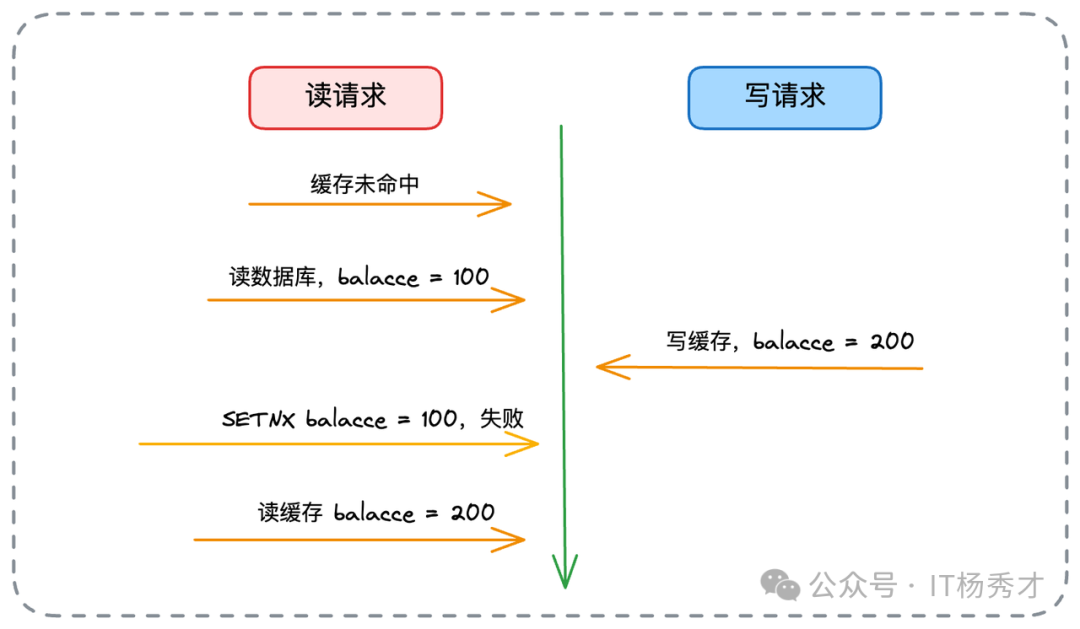
因此,除了数据丢失风险,Write Back 能较好地缓解数据不一致问题。
7. Refresh Ahead(预刷新/CDC)
随着 CDC 技术普及,此模式流行起来。业务方只写数据库,通过监听数据库 Binlog(如使用 Canal)来异步刷新缓存。
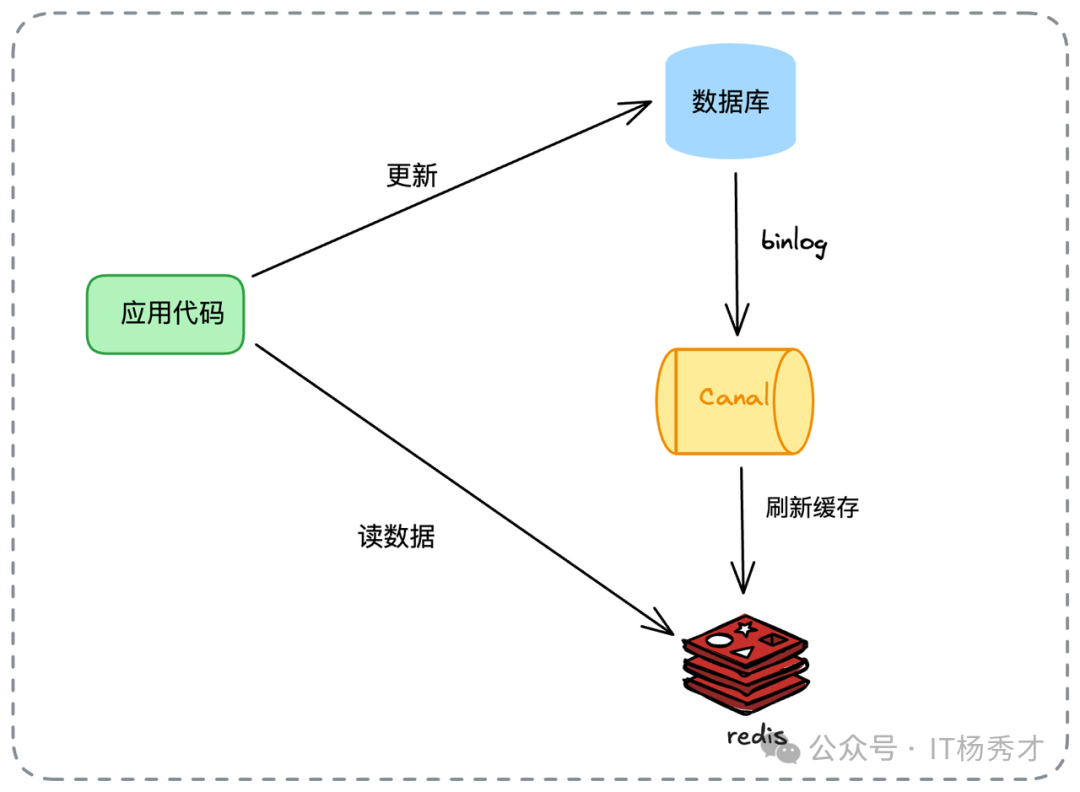
它将缓存更新逻辑从业务代码解耦,但仍存在“写库后到缓存刷新前”的时间窗口不一致。同样面临读写并发问题:
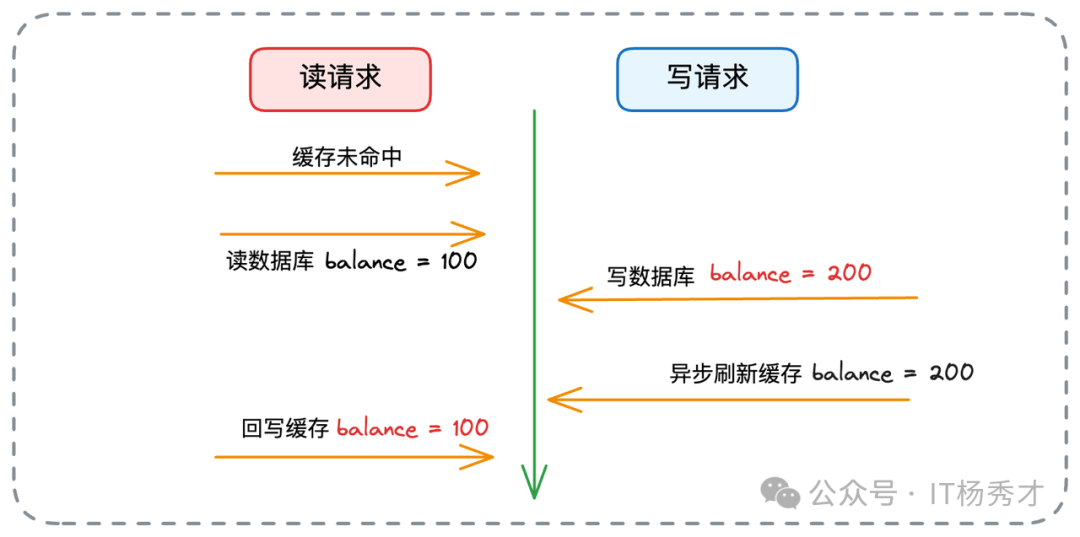
解决方案同 Write Back:读请求回填缓存时使用 SETNX。
8. Singleflight
这并非读写模式,而是一种流量控制模式。其核心是:当缓存未命中时,针对同一 Key 的大量并发查询,只允许一个请求去数据库加载数据,其余请求阻塞等待该结果。
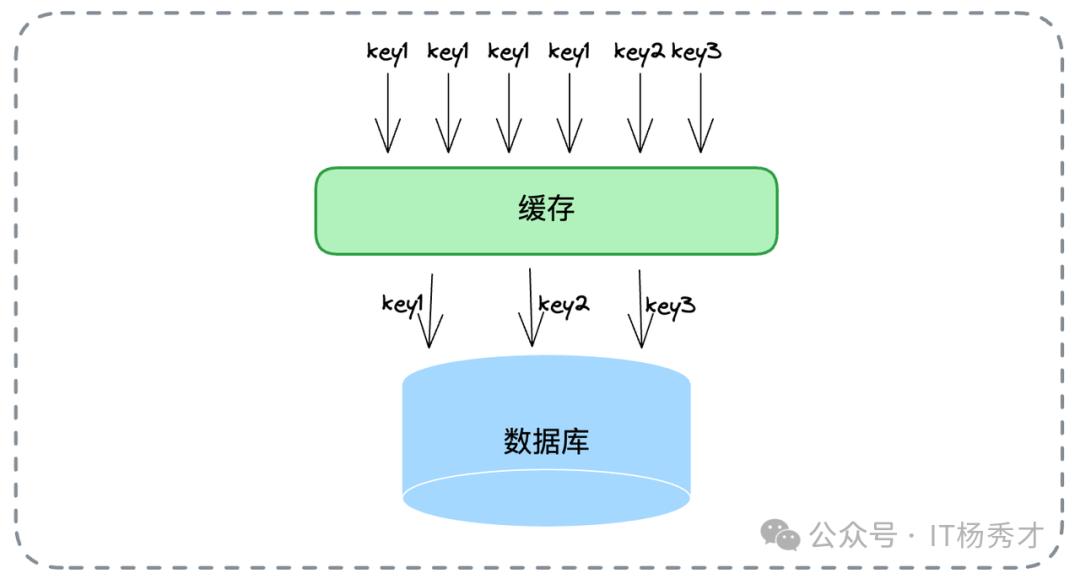
其核心价值在于保护数据库,防止缓存击穿导致雪崩,特别适用于热点数据(Hot Key)场景。
9. 删除缓存与延迟双删
这是业务中最常见的策略之一:更新数据时,先更新数据库,然后直接删除缓存。也可结合 Write Through,让缓存组件更新完DB后自删。
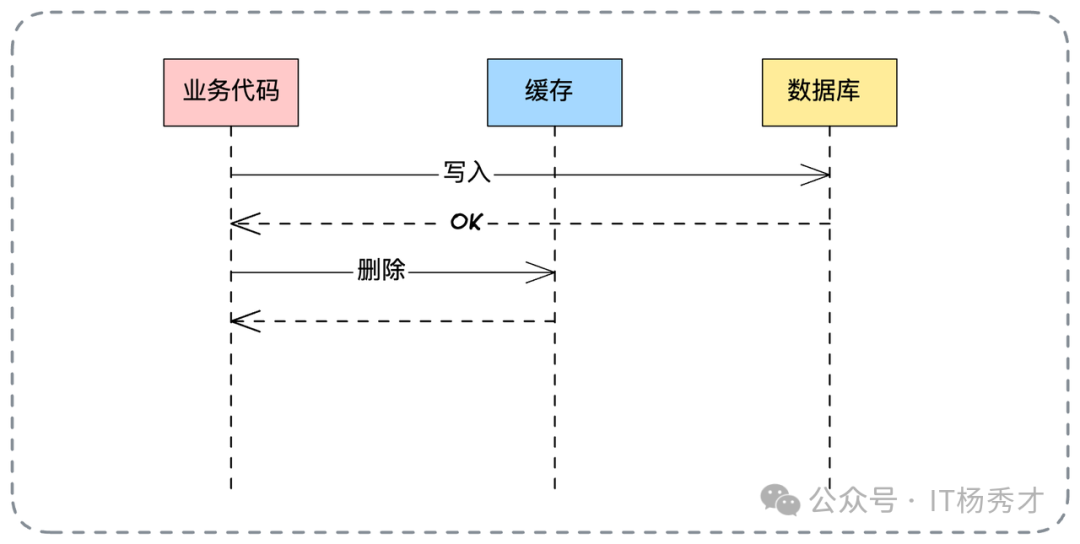
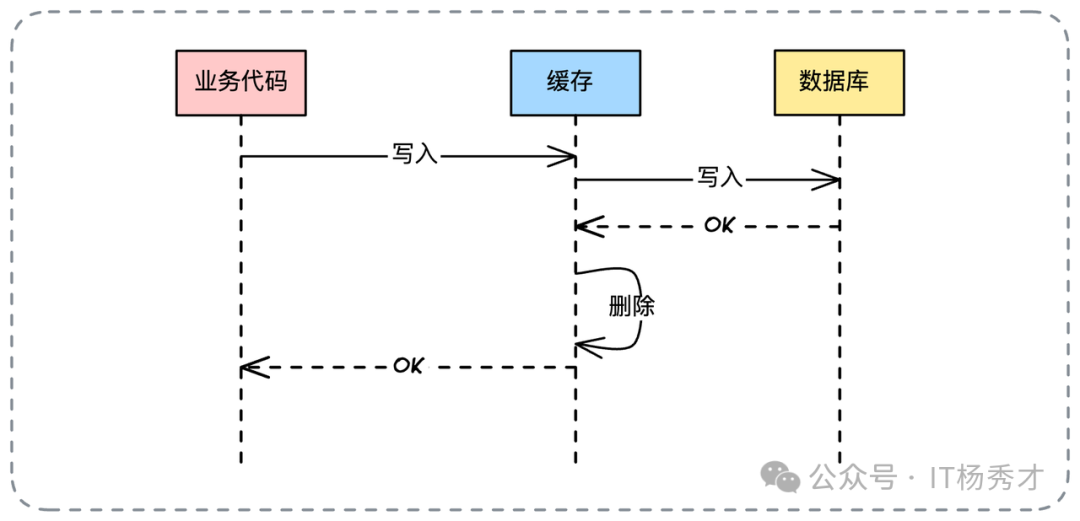
为何是“删”而非“更新”?这体现了懒加载思想,避免无效的缓存计算与更新。
但“先改库后删缓存”仍有理论上的不一致风险,即“读线程缓存未命中”与“写线程”并发:
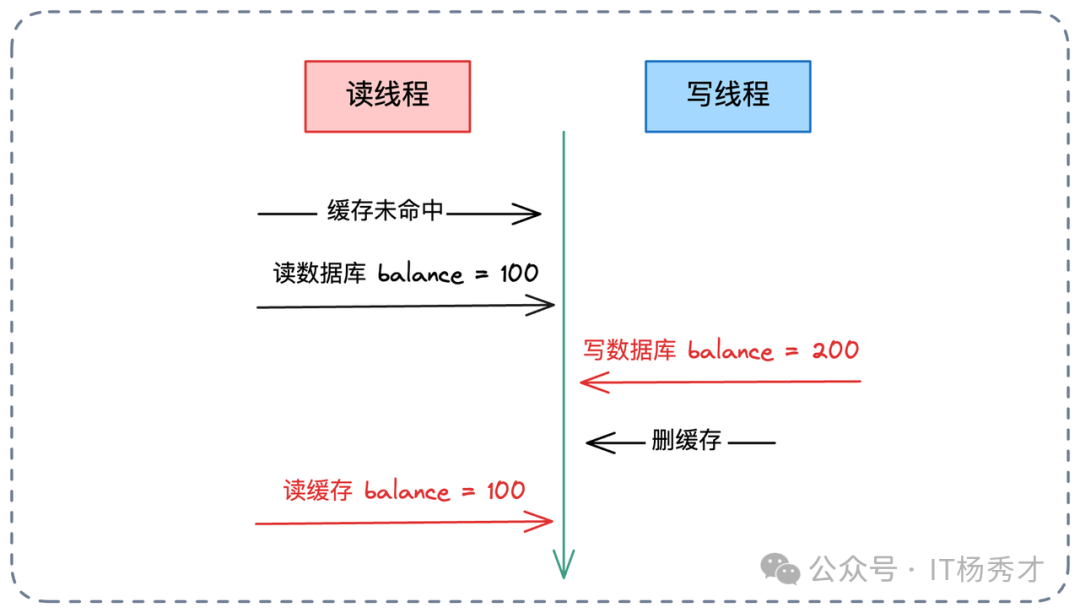
为解决此极低概率问题,引入了延迟双删策略。
延迟双删(Delayed Double Delete)
基本流程:写数据库 -> 删缓存 -> 延迟N毫秒 -> 再次删缓存。首次删除可选。
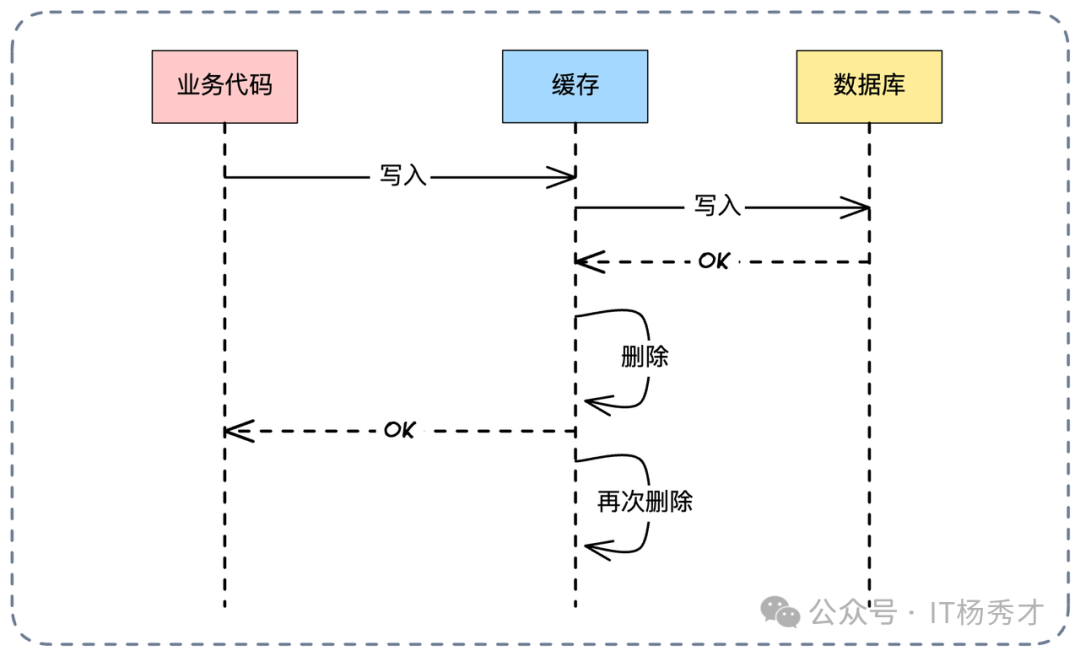
第二次删除的目的,是清除可能在第一次删除后、延迟期间被读请求回填的脏数据。
理论上,若读请求在第二次删除后才回填,仍会不一致,但概率极低。其代价是降低了缓存命中率并增加了系统复杂度。延迟时间需覆盖主从同步延迟及业务处理耗时。
10. 模式选择与工程实践
面试官常问:“项目中该选哪种?” 答案是:没有银弹,需根据业务权衡。
- 强一致性场景(如金额):可能直接绕过缓存,或使用分布式锁,牺牲性能保一致。
- 常规业务:延迟双删是一个性价比高的方案,能覆盖绝大多数问题。
- 写多读少或可丢失场景(如统计):可考虑 Write Back。
亮点:装饰器模式实现
要展示代码架构能力,可提及使用装饰器模式统一封装缓存逻辑。以下是一个 Read Through 的伪代码示例:
// 1. 定义标准接口
type Cache interface {
Get(key string) any
Set(key string, val any)
}
// 2. 定义 ReadThrough 装饰器
type ReadThroughCache struct {
c Cache // 基础缓存实例
fn func(key string) any // 数据加载函数
}
// 3. 实现 Get 方法,植入 Read Through 逻辑
func (r *ReadThroughCache) Get(key string) any {
// 先查缓存
val := r.c.Get(key)
// 缓存未命中
if val == nil {
// 调用回源函数加载数据
val = r.fn(key)
// 回写缓存
r.c.Set(key, val)
}
return val
}
通过此类设计,可以规范团队缓存使用,并轻松扩展出 Singleflight 等能力。
11. 总结
本文系统分析了 Cache Aside、同步更新、Read Through、Write Through、Write Back、Refresh Ahead、Singleflight 以及删除缓存、延迟双删等策略。其核心矛盾永远是性能与一致性的博弈。
在面试中,能够清晰指出每种模式在何种并发场景下会出问题,并给出如 SETNX 或延迟双删等解决方案,你将展现出超越大多数候选人的深度。掌握这些知识,不仅有助于应对技术面试,更是构建稳健、高性能分布式系统的必备技能。
 发表于 2026-1-10 04:36:08
|
查看: 204|
回复: 0
发表于 2026-1-10 04:36:08
|
查看: 204|
回复: 0
