在涉及海量节点数据的图数据库项目中,实现高效的全文搜索是一个关键需求。本文将分享基于 Python 开发 Neo4j 搜索接口,并重点探讨如何通过创建和使用索引来优化查询性能。
一、Python接口开发:Neo4j全文搜索接口
目标:开发一个能够根据节点description字段进行模糊搜索的后台接口。
第一步:为搜索字段创建索引
当面对可能高达百万级别的节点数据时,为搜索字段建立索引是提升查询效率的必要前提,否则每次查询都将触发耗时的全表扫描。
在 Neo4j 中,创建索引的基本语法如下:
CREATE INDEX ON :Label1:Label2:Label3(commonProperty);
针对实际业务场景,假设我们需要在 COAT CHARACTERISTICS 标签节点的 description 属性上建立索引。早期的索引创建语法如下:
CREATE INDEX ON :`COAT CHARACTERISTICS`(description);
而 Neo4j 推荐使用的新语法更为清晰:
CREATE INDEX FOR (n:`COAT CHARACTERISTICS`) ON (n.description);
执行上述命令后,可以在数据库中查看已创建的索引。
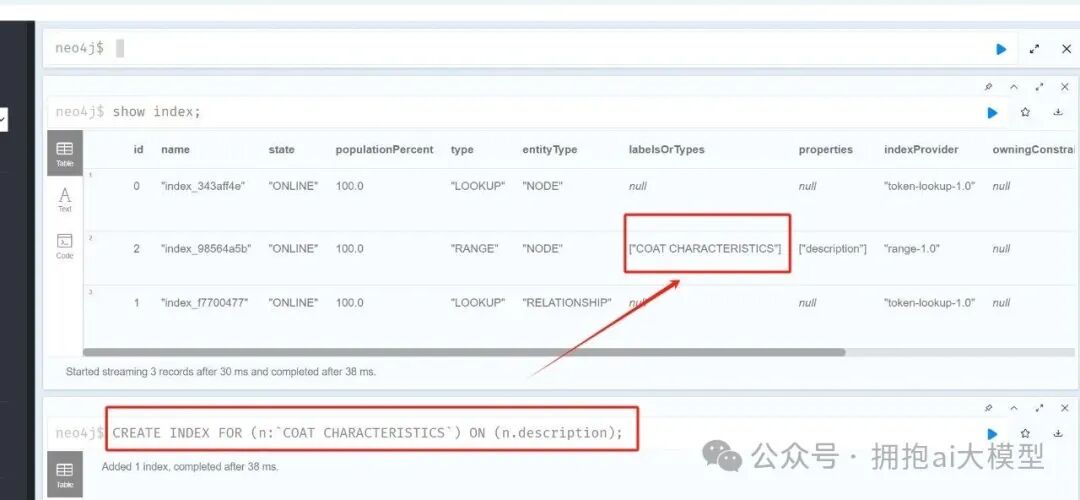
图1:在 Neo4j 中执行索引创建命令并查看现有索引列表
第二步:尝试与挑战——多标签复合索引
在实际业务中,一个属性可能同时属于多个标签的节点。理想的状况是为多个标签的同一属性创建一个复合索引,例如:
CREATE INDEX FOR (n:`COAT CHARACTERISTICS`:`Dog CHARACTERISTICS`) ON (n.description);
但经过尝试,发现 Neo4j 可能不支持这种直接为多个标签创建单一索引的语法。作为妥协方案,目前我们选择为每个需要搜索的标签单独创建索引。如果后续出现性能瓶颈,再考虑其他优化策略。
CREATE INDEX FOR (n:`Dog CHARACTERISTICS`) ON (n.description);
第三步:编写Python接口并验证索引使用
我们的节点数据结构示例如下:
<elementId>: 4:2c5c8dc1-34f7-4ebf-ad49-e6fa23344df8:105
<id>: 105
description: 猫的被毛长度、质地、颜色和图案等外观特征。
entity_type: Dog CHARACTERISTICS
id: 猫的被毛特征
rank: 1
source_id: 0
weight: 1
接下来,我们编写 Python 函数 get_node_data2,它根据传入的参数动态构建 Cypher 查询语句,核心搜索逻辑是使用 CONTAINS 进行模糊匹配。
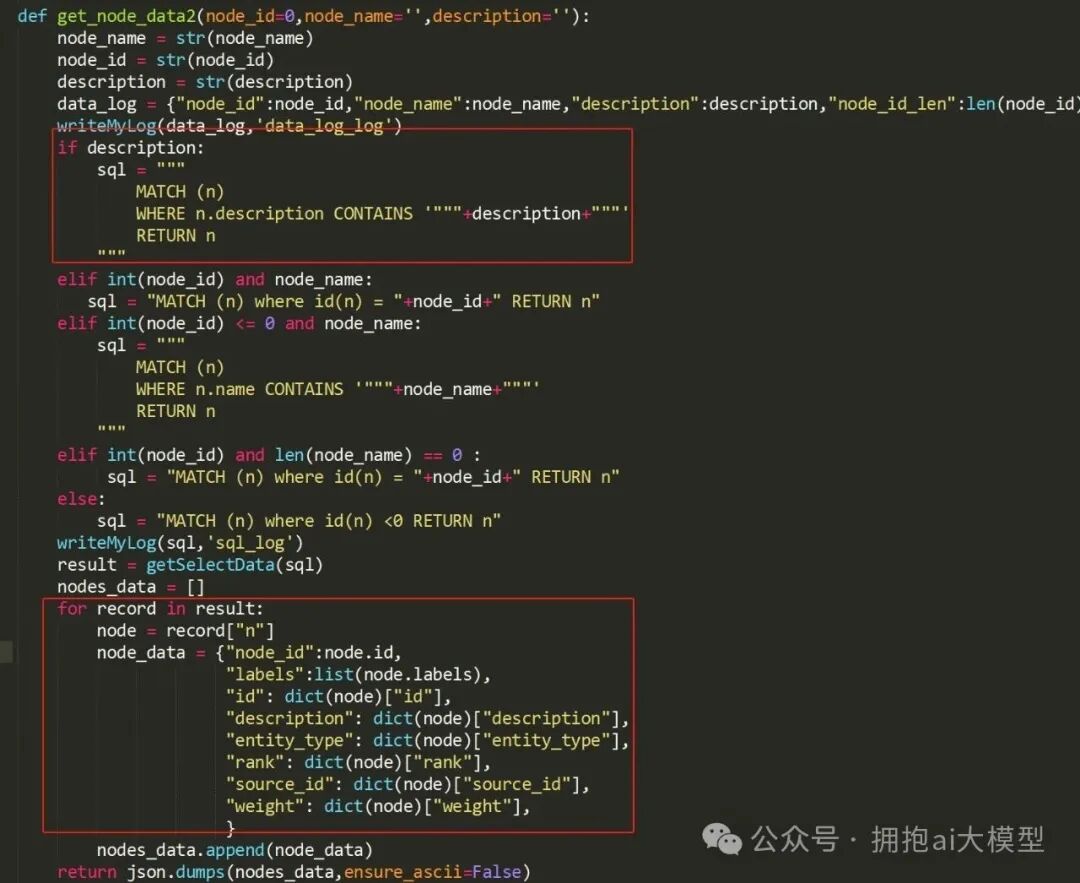
图2:实现动态搜索逻辑的Python函数代码
从函数日志中,我们捕获到实际执行的查询语句为:
MATCH (n) WHERE n.description CONTAINS ‘猫的被毛长度’ RETURN n;
一个关键问题是:这条查询是否用到了我们刚刚创建的索引?我们可以使用 EXPLAIN 或 PROFILE 命令来查看查询的执行计划。
EXPLAIN MATCH (n) WHERE n.description CONTAINS ‘猫的被毛长度’ RETURN n;
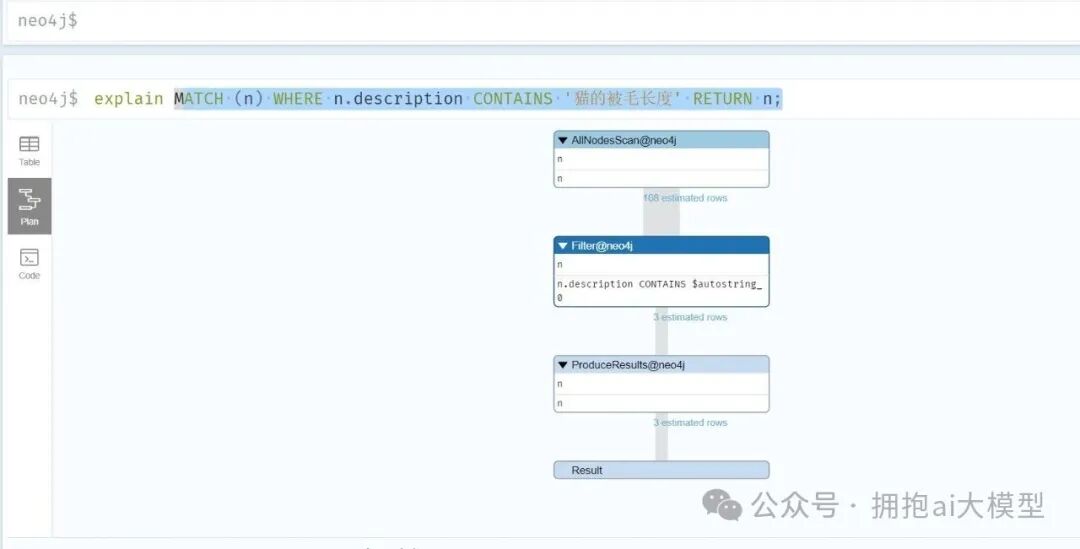
图3:使用EXPLAIN命令分析查询执行计划,显示为“AllNodesScan”
从图3的执行计划可以看出,该查询仍然执行的是“AllNodesScan”(全节点扫描),并没有使用索引。这是因为 CONTAINS 子句默认可能不会触发范围索引。Neo4j 的索引使用有特定规则,对于全文搜索,可能需要使用 =‘value’ 进行精确匹配,或考虑使用 Neo4j 的全文索引功能。在接口开发的初期,我们可以暂时将索引优化问题搁置,优先保证功能的完整性,将节点及其关系数据成功查询并返回。
 发表于 2026-1-10 06:25:29
|
查看: 220|
回复: 0
发表于 2026-1-10 06:25:29
|
查看: 220|
回复: 0
