在构建大型分布式系统时,Kafka 作为核心的消息中间件,其性能表现直接影响整个系统的吞吐与稳定性。准确估算高并发场景下 Kafka 的 TPS(每秒事务数),对于前期的容量规划、运行时的性能优化以及长期的成本控制都至关重要。一个科学的估算应基于对系统架构、工作负载特征以及关键资源瓶颈的量化分析,而非依赖单一指标的经验判断。
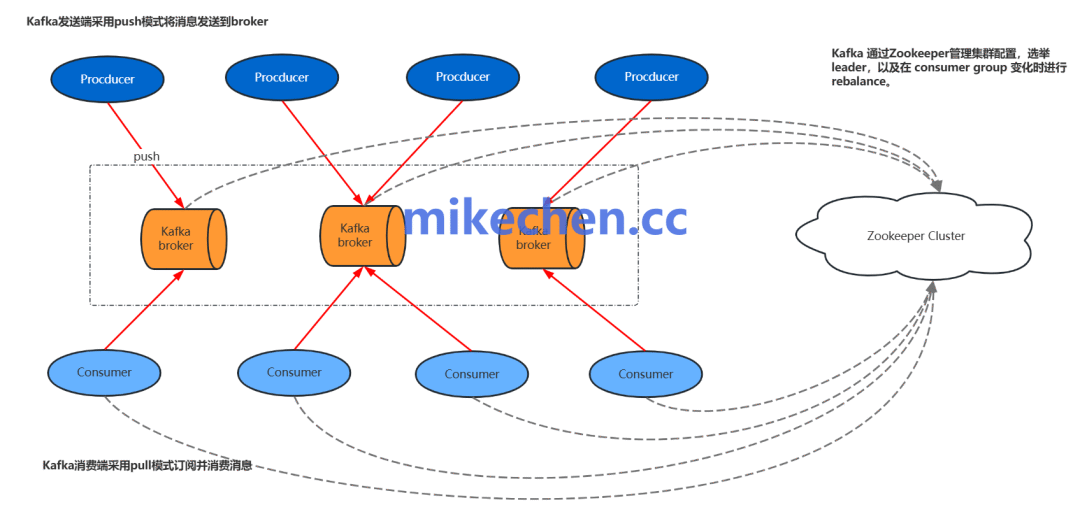
TPS 估算的核心考量
首先需要明确度量的口径。对于 Kafka 而言,TPS 通常指写入(produce)操作的吞吐量。这里必须区分消息数和字节数:即便 TPS 数值相同,如果消息大小、分区数量或批处理策略不同,系统所需的资源将差异显著。因此,在估算前应并行衡量消息吞吐(MB/s) 与消息速率(msgs/s)。
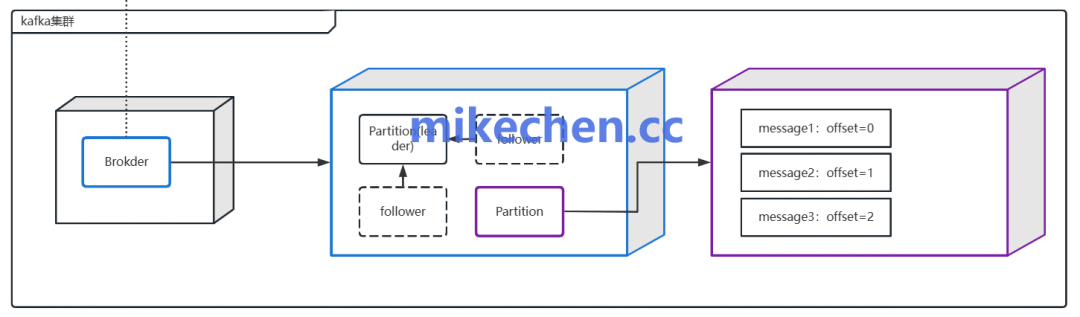
其次,必须系统性地识别影响 TPS 的关键因素,主要包括:
- 消息大小与批量设置 (
batch.size, linger.ms):增大批量可以显著提升吞吐、降低网络请求次数,但会相应增加消息传输的延迟。
- 分区数与副本因子:增加分区能提高生产与消费的并行度,但也会给 Broker 带来更高的元数据管理和文件句柄开销。副本因子则直接影响磁盘 I/O 和网络流量。
- 生产者与消费者并发度:包括客户端线程数、连接数等,这些直接影响网络连接管理和 CPU 使用率。
- 网络带宽与延迟:这是决定最大字节吞吐量的物理上限。
- 磁盘性能与文件系统缓存:磁盘的顺序写/读吞吐量、IOPS 以及对文件系统缓存的利用,直接约束了消息持久化的性能。
- 可靠性策略与压缩:
acks 配置(0/1/all)决定了数据可靠性的级别,同时影响吞吐和延迟;compression.type 压缩可以减少网络传输和磁盘占用的数据量,但会消耗额外的 CPU 资源。
- 序列化/反序列化开销:客户端与 Broker 端对消息的编解码处理,会消耗一定的 CPU 计算资源。
通过综合考虑以上因素,并结合实际的业务负载模型(如峰值流量、消息大小分布等),我们才能对 Kafka 集群在高并发下的 TPS 能力做出相对准确的估算,从而为系统设计和资源采购提供可靠依据。
如果你在系统设计或性能调优中遇到问题,欢迎到云栈社区与更多开发者交流讨论。 |  发表于 2026-1-10 13:20:35
|
查看: 134|
回复: 0
发表于 2026-1-10 13:20:35
|
查看: 134|
回复: 0
