多年没有使用 PageHelper 了,最近加入新公司,接手了一个采用此工具集成框架的独立紧急项目。开发过程还算顺利,但没想到在最终测试阶段,它却带来了一个深刻的教训。
项目遭遇了哪些诡异问题?
一切都要从接手这个项目说起。在开发过程中,各种离奇的问题接踵而至,下面简单列举几个。
账号重复注册?
如字面意思,已经注册过的账号,竟然可以再次注册成功!
else if (UserConstants.NOT_UNIQUE.equals(userService.checkUserNameUnique(username))
|| "匿名用户".equals(username)){
// 注册用户已存在
msg = "注册用户'" + username + "'失败";
}
如上所示,checkUserNameUnique(username) 方法用来验证数据库中是否存在该用户名:
<select id="checkUserNameUnique" parameterType="String" resultType="int">
select count(1) from sys_user where user_name = #{userName} limit 1
</select>
从代码逻辑看,似乎不应该有问题。具体原因我们稍后分析,先看下一个问题。
查询全部分类的下拉列表只返回5条数据?
明明数据库中有十多个分类,为什么接口只返回5个?我并没有添加任何分页参数。
相信用过 PageHelper 的同学已经猜到问题出在哪里了。
修改用户密码报错?
当管理员在后台重置用户密码时,系统居然报错了。
报错信息非常明确:sql语句异常,update语句不认识 “Limit 5”。
至此,报错信息已经揭示了问题的根源——我的 SQL 被意外拼接上了分页参数 limit。
小结
以上提到的只是冰山一角。在实际使用中,凡是涉及 SQL 操作的地方,都可能因为这个分页参数引发问题,主要可以归纳为两类:
- 直接导致报错:如
insert、update 等不支持 limit 的语句,会直接抛出异常。
- 导致业务逻辑错误但无代码报错:
- 如前文提到的用户可重复注册,代码层面其实抛出了异常,但被方法捕获并
throw,最终由全局异常处理器处理了。
- 非分页查询的 SQL 被拼接了
limit,导致没有报错,但返回的数据量错误。
需要注意的是:这些异常并非每次必现,而是有一定概率,但触发频率较高。 原因将在下文中逐步揭晓。
PageHelper 是如何引发上述问题的?
PageHelper 的使用方式
这里主要讲解项目所基于框架的使用方式,代码如下:
@GetMapping("/cms/cmsEssayList")
public TableDataInfo cmsEssayList(CmsBlog cmsBlog){
//状态为发布
cmsBlog.setStatus(“1”);
startPage();
List<CmsBlog> list = cmsBlogService.selectCmsBlogList(cmsBlog);
return getDataTable(list);
}
使用起来很简单:通过 startPage() 指定分页参数,再通过 getDataTable(list) 对结果数据进行分页格式封装。可能有人会问,这里既没有显式传入分页参数,实体类中也没有,这就是关键所在,下一节我们来剖析源码。
startPage() 做了什么?
protected void startPage(){
// 通过request去获取前端传递的分页参数,不需要控制器显式接收
PageDomain pageDomain = TableSupport.buildPageRequest();
Integer pageNum = pageDomain.getPageNum();
Integer pageSize = pageDomain.getPageSize();
if (StringUtils.isNotNull(pageNum) && StringUtils.isNotNull(pageSize))
{
String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());
Boolean reasonable = pageDomain.getReasonable();
// 真正使用pageHelper进行分页的位置
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);
}
}
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable) 的参数含义如下:
pageNum:页码pageSize:每页数据量orderBy:排序规则reasonable:分页合理化,自动处理不合理的参数(如页码小于0则设为1)
继续深入跟踪 startPage 构造方法,最终到达以下位置:
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero){
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
// 1、获取本地分页
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
// 2、设置本地分页
setLocalPage(page);
return page;
}
核心在于 getLocalPage() 和 setLocalPage(page) 这两个方法。
getLocalPage()
查看该方法:
public static <T> Page<T> getLocalPage(){
return LOCAL_PAGE.get();
}
再看看常量 LOCAL_PAGE 是什么:
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
原来是 ThreadLocal。学过 Java 基础都知道,这是每个线程独有的本地缓存对象。当一个请求到来时,会获取处理当前请求的线程的 ThreadLocal,通过 LOCAL_PAGE.get() 检查该线程是否已有未执行的分页配置。
setLocalPage(page)
这个方法显而易见,就是设置线程的分页配置:
protected static void setLocalPage(Page page){
LOCAL_PAGE.set(page);
}
小结
经过前面的分析,问题的症结似乎指向了 ThreadLocal。是不是使用后没有及时清理,导致同一个线程处理下一个请求时,仍然携带了上一次的分页配置?
带着这个疑问,我们来看看 MyBatis 是如何使用 PageHelper 的。
MyBatis 使用 PageHelper 的机制分析
我们需要关注 MyBatis 在何时使用这个 ThreadLocal 来获取分页参数。前面提到,通过 PageHelper.startPage() 设置 page 缓存后,当程序执行 Mapper 接口方法时,就会被 PageInterceptor 拦截器拦截。
PageHelper 作为 MyBatis 的分页插件,其原理正是通过拦截器实现的。我们重点关注 PageInterceptor 的 intercept 方法:
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
// 由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
boundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.ORIGINAL, boundSql, cacheKey);
}
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
我们聚焦几个关键位置:
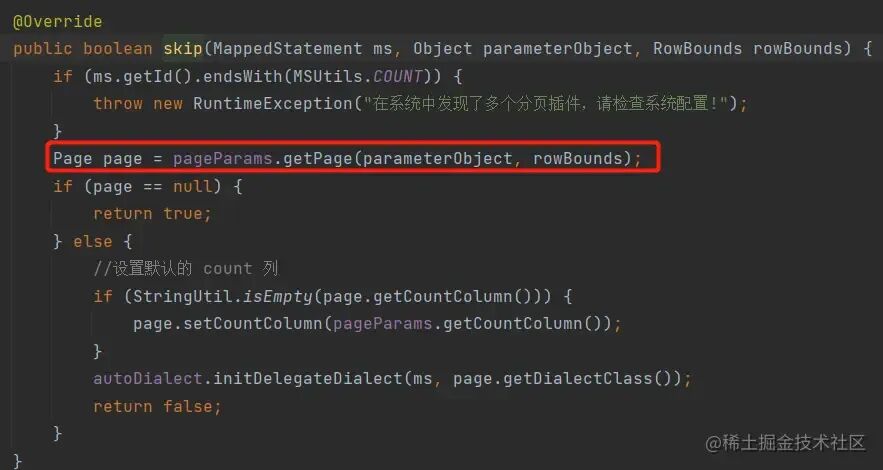
1. 设置分页:dialect.skip(ms, parameter, rowBounds)
此方法内部判断是否启用分页,其中会调用:
Page page = pageParams.getPage(parameterObject, rowBounds);
继续跟踪 getPage(),发现其第一行就从 ThreadLocal 获取值:
Page page = PageHelper.getLocalPage();
2. 统计数量:dialect.beforeCount(ms, parameter, rowBounds)
分页通常需要先获取记录总数。如果 count 为 0,则直接返回空列表,不执行后续分页查询。
3. 分页查询:ExecutorUtil.pageQuery
在处理完 count 后,进行真正的分页查询。是否执行分页,取决于前面从 ThreadLocal 获取的 page 对象。注意,非分页查询以及 insert、update 操作不会进入此分支。
4. 非分页查询:executor.query
如果不满足分页条件,SQL 执行会走到下面的分支:
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
现在可以思考一下:如果 ThreadLocal 在使用后未被清除,当同一个线程执行非分页方法时,dialect.skip() 方法仍然会获取到之前设置的分页 Page 对象。
为什么非分页查询也会被影响?回顾 dialect.skip(ms, parameter, rowBounds) 的逻辑(如下代码截图所示),只要 page 不为 null,该 SQL 就会走上文提到的 ExecutorUtil.pageQuery 分页逻辑,从而导致各种预期之外的情况。
实际上,PageHelper 对分页后的 ThreadLocal 是有清理机制的。
5. 清除 ThreadLocal
在 intercept 方法的 finally 块中,会在 SQL 方法执行完毕后,清理 page 缓存:
finally {
if(dialect != null){
dialect.afterAll();
}
}
查看 afterAll() 方法:
@Override
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
我们只关注 clearPage():
public static void clearPage(){
LOCAL_PAGE.remove();
}
小结
至此,PageHelper 的工作原理已经清晰。整体来看,设计似乎没有问题。但我们可以考虑几种极端情况:
- 调用
startPage() 后未执行 SQL:当前线程的 ThreadLocal 被设置了分页参数但未被消费。下一个使用该线程的请求到来时,就会出问题。
- 程序在执行 SQL 前发生异常:无法执行到
finally 块中的 clearPage() 方法,导致线程的 ThreadLocal 被污染。
因此,官方的建议是:使用 PageHelper 分页时,执行 SQL 的代码必须紧跟 startPage() 方法之后。此外,也可以在可能存在问题的非分页方法前手动调用 PageHelper.clearPage() 进行清理。
注意:不要在需要分页的方法前手动调用 clearPage(),否则会导致分页失效。
为什么问题不是每次请求都出现?
这取决于服务所使用的容器,例如 Tomcat。现代应用服务器(包括基于 Netty 的)通常使用线程池来处理请求,通过复用线程来提高并发能力。
假设线程1持有没有被清除的 page 参数,如果后续某个请求恰好复用了线程1,那么问题就会出现;而使用线程2或线程3的请求则正常。这就解释了问题的随机性。
总结
关于 PageHelper 的这次“踩坑”经历就分享到这里。它确实耗费了我不少排查时间。若不是项目紧急,来不及替换,我可能会考虑其他方案。虽然已经全局检查,确保 startPage() 后紧跟 SQL 命令,但难免有“漏网之鱼”,最终只能在有问题的方法前调用 clearPage() 来打补丁。
尽管 PageHelper 带来了困扰,但在定位问题的过程中,我也深入了解了其与 MyBatis 拦截器的协作机制,对于喜欢阅读源码的同学来说,这未尝不是一次有益的 实战 学习。
本文旨在分享技术排查经验,欢迎前往云栈社区交流更多后端开发中的实战问题与解决方案。
 发表于 2026-1-10 17:12:15
|
查看: 298|
回复: 0
发表于 2026-1-10 17:12:15
|
查看: 298|
回复: 0
