
一、前言
在逆向工程与二进制分析的工具链中,我们已经掌握了两个至关重要的框架,它们各司其职,构成了“看”与“跑”的能力闭环:
- Unicorn (大脑):负责运行代码。它完美模拟 CPU 的寄存器状态、内存访问与指令执行流程。
- Capstone (眼睛):负责查看代码。它将枯燥的机器码(Bytes)精准地翻译成人类可读的汇编指令(Asm)。
然而,一个完整的操控链条还缺少关键一环:当我们想要主动修改程序逻辑时该怎么办?例如,我们需要 Patch 掉一段反调试检测代码,或是向内存中注入一段全新的 Shellcode。这时,我们就需要一双能够“书写”的手——Keystone。
1. 什么是 Keystone?
Keystone 是一个轻量级、多平台、多架构的汇编框架。它的作用与 Capstone 正好相反:Capstone 将机器码转为汇编,而 Keystone 将汇编代码编译回机器码。它是实现动态代码修改与生成的桥梁。
2. Keystone 的核心价值
-
人类可读 -> 机器可读
只需一行汇编指令,例如 INC RAX,Keystone 能瞬间将其转换为对应的机器码 \x48\xFF\xC0。
-
多架构支持
通过一套统一的 API,即可支持 x86, ARM, MIPS, PowerPC, SPARC 等主流架构,无需安装笨重的 GCC 或交叉编译工具链。
-
动态灵活
它以库(Library)的形式提供,而非独立的编译器。这意味着你可以在 Python 脚本运行时动态生成和修改代码,实现真正的运行时“Just-In-Time”汇编。
二、环境准备与基础概念
1. 环境安装
安装 Keystone 引擎非常简单,但请务必注意包名,避免与同名项目冲突。
# 正确做法:安装 Keystone 汇编引擎
pip install keystone-engine
# 错误做法:安装 'keystone'
# 'keystone' 是 OpenStack 的身份认证组件,装错会导致冲突!
2. 核心类解析
在 Python 脚本中,我们主要与以下两个类交互:
Ks (Keystone Engine):汇编引擎的主入口。需要实例化它以创建一个汇编器对象。
- 初始化:
ks = Ks(arch, mode)
- 核心方法:
ks.asm(code_string, addr)
KsError (Exception):异常处理类。当汇编代码存在语法错误(如指令拼写错误、操作数不匹配)时,Keystone 会抛出此异常。
3. 架构与模式 (Architecture & Mode)
Keystone 的常量命名规范与 Unicorn/Capstone 保持高度一致,你只需将前缀 UC_ 或 CS_ 替换为 KS_ 即可轻松上手。
常用架构与模式组合对照表:
| 目标环境 |
Unicorn |
Capstone |
Keystone |
| x86 (32位) |
UC_ARCH_X86, UC_MODE_32 |
CS_ARCH_X86, CS_MODE_32 |
KS_ARCH_X86, KS_MODE_32 |
| x64 (64位) |
UC_ARCH_X86, UC_MODE_64 |
CS_ARCH_X86, CS_MODE_64 |
KS_ARCH_X86, KS_MODE_64 |
| ARM (32位) |
UC_ARCH_ARM, UC_MODE_ARM |
CS_ARCH_ARM, CS_MODE_ARM |
KS_ARCH_ARM, KS_MODE_ARM |
| ARM Thumb |
UC_ARCH_ARM, UC_MODE_THUMB |
CS_ARCH_ARM, CS_MODE_THUMB |
KS_ARCH_ARM, KS_MODE_THUMB |
4. 语法格式 (Syntax)
对于 x86 架构,汇编语言存在不同的书写格式。Keystone 允许通过 KS_OPT_SYNTAX 选项来切换语法风格。
KS_OPT_SYNTAX_INTEL (默认):Intel 语法。
- 特点:
mov dst, src。这是绝大多数逆向工具(如 IDA Pro、x64dbg)的默认显示风格。
- 示例:
mov eax, 1
KS_OPT_SYNTAX_ATT:AT&T 语法。
- 特点:
mov src, dst,寄存器前加 %,立即数前加 $。常见于 Linux 环境下的 GCC 和 GDB。
- 示例:
mov $1, %eax
KS_OPT_SYNTAX_NASM:NASM 语法。
- 特点:与 Intel 语法类似,但在内存寻址和宏处理上更加严格规范。
设置方法:
ks = Ks(KS_ARCH_X86, KS_MODE_64)
# 切换到 AT&T 语法
ks.syntax = KS_OPT_SYNTAX_ATT
三、静态汇编初体验
在将 Keystone 与 Unicorn 集成之前,我们先独立运行它,直观感受如何将一行汇编语句翻译成机器码。
目标:将汇编指令 “xor rax, rax; inc rax” 编译为 x64 架构的机器码。
示例代码:
from keystone import *
# 1. 准备汇编代码
# 使用分号 ; 分隔多条指令
ASSEMBLY = "xor rax, rax; inc rax"
try:
# 2. 初始化汇编引擎
# 架构: x86, 模式: 64位
ks = Ks(KS_ARCH_X86, KS_MODE_64)
# 3. 执行编译 (Assemble)
# ks.asm(code, addr=0)
# code: 汇编字符串
# addr: (可选) 起始地址,用于计算相对跳转偏移,默认为 0
encoding, count = ks.asm(ASSEMBLY)
# 4. 输出结果
print(f"Assembly: {ASSEMBLY}")
print(f"Encoding: {encoding}") # 原始整数列表
print(f"Count : {count}") # 成功编译的指令数量
# 关键步骤:将 list[int] 转换为 bytes
# Unicorn 的 mem_write 等方法需要 bytes 类型
machine_code = bytes(encoding)
print("Machine Code: ",end="")
for i in range(len(machine_code)):
print(f"{machine_code[i]:02x}", end=" ")
print()
except KsError as e:
print(f"ERROR: {e}")
运行结果:
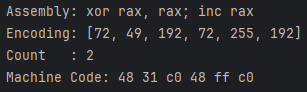
核心 API 详解:ks.asm()
ks.asm() 方法的返回值是一个元组 (encoding, count):
-
encoding (list[int]):
- 这是一个整数列表,例如
[0x48, 0x31, 0xC0, 0x48, 0xFF, 0xC0]。
- 注意:它不是 Python 的
bytes 对象!如果直接把它传给 uc.mem_write,Unicorn 会报类型错误。
- 正确做法:使用
bytes(encoding) 将其转换为二进制字节流。
-
count (int):
- 表示成功编译的汇编语句数量(以
; 分隔)。
- 如果编译失败(如语法错误),Keystone 会抛出
KsError 异常,而非返回错误码,因此务必使用 try-except 进行包装。
四、核心实战:Unicorn + Keystone 动态代码修改
理论学习之后,让我们进入实战环节,看看如何结合 Unicorn 与 Keystone 实现强大的动态代码修改(Patching)功能。
场景 1:NOP 填充 (指令抹除)
需求:
在逆向分析中,我们常需要“抹掉”某些指令,例如反调试检查(RDTSC、CPUID)或无关的垃圾代码。假设在地址 0x400000 处有一条 XOR EAX, EAX 指令(长度 2 字节),我们希望将其替换为 NOP(空指令),让 CPU 什么也不做直接滑过。
核心思路:使用 Keystone 生成等长的 NOP 指令机器码,覆盖目标内存区域。
示例代码:
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
# 1. 初始化所有引擎
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
# 2. 准备内存环境
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
# 写入原始代码: xor eax, eax (2字节) + inc eax (2字节)
# 机器码: 31 c0 ff c0
ORIGINAL_CODE = b"\x31\xc0\xff\xc0"
mu.mem_write(ADDRESS, ORIGINAL_CODE)
print("--- [Before Patch] ---")
for insn in cs.disasm(mu.mem_read(ADDRESS, 4), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
# ==========================================
# 3. 核心操作:NOP Patch
# ==========================================
TARGET_ADDR = 0x400000
PATCH_LEN = 2 # 需要覆盖的长度 (xor eax, eax 是 2 字节)
print(f"\n Patching {TARGET_ADDR:x} with {PATCH_LEN} NOPs...")
# 生成 NOP 机器码 ("nop; nop")
# encoding -> [0x90, 0x90]
encoding, _ = ks.asm("nop; " * PATCH_LEN)
# 写入内存覆盖原指令
mu.mem_write(TARGET_ADDR, bytes(encoding))
# ==========================================
# 4. 验证结果
# ==========================================
print("\n--- [After Patch] ---")
# 读取内存查看变化
patched_code = mu.mem_read(ADDRESS, 4)
for insn in cs.disasm(patched_code, ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
# 模拟执行验证
print("\n Executing...")
mu.reg_write(UC_X86_REG_RAX, 10) # 初始值 10
mu.emu_start(ADDRESS, ADDRESS + 4)
print(f"RAX = {mu.reg_read(UC_X86_REG_RAX)}")
# 结果应为 11 (因为 XOR 被 NOP 掉了,只有 INC 执行了)
运行结果:
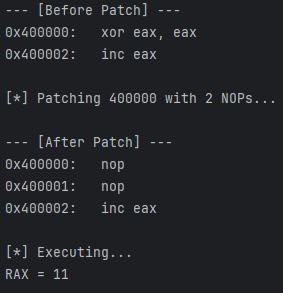
场景 2:逻辑篡改 (Hook & Modify)
需求:
在破解或去混淆时,常需修改关键的条件分支跳转。例如,遇到 TEST EAX, EAX; JZ 0xTarget,如果验证失败(EAX==0)就会跳转到错误分支。我们的目标是:将 JZ(条件跳转)强制修改为 JMP(无条件跳转),确保程序始终走向预期路径。
核心挑战 (JIT 陷阱):
Unicorn 使用 JIT(即时编译)技术加速执行。如果在 UC_HOOK_CODE 回调中动态修改当前正在执行的指令所在内存,CPU 实际上已经完成了该指令的取指和解码,此次修改仅对下一次执行该地址的指令有效。
因此,对于确定的逻辑修改,最佳实践是在模拟启动前 (Pre-Patch) 就完成对内存的修改。
示例代码:
from unicorn import *
from unicorn.x86_const import *
from keystone import *
from capstone import *
# 1. 初始化引擎
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
# 2. 准备内存与代码
ADDRESS = 0x400000
MEM_SIZE = 2 * 1024 * 1024
mu.mem_map(ADDRESS, MEM_SIZE)
# --- 构造模拟场景 ---
# 汇编逻辑:
# 0x400000: XOR EAX, EAX (EAX = 0)
# 0x400002: INC EAX (EAX = 1, ZF = 0)
# 0x400004: JZ 0x40000A (关键跳转:此时 ZF=0,不应跳转)
# 0x400006: INC EAX (EAX = 2, 正常路径)
# 0x40000A: DEC EAX (EAX = 0, 跳转目标)
CODE_ASM = """
xor eax, eax;
inc eax;
jz 0x40000a;
inc eax;
nop; nop;
dec eax;
"""
# 编译并写入原始代码
code_bytes, _ = ks.asm(CODE_ASM, ADDRESS)
mu.mem_write(ADDRESS, bytes(code_bytes))
print("--- [Original Logic] ---")
print("Expectation: EAX=1, ZF=0 -> JZ NOT taken -> EAX becomes 2")
for insn in cs.disasm(bytes(code_bytes), ADDRESS):
print(f"0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
# ==========================================
# 3. 核心操作:静态 Patch (Pre-Patch)
# ==========================================
# 目标:将 0x400004 处的 JZ 修改为 JMP
KEY_JUMP_ADDR = 0x400004
PATCH_ASM = "jmp 0x40000a"
print(f"\n Patching {KEY_JUMP_ADDR:x} to '{PATCH_ASM}'...")
# 编译新指令
# 关键:传入 KEY_JUMP_ADDR 作为基址,以正确计算相对跳转偏移
patch_code, _ = ks.asm(PATCH_ASM, KEY_JUMP_ADDR)
# 覆盖内存
mu.mem_write(KEY_JUMP_ADDR, bytes(patch_code))
# ==========================================
# 4. 执行验证
# ==========================================
print(" Executing...")
try:
# 从头开始执行
mu.emu_start(ADDRESS, ADDRESS + len(code_bytes))
except UcError as e:
print(e)
# 检查结果
final_eax = mu.reg_read(UC_X86_REG_EAX)
print(f"\n Execution finished. Final EAX = {final_eax}")
# 逻辑验证:
# 原逻辑:1 -> inc -> 2 (跳转未发生)
# Patch后:1 -> jmp -> dec -> 0 (强制跳转)
if final_eax == 0:
print(">>> SUCCESS: Jump taken (Logic altered)!")
else:
print(">>> FAILED: Jump not taken.")
运行结果:
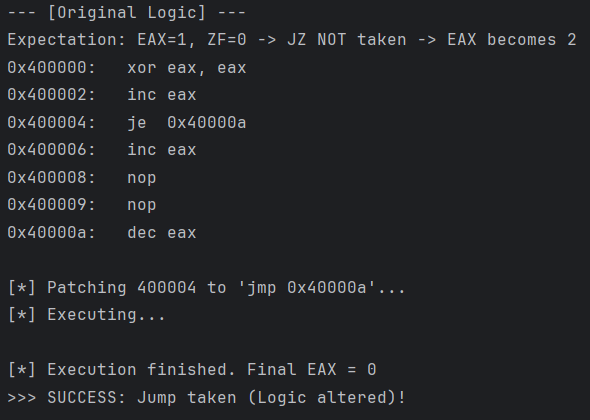
通过这个案例,我们成功利用 Keystone 改变了程序的控制流,强制其执行了本不该发生的跳转,完美演示了如何绕过条件检查。
场景 3:Shellcode 注入
需求:
有时我们需要在程序的代码空洞(Code Cave)或空白内存区域注入一段全新的逻辑,例如打印调试信息、Dump 内存或实现特定功能。
我们需要在内存 0x500000 处写入一段 Shellcode,调用 Linux 的 write 系统调用在标准输出打印 "HACKED",然后让 CPU 跳转执行它。
示例代码:
from unicorn import *
from unicorn.x86_const import *
from keystone import *
import sys
# 1. 初始化引擎
mu = Uc(UC_ARCH_X86, UC_MODE_64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
# 2. 准备内存
# 映射主程序区域(模拟宿主)
mu.mem_map(0x400000, 1024 * 1024)
# 映射 Shellcode 区域
SHELLCODE_ADDR = 0x500000
mu.mem_map(SHELLCODE_ADDR, 1024 * 1024)
# 3. 编写 Shellcode (使用三引号编写多行汇编)
# 逻辑:打印 "HACKED" 到 stdout (fd=1),然后无限循环
CODE_ASM = """
mov rdi, 1;
mov rsi, 0x500100;
mov rdx, 6;
mov rax, 1;
syscall;
loop:
jmp loop;
"""
# 4. 编译并注入
print(f" Compiling shellcode at 0x{SHELLCODE_ADDR:x}...")
# 传入基址以处理相对跳转(此例中jmp loop是相对跳转)
encoding, _ = ks.asm(CODE_ASM, SHELLCODE_ADDR)
machine_code = bytes(encoding)
# 写入代码
mu.mem_write(SHELLCODE_ADDR, machine_code)
# 在 0x500100 写入字符串数据
mu.mem_write(0x500100, b"HACKED")
# ==========================================
# 5. 关键步骤:处理 SYSCALL
# ==========================================
# Unicorn 默认不模拟系统调用,必须手动 Hook 来模拟其行为
def hook_syscall(uc, user_data):
rax = uc.reg_read(UC_X86_REG_RAX)
if rax == 1: # write 系统调用号
fd = uc.reg_read(UC_X86_REG_RDI)
buf = uc.reg_read(UC_X86_REG_RSI)
cnt = uc.reg_read(UC_X86_REG_RDX)
data = uc.mem_read(buf, cnt)
print(f">>> write({fd}, {data.decode()}, {cnt})")
# 手动推进 RIP,跳过 syscall 指令(2字节: 0f 05)
rip = uc.reg_read(UC_X86_REG_RIP)
uc.reg_write(UC_X86_REG_RIP, rip + 2)
# 添加指令级别的 Hook,只针对 SYSCALL 指令
mu.hook_add(UC_HOOK_INSN, hook_syscall, None, 1, 0, UC_X86_INS_SYSCALL)
# ==========================================
# 6. 执行 Shellcode
# ==========================================
print(" Jumping to shellcode...")
# 强制修改 RIP (指令指针) 指向 Shellcode 入口
mu.reg_write(UC_X86_REG_RIP, SHELLCODE_ADDR)
try:
mu.emu_start(SHELLCODE_ADDR, SHELLCODE_ADDR + len(machine_code))
except UcError as e:
print(f" Execution stopped: {e}") # 预期会停在无限循环
运行结果:
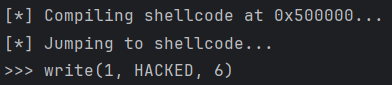
通过 Keystone,我们无需手动查阅指令手册拼凑机器码,直接用直观的汇编语言就实现了复杂的代码注入功能,极大地提升了逆向工程与漏洞利用中代码编写的效率。
五、进阶技巧:处理复杂指令与符号
在掌握了基础用法之后,Keystone 还提供了一些高级特性来应对更复杂的编译需求,例如灵活切换汇编语法风格、以及处理代码中的符号标签。
1. 语法格式切换
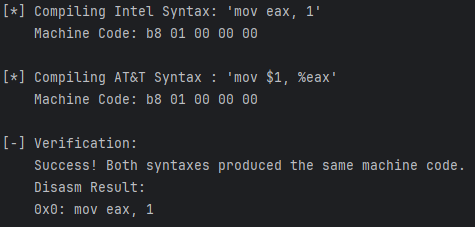
Keystone 默认使用 Intel 语法,但你也可以轻松切换到 AT&T 或 NASM 语法。下面的代码演示了如何切换并验证不同语法编译出的机器码是否一致。
from keystone import *
from capstone import *
# 初始化
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
# --- 场景 A: Intel 语法 (默认) ---
intel_asm = "mov eax, 1"
print(f" Compiling Intel Syntax: '{intel_asm}'")
encoding, _ = ks.asm(intel_asm)
machine_code_intel = bytes(encoding)
# 打印机器码 hex
print(f" Machine Code: ",end="")
for i in machine_code_intel:
print(f"{i:02x}",end=" ")
print()
# --- 场景 B: AT&T 语法 ---
# 切换语法模式
ks.syntax = KS_OPT_SYNTAX_ATT
att_asm = "mov $1, %eax"
print(f"\n Compiling AT&T Syntax : '{att_asm}'")
encoding, _ = ks.asm(att_asm)
machine_code_att = bytes(encoding)
print(f" Machine Code: ",end="")
for i in machine_code_att:
print(f"{i:02x}",end=" ")
print()
# --- 验证结果 ---
print("\n[-] Verification:")
if machine_code_intel == machine_code_att:
print(" Success! Both syntaxes produced the same machine code.")
# 反汇编看一眼
print(" Disasm Result:")
for insn in cs.disasm(machine_code_att, 0):
print(f" 0x{insn.address:x}: {insn.mnemonic} {insn.op_str}")
else:
print(" Failed! Logic mismatch.")
运行结果:
2. 符号解析
在编写汇编代码时,使用标签(Label)进行跳转是更符合人类思维的方式,例如 jmp loop_start。然而,Keystone 的 Python 绑定默认不包含复杂的符号解析回调(Symbol Resolver Callback)功能。
Pythonic 解决方案:利用 Python 强大的字符串格式化功能(f-string),在将代码送入 Keystone 编译之前,手动完成符号的“链接”工作。这实际上是一种更灵活、更直观的“预编译”处理。
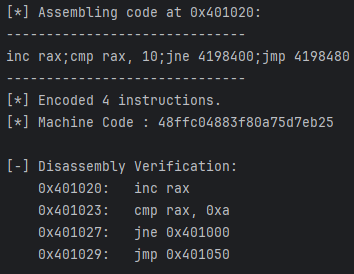
示例:假设我们需要在地址 0x401020 处编写一段包含条件跳转的循环逻辑。
from keystone import *
from capstone import *
# 1. 初始化引擎 (x86-64)
ks = Ks(KS_ARCH_X86, KS_MODE_64)
cs = Cs(CS_ARCH_X86, CS_MODE_64)
# 2. 定义符号表 (Symbol Table)
# 模拟程序中的关键地址
SYMBOLS = {
"LOOP_START": 0x401000,
"FUNC_EXIT": 0x401050
}
# 当前代码的写入地址 (基址)
# Keystone 需要这个地址来计算相对跳转的偏移量
CURRENT_ADDR = 0x401020
# 3. 编写汇编 (使用 f-string 动态替换符号)
# Python 会自动将 {SYMBOLS['...']} 替换为对应的整数地址
asm_code = (f"inc rax;"
f"cmp rax, 10;"
f"jne {SYMBOLS['LOOP_START']};" # 跳转到 0x401000
f"jmp {SYMBOLS['FUNC_EXIT']}") # 跳转到 0x401050
print(f" Assembling code at 0x{CURRENT_ADDR:x}:")
print("-" * 30)
print(asm_code)
print("-" * 30)
try:
# 4. 执行编译
# 关键:必须传入 CURRENT_ADDR 作为第二个参数 (基址)
# 否则 Keystone 会认为基址是 0,导致生成的跳转偏移量错误
encoding, count = ks.asm(asm_code, CURRENT_ADDR)
machine_code = bytes(encoding)
# 5. 输出机器码
print(f" Encoded {count} instructions.")
print(f" Machine Code : {machine_code.hex()}")
# 6. 反汇编验证 (使用 Capstone)
print("\n[-] Disassembly Verification:")
for insn in cs.disasm(machine_code, CURRENT_ADDR):
print(f" 0x{insn.address:x}:\t{insn.mnemonic}\t{insn.op_str}")
except KsError as e:
print(f"[!] Error: {e}")
运行结果:
这种方法结合了 Python 的灵活性与 Keystone 的编译能力,使得编写和维护包含复杂控制流的汇编代码变得更加容易。
六、总结
至此,我们已经完整地学习了二进制分析与逆向工程领域的“三剑客”:Unicorn、Capstone 和 Keystone。这三个框架各司其职,协同工作,构成了一个从读取、修改到执行的全功能闭环:
- Unicorn (Run):模拟执行引擎。负责维护 CPU 的完整状态(寄存器、内存),并忠实地执行每一条机器指令。
- Capstone (Read):反汇编引擎。将内存中原始的、难以理解的机器码(
0101)精准地翻译成人类可读的汇编指令,是我们的“眼睛”。
- Keystone (Write):汇编引擎。将我们用高级逻辑描述的汇编代码,编译回机器可执行的二进制码,并注入到模拟环境或真实进程中,是我们的“双手”,实现了对程序的主动干预和创造。
协作流程图清晰地展示了这一过程:
掌握这三个框架,意味着你拥有了在虚拟沙箱中动态分析、调试甚至重塑二进制程序行为的强大能力。无论是进行恶意软件分析、漏洞利用研究,还是软件保护与破解,这套工具链都是不可或缺的利器。希望这篇深入浅出的指南能帮助你在云栈社区的探索之路上更进一步。

 发表于 2026-1-12 00:45:28
|
查看: 215|
回复: 0
发表于 2026-1-12 00:45:28
|
查看: 215|
回复: 0
