大模型领域的发展,让我对时间的流速有了截然不同的认知。
一方面,由于一直在埋头推进诸多事项,从微观层面来看,痛苦总会让人觉得时间过得很慢。另一方面,领域的快速发展、不断突破的模型性能与层出不穷的新特性,又让人感觉时间飞逝——竟能在这么短的时间内发生如此多的变化。
从上次选 offer(22 年秋招之后,强化学习路在何方?)到现在,已经过去了 n 个月,也积攒了不少感触想要分享讨论。
我是在 24 年 9 月初离开网易伏羲实验室的,决策逻辑与当初选择 offer 时一脉相承:在那个时间节点,我认为 LLM 能够赋予 RL 更大的想象空间和更广泛的影响力,因此决定离开这个更专注于游戏场景的实验室,去往一个拥有更多资源、也更加专注大模型的地方。
题外话,非常感谢伏羲实验室的老板们对我的支持。在毕业确定 offer 后,大约是 22 年 12 月左右,我便再次提前去伏羲实验室实习了。那个时间点恰逢 ChatGPT 横空出世,各方都希望能赶上这波东风。
由于之前在伏羲实习过,老板对我有一定的信任基础,所以这件事我便自然而然地参与了进来。在伏羲期间,最初用了用 trlx,后来裸着用 deepspeed-chat,自己动手魔改代码以支持当时的训练目标。
比较有意思的是,还用 ray 的 serve 搭建了一个能够动态组 batch 的在线推理服务,从而较好地支持了多个 DP worker 实际上并不那么一致的负载请求,训练了一些偏向人设对话的 RLHF 任务。
再次题外话。因为一直很关心 RL 的实现细节,同时对工程实现也颇有兴趣,所以很早就开始自己编写各种简陋的 RL 训练框架,同时也会参与一些社区开发。
那时候社区其实没几个人,大伙多多少少都相互认识,所以在初七( @初七123334 )启动 OpenRLHF 的时候,我也参与了一脚。说句实在话,OpenRLHF 确实实实在在地推动了世界范围内各家公司的 RLHF 开发进展,这一点,初七的贡献值得被反复强调。
另外,再次题外话,真的很感慨人的命运。正如刚才所说,因为个人兴趣使然,我也会很关心 infra——毕竟 RL 的一种理解角度就是用搜索算力换取性能,因此更高效的实现才能训练出更好的 model。
于是,我尝试将自己比较关心的传统 RL 分布式训练相关的论文和系统总结了一遍,写了一篇知乎文档(一个分布式深度强化学习(Distributed Deep Reinforcement Learning)的简单 slide)。
同时,为了满足自己阅读他人代码的小欲望,我搜集了当时几乎所有开源的RL训练库,整理成一个 GitHub repo:
https://github.com/wwxFromTju/awesome-reinforcement-learning-lib
对库实现感兴趣的不止我一个,因此也有不少同学来帮忙补充信息,并格式化 readme 等。比如现在大名鼎鼎的、在 OAI 担任 post training infra 负责人、在多个 GPT 报告中留名的苹果哥(@Trinkle),当时还在 CMU 读硕士,就帮着调整了一些格式并补充了信息。对比起来,我还在辛苦搬砖,命运啊。
从 24 年 9 月 9 日入职至今,已有一年三个多月了。如果要吹牛的话,那肯定会说自己干了很多事,但坦率地说,一开始 landing 并不顺利,原因也是多方面的。
一方面,RLHF 的优化效果本身就很难衡量,加之链路很长,偏好数据、reward model 效果,真是公说公有理、婆说婆有理,而我自认是一个对文字不太敏感的人,所以也很难做一个称职的反馈者。
另一方面,只能说卡数有限,用起来确实有些捉襟见肘,并且那时在 RL 方向(或者更准确地说是 alignment 方向)的同学有些少——一个正式同学,一个刚入职不久的应届同学,一个校招实习同学。
更棘手的是,那位正式同学是从其他方向转过来的,我们在技术审美上有很强烈的分歧,于是他申请转 base 到北京老板那边,独立开展自己的工作。最终留在杭州实打实干活的,就剩下了一个刚入职不久的应届同学和一个校招实习同学,这对我来说真是个 landing 的下马威。
题外话+1,在我刚过来的时候,某个大佬团队的同学就来找我喝了杯咖啡,问我想不想过去。在我持续犹豫的时候,还又吃了两次饭。不过最终还是想着,人不能打退堂鼓,而且对我来说这算是个新领域,需要做出成绩来证明自己,而不是去一个有更多积累的团队镀金(嘴硬),所以最终还是留了下来。
landing 不太顺利的局面,除了 RLHF 这个领域模糊的优化目标外,RL 本身的实践难度也是一个现实问题。在我来的时候,内部其实已经有一套能够跑起来的训练链路,并且在 online DPO 上取得了一些效果。
但坦率地讲,我个人觉得“有效果”这件事,并不能证明一个 RL 框架是完善或完美的。开句玩笑话,如果一个人刚开始接触 RL,那他的第一个 aha 时刻往往会发生在:一开始训不 work,吐槽 RL 不那么 work,到后来发现写了不少 bug,感慨 RL 竟能在这些 bug 的制约下还学得这么好。
用稍微好理解的说法,就是只要梯度与真实优化目标的梯度方向能够大致一致(比如形成锐角),那么实际跑起来的训练就能看到增益。回归正题,就是能训起来有效果的框架,实际上还有很多细节值得打磨,从而获得更好的效果。
另外,一开始的框架用的是 torch rpc,启动任务后,debug 和查看日志都面临不少挑战。幸运的是,在支持训练的 infra 团队那边,有一位同学在初期接触时与我非常同频,加上社区有 OpenRLHF 这样优秀的工作,在几次开会后,我和这位同学两个人便开始启动了新框架的开发。
回过头来看,这也是 ROLL 的诞生时刻。说实话,因为 landing 不太顺利,我感觉自己在一开始也没什么太好的产出,属于出苦力干活,搞框架看细节,而框架的进展在最初也没太被关注。
就这样蹉跎到了年底,迎来了 Deepseek-R1 时刻。那时候,“不甘心”可以说充斥着我的内心。我连续好久都在反思自己这段时间在干什么,为什么会这样——别人在改变世界,我在干啥??
情绪越积越浓,终于找到+1 老板表了态,希望获得一定的支持来做 reasoning 这件事。那个时间点是在春节前几天,同学们都已陆续请假回家,来不及启动项目,于是就这样过了春节。
春节期间,我被几个朋友拉了个群,他们都在哼哧哼哧加班训练 reasoning 能力,还开了个小玩笑“xxx 还在欢度春节”。虽然我在春节期间跑的任务已经挤满了整个队列,但那时候的“不甘心”情绪可以说更加浓烈了。
于是在节后,我再次找到老板说:给我时间和卡,一段时间后如果没有结果,那我背责任走人。幸运的是,老板表示了支持。于是我私下找了可以合作的同学逐一确认,拉了一个小团队开始 rush reasoning 优化这件事。
接下来,便是常见的痛苦时刻——收集数据、训模型、评测,这三板斧轮流来。从 Qwen2.5 32B dense 到内部的百 B MOE,可以说一步一个脚印。到现在还清晰地记得,每天醒来第一件事是看钉钉有无任务失败的提醒,第二件事是打开训练日志查看训练效果。
出门吃饭时,老婆开车,我在副驾写代码、起实验。随着训练的推进,加入的 infra 同学也越来越多,小团队紧密合作,一切都在步入正轨。直到 4 月中旬,阶段性完成了 reasoning 训练的第一阶段,取得了一些效果。
虽然我没有提,但老板主动提了晋升,也算是给自己的不甘心有了一个好的交代。另外,也算是通过这件事,与不少同学建立了信任关系。在训练 reasoning 阶段可以说是燃尽了自己,所以请了一周假和老婆去日本旅游。
但人啊,总是会想着未来的事。因为自己本身是 RLer,相比 RLVR(说实话,RLVR 其实就是一个 bandit 问题,不是纯粹的 RL 优化链路),我更相信 RL 在多轮交互时的优势与价值。所以一直在向各位老板强调 agentic 能力的重要性,同时也在框架侧和同学们探讨如何设计才能更符合 agentic 训练的需求。
作为一个传统的 RLer,gym 是一个不可能绕过的库,因此从一开始,我们就选择了 gym 的几个标准 API 接口作为基础(后来 GEM 出现后,我们便选择了它)。同时,正如前面所说,RLVR 其实就是一个 bandit 问题,不是纯粹的 RL 优化链路,所以我们基于已有框架的基本功能,构建了面向 agentic 的新优化链路。
因为以前做过不少传统的 RL 优化系统,很自然会想到我们需要 remote env 等能力,于是便在框架中预埋了接口,留待后续使用。虽然 reasoning 这件事在内部做得还行,但外部的同学似乎闻所未闻,这让小伙伴们心里都憋着一股劲,总想着对外发出点声音。
幸运的是,在各位大佬的帮助下,组织允许我们开源内部使用的 RL 框架。由于 RL 框架一开始就是面向内部基建开发的,有不少与内部基建紧耦合的地方,所以小伙伴们手忙脚乱地对框架进行修改。
同时还需要撰写介绍框架的 report,于是我便和几个小伙伴在 overleaf 开启巴拉巴拉模式,赶在 5 月 30 号把东西搞定,在 GitHub 开源并发布了 report。那时候就是想“卷”,所以先把框架的缩写定为 ROLL,再倒推对应的全称。机缘巧合,ROLL 这个词有很多衍生空间,这就是后话了。
这个过程实在太累了,于是端午节和老婆两人去安吉休养生息。我还记得那天下着雨,我坐在阳台看着远山发呆,然后拿着手机和最初合作的小伙伴说:没想到咱们最终能够开源这个框架。

人嘛,总不能一直很卷。卷不动了,就想着歇歇,做点探索。而且想做 RL 的同学也变多了,于是我便拉起了对应的 RL 小组,取名为 Agentic Reasoning Model(并弄了一个规划脑图,给大伙持续洗脑哈哈哈哈)。
从 alignment 时代到 reasoning 时代,各种 XPO 层出不穷,新 paper 非常之多,改点 trick 就是一篇新 paper,这让作为 RLer 的我非常震惊。如果你看过我以前参与的两篇 ICLR Blog 和一个 COLM(The 37 Implementation Details of Proximal Policy Optimization和Rethinking the Implementation Tricks and Monotonicity Constraint in Cooperative Multi-agent Reinforcement Learning、arXiv reCAPTCHA),就会知道传统 RL 实现中有非常多细节的 trick,但原来社区的大伙并不会加点 trick 就给算法取个新名字。
这激起了我的逆反心理,我想知道这些新 trick 在什么情况下能够生效。于是便和几个小伙伴开启了一个 topic,尝试用实验分析各个 trick 的作用,并最终写了一篇 report(arXiv reCAPTCHA)。简单来说,trick 并非万能,不同 model 需要不同的 trick 组合。
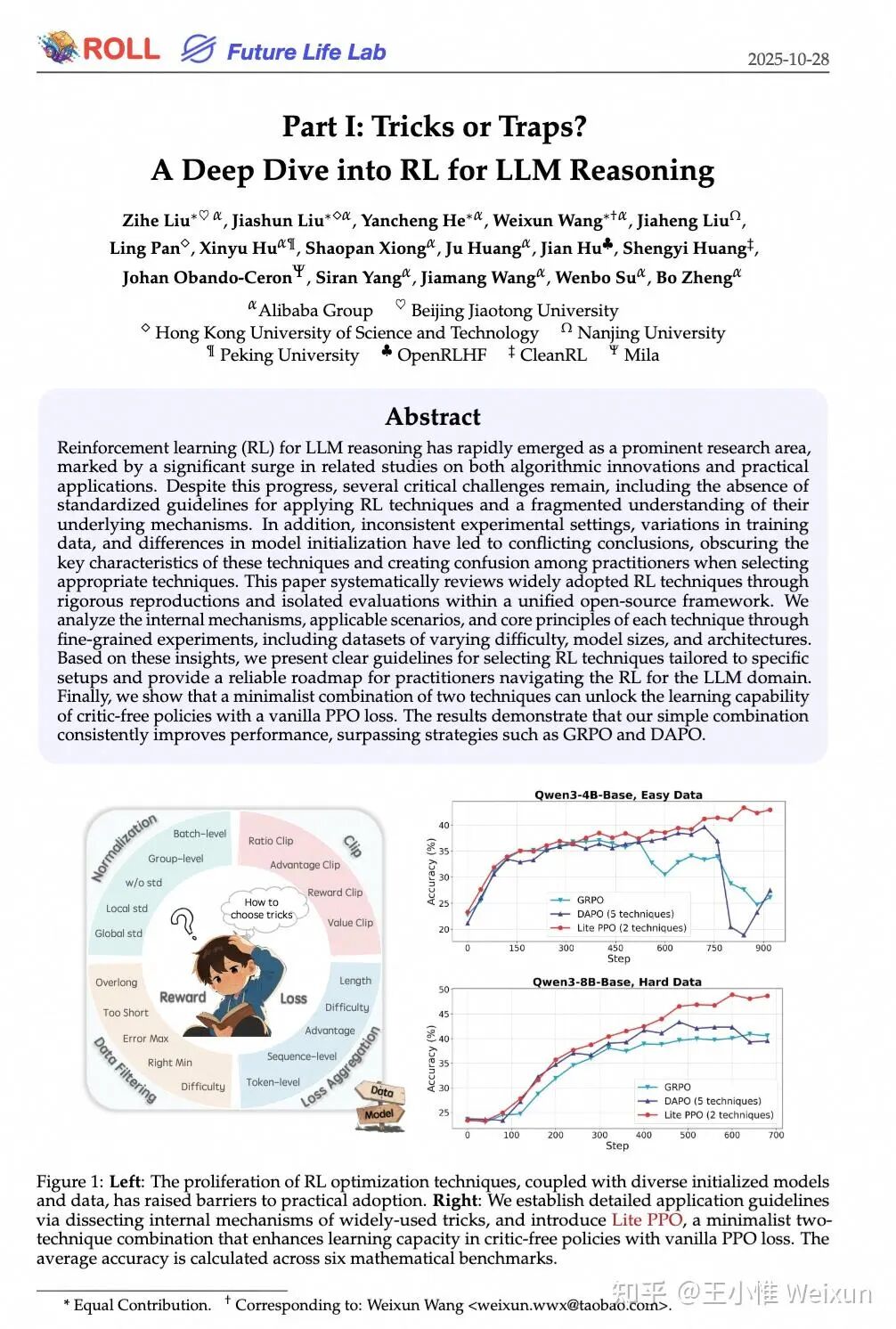
其次,正如前面所说,RL 的一种理解角度就是用搜索算力换取性能,因此更高效的实现才能训练出更好的 model。所以我们需要更快的框架。在传统 RL 领域的一个做法是 async 加速,这里有很多讨论,因为很多算法同学会认为 off policy 在当前 setting 下会影响模型性能。
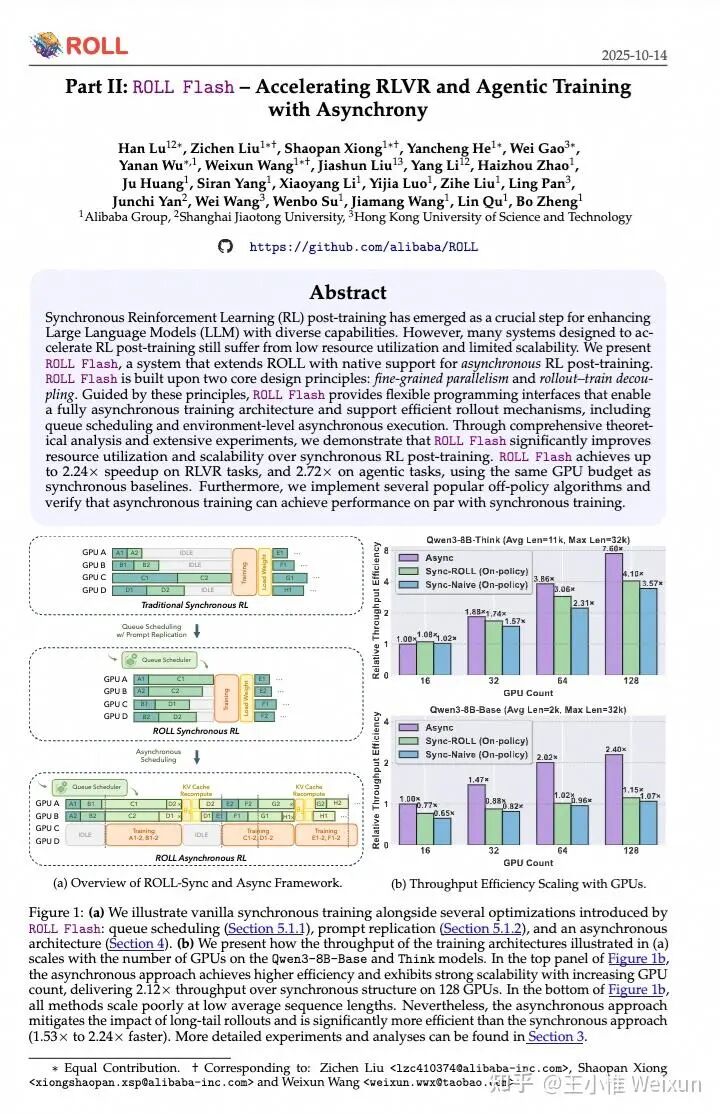
但这个问题先搁置争议,因为是否 off policy、是否 async 会影响性能,是需要与具体算法强绑定来看的。同时,社区中也很快出现了对 async 进行优化的框架 areal,因此我们自然会想对 ROLL 进行升级优化。
基于这样的动机,我们面向 ROLL 的架构提出了 ROLL Flash,强化了 ROLL 框架上的异步能力,使其原生支持异步 RL 后训练系统。ROLL Flash 基于两个核心设计原则:细粒度并行性和部署-训练解耦。我们详细分析了不同场景下异步对效率带来的增益,并在框架中支持了一系列可用于做 off-policy 的算法:Decoupled PPO、TIS、CISPO、TOPR,并进行了调试,发现这些算法在某些 setting 上的性能表现相近,最终也发布了一篇 report(arXiv reCAPTCHA)。
躺久了,老板肯定不满意。同时 agentic 的价值也被逐步认可,所以 9 月初内部便拉起了一个 agentic 能力强化专项。虽然一直在内部给大伙巴拉巴拉 agentic 有多重要,但实际启动时,还是发现缺乏很多关键基建,比如 remote env 部分能力缺失,比如 agent 框架侧并不原生支持训练。
幸运的是,大伙认同这件事,因此随着大伙的投入,做出了 Rock 这个 remote env 管理的新功能(https://github.com/alibaba/ROCK)。并且,为了让 agent 框架的同学能够明白 RL 需要什么,我找到了 agent 框架的负责同学,从 MDP 开始讲 RL 需要的几个核心概念和对应组件。
大伙顺利地从仅使用 agent 框架作为 tool 提供者,到最终可以原生 hook 住训练框架与 agent 框架的交互逻辑,IFlow CLI(https://github.com/iflow-ai/iflow-cli)正式加入 agentic 能力大家庭,AgenticLearning Ecosystem(ALE)至此建立。
除了 infra 的顺畅建立,25 年感觉像是一个轮回,年初痛苦地训 reasoning 能力,年底痛苦地训 agentic 能力。在这个过程中,相比年初,有更多的同学承担起了重担(过程中,大伙那一直板着的脸,真可以说是苦难行军)。
我们基于 IFlow CLI 这个框架,通刷了一遍当前 model 的表现,并通过最朴素的技术路线一步步往前,最终强化出了一个 v0.1 版本的 agentic model:ROME(基于 Qwen3-30A3-coder,Qwen yyds!)。
同时,正如之前所说,RLVR 更像一个 bandit 问题,因此很多面向 RLVR 建模形式的算法,如果朴素迁移到多轮交互的 agentic 场景,可能并不那么合适。所以我们探索了一些改进,比如将建模粒度调整到轮次级别——不论是 ratio 的计算、训推修正还是过滤,都按照轮次这个粒度来。
并且为了解决一些难采样的问题,我们还加入了专家轨迹和各种 reset 机制,最终形成了 Interaction-Perceptive Agentic Policy Optimization(IPA)这个算法。说实话,在这短短三个月内,和小伙伴们一起搞定 infra、搞定数据、搞定训练,真的很难,也做错了很多很多事,不过很多事只能将错就错,一步步往前。所以 V0.1 版本的 ROME,请多多包涵。
希望我们交完学费后,能够避免之前犯的错误,训出更好的模型。最终也写了一篇 report(arXiv reCAPTCHA)。在这里其实我们埋了不少梗,比如因为我很喜欢喝精酿啤酒(虽然老婆不让喝),所以我们的训练系统缩写成了 ALE,是一种啤酒分类(艾尔);同时我们的 RL 算法缩写成了 IPA,这也是一种啤酒分类(印度淡色艾尔)。
此外,为了更极客好玩一些,类似 GNU、WINE 之类的命名风格,我们也采用了类似的方式:ROME(ROME is Obviously an Agentic ModEl)。这个名字,一方面是想说罗马不是一天建成的,需要各种 infra 支持(ALE),同时也需要痛苦的训练。另外,还有一个个人的想法,我个人当前认为 agentic model 的形式会是最终的形态,所以不论你做什么 model 能力,最终都会条条大路通罗马。

前行总是痛苦的,更痛苦的是不甘心。希望新的一年少一些不甘心,纵情向前。这一年的经历让我深刻体会到,从传统的强化学习领域转向大模型训练,不仅需要技术的积累,更需要对复杂工程问题的拆解和持续探索的韧性。如果你想了解更多关于AI开源项目的实战故事和技术细节,不妨来云栈社区看看,这里汇聚了许多开发者的实践与思考。
作者:王小惟 Weixun,已获作者授权发布
来源:https://zhuanlan.zhihu.com/p/1993017628877426830
 发表于 2026-1-12 00:50:44
|
查看: 118|
回复: 0
发表于 2026-1-12 00:50:44
|
查看: 118|
回复: 0
