今天分享一个颇具洞察的AI技术趋势,其核心观点来自一篇题为《AI的万亿美元机遇:上下文图谱(Context graphs)》的文章。

这篇文章的核心论点是:谁能在智能体(Agent)执行动作的瞬间,将“为什么这么做”的决策痕迹捕获下来,并连接成一张可搜索的知识图谱,谁就可能构建AI时代的新一代记录系统,从而把握住一个万亿美元级别的市场机会。
核心洞察:从数据到决策痕迹
-
下一代万亿美元机会不在“数据”本身,而在“决策痕迹”
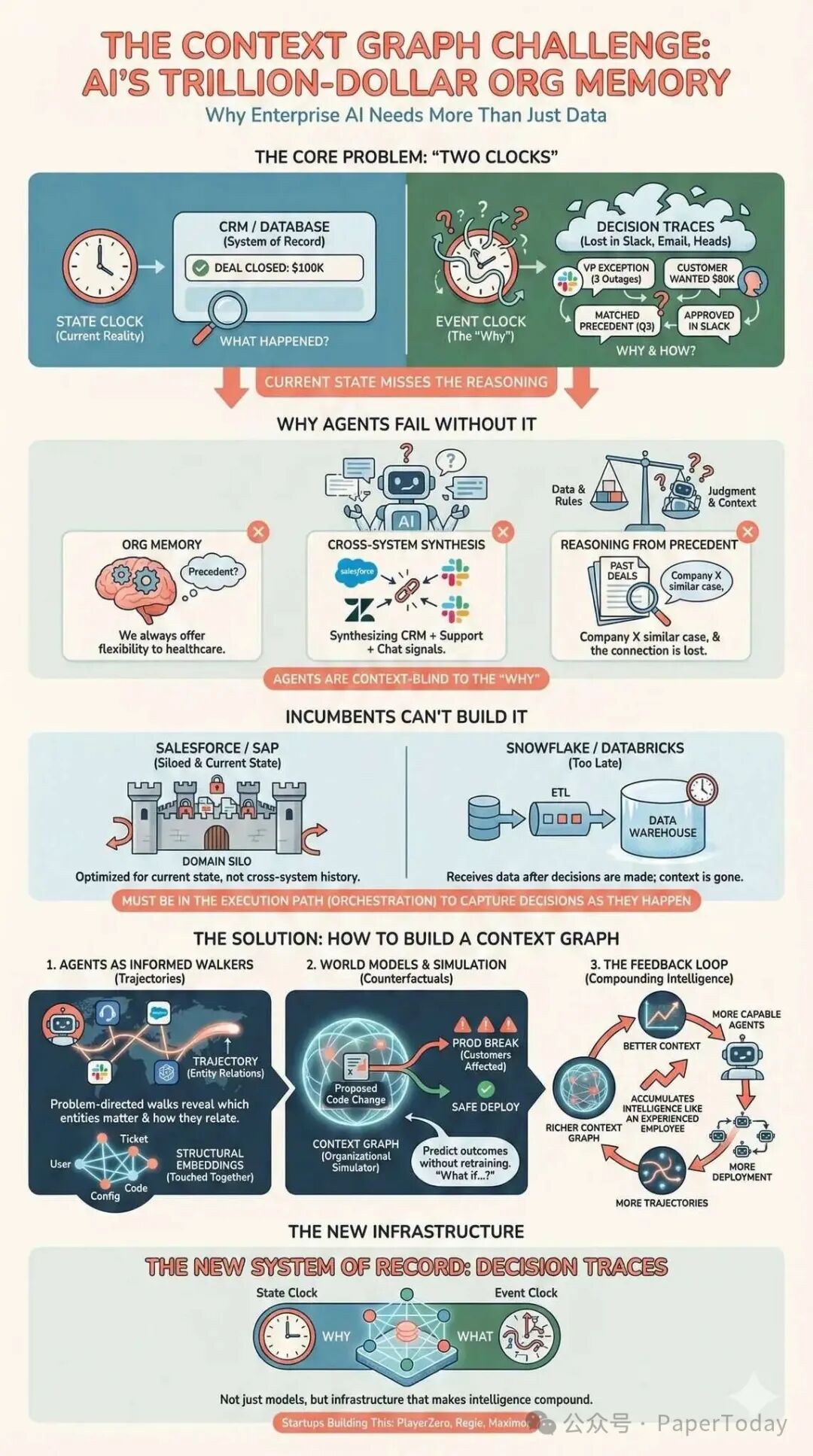
现有的企业系统(如CRM/ERP)主要记录“当前状态”,却丢失了“当时为什么做出这个决定”的上下文。AI智能体要实现真正的自主决策,必须能够查询那些以往只存在于Slack、邮件或人脑中的“决策痕迹”,包括例外情况、历史先例、审批链条等。
-
“上下文图谱” = 将决策痕迹转化为可搜索、可复用的资产
解决方案是在智能体的编排层,将每一次决策的完整过程——“输入信息、应用规则、触发例外、获得审批、产生输出”——作为一个快照持久化下来。这些快照相互关联,最终形成一张跨越不同系统、带有清晰时间线的知识图谱。随着时间推移,这张图谱的价值会不断累积,成为企业新的“真相来源”。
-
传统巨头难以补足这一层
- 运营型巨头(如Salesforce):其系统设计天生用于存储“结果”,而非“决策过程”。
- 数据仓库巨头(如Snowflake):主要在“事后”读取和整合数据,无法在“决策发生时”实时写入决策痕迹。
试图事后补录这些痕迹是徒劳的,因为关键的决策上下文已经丢失,现场无法还原。
-
创业公司的三种切入路径
① 直接重做记录系统,打造AI原生的CRM/ERP。
② 切入一个高频发生“例外”处理的模块(如财务对账、交易审批),先成为该模块的专用“决策系统”,再反向同步至其他系统。
③ 构建跨系统的智能体编排层,从第一天起就将“决策痕迹”作为核心数据存储下来,最终演进为新的“决策记录系统”。
规则与决策痕迹:智能体自主性的关键
规则告诉智能体“在一般情况下应该发生什么”(例如:“报告收入请使用官方ARR定义”)。
决策痕迹则记录了“在这个特定情况下实际发生了什么”(例如:“我们在政策v3.2下使用了X定义,经过副总裁例外批准,基于先例Z,这是我们改变的内容”)。
AI智能体不仅需要规则,更需要访问过去的决策痕迹:看看规则是如何被应用的,哪里授予了例外,冲突如何解决,谁批准了什么,以及哪些先例实际上管理者现实世界的运作。
这就是专注于智能体系统的创业公司所具有的结构性优势:它们位于执行路径之中。它们在决策发生的时刻,能够看到完整的上下文:收集了哪些跨系统输入,评估了什么政策,调用了什么例外路径,谁给予了批准,写入了什么状态。如果将这些痕迹持久化保存,你就能得到当今大多数企业都缺失的东西:一个可查询的决策记录。
我们称这些不断积累的痕迹所形成的结构为上下文图谱:它不是“模型的思维链”,而是一个跨实体、跨时间缝合起来的决策痕迹的动态记录,使得历史先例变得可搜索。随着时间的推移,这个上下文图谱将成为自主智能体真正的真相来源——因为它不仅解释了“发生了什么”,还解释了“为什么它被允许发生”。
核心问题并非现有记录系统是否会存活,而在于是否会出现一个全新的记录系统——一个记录“决策”而非“对象”的系统——以及它是否会成为下一个万亿美元的平台。
上下文图谱作为新型持久层
当创业公司构建智能体编排层,并在每次运行时记录决策痕迹时,它们就拥有了当今企业几乎从未拥有过的东西:一个结构化的、可重演的、关于“上下文如何转化为行动”的历史。
这在实践中是什么样子的?
假设一个续订智能体提议给予客户20%的折扣。公司政策通常将续订折扣限制在10%,除非涉及“服务影响”的例外情况并获得批准。智能体会从PagerDuty提取三个SEV-1事件记录,从Zendesk提取一个“除非问题修复否则取消服务”的升级工单,同时查询到上个季度副总裁曾批准过一个类似例外的续订线程。基于这些上下文,它将例外申请路由给财务部门审批。财务批准后,CRM系统最终只记录了一个简单的事实:“给予20%折扣。”
一旦你拥有了决策记录,“为什么”就变成了一等公民数据。随着时间的推移,这些记录自然形成一个上下文图谱:企业关心的各种实体(账户、续订、票据、事件、政策、审批者、智能体运行实例)通过决策事件(关键时刻)和解释“为什么”的链接连接在一起。公司现在可以审计和调试AI的自主决策过程,并将例外情况转化为可复用的先例,而不是每个季度都在Slack里重新学习相同的边缘案例。
反馈循环是让这一切产生复合效应的关键。捕获的决策痕迹成为可搜索的先例库。每一次自动化决策都为图谱增添一个新的痕迹。
这个过程在第一天并不需要完全自主。它可以始于“人在循环”模式:智能体提出建议、收集上下文、路由审批并记录痕迹。随着时间推移,类似案例不断重复出现,更多的决策路径可以实现自动化,因为系统拥有一个结构化的、包含先前决策和例外的知识库。即使最终决定仍由人类做出,图谱也在持续增长,因为工作流层捕获了输入、审批和理由,并将其作为持久化的先例保存下来,而不是任其消失在Slack的聊天记录中。
原文核心观点来源:https://foundationcapital.com/context-graphs-ais-trillion-dollar-opportunity/
对构建下一代AI基础设施、上下文图谱与智能体编排等技术话题感兴趣?欢迎在云栈社区与更多开发者交流探讨。 |  发表于 2026-1-12 05:34:22
|
查看: 292|
回复: 0
发表于 2026-1-12 05:34:22
|
查看: 292|
回复: 0
