本文将详细介绍如何在 Flask 项目中使用 SQLAlchemy ORM 来操作数据库,涵盖从连接配置、模型定义到在视图函数中具体实现增、删、改、查(CRUD)的全过程。
Flask项目中数据库连接设置
在 Flask-SQLAlchemy 中,数据库的连接信息通过一个 URL 来指定,并且需要保存到 Flask 应用的 SQLALCHEMY_DATABASE_URI 配置项中。
在 manage.py 或主应用文件中进行如下配置:
# SQLAlchemy的链接配置:“数据库驱动://用户名:密码@服务器地址:端口/数据库名称?配置参数”
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 如果不使用mysqlclient驱动而改用pymysql,则需要在连接字符串中指定
# app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123@127.0.0.1:3306/flask-test?charset=utf8mb4"
其他常用的配置项:
# 动态追踪模型的修改,在生产环境中可设置为False以减少开销
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
# 设置为True时,会在控制台打印出SQLAlchemy执行的原始SQL语句,便于调试
app.config["SQLALCHEMY_ECHO"] = True
常用字段类型与列选项
在使用 SQLAlchemy 定义模型时,需要了解其字段类型与Python数据类型的对应关系,以及常用的列约束选项。
常用SQLAlchemy字段类型对照表
| 模型字段类型名 |
Python中数据类型 |
说明 |
| Integer |
int |
普通整数,一般是32位 |
| SmallInteger |
int |
取值范围小的整数,一般是16位 |
| BigInteger |
int |
不限制精度的整数 |
| Float |
float |
浮点数 |
| Numeric |
decimal.Decimal |
定点数,适用于精确计算如金额 |
| String |
str |
变长字符串 |
| Text |
str |
长文本字符串 |
| Boolean |
bool |
布尔值 |
| DateTime |
datetime.datetime |
日期和时间 |
| Date |
datetime.date |
日期 |
| Time |
datetime.time |
时间 |
| Enum |
enum.Enum |
枚举类型 |
常用SQLAlchemy列约束选项
| 选项名 |
说明 |
| primary_key |
如果为True,代表该列是主键 |
| unique |
如果为True,该列创建唯一索引,不允许重复值 |
| index |
如果为True,为该列创建普通索引,提高查询效率 |
| nullable |
如果为True,允许空值;False则不允许 |
| default |
为该列定义默认值 |
数据库基本操作概念
在 SQLAlchemy 中,所有的添加、修改、删除操作都由数据库会话(Session)管理,会话对象通过 db.session 访问。在准备将数据持久化到数据库前,需要先将数据对象添加到会话中,然后调用 db.session.commit() 提交会话。
查询操作则是通过模型类的 query 属性返回的查询对象进行的。最基本的查询是返回表中的所有数据,也可以通过 filter() 或 filter_by() 方法进行更精确的条件过滤。
模型类定义
在实际项目中,我们通常会将模型类定义在单独的模块中。为了方便演示,以下示例将模型类直接写在主应用文件(如 app.py)中。一个清晰的项目结构通常将模型放在独立的 model 层。
完整的应用初始化及模型定义代码如下:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 连接数据库URL
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:Rebort@127.0.0.1:3306/flask-test?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
# 查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 把SQLAlchemy组件注册到项目中
db = SQLAlchemy()
db.init_app(app)
# 创建模型类
class Student(db.Model):
"""学生信息模型"""
# 下面的字段配置相当于执行SQL语句建表
"""
CREATE TABLE tb_student2 (
id INTEGER NOT NULL COMMENT '主键' AUTO_INCREMENT,
name VARCHAR(15) COMMENT '姓名',
age SMALLINT COMMENT '年龄',
sex BOOL COMMENT '性别',
email VARCHAR(128) COMMENT '邮箱地址',
money NUMERIC(10, 2) COMMENT '钱包',
PRIMARY KEY (id),
UNIQUE (email)
)
"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "tb_student2"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(15), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")
def __repr__(self): # 类似于Django的__str__,用于调试和显示
return f"{self.name}<{self.__class__.__name__}>"
class Course(db.Model):
"""课程模型"""
__tablename__ = "tb_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(255), unique=True, comment="课程")
price = db.Column(db.Numeric(8, 2), comment="价格")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class Teacher(db.Model):
"""老师模型"""
__tablename__ = "tb_teacher"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(255), unique=True, comment="姓名")
# 枚举类型
option = db.Column(db.Enum("讲师", "助教", "班主任"), default="讲师")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
if __name__ == '__main__':
# 要想执行创建表,需要调用db.create_all(),db要被调用,需要放到app上下文里面
with app.app_context():
# 检测数据库,如果模型对应的表不存在,则创建
db.create_all()
app.run(debug=True)
运行上述代码后,查看数据库,可以发现相应的数据表已经创建成功。
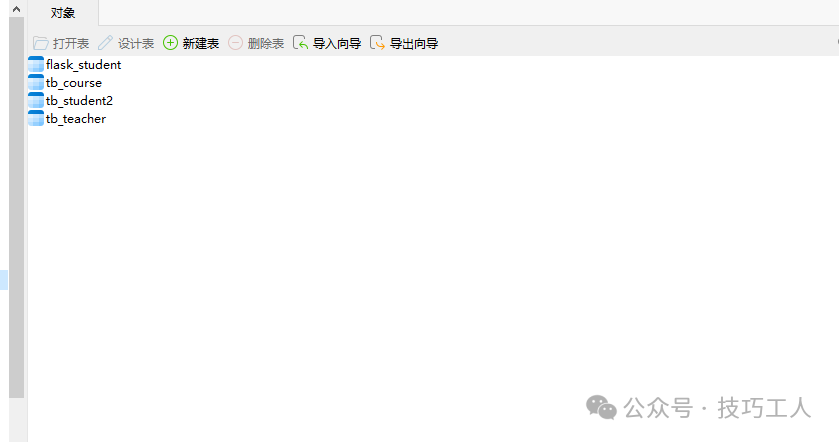
数据表操作
创建和删除表
除了在应用启动时创建表,也可以在视图函数或特定逻辑中控制表的创建与删除。
在视图函数中创建表:
@app.route("/create")
def create_table():
db.create_all() # 为项目中所有已识别的模型创建数据表
return "ok"
在视图函数中删除表(慎用):
@app.route("/drop")
def drop_table():
db.drop_all() # 删除项目中所有模型对应的数据表
return "ok"
在应用上下文外调用(如在脚本中):
with app.app_context():
db.create_all() # 或 db.drop_all()
数据操作(CRUD)
接下来,我们聚焦于核心的数据操作,看看如何在 Flask 视图函数中实现对 数据库 的增删改查。
添加数据
添加一条数据
@app.route("/data")
def data():
"""添加数据"""
# 添加一条数据
student = Student(
name="小明",
age=17,
sex=True,
email="xiaoming@qq.com",
money=30.50
)
db.session.add(student)
db.session.commit()
return "ok"
通过浏览器 GET 请求访问 /data 路径触发添加操作。

操作成功后,可以在数据库表中查看到新增的数据。
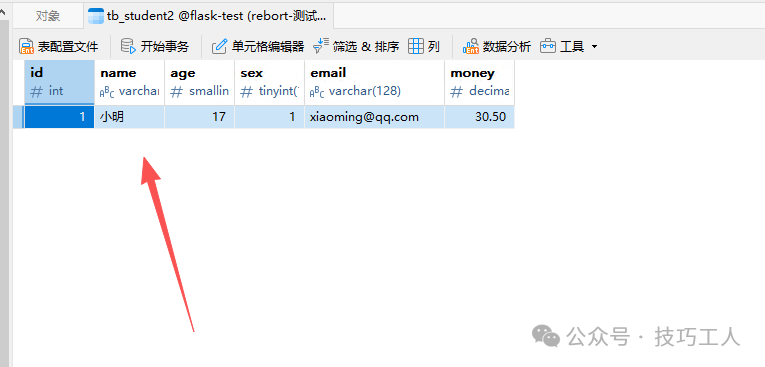
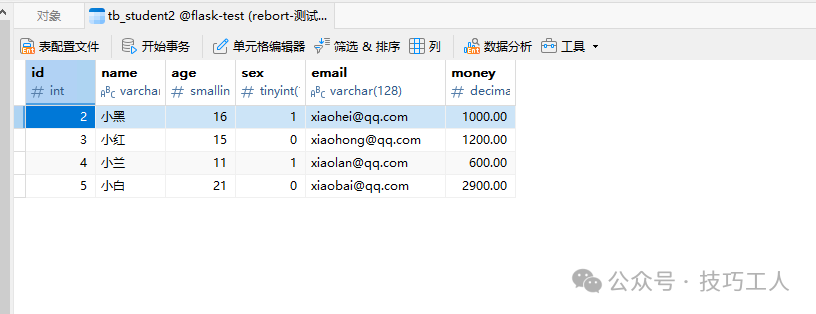
添加多条数据
使用 add_all() 方法可以一次性添加多个模型实例。
@app.route("/data")
def data():
"""添加数据"""
# 添加多条数据
student_list = [
Student(name="小黑", age=16, sex=True, email="xiaohei@qq.com", money=1000),
Student(name="小红", age=15, sex=False, email="xiaohong@qq.com", money=1200),
Student(name="小兰", age=11, sex=True, email="xiaolan@qq.com", money=600),
Student(name="小白", age=21, sex=False, email="xiaobai@qq.com", money=2900),
]
db.session.add_all(student_list)
db.session.commit()
return "ok"
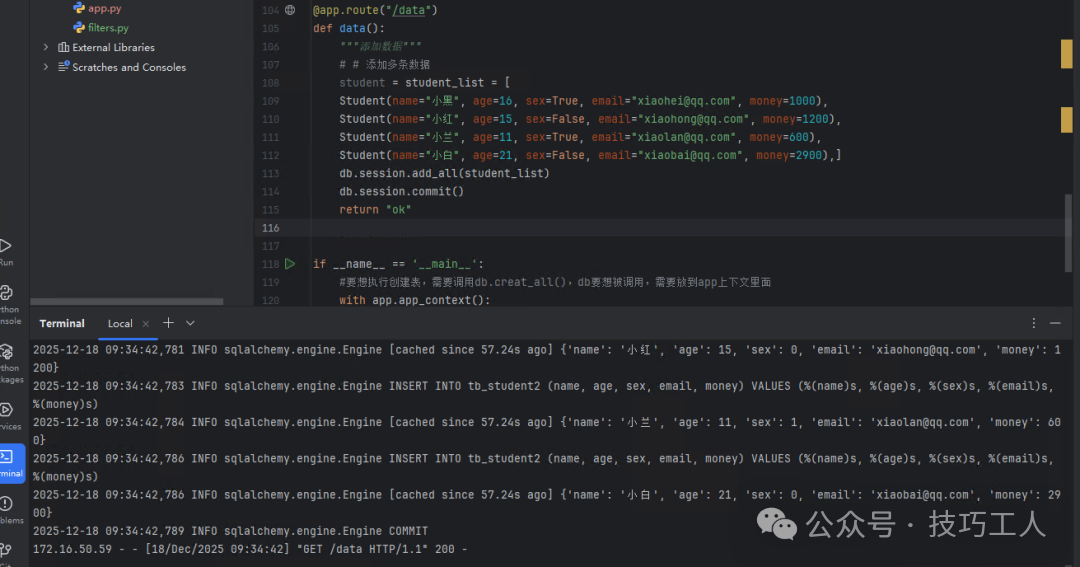
浏览器请求后,查看数据库,确认多条数据已成功插入。
更新操作
更新一条数据
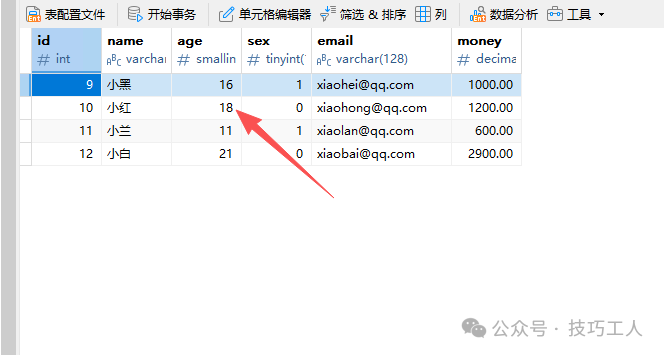
更新数据通常分为三步:查询出要更新的记录、修改其属性、提交会话。
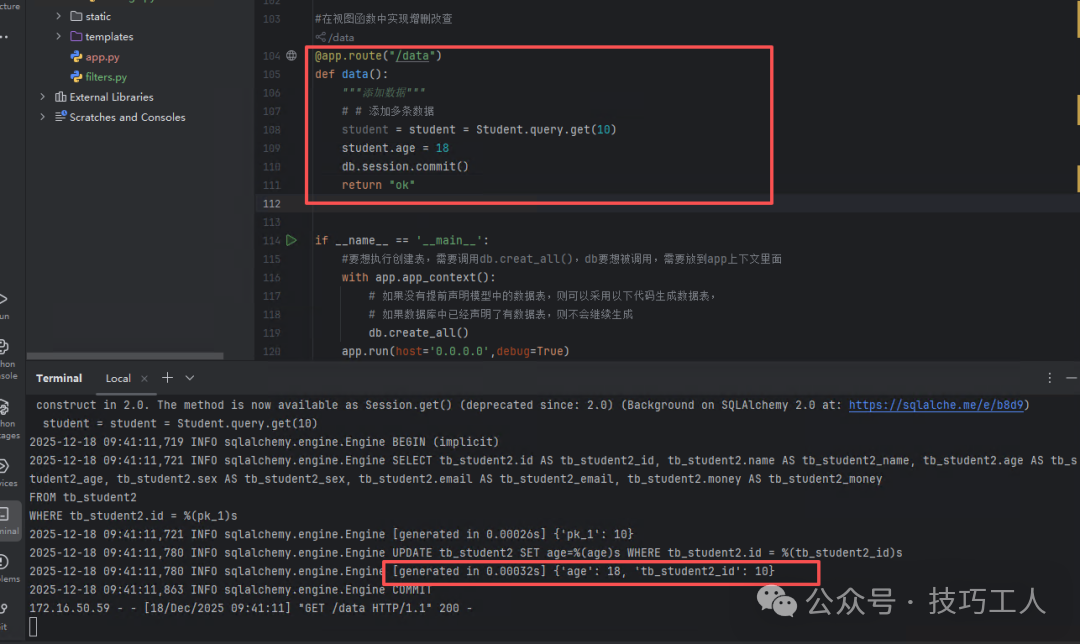
@app.route("/data")
def data():
"""更新数据"""
# 更新一条数据,例如更新id为10的学生年龄
student = Student.query.get(10)
student.age = 18
db.session.commit()
return "ok"
更新前,先查看ID为10的记录的原始数据。
执行更新操作后,查看数据变化及后台SQL日志。
更新多条数据
使用查询对象的 update() 方法可以批量更新符合条件的所有记录。
@app.route("/data")
def data():
"""更新多条数据"""
# 将所有性别为True(男性)的学生的钱包金额设置为年龄的100倍
Student.query.filter(Student.sex == True).update({
Student.money: Student.age * 100,
})
db.session.commit()
return "ok"
在更新前,查看一下原始数据的状态。
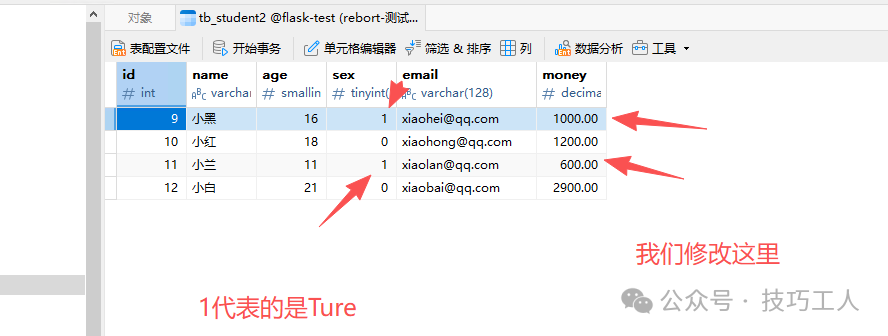
执行更新操作后,可以看到符合条件的记录(sex为True)的money字段已被批量计算更新。
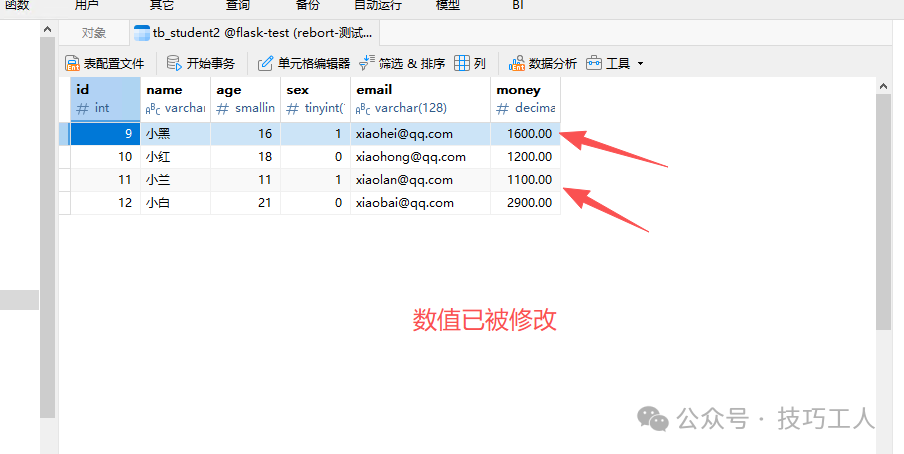
删除操作
删除一条数据
删除数据也需要先查询出目标对象,然后通过 db.session.delete() 进行删除。
@app.route("/data")
def data():
"""删除数据"""
# 删除一条数据,例如删除id为9的学生
student = Student.query.get(9)
db.session.delete(student)
db.session.commit()
return "ok"
删除前,确认一下ID为9的记录存在。
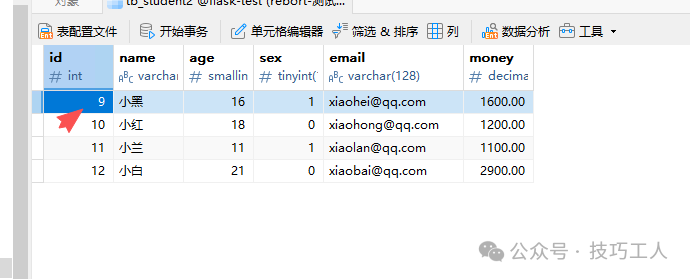
执行删除后,该记录已从表中消失。
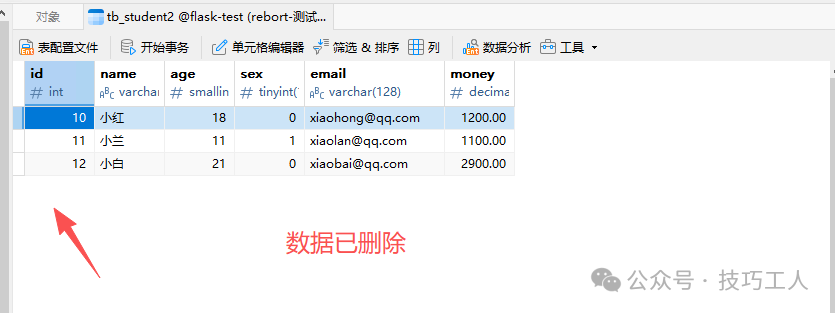
删除多条数据
查询对象的 delete() 方法可以直接删除所有符合条件的记录。
@app.route("/data")
def data():
"""删除数据"""
# 删除所有性别为False(女性)的学生记录
Student.query.filter(Student.sex == False).delete()
db.session.commit()
return "ok"
删除前,查看性别为False的记录。
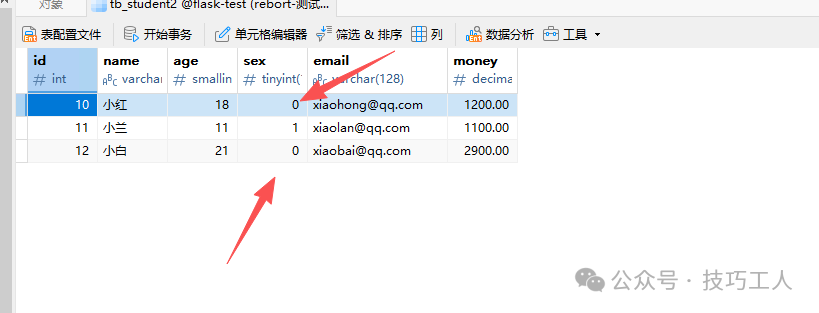
执行删除后,表中只剩下性别为True的记录。
关于数据库锁的简要说明
在高并发场景下操作数据库时,需要考虑资源竞争问题。数据库锁是解决并发控制的一种机制,主要分为悲观锁和乐观锁两种思想。
悲观锁 认为并发冲突很可能发生,因此在操作数据前就先将其锁住。在SQL中通常通过 SELECT ... FOR UPDATE 实现。这种方法保证了一致性,但会形成串行阻塞,影响系统性能。
乐观锁 认为冲突很少发生,它不直接加锁,而是在更新数据时增加一个判断条件(通常是版本号或原始值),检查数据是否已被其他事务修改。如果更新失败(受影响行数为0),则说明发生了冲突,需要进行回滚或重试。乐观锁适用于读多写少的高并发场景,能提供更好的性能。
总结
本文详细讲解了在 Flask 框架中集成 SQLAlchemy ORM 进行数据库开发的完整流程。从环境配置、模型定义,到在视图函数中具体实现数据的增加、查询、更新和删除,每一步都配有清晰的代码示例和效果演示。掌握这些核心操作,是进行 Flask Web应用开发的基础。希望这篇实战指南能帮助你在项目中更高效地处理数据层逻辑。更多深入的技术讨论和资源分享,欢迎关注云栈社区的开发者们。
 发表于 2026-1-12 08:39:00
|
查看: 196|
回复: 0
发表于 2026-1-12 08:39:00
|
查看: 196|
回复: 0
