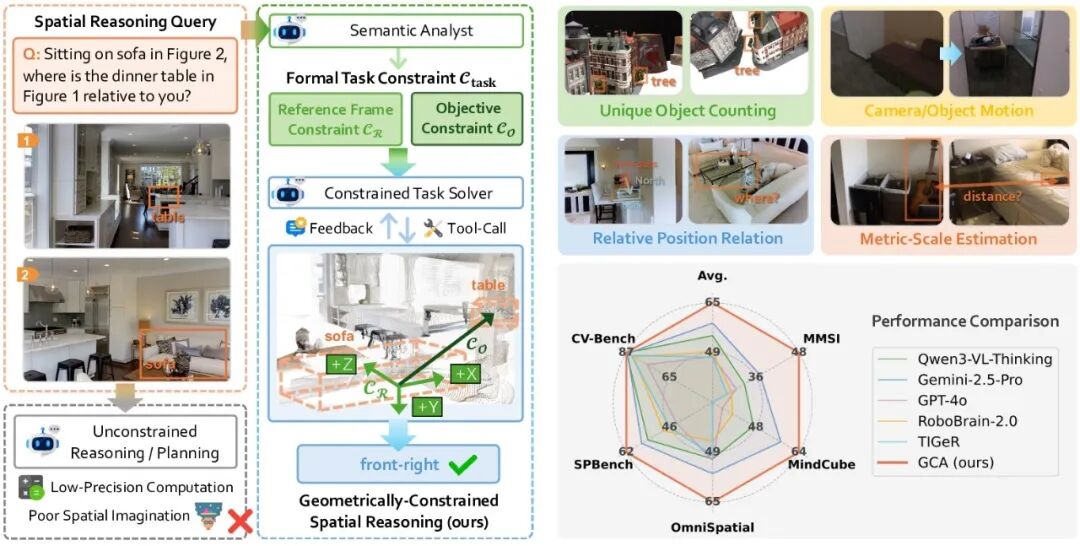
现有的视觉大模型普遍存在一个明显的短板——「语义-几何鸿沟」。这意味着它们不仅难以分清东南西北,更无法处理需要精确空间量化的任务。例如,当被问及“你坐在沙发上时,餐桌在你的哪一侧?”这类问题时,视觉语言模型往往无法给出正确答案。
这种鸿沟的根源在于,VLM将丰富的视觉像素信息压缩为抽象的语义特征时,大量高保真的几何细节(如精确位置、朝向、尺度)丢失了。这导致模型在进行空间推理时,如同在“凭空瞎猜”——它读懂了画面的语义,却停留在“语言的世界”里,缺乏现实世界赖以运行的几何直觉,使得空间判断漏洞百出。

针对这一核心痛点,来自北京航空航天大学与上海人工智能实验室的研究团队提出了一种创新解决方案——几何约束智能体。GCA开创了“先形式化约束,后确定性计算”的空间推理新范式。它不依赖于海量的数据微调,而是通过构建形式化的任务约束,强制VLM从“模糊直觉”转向“精确求解”,并借助视觉工具调用和代码编写进行参数化计算,从而为跨越语义与几何之间的鸿沟搭建了一座可验证、确定性的桥梁。
在实验中,GCA直接引领Qwen、Gemini等基座模型实现了“能力跃迁”。在公认高难度的MMSI-Bench测试中,它将模型性能提升了近50%,击败了现有的基于训练的方法和工具集成方法,并在多个主流空间推理基准测试中确立了新的SOTA。
核心挑战:跨越「语义-几何」的认知鸿沟
视觉语言模型在图像描述与通用语义理解上表现卓越。然而,当任务转向需要高精度几何计算的空间推理时,例如判断物体的精确朝向、测量距离或进行视角变换,其表现便会显著下滑。
研究团队指出,这种能力断层的根源正是「语义-几何鸿沟」。具体表现为:
- 视觉与几何信息的有损压缩:VLM将丰富的像素信息压缩为抽象语义特征的过程,如同将一幅详细地图简化为几个地标名称,导致物体的精确几何细节大量丢失。
- 几何想象的缺失:以“坐在沙发上”这一场景为例,VLM仅能调用模糊的空间常识,却无法在脑海中精确构建出“从沙发视角看去”的三维场景。这种几何想象力的匮乏,使其在面对复杂空间推理时力不从心。
🛠️ 核心方法:基于形式化约束的两阶段推理
为了在“语义”与“几何”之间搭建可靠桥梁,GCA创新性地引入了形式化任务约束,将空间推理精准拆解为两个阶段:
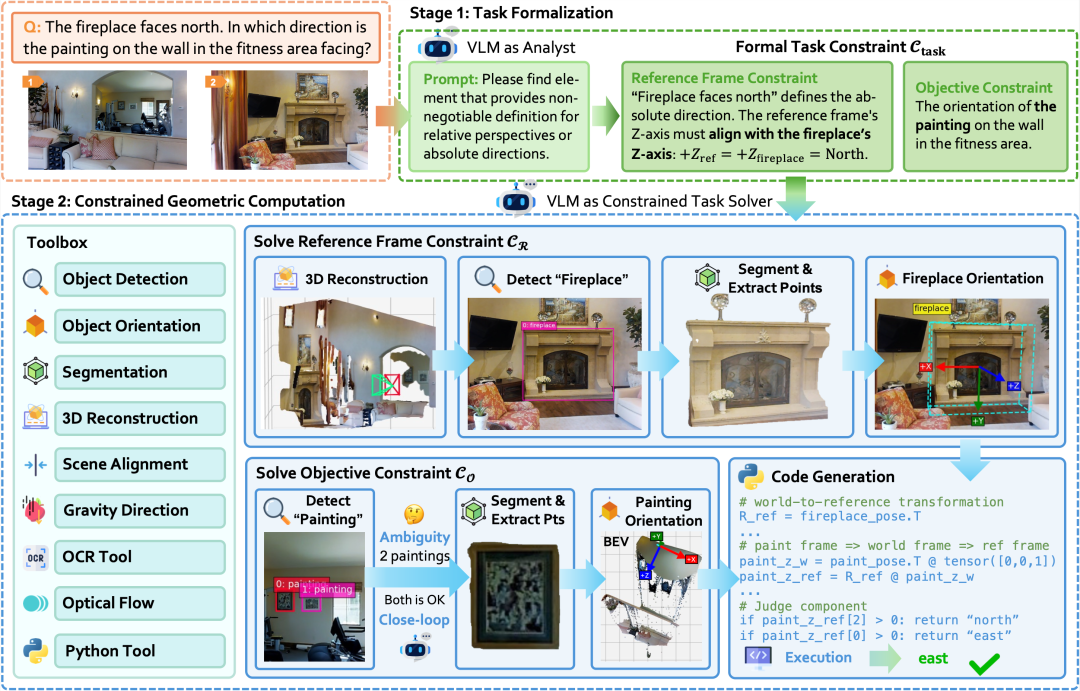
1. 任务形式化 —— 从「模糊指令」到「精确规则」
VLM首先扮演“语义分析师”的角色,利用其强大的语义理解能力,将模糊的自然语言指令转化为明确的数学约束。这一步骤不涉及具体计算,而是确立规则:
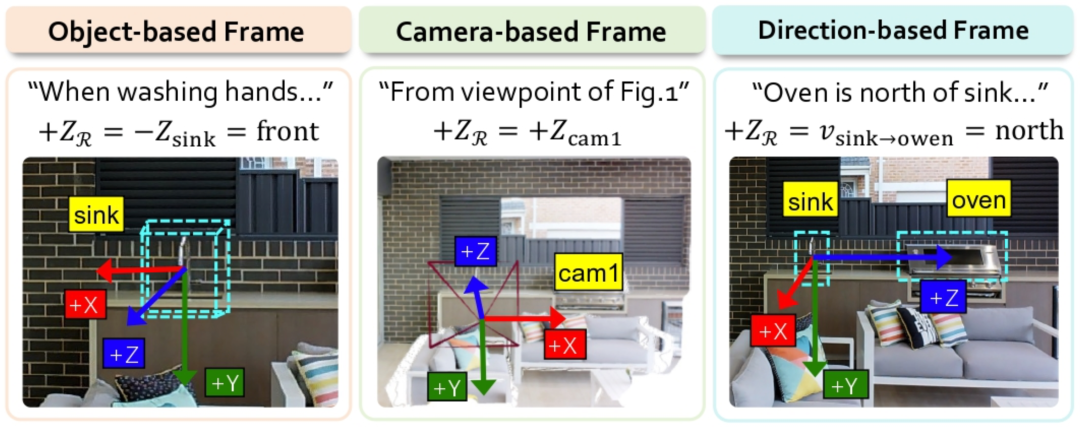
- 参考系约束:明确空间计算的“锚点”。GCA归纳了三种人类常用的核心参考系,模型必须从中指定其一:
- 基于物体的参考系:利用物体自身的坐标系。例如指令“当你在洗手时...”隐含了观察者必须“面对洗手池”,因此参考系由洗手池的朝向决定。
- 基于相机的参考系:即标准的视图坐标系。例如“从图1的视角来看...”,此时参考系直接绑定为相机的坐标系。
- 基于方向的参考系:由两个物体的位置关系定义。例如“烤箱在水槽的北面”,此时“北”的方向由从水槽指向烤箱的向量严格定义。
- 目标约束:明确要解答的“几何问题”本身,例如具体的距离值、角度或方位。
2. 几何计算 —— 在规则内进行「确定性求解」
在确立约束后,VLM转变为“任务求解器”。它不再进行开放式的语义联想,而是严格遵循 C_task 划定的边界,调用3D重建、目标检测、OCR等感知与计算工具,执行确定性的几何计算,在参考系 C_R 下求解目标 C_O。这一阶段的高效实现依赖三个核心设计:
- 智能工具调度与绑定:VLM像指挥官一样,调度感知工具获取数据,并能智能地将“最左边的椅子”等模糊描述,精准绑定到具体的几何对象上,消除语义歧义。
- 感知与计算的无缝衔接:感知工具负责将视觉世界参数化为高保真3D表示,计算工具则负责执行代码、完成坐标转换,二者在统一框架下协同,实现从“看到”到“算准”的闭环。
- 检索增强的可靠计算:采用类似RAG的策略,VLM从一个已验证的几何公式库中检索正确模型来生成代码,从根本上杜绝“幻觉”,确保每项计算都基于可靠的物理原理。这种方法也体现了优秀开源实战项目中工具集成的思路。
实验结果:全新的空间推理SOTA
在MMSI-Bench、MindCube-tiny、OmniSpatial等多个主流空间推理基准上,GCA证明了其有效性,构建了一个全新的空间智能SOTA。
综合性能提升
GCA取得了65.1%的平均准确率,显著超越了现有基于训练的方法与工具集成的方法。特别是在极具挑战性的多图空间推理基准MMSI-Bench中,面对复杂的视角变换与相对方位推断,现有主流模型往往只能徘徊在25%~30%左右的“随机猜测”水平线。
而基于Qwen3-VL-Thinking构建的GCA,准确率从32.6%跃升至47.6%。这一数据证明,GCA成功让VLM摆脱了“蒙答案”的困境,向具备可靠的空间推理能力迈出了关键一步。
强大的通用性
GCA并非特定模型的“专属补丁”,而是一种无需训练的通用推理范式,可直接赋能各类基座模型。
实验显示,在搭载GCA架构后,受测模型在MMSI-Bench上的性能平均实现了约37%的相对提升。其中,基于Gemini-2.5-Pro构建的GCA表现尤为惊艳,其准确率从36.9%飞跃至55.0%,有效地激发了顶级模型的空间推理潜力。
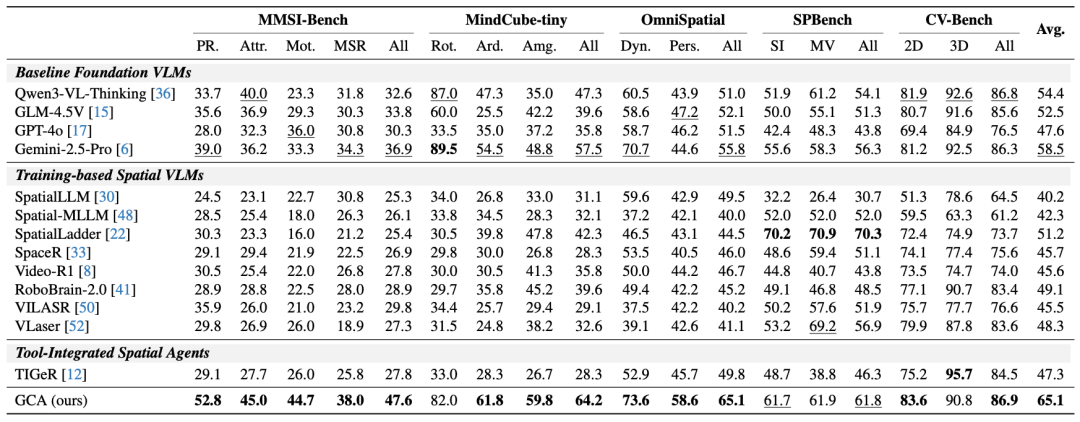
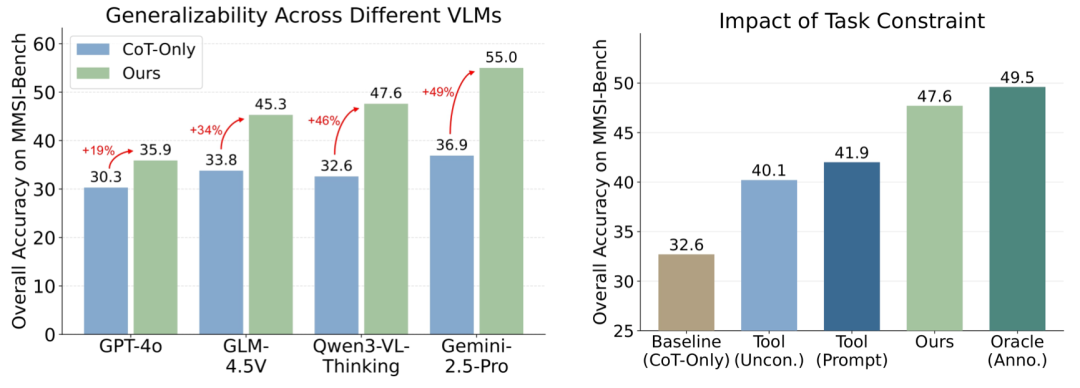
通过系统的消融实验与归因分析,研究进一步证实了GCA架构的前瞻性:
- 形式化约束至关重要:对比实验表明,若仅为VLM提供工具而不施加形式化约束,其性能提升微乎其微。这证明,缺乏 C_task 的引导,VLM无法做出正确的几何规划;正是“先约束”的范式,真正释放了工具的潜力。
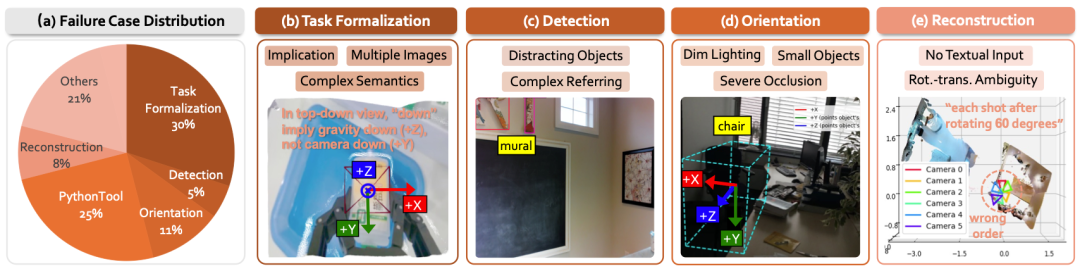
- 可解释的错误归因:得益于GCA架构的模块化设计,研究团队能够对推理链路进行精确的错误归因。分析显示,VLM在“任务形式化”阶段的准确率已高达约70%,当前主要错误来源于下游感知工具。这表明,GCA的推理逻辑是稳健的,其性能将随着感知模型的进步而持续提升。
总结与意义
GCA提出了一种“语言定义约束,几何执行计算”的新范式。通过将模糊的空间查询转化为带约束的数学问题,GCA有效避免了VLM在有损语义空间中进行不可靠的空间想象。这不仅大幅提升了推理的准确性,也让机器向拥有“几何直觉”迈出了关键一步,回应了攀登“空间智能”高峰的核心挑战。
这项研究为如何增强AI对物理世界的理解提供了新的思路,值得所有对人工智能前沿进展感兴趣的研究者和开发者在云栈社区深入探讨。
 发表于 2026-1-13 01:17:27
|
查看: 290|
回复: 0
发表于 2026-1-13 01:17:27
|
查看: 290|
回复: 0
