引言:为什么需要理解Linux文件系统核心机制?
在计算科学领域,Linux文件系统被公认为操作系统设计的典范。Linux创始人Linus Torvalds提出的“一切皆文件”哲学,不仅简化了系统接口,更提供了无与伦比的灵活性。作为Linux系统的基石,深入理解其文件操作机制对于系统开发者、运维工程师乃至追求高性能的应用开发人员都至关重要。
本文将带领你深入探索Linux文件操作的内部世界,从用户空间的应用程序出发,穿越系统调用接口的边界,剖析内核中复杂的虚拟文件系统数据结构,最终抵达物理存储介质。通过这场深度之旅,你将获得对Linux文件系统设计哲学的深刻洞察与实战调优能力。
第一部分:Linux文件操作全景视图
1.1 宏观架构:层次化设计之美
Linux文件操作采用经典的分层架构,这种设计思想清晰地将不同职责模块化:
用户应用程序 → 系统调用接口 → VFS层 → 具体文件系统 → 块设备层 → 物理存储
可以将其类比为一个高效的邮政系统:应用程序是寄件人,系统调用是邮筒,VFS是中央分拣中心,具体文件系统是地方邮局,块设备层是邮递员,而物理存储则是最终的收件信箱。每一层只需了解相邻层的接口,这种低耦合设计带来了强大的可扩展性。
1.2 核心设计哲学
Linux文件系统设计体现了几个历经时间考验的关键原则:
- 一切皆文件:不仅是普通文本或二进制文件,包括设备、管道、套接字甚至进程信息都被抽象为文件对象,通过统一的文件描述符进行访问。
- 统一的接口:无论是操作磁盘文件还是网络套接字,都使用同一套API(
open、read、write、close等),极大降低了学习与使用成本。
- 层次化命名空间:树状的目录结构提供了一种直观、高效的组织与定位资源的方式。
- 权限分离:基于用户(user)、组(group)和其他(others)三个维度的精细权限控制(rwx),构成了系统安全的重要屏障。
第二部分:虚拟文件系统(VFS)—— Linux的文件抽象中枢
2.1 VFS的作用与意义
VFS是Linux内核中一个强大的抽象层,它如同一个万能适配器,允许诸如ext4、XFS、NTFS、FAT32等截然不同的具体文件系统,以完全统一的方式呈现给上层的用户和应用程序。这意味着开发者编写文件操作代码时,几乎无需关心底层存储格式的差异,这种设计极大地增强了系统的兼容性与可移植性。
2.2 VFS核心数据结构
理解VFS的关键在于掌握其四大核心数据结构,它们共同构成了Linux文件系统的内存骨架。以下是从内核源码 include/linux/fs.h 中提炼出的简化定义:
/* 超级块结构:代表一个已挂载的文件系统实例 */
struct super_block {
struct list_head s_list; /* 超级块链表 */
dev_t s_dev; /* 设备标识符 */
unsigned long s_blocksize; /* 块大小 */
struct file_system_type *s_type; /* 文件系统类型 */
struct super_operations *s_op; /* 超级块操作函数集 */
struct dentry *s_root; /* 根目录的dentry */
struct list_head s_inodes; /* 所有inode的链表 */
// ... 其他成员
};
/* inode结构:文件或目录的元数据(metadata) */
struct inode {
umode_t i_mode; /* 文件类型和权限 */
uid_t i_uid; /* 所有者UID */
gid_t i_gid; /* 组GID */
loff_t i_size; /* 文件大小 */
struct timespec64 i_atime; /* 最后访问时间 */
struct timespec64 i_mtime; /* 最后修改时间 */
struct timespec64 i_ctime; /* 最后状态改变时间 */
const struct inode_operations *i_op; /* inode操作函数集 */
struct super_block *i_sb; /* 所属超级块 */
struct address_space *i_mapping; /* 地址空间(用于页缓存) */
// ... 其他成员
};
/* dentry结构:目录项,建立文件名到inode的链接 */
struct dentry {
struct dentry *d_parent; /* 父目录dentry */
struct qstr d_name; /* 文件名 */
struct inode *d_inode; /* 关联的inode */
struct list_head d_child; /* 兄弟节点链表 */
struct list_head d_subdirs; /* 子节点链表 */
struct dentry_operations *d_op; /* dentry操作函数集 */
// ... 其他成员
};
/* file结构:已打开文件的上下文信息 */
struct file {
struct path f_path; /* 文件路径(含dentry和挂载点) */
struct inode *f_inode; /* 关联的inode */
const struct file_operations *f_op; /* 文件操作函数指针 */
loff_t f_pos; /* 当前读写位置(偏移量) */
atomic_long_t f_count; /* 引用计数 */
fmode_t f_mode; /* 文件模式(读/写) */
unsigned int f_flags; /* 打开时的标志(如O_RDONLY) */
// ... 其他成员
};
2.3 数据结构关系图解
这些核心数据结构并非孤立存在,下图清晰地展示了进程、VFS抽象层与具体文件系统实现之间的关系:
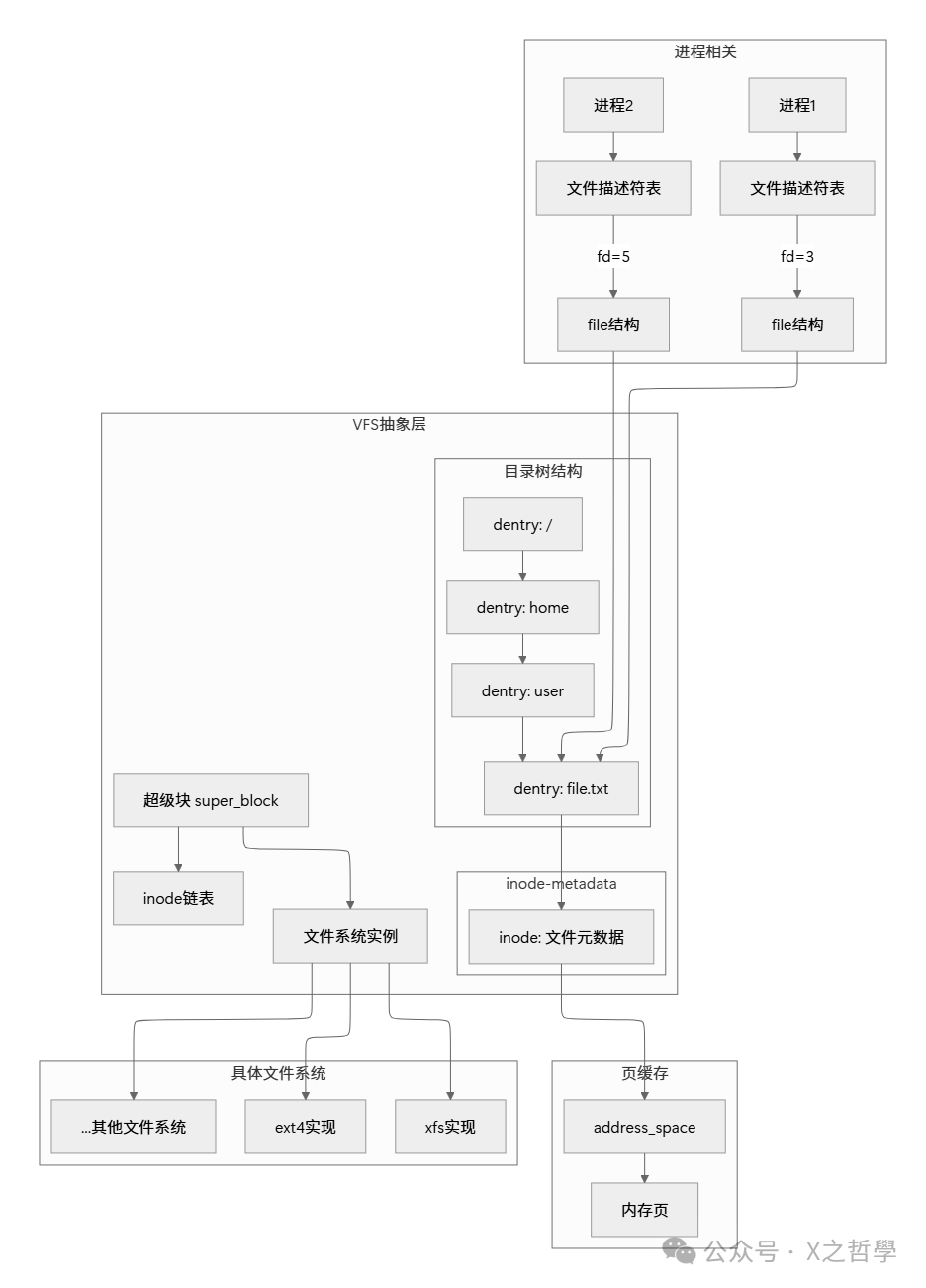
2.4 VFS工作流程示例:打开一个文件
当应用程序执行 open("/home/user/file.txt", O_RDONLY) 时,VFS内部经历了一场精密的协作:
- 路径解析:将绝对路径 “/home/user/file.txt” 分解为分量:["home", "user", "file.txt"]。
- 目录查找:从当前进程的当前目录或根目录(
/)开始,逐级查找每个分量对应的dentry。这个过程会利用目录项缓存(dentry cache)来加速。
- inode获取:找到最终文件 “file.txt” 的dentry后,通过
d_inode 指针获取其关联的inode结构。
- 权限检查:根据inode中的
i_mode(权限位)和进程的有效用户ID/组ID,检查当前进程是否有权限以只读方式访问该文件。
- file结构创建:创建一个新的
file 结构体,将其 f_inode 指向刚找到的inode,并初始化 f_pos(位置指针为0)、f_mode(只读模式)等字段。
- 文件描述符分配:在当前进程的文件描述符表中找到一个空闲的槽位,将
file 结构的指针存入,并返回该槽位的索引(一个非负整数)作为文件描述符(fd)给用户程序。
整个过程需要处理符号链接解析、挂载点跨越、权限验证等多种复杂情况,而VFS通过统一且强大的接口,将这些细节完美地隐藏了起来。
第三部分:文件描述符与打开文件表
3.1 文件描述符的本质
文件描述符是UNIX/Linux系统的核心概念之一,它是一个非负整数,代表进程内对一个已打开文件的引用。你可以将其想象成图书馆的索书号:你无需知道某本书具体存放在哪个房间、哪个书架,只需提供正确的索书号,管理员就能帮你找到它。文件描述符就是这个“索书号”,它是对内核中复杂文件对象的轻量级句柄。
3.2 三级表结构
Linux使用清晰的三级表结构来管理所有打开的文件,这保证了资源的有效共享与隔离:

- 进程级文件描述符表:每个进程私有,存储指向“系统级打开文件表”中某个条目的指针。
fd 就是这个表的索引。
- 系统级打开文件表:全局共享,每个条目是一个
file 结构,包含了文件打开模式(读/写)、当前文件偏移量 (f_pos) 和引用计数 (f_count) 等。
- inode表:全局共享,每个活动文件或目录对应一个
inode 结构,存储文件的元数据(如所有者、大小、时间戳)和指向实际数据块的指针。
当两个进程打开同一个文件时,它们会有各自独立的文件描述符和 file 结构(因此可以有独立的文件偏移量),但最终指向同一个 inode。
3.3 文件描述符表的实现
每个进程的 task_struct(进程控制块)中都有一个 files 成员,指向一个 files_struct 结构:
struct files_struct {
atomic_t count; /* 引用计数 */
struct fdtable __rcu *fdt; /* 可扩展的文件描述符表 */
struct file __rcu * fd_array[NR_OPEN_DEFAULT]; /* 默认的文件指针数组 */
// ...
};
struct fdtable {
unsigned int max_fds; /* 当前表的最大容量 */
struct file __rcu **fd; /* 文件指针数组 */
// ...
};
当进程调用 open() 成功时,内核会:1. 在 fdtable 中查找最小的空闲索引位置;2. 创建并初始化对应的 file 结构;3. 将 file 指针存入 fdtable->fd 数组的该索引处;4. 将此索引作为文件描述符值返回给用户空间。
第四部分:页缓存(Page Cache)—— 性能加速的关键引擎
4.1 页缓存的设计思想
页缓存是Linux文件系统性能优化的核心机制,其基本思想根植于计算机科学的两个经典局部性原理:
- 时间局部性:最近被访问过的数据,在未来短时间内很可能再次被访问。
- 空间局部性:访问某个存储位置的数据时,其邻近位置的数据也很可能很快被访问。
页缓存通过将磁盘数据缓存在物理内存中,将缓慢的磁盘I/O转化为快速的内存访问,从而极大提升系统整体I/O性能。
4.2 页缓存的数据结构
页缓存的核心是 address_space 结构,它充当了inode和内存页(page)之间的桥梁:
struct address_space {
struct inode *host; /* 所属的inode */
struct radix_tree_root page_tree; /* 基数树,用于快速查找缓存页 */
spinlock_t tree_lock; /* 保护基数树的锁 */
unsigned long nrpages; /* 当前缓存的页总数 */
const struct address_space_operations *a_ops; /* 地址空间操作 */
// ...
};
每个打开的文件(inode)通过 i_mapping 关联一个 address_space,其中 page_tree 这个基数树结构可以高效地根据文件偏移量找到对应的缓存内存页。
4.3 页缓存工作流程
一次文件读取请求在页缓存层面的旅程,可以通过下面的序列图来理解:
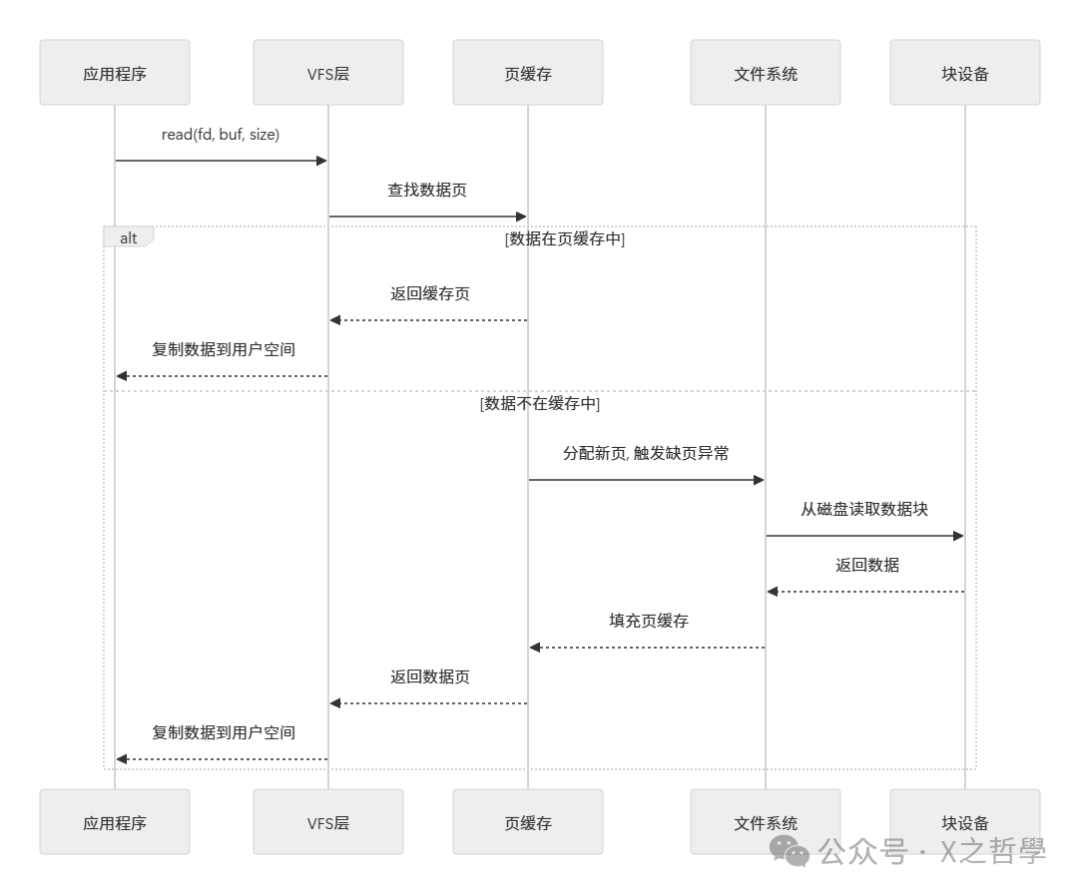
当 read() 调用发生时:1. VFS层首先检查请求的数据页是否已在页缓存中;2. 若在(缓存命中),则直接将该内存页的数据复制到用户缓冲区;3. 若不在(缓存未命中),则内核需要分配新的内存页,触发“缺页异常”,由具体文件系统向块设备发起读请求,将数据从磁盘载入新页,然后将其加入页缓存,最后再复制数据到用户空间。
4.4 页缓存替换策略
Linux采用一种改进的双列表LRU算法来管理庞大的页缓存,平衡性能与内存利用率:
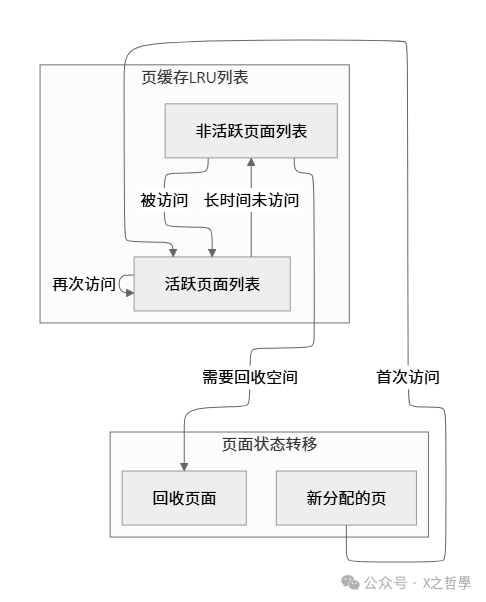
内存页被分为两个列表:活跃列表和非活跃列表。新缓存页或刚被访问的页会进入活跃列表头部。随着时间推移,活跃列表中长时间未被访问的页会被移动到非活跃列表。当系统内存紧张,需要回收页面时,内核优先从非活跃列表的尾部开始回收。这种策略能有效保护正在被频繁访问的“热”数据。
第五部分:具体文件系统实现剖析
5.1 ext4文件系统深入分析
ext4作为目前Linux发行版最主流的文件系统,在ext3的基础上引入了多项关键优化。
5.1.1 ext4磁盘布局
ext4将存储空间划分为多个“块组”,每个块组结构相似,旨在减少磁头寻道距离:
+----------------------------------------------------------------+
| 引导块 | 超级块 | 块组描述符表 | 数据块位图 | inode位图 | inode表 | 数据块 |
+----------------------------------------------------------------+
这种布局使得元数据(位图、inode表)与对应的数据块尽可能靠近。
5.1.2 ext4核心特性
| 特性 |
描述 |
优势 |
| Extents |
用连续块的区间(起始块+长度)取代传统的间接块映射。 |
大幅减少大文件的元数据开销,提升顺序读写性能。 |
| 延迟分配 |
推迟实际磁盘块的分配,直到数据即将写回磁盘的时刻。 |
允许内核在更了解最终数据大小的前提下做更好的分配决策,减少碎片。 |
| 多块分配 |
一次性分配多个连续的磁盘块。 |
进一步减少碎片,提升写入吞吐量。 |
| 日志校验和 |
为日志记录添加校验和。 |
提高文件系统崩溃后日志恢复的可靠性。 |
| 快速fsck |
通过记录未初始化的块组等信息,极大缩短文件系统检查时间。 |
系统启动更快。 |
5.1.3 ext4数据结构示例
/* ext4超级块结构(磁盘格式,简化版) */
struct ext4_super_block {
__le32 s_inodes_count; /* inode总数 */
__le32 s_blocks_count; /* 块总数 */
__le32 s_r_blocks_count; /* 保留给超级用户的块数 */
__le32 s_free_blocks_count; /* 空闲块数 */
__le32 s_free_inodes_count; /* 空闲inode数 */
__le32 s_first_data_block; /* 第一个数据块(通常为1或0) */
__le32 s_log_block_size; /* 块大小 = 1024 << s_log_block_size */
__le32 s_blocks_per_group; /* 每个块组的块数 */
__le32 s_inodes_per_group; /* 每个块组的inode数 */
__le32 s_mtime; /* 最后一次挂载时间 */
__le32 s_wtime; /* 最后一次写入时间 */
__le16 s_mnt_count; /* 挂载次数 */
__le16 s_max_mnt_count; /* 最大挂载次数(触发fsck检查) */
// ... 其他许多字段
};
5.2 不同文件系统对比
| 特性 |
ext4 |
XFS |
Btrfs |
ZFS |
| 最大文件大小 |
16 TiB |
8 EiB |
16 EiB |
16 EiB |
| 最大卷大小 |
1 EiB |
8 EiB |
16 EiB |
16 EiB |
| 日志 |
有 |
有 |
有(支持多种模式) |
有(ZIL) |
| 写时复制 |
无 |
部分(元数据) |
有 |
有 |
| 快照 |
无(实验性) |
有 |
有 |
有 |
| 压缩 |
有(透明压缩) |
有 |
有 |
有 |
| 数据去重 |
无 |
无 |
有 |
有 |
| 数据校验 |
部分(元数据) |
有 |
有 |
有(端到端) |
| 成熟度/稳定性 |
非常高(默认选择) |
高(企业级) |
中等(特性丰富) |
高(企业级) |
第六部分:系统调用实现机制
6.1 从用户空间到内核空间
系统调用是用户程序与内核交互的唯一合法桥梁。以 read() 为例,我们看看它是如何穿越边界的:
/* 用户空间可见的C库接口 */
ssize_t read(int fd, void *buf, size_t count);
/* 内核中的实现(极度简化版) */
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd); /* 通过fd获取对应的file结构 */
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file); /* 获取当前文件偏移 */
ret = vfs_read(f.file, buf, count, &pos); /* 核心:调用VFS通用读函数 */
if (ret >= 0)
file_pos_write(f.file, pos); /* 更新文件偏移 */
fdput_pos(f);
}
return ret;
}
6.2 系统调用执行流程
一次 read 系统调用的完整旅程,涉及从用户态到内核态的切换及层层传递:
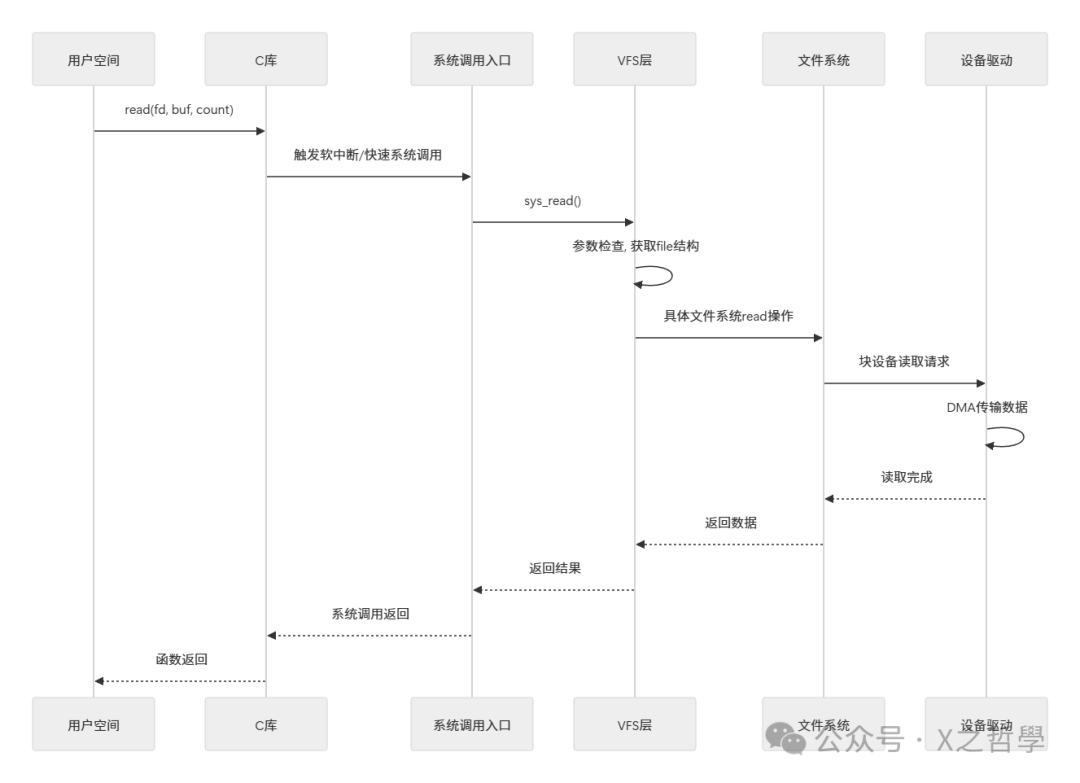
第七部分:实战应用、调试与性能优化
7.1 文件操作性能分析工具集
| 工具 |
主要用途 |
示例命令 |
| strace |
跟踪进程执行的系统调用。 |
strace -e trace=file,desc ls -l |
| ltrace |
跟踪进程调用的库函数。 |
ltrace ls -l |
| perf |
强大的系统性能分析工具。 |
perf record -ag -- sleep 5; perf report |
| iostat |
监控系统I/O设备负载。 |
iostat -xdm 1 |
| vmstat |
报告虚拟内存、进程、CPU、I/O状态。 |
vmstat 1 |
| blktrace |
深入跟踪块设备I/O请求。 |
blktrace -d /dev/sda -o trace |
| fatrace |
实时报告文件访问事件。 |
fatrace |
7.2 文件系统调试技巧
7.2.1 使用debugfs检查ext4文件系统
# 查看文件系统总体统计信息
debugfs -R "stats" /dev/sda1
# 查看特定inode的详细信息(如根目录通常是2)
debugfs -R "stat <2>" /dev/sda1
# 列出已被删除但inode尚未被回收的文件(数据可能还在)
debugfs -R "lsdel" /dev/sda1
# 进入写模式,尝试恢复(需谨慎!)
debugfs -w /dev/sda1
debugfs: undel <inode_number>
7.2.2 内核调试技巧
// 在内核模块或文件系统代码中插入动态调试信息
pr_debug("VFS: %s reading from inode %lu, pos=%lld\n",
current->comm, inode->i_ino, pos);
// 动态启用/关闭内核中的调试信息(需配置CONFIG_DYNAMIC_DEBUG)
echo "file fs/ext4/* +p" > /sys/kernel/debug/dynamic_debug/control
7.3 性能优化实践
-
选择合适的I/O调度器
# 查看块设备支持的调度器
cat /sys/block/sda/queue/scheduler
# 设置为deadline(对数据库类随机I/O友好)
echo deadline > /sys/block/sda/queue/scheduler
# 设置为none(常用于虚拟机或高速SSD,让设备自身处理)
echo none > /sys/block/sda/queue/scheduler
-
调整页缓存与内存参数
# 增加脏页(待写回磁盘的数据)占总内存的百分比阈值
echo 20 > /proc/sys/vm/dirty_ratio
# 降低内存交换的倾向性,尽可能将数据保留在内存
echo 10 > /proc/sys/vm/swappiness
-
文件系统挂载优化
# 针对SSD的ext4挂载优化选项
# noatime/nodiratime: 减少读操作时的元数据更新
# discard: 启用TRIM,帮助SSD回收空间
mount -o noatime,nodiratime,discard /dev/sda1 /mnt/data
第八部分:动手实践:实现一个简单的内存文件系统
8.1 最简单的内存文件系统框架
以下是一个高度简化的内存文件系统(simplefs)的内核模块框架,它展示了注册一个文件系统所需的最基本结构:
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/slab.h>
#define SIMPLEFS_MAGIC 0x13131313
#define SIMPLEFS_BLOCK_SIZE 4096
#define SIMPLEFS_FILENAME_MAXLEN 255
/* 简单文件系统的内存inode */
struct simplefs_inode {
umode_t mode;
uint64_t ino;
uint64_t data_block;
uint64_t file_size;
};
/* 简单文件系统的超级块信息 */
struct simplefs_sb_info {
uint64_t magic;
uint64_t block_size;
uint64_t inodes_count;
uint64_t free_blocks;
unsigned long *free_blocks_bitmap;
};
/* 定义文件系统操作函数集(需实现) */
static const struct super_operations simplefs_super_ops = {
.statfs = simplefs_statfs,
.evict_inode = simplefs_evict_inode,
};
static const struct inode_operations simplefs_inode_ops = {
.create = simplefs_create,
.lookup = simplefs_lookup,
.mkdir = simplefs_mkdir,
};
static const struct file_operations simplefs_file_ops = {
.read_iter = generic_file_read_iter,
.write_iter = generic_file_write_iter,
.mmap = generic_file_mmap,
.open = generic_file_open,
.release = simplefs_release,
};
/* 挂载函数 */
static struct dentry *simplefs_mount(struct file_system_type *fs_type,
int flags, const char *dev_name,
void *data)
{
struct dentry *dentry = mount_bdev(fs_type, flags, dev_name,
data, simplefs_fill_super);
if (IS_ERR(dentry))
pr_err("Failed to mount simplefs\n");
else
pr_info("simplefs mounted successfully\n");
return dentry;
}
/* 定义文件系统类型 */
static struct file_system_type simplefs_fs_type = {
.owner = THIS_MODULE,
.name = "simplefs",
.mount = simplefs_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
/* 模块初始化 */
static int __init simplefs_init(void)
{
int ret = register_filesystem(&simplefs_fs_type);
if (ret == 0)
pr_info("simplefs module loaded\n");
else
pr_err("Failed to register simplefs\n");
return ret;
}
/* 模块退出 */
static void __exit simplefs_exit(void)
{
int ret = unregister_filesystem(&simplefs_fs_type);
if (ret == 0)
pr_info("simplefs module unloaded\n");
else
pr_err("Failed to unregister simplefs\n");
}
module_init(simplefs_init);
module_exit(simplefs_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Linux File System Explorer");
MODULE_DESCRIPTION("A simple example filesystem for learning");
8.2 示例文件系统架构图
这个简单的教学文件系统同样遵循标准的分层架构:
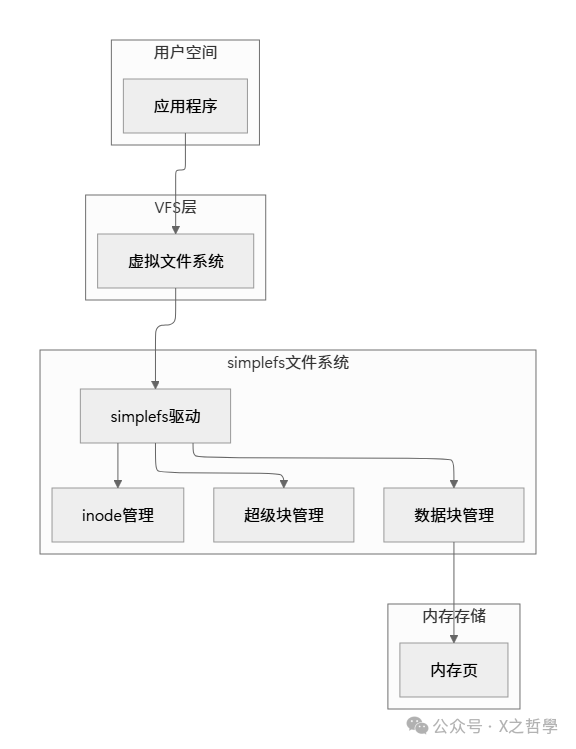
第九部分:总结与最佳实践
9.1 Linux文件操作核心要点回顾
通过对Linux文件系统机制的层层剖析,我们可以总结出以下核心设计精髓:
- 抽象与统一:VFS作为强大的抽象层,完美统一了五花八门的底层文件系统接口。
- 一切皆文件:这一哲学理念极大简化了系统I/O模型,使设备、管道、套接字等都能通过文件接口访问。
- 缓存为王:智能的页缓存机制,基于局部性原理,将性能提升了一个数量级。
- 异步与并发:从内核的异步I/O到用户态的
epoll/io_uring,现代Linux提供了丰富的机制来支持高并发、低延迟的I/O操作。
- 可扩展性:模块化的设计使得添加一个新的文件系统驱动程序变得相对直接。
9.2 性能优化建议速查表
| 应用场景 |
优化建议 |
预期效果 |
| 大量小文件读写 |
使用 tmpfs 内存文件系统;调整 vm.vfs_cache_pressure。 |
减少磁盘元数据操作开销,极致提速。 |
| 大文件顺序读写 |
增大预读参数 (/sys/block/sda/queue/read_ahead_kb);考虑使用 O_DIRECT。 |
最大化磁盘顺序吞吐量。 |
| 随机I/O访问(如数据库) |
使用 deadline 或 noop I/O调度器;确保使用SSD。 |
降低I/O延迟,提高响应速度。 |
| 高并发网络服务 |
提高进程文件描述符限制 (ulimit -n);采用异步I/O框架 (io_uring)。 |
提升服务并发连接与处理能力。 |
| 内存紧张的系统 |
适当降低 vm.swappiness;监控并调整脏页回写参数 (vm.dirty_*)。 |
平衡内存使用,避免因频繁交换导致的性能抖动。 |
9.3 故障排查流程图
当遇到文件操作相关问题时,可以遵循以下逻辑进行排查:
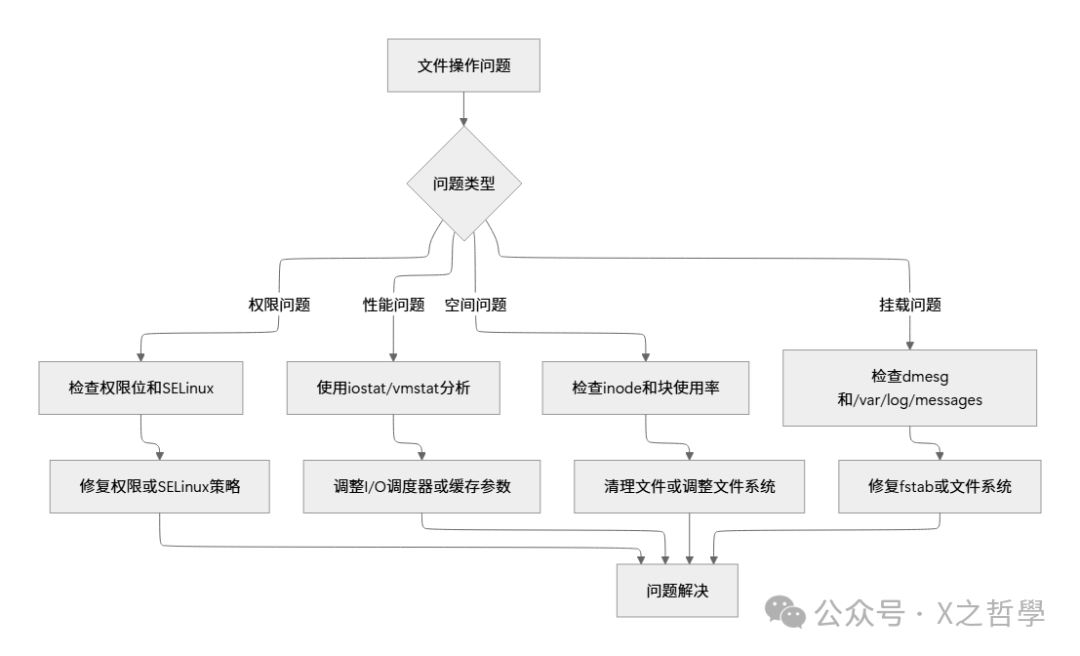
希望这篇深度剖析能帮助你建立起对Linux文件系统内部机制的清晰认知。无论是进行底层系统开发、性能调优,还是仅仅为了满足技术好奇心,理解这些核心机制都将使你受益匪浅。探索不止,欢迎在云栈社区继续交流与分享你的实践经验。
 发表于 2026-1-13 02:19:31
|
查看: 186|
回复: 0
发表于 2026-1-13 02:19:31
|
查看: 186|
回复: 0
