1. 文件系统全景: 从用户视角到磁盘结构
1.1 一切皆文件的哲学
在 Linux 中,所有资源都被视为文件。无论是普通文本文件、目录,还是硬件设备、进程间通信管道,甚至是网络连接,都通过统一的文件接口进行访问。
这种设计哲学极大地简化了系统架构,使得对各类资源的操作可以通过相同的系统调用来完成。当你访问 /dev/sda 时,实际上是在与磁盘设备交互;当你向 /proc/1/status 写入时,实际上是在与进程1通信。这种抽象是理解 操作系统 设计理念的基石。
1.2 文件系统层次架构
Linux 文件系统的设计采用了经典的分层架构,从用户空间到物理磁盘,每一层都有明确的职责和抽象:
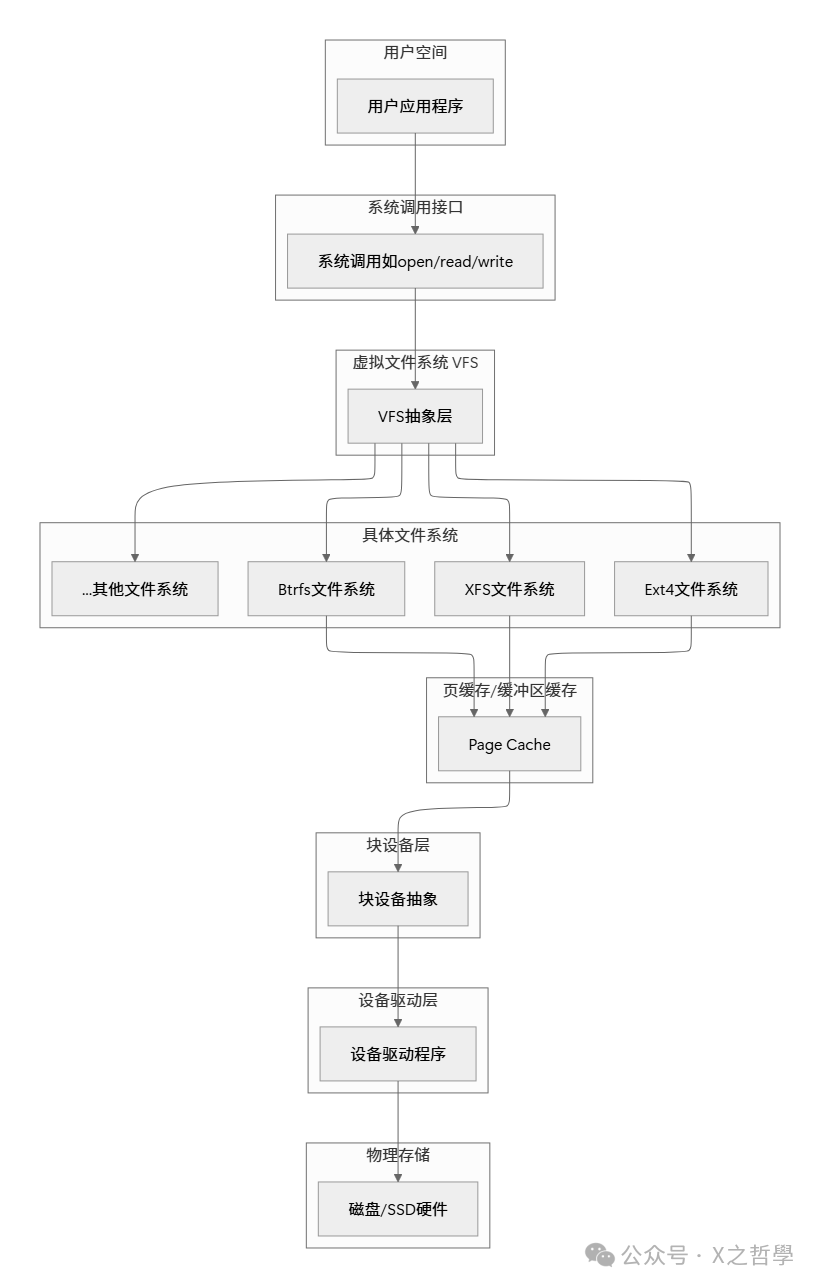
这个分层架构的关键在于虚拟文件系统(VFS)层,它为上层提供了统一的文件操作接口,同时允许下层各种具体文件系统以插件方式存在。
2. 虚拟文件系统: Linux的统一文件接口
2.1 VFS的设计思想
想象一下图书馆的管理系统:无论图书是中文版还是英文版,平装本还是精装本,读者都可以通过相同的查询系统找到它们。VFS 正是这样的统一查询系统,它抽象了不同文件系统的差异,为用户空间提供一致的API。
VFS 的核心是面向对象的设计思想,尽管是用C语言实现的。它定义了四种主要对象类型,每种对象都有对应的操作函数表:
| 对象类型 |
内存中实例数量 |
对应磁盘结构 |
生命周期 |
主要作用 |
| 超级块对象 |
每个挂载的文件系统一个 |
超级块 |
挂载期间 |
描述文件系统整体信息 |
| 索引节点对象 |
每个打开的文件一个 |
inode |
文件访问期间 |
描述文件的元数据和数据位置 |
| 目录项对象 |
每个路径分量一个 |
目录项 |
路径解析期间 |
链接文件名到inode,提供路径缓存 |
| 文件对象 |
每个打开的文件描述符一个 |
无 |
文件打开期间 |
描述进程与打开文件的交互状态 |
2.2 VFS四大核心对象详解
2.2.1 超级块对象(super_block)
超级块是文件系统的“身份证”和“管理手册”。每个挂载的文件系统在内存中都有一个超级块对象,它包含:
- 文件系统类型和基本信息
- 块大小、总块数、空闲块数
- 操作函数表(super_operations)
- 挂载选项和状态标志
在 Ext4 文件系统中,超级块对应磁盘上的特定扇区,记录了文件系统的关键参数。当文件系统挂载时,这些信息被读入内存,形成超级块对象。
2.2.2 索引节点对象(inode)
索引节点是文件的“身份证明”和“属性档案”。每个文件(包括目录、设备文件等)都有唯一的 inode,包含:
- 文件类型(普通文件、目录、符号链接等)
- 权限位(rwx权限)
- 所有者和组信息
- 时间戳(创建、修改、访问时间)
- 文件大小
- 数据块位置信息
inode 是理解 Linux 文件系统的关键。它不包含文件名,只包含文件的元数据和指向数据块的指针。多个文件名可以指向同一个 inode(硬链接),但一个 inode 只能属于一个文件系统。
// Linux内核中inode结构的简化表示
struct inode {
// 基本信息
umode_t i_mode; // 文件类型和权限
unsigned long i_ino; // inode编号
kdev_t i_dev; // 设备号
nlink_t i_nlink; // 硬链接计数
// 所有权
uid_t i_uid; // 用户ID
gid_t i_gid; // 组ID
// 大小和时间
loff_t i_size; // 文件大小(字节)
struct timespec i_atime; // 最后访问时间
struct timespec i_mtime; // 最后修改时间
struct timespec i_ctime; // 最后状态改变时间
// 数据块信息
unsigned long i_blocks; // 分配的块数
union {
// 不同文件系统的特定信息
struct ext4_inode_info ext4_i;
// 其他文件系统的inode信息...
} u;
// 操作方法
struct inode_operations *i_op; // inode操作
struct file_operations *i_fop; // 文件操作
struct super_block *i_sb; // 所属超级块
};
2.2.3 目录项对象(dentry)
目录项是文件路径中的“路标”和“名字标签”。它建立文件名到 inode 的映射关系,并提供路径查找缓存(dcache)以提高性能。
当用户访问 /home/user/document.txt 时,VFS 会为每个路径分量(home、user、document.txt)创建目录项对象,并将它们连接起来形成路径。
2.2.4 文件对象(file)
文件对象是进程与文件交互的“工作台”。每次 open() 系统调用都会创建一个文件对象,包含:
- 文件打开模式(读、写、追加等)
- 当前文件偏移量
- 操作函数表(file_operations)
- 指向关联 dentry 和 inode 的指针
多个进程可以同时打开同一个文件,每个进程都有自己的文件对象和文件偏移量。
2.3 VFS对象间的关系
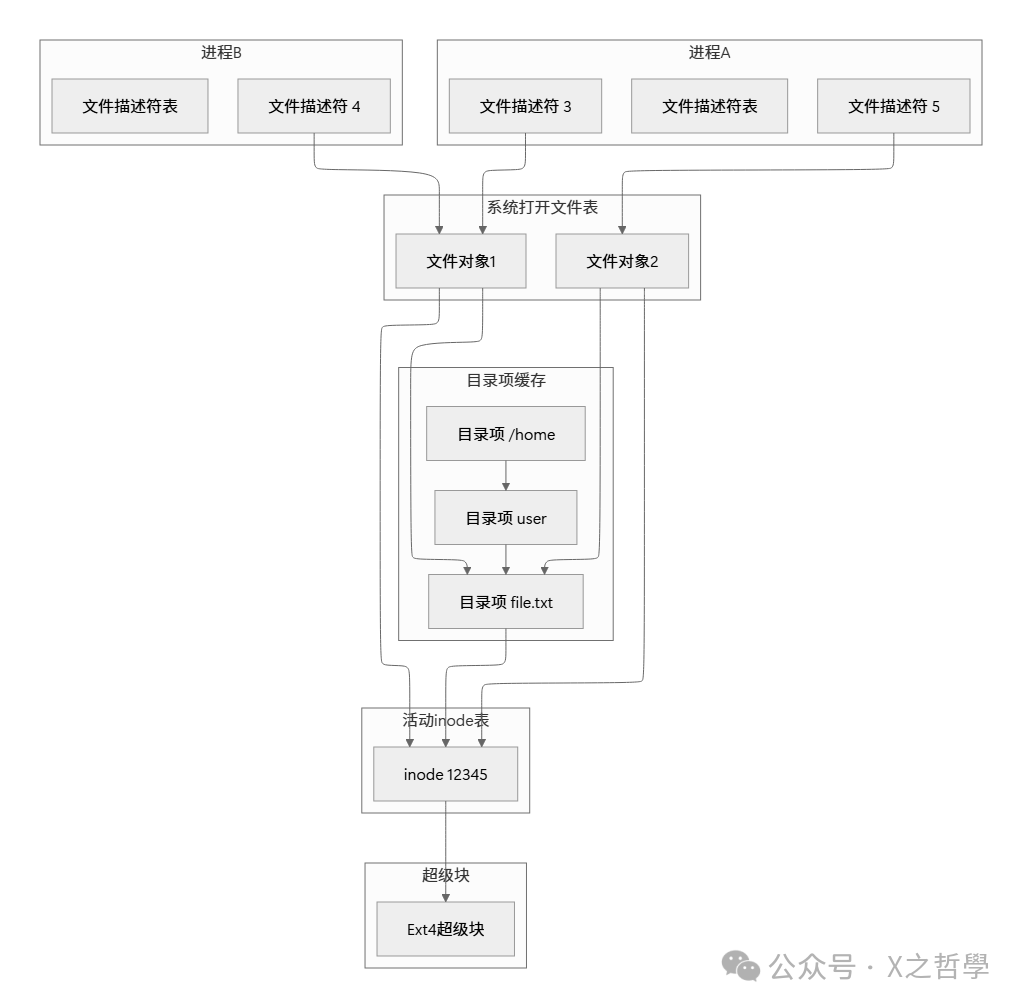
上图展示了 VFS 各对象之间的关系。注意多个进程可以共享同一个文件对象(如进程A和进程B都通过文件对象1访问文件),也可以有独立的文件对象(如进程A还通过文件对象2访问同一文件)。理解这些对象的 缓存机制 和生命周期对性能调优至关重要。
3. 磁盘文件系统结构: 数据如何持久存储
3.1 文件系统磁盘布局
文件系统在磁盘上的布局就像图书馆的书架规划,不同区域有不同用途。一个典型的 UNIX 文件系统磁盘布局如下:
| 区域 |
占磁盘比例 |
内容 |
作用 |
| 引导块 |
第一个块 |
引导程序 |
系统启动(仅根文件系统需要) |
| 超级块 |
紧随引导块 |
文件系统元数据 |
描述文件系统整体结构 |
| inode 表 |
约1-10% |
所有 inode |
存储文件元数据 |
| 数据块区 |
剩余空间 |
文件内容和目录项 |
存储实际数据 |
3.2 关键磁盘数据结构
3.2.1 超级块(Superblock)
超级块是文件系统的“总规划图”,通常位于磁盘的第二个块(第一个块是引导块)。它包含:
- 魔数(标识文件系统类型)
- 块大小和总数
- 空闲块计数和位置
- inode 总数和空闲数
- 挂载时间和最后写入时间
由于超级块至关重要,文件系统通常会创建多个备份,以防主超级块损坏。
3.2.2 inode 磁盘结构
磁盘上的 inode 是固定大小的结构(在 Ext2/3/4 中通常为 128 或 256 字节),包含文件的元数据。最重要的是,它包含指向文件数据块的指针:
- 直接指针: 前12个指针直接指向数据块
- 间接指针: 第13个指针指向一个包含256个指针的块(一级间接)
- 双间接指针: 第14个指针指向一个指针块,每个指针再指向一个指针块(二级间接)
- 三间接指针: 第15个指针提供三级间接寻址
这种设计允许小文件高效访问(直接指针),同时支持超大文件(通过间接指针)。计算表明,使用4KB块大小和32位块号时,这种结构可以支持最大约16TB的文件。
3.2.3 目录项(Directory Entry)
目录在磁盘上是一种特殊文件,其内容是由目录项组成的列表。每个目录项结构简单:
struct ext4_dir_entry {
__le32 inode; // inode编号
__le16 rec_len; // 目录项长度
__le8 name_len; // 文件名长度
__le8 file_type; // 文件类型
char name[]; // 文件名(变长)
};
目录查找就是线性扫描这些目录项,直到找到匹配的文件名。为了提高性能,现代文件系统如 Ext4 使用哈希树索引来加速大型目录的查找。
3.3 数据块分配策略
文件系统需要高效管理数据块,既要减少碎片,又要保证性能。Ext4 引入了多项改进:
- 多块分配: 一次性分配多个连续块,减少碎片
- 延迟分配: 直到数据写入缓存时才分配磁盘块,增加连续分配机会
- extent 结构: 用“起始块+长度”表示连续块范围,代替单个块指针列表
这种设计类似于停车场管理:与其记录每个车位状态,不如记录“从A区10号开始连续5个车位可用”,大大减少了元数据开销。
4. 具体文件系统实现: 以Ext4为例
4.1 Ext4的核心改进
Ext4 是 Linux 最常用的文件系统之一,它在 Ext3 基础上做了显著改进:
| 特性 |
Ext3 |
Ext4 |
改进效果 |
| 最大文件大小 |
2TB |
16TB |
支持更大文件 |
| 最大文件系统大小 |
4TB |
1EB |
支持超大存储 |
| 子目录限制 |
32000个 |
无限 |
更好的组织性 |
| Extents支持 |
无 |
有 |
减少碎片,提高性能 |
| 日志校验 |
无 |
有 |
提高数据完整性 |
| 在线碎片整理 |
无 |
有 |
维护期间可用性 |
4.2 Ext4磁盘布局细节
Ext4 使用更灵活的磁盘布局,称为“弹性块组”。它将磁盘划分为多个块组,每个块组包含自己的 inode 表和数据块,但元数据可以更灵活地分布。
块组0的开头包含:
- 超级块副本
- 块组描述符表
- 数据块位图(指示哪些块已用)
- inode 位图(指示哪些 inode 已用)
- inode 表
- 数据块
4.3 日志机制: 确保数据一致性
文件系统操作(如写入文件)涉及多个磁盘写入:更新 inode、更新位图、写入数据。如果系统在中间崩溃,文件系统可能处于不一致状态。
Ext3/4 的日志机制像飞机的“黑匣子”:首先将即将进行的操作记录到专门的日志区域,然后执行实际操作,最后清除日志记录。如果系统崩溃,恢复时只需重放或撤销日志中的操作,快速恢复一致性。
Ext4 提供三种日志模式:
- journal: 记录所有数据和元数据(最安全,性能最低)
- ordered: 只记录元数据,但保证先写数据再写元数据(默认模式)
- writeback: 只记录元数据,不保证写入顺序(性能最高)
5. 文件操作流程: 从系统调用到磁盘写入
5.1 文件打开流程
当应用程序调用 open("/home/user/file.txt", O_RDONLY) 时,内核执行以下步骤:
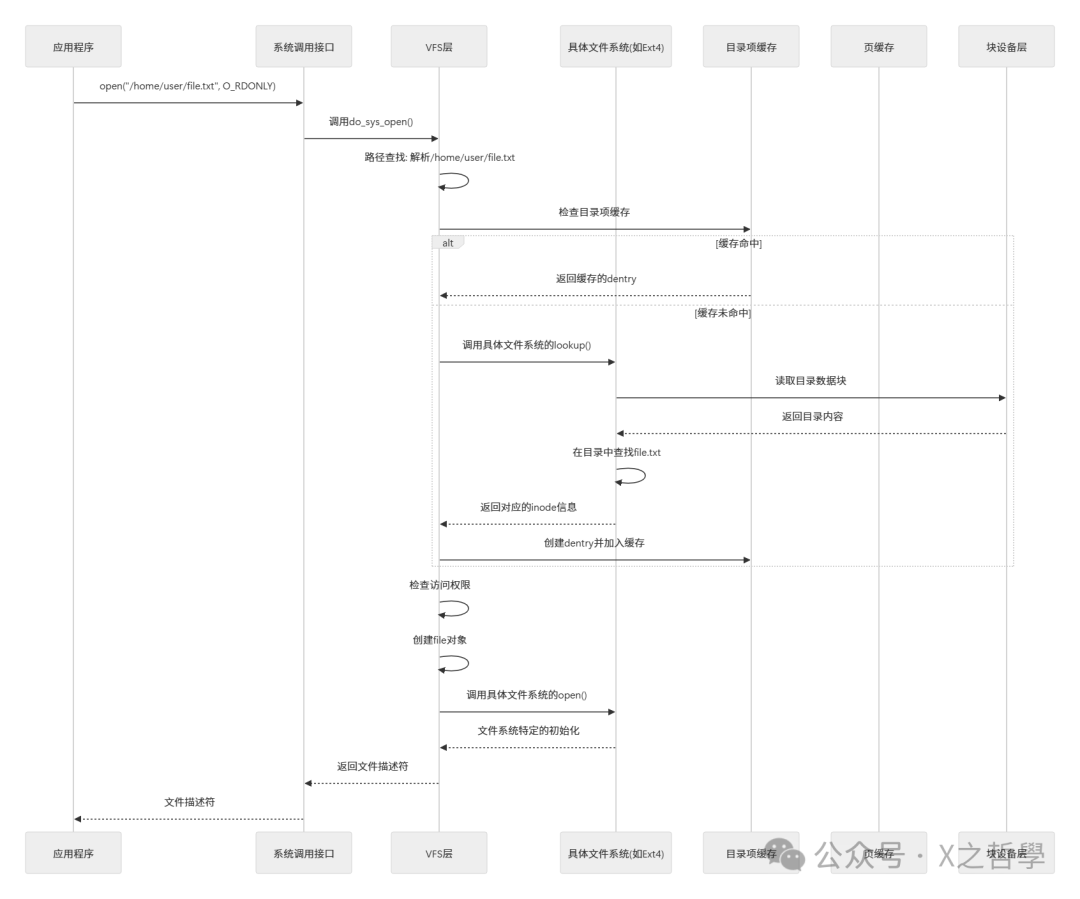
5.2 文件读取流程
read() 系统调用触发的读取流程体现了 Linux 文件系统的高度优化:
- 检查页缓存: 首先在内存的页缓存中查找所需数据
- 缓存命中: 如果数据已在缓存中,直接复制到用户缓冲区
- 缓存未命中: 从磁盘读取数据到页缓存,再复制到用户缓冲区
- 预读机制: 基于访问模式预测并提前读取后续数据块
这种机制使得顺序读取大文件时性能接近内存带宽,因为大多数读取操作都在缓存中完成。
5.3 文件写入流程
写入操作更加复杂,涉及缓存、回写和一致性保证:
- 写入页缓存: 数据首先写入内存中的页缓存
- 标记脏页: 修改的页面被标记为“脏”
- 延迟写入: 数据不会立即写入磁盘
- 内核线程回写: 由
pdflush 或 bdi_writeback 线程定期将脏页写入磁盘
这种“回写缓存”策略大幅提高了写入性能,但需要日志机制来保证崩溃一致性。
6. 高级主题: 文件系统特性与优化
6.1 文件系统特性对比
不同的文件系统针对不同用例进行了优化:
| 特性 |
Ext4 |
XFS |
Btrfs |
适用场景 |
| 最大文件系统 |
1EB |
8EB |
16EB |
超大存储 |
| 写时复制 |
否 |
否 |
是 |
快照和备份 |
| 数据校验和 |
仅元数据 |
仅元数据 |
全部数据 |
数据完整性要求高 |
| 在线压缩 |
否 |
是 |
是 |
节省存储空间 |
| 在线扩容 |
是 |
是 |
是 |
需要灵活扩展 |
| 子卷支持 |
有限 |
有限 |
完整 |
虚拟化和容器 |
6.2 性能优化技术
现代文件系统采用多种技术提高性能:
- 延迟分配: 直到数据必须写入磁盘时才分配块,增加连续分配机会
- 多块分配: 一次性分配多个连续块,减少碎片
- 预分配: 提前预留空间,保证连续性
- 日志校验: 减少日志恢复时间
- 屏障写入: 保证写入顺序,提高数据安全性
6.3 面向未来的文件系统: Btrfs
Btrfs(B-tree文件系统)代表了 Linux 文件系统的未来方向,它引入了几项革命性特性:
- 写时复制: 修改数据时不会覆盖原数据,而是写入新位置
- 内置 RAID 支持: 无需外部工具即可配置 RAID
- 子卷和快照: 轻量级快照,几乎瞬时创建
- 数据去重: 自动检测并合并重复数据块
- 透明压缩: 数据在磁盘上自动压缩,节省空间
7. 实用工具与调试技术
7.1 文件系统调试工具
理解和调试文件系统需要专业工具:
| 工具 |
用途 |
示例命令 |
debugfs |
直接检查和操作文件系统数据结构 |
debugfs /dev/sda1 |
dumpe2fs |
显示 Ext2/3/4 文件系统信息 |
dumpe2fs /dev/sda1 |
tune2fs |
调整 Ext2/3/4 文件系统参数 |
tune2fs -l /dev/sda1 |
xfs_info |
显示 XFS 文件系统信息 |
xfs_info /dev/sda1 |
btrfs |
Btrfs 文件系统管理工具 |
btrfs filesystem show |
7.2 性能分析与追踪
对于深入分析文件系统性能问题,Linux 提供了强大的追踪工具:
- strace: 跟踪系统调用
strace -e trace=file -tt -o trace.log ls -l
- ftrace: 内核函数追踪
echo function > /sys/kernel/debug/tracing/current_tracer
echo 1 > /sys/kernel/debug/tracing/tracing_on
cat /sys/kernel/debug/tracing/trace
- BPF/eBPF: 高级动态追踪
bpftrace -e 'tracepoint:ext4:ext4_sync_file { printf("%s %d\n", comm, pid); }'
- blktrace: 块设备 I/O 追踪
blktrace -d /dev/sda -o trace
blkparse trace
7.3 文件系统检查和修复
文件系统损坏时,需要使用修复工具:
- fsck: 文件系统检查与修复
fsck.ext4 -p /dev/sda1 # 自动修复
fsck.ext4 -y /dev/sda1 # 交互式修复
- xfs_repair: XFS 文件系统修复
xfs_repair /dev/sda1
- btrfs check: Btrfs 文件系统检查
btrfs check /dev/sda1
重要提示: 在运行修复工具前,务必卸载文件系统或从救援环境启动,避免数据损坏。
8. 文件系统实现实例: 一个简化的学习模型
为了帮助理解文件系统的工作原理,让我们设计一个极简的内存文件系统(MemeFS)。这个示例展示了文件系统核心概念的实际应用:
#include <linux/fs.h>
#include <linux/module.h>
#include <linux/slab.h>
#define MEMFS_MAGIC 0x20250112
#define MAX_FILES 128
#define BLOCK_SIZE 4096
// 内存文件系统超级块
struct memfs_sb_info {
unsigned long magic; // 魔数
int block_size; // 块大小
int max_blocks; // 最大块数
int free_blocks; // 空闲块数
unsigned long *bitmap; // 块位图
};
// 内存文件系统inode信息
struct memfs_inode_info {
int first_block; // 第一个数据块索引
int num_blocks; // 分配的块数
char *data_blocks; // 数据块指针
struct inode vfs_inode; // VFS inode
};
// 文件系统类型定义
static struct file_system_type memfs_fs_type = {
.owner = THIS_MODULE,
.name = "memfs",
.mount = memfs_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
// 超级块操作
static const struct super_operations memfs_sops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode,
.show_options = generic_show_options,
};
// inode操作
static const struct inode_operations memfs_iops = {
.lookup = simple_lookup,
.getattr = memfs_getattr,
};
// 文件操作
static const struct file_operations memfs_fops = {
.read_iter = generic_file_read_iter,
.write_iter = generic_file_write_iter,
.llseek = generic_file_llseek,
.open = generic_file_open,
};
// 创建inode
static struct inode *memfs_create_inode(struct super_block *sb, umode_t mode)
{
struct inode *inode;
struct memfs_inode_info *info;
inode = new_inode(sb);
if (!inode)
return NULL;
inode->i_ino = get_next_ino();
inode->i_mode = mode;
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
info = kmalloc(sizeof(struct memfs_inode_info), GFP_KERNEL);
if (!info) {
iput(inode);
return NULL;
}
info->first_block = -1; // 未分配
info->num_blocks = 0;
info->data_blocks = NULL;
inode->i_private = info;
if (S_ISDIR(mode)) {
inode->i_op = &memfs_iops;
inode->i_fop = &simple_dir_operations;
set_nlink(inode, 2); // "."和".."
} else if (S_ISREG(mode)) {
inode->i_op = &memfs_iops;
inode->i_fop = &memfs_fops;
set_nlink(inode, 1);
}
return inode;
}
// 挂载文件系统
static struct dentry *memfs_mount(struct file_system_type *fs_type,
int flags, const char *dev_name,
void *data)
{
struct dentry *root;
struct super_block *sb;
struct memfs_sb_info *sbi;
// 分配超级块
sb = sget(fs_type, NULL, set_anon_super, flags, NULL);
if (IS_ERR(sb))
return ERR_CAST(sb);
// 初始化超级块信息
sbi = kzalloc(sizeof(struct memfs_sb_info), GFP_KERNEL);
if (!sbi) {
deactivate_locked_super(sb);
return ERR_PTR(-ENOMEM);
}
sbi->magic = MEMFS_MAGIC;
sbi->block_size = BLOCK_SIZE;
sbi->max_blocks = MAX_FILES * 4; // 每个文件最多4个块
sbi->free_blocks = sbi->max_blocks;
// 分配位图
sbi->bitmap = kcalloc(BITS_TO_LONGS(sbi->max_blocks),
sizeof(unsigned long), GFP_KERNEL);
if (!sbi->bitmap) {
kfree(sbi);
deactivate_locked_super(sb);
return ERR_PTR(-ENOMEM);
}
sb->s_fs_info = sbi;
sb->s_op = &memfs_sops;
sb->s_time_gran = 1;
// 创建根目录inode
root = d_make_root(memfs_create_inode(sb, S_IFDIR | 0755));
if (!root) {
kfree(sbi->bitmap);
kfree(sbi);
deactivate_locked_super(sb);
return ERR_PTR(-ENOMEM);
}
sb->s_root = root;
return root;
}
// 模块初始化
static int __init memfs_init(void)
{
int ret;
printk(KERN_INFO "MemFS: Initializing memory file system\n");
ret = register_filesystem(&memfs_fs_type);
if (ret) {
printk(KERN_ERR "MemFS: Failed to register filesystem\n");
return ret;
}
printk(KERN_INFO "MemFS: Registered successfully\n");
return 0;
}
// 模块清理
static void __exit memfs_exit(void)
{
unregister_filesystem(&memfs_fs_type);
printk(KERN_INFO "MemFS: Unregistered\n");
}
module_init(memfs_init);
module_exit(memfs_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Linux Filesystem Explorer");
MODULE_DESCRIPTION("A simple in-memory filesystem for educational purposes");
这个简化的内存文件系统展示了:
- 文件系统类型注册
- 超级块创建和初始化
- inode 创建和管理
- 简单的块分配策略
- 与 VFS 的集成方式
虽然功能有限,但它包含了真实文件系统的核心要素,对于理解 存储架构 非常有帮助。
9. 总结
Linux 文件系统是一个复杂而精妙的系统,它通过多层抽象和优化,在简单性与性能、一致性与效率之间取得了精巧的平衡。
从设计思想看,Linux 文件系统的核心是“一切皆文件”的 UNIX 哲学和分层抽象架构。VFS 层提供了统一接口,具体文件系统实现细节,块设备层处理硬件差异。这种设计使得 Linux 能够支持数十种文件系统,从传统的 Ext4 到现代的 Btrfs,从本地文件系统到网络文件系统。
从数据结构看,文件系统的核心是 inode、dentry、file 和 superblock 这四大对象。inode 是文件的身份证明,存储元数据和数据位置;dentry 是路径导航的路标,提供名称解析和缓存;file 是进程与文件的交互界面;superblock 是文件系统的管理手册。这些对象在内存和磁盘上有着不同的表示和生命周期,通过精巧的缓存机制提高性能。
从实现机制看,现代文件系统采用了许多优化技术:日志机制确保崩溃一致性,延迟分配提高空间连续性,写时复制支持高效快照,数据校验和保证完整性。这些机制共同作用,使文件系统既可靠又高效。
从发展趋势看,文件系统正在适应新硬件和新场景。NVMe SSD 需要新的 I/O 模式,持久内存需要新的存储抽象,云计算需要多租户和弹性扩展。未来文件系统可能会更加智能化,能够自动优化数据布局,预测访问模式,甚至理解数据语义。
理解 Linux 文件系统不仅有助于解决实际运维问题,还能启发我们对存储系统设计的思考。在这个数据爆炸的时代,高效可靠的文件系统比以往任何时候都更加重要。深入掌握这些底层原理,也是每一位追求卓越的开发者可以在 云栈社区 等技术论坛中进行深入交流和成长的宝贵财富。
 发表于 2026-1-13 02:24:31
|
查看: 219|
回复: 0
发表于 2026-1-13 02:24:31
|
查看: 219|
回复: 0
