软件工程领域正面临日益复杂的挑战,开发人员不仅需要深厚的技术知识,还需借助智能化工具来高效解决问题。数字化转型的加速推进使得软件系统规模急剧扩大,传统手工方式已难以应对代码维护与质量保障的快速增长需求。
在此背景下,月之暗面于2025年6月发布了针对软件工程任务的全新开源代码大模型 Kimi-Dev-72B。
月之暗面公司成立于2023年3月,由清华天才少年杨植麟创立,其团队核心成员曾任职于谷歌、Meta等顶尖科技企业。凭借在长文本处理和多模态AI领域的技术积累,该公司已推出支持20万汉字超长上下文处理的Kimi智能助手。
进入2025年,面对DeepSeek等竞争对手的技术突破及其开源策略带来的市场压力,月之暗面决定调整战略,转向开源领域。Kimi-Dev-72B的发布,正是这一战略转型的关键举措。
开创性的双角色代码智能体
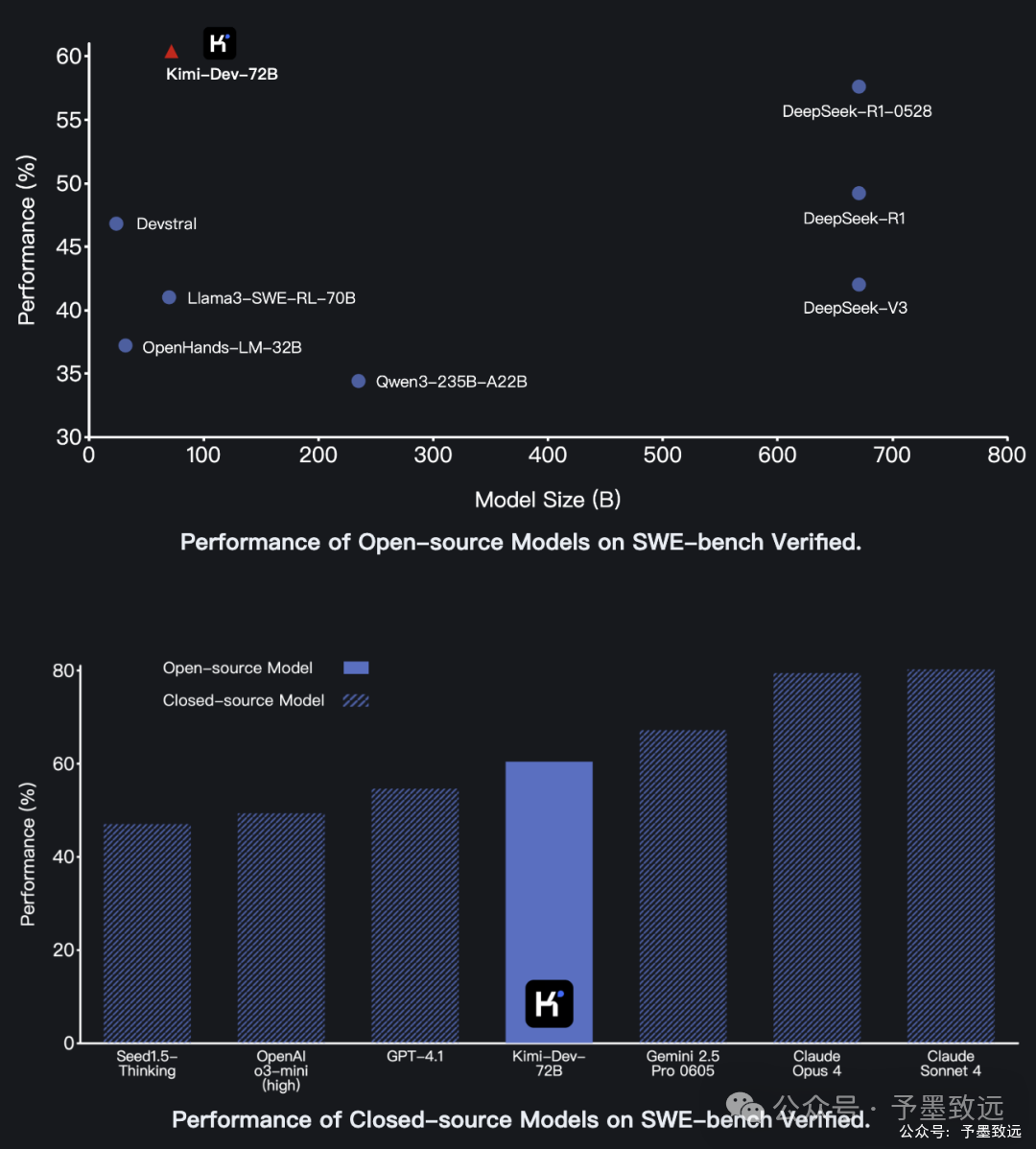
Kimi-Dev-72B是一款为软件工程领域量身打造的开源代码大型语言模型,旨在通过智能化手段解决开发过程中的各类问题。该模型最显著的特点,在于它打破了“参数规模决定性能”的行业迷思,以仅720亿的参数量,取得了超越更大规模模型的性能表现。
目前,该模型已在 HuggingFace 和 GitHub 平台提供完整的模型权重及源代码下载与部署支持。
在基础架构上,Kimi-Dev-72B基于Qwen 2.5-72B模型进行二次开发。这意味着使用者需要遵守Qwen-2.5-72B的原始许可限制(如《通义千问许可协议》),而月之暗面自身的创新工作(即通过强化学习获得的微调权重)则以宽松的MIT协议开源。这一许可模式既尊重了上游开源社区,也保障了自身创新成果的开放性。
自我博弈与结果导向的训练哲学
Kimi-Dev-72B的设计核心在于 BugFixer(代码缺陷修正者) 和 TestWriter(测试编写者) 两种角色的结合。这一创新设计使模型能够自我验证修复的正确性,形成一个闭环的智能工作流。
两种角色都遵循一个共同的最小框架,包含两个关键阶段:
- 文件定位:准确找到需要修改的目标文件。
- 代码编辑:修正现有代码中的问题或潜在缺陷,并根据需要编写并添加新的单元测试代码。
为了夯实模型作为BugFixer和TestWriter的先验知识,研发团队以Qwen 2.5-72B基础模型为起点,使用了约1500亿个高质量的真实数据进行了中期训练。训练数据包含数百万个来自 GitHub 的问题与PR提交记录,目的是让模型学习人类开发者如何推理问题并生成解决方案。团队还执行了严格的数据净化流程,确保训练数据中不包含SWE-bench Verified基准中的内容,避免数据泄露。
模型训练中的一个关键创新是 仅基于执行结果的奖励机制。在训练过程中,只使用代码在Docker环境中的最终执行结果(成功为1,失败为0)作为奖励信号,而不考虑任何与代码格式或编写过程相关的中间因素。这种纯粹以结果为导向的设计,确保了模型生成的解决方案高度符合实际开发标准,具备真正的可执行性。
强化学习策略:步步为营的智能化演进
经过中期训练和监督微调后,Kimi-Dev-72B在文件定位方面已表现出色。随后的强化学习阶段主要侧重于进一步提升其代码编辑能力。这一阶段采用了月之暗面k1.5模型中描述的先进策略优化方法,其中包含三个关键设计。
首先,是 高效提示集 的构建。团队会过滤掉在多样本评估下成功率为零的提示,以此提升大批量训练的效率和针对性。其次,采取了循序渐进的课程学习策略,逐步引入新的、更具挑战性的提示,从而阶梯式地增加任务难度。
第三个关键设计是 正向示例强化。在训练的最后阶段,模型会将之前已经成功解决的问题方案,重新纳入当前的训练批次中进行学习。这一过程能够巩固和强化那些被验证有效的解决模式与方法,加速模型的收敛与性能提升。
性能表现:在权威基准测试中证明实力
Kimi-Dev-72B在 SWE-bench Verified 基准测试中取得了 60.4% 的准确率,创下了开源模型在此项测试中的SOTA(当前最佳)记录。SWE-bench是用于评估大语言模型在真实软件开发环境中解决代码问题能力的权威基准,而SWE-bench Verified是其经过精炼和验证的改进版本,包含500个高质量样本。
这一成绩的引人注目之处在于,它超越了参数量高达6710亿的新版DeepSeek-R1,有力地挑战了行业对“参数即性能”的固有认知。这标志着在人工智能领域,精专化的模型设计与训练策略,可能比单纯的规模扩张更具效率。
当然,关于该模型的评价也存在一些讨论。部分观点认为,作为Qwen2.5-72B的微调版本,仅在一个基准测试上取得的优异成绩可能缺乏足够的泛化说服力,且有用户实测反馈其部分场景下的效果不如DeepSeek-R1。此外,有测试表明该模型在处理中文问题时,其思考与回答均以英文进行,在中文场景下存在一定的应用局限性。
部署与应用:降低技术门槛的务实方案
Kimi-Dev-72B的量化版本已在 Hugging Face 平台上线,为开发者提供了更便捷、资源需求更低的接入方式。对于希望进行本地部署的用户,模型对硬件有一定要求,官方推荐使用8张NVIDIA 4090显卡,并支持高效的vLLM推理引擎。
在实际应用层面,一个值得关注的渠道是OpenRouter平台。该平台提供了免费兼容OpenAI API调用的Kimi-Dev-72B接口,极大降低了开发者试用和将其集成到自身工作流中的技术门槛。
尽管如此,也有开发者反馈,完整的模型文件体积约140GB,本地部署仍需相当的技术实力和硬件资源支撑。这反映出当前大模型应用在普惠性与高性能之间仍需权衡。
月之暗面公司已经制定了清晰的未来路线图,计划继续扩展Kimi-Dev的能力边界,推动其与主流开发工具、版本控制系统以及CI/CD流程的深度整合,目标是进一步融入开发者的日常工作流。这表明Kimi-Dev-72B不仅仅是一个独立的技术产品,更是构建未来软件工程智能化生态系统的重要一环。
专业化道路上的无限可能
Kimi-Dev-72B的成功,清晰地展示了技术专业化路径的巨大价值。其核心优势在于精准解决具体行业痛点,而非盲目追求通用参数规模。这种“以小博大”的技术路线,为中国AI企业在全球竞争中探索出了一条差异化的创新路径。
月之暗面表示,正在积极研究和开发扩展Kimi-Dev-72B功能的方法,并探索让其处理更复杂的软件工程任务。公司承诺将持续改进模型,进行严谨的红队测试,并向社区发布更强大的版本。
从整个行业视角来看,Kimi-Dev-72B的推出揭示了AI竞争底层逻辑的深刻变化:当AI从“新奇工具”转变为“生产基础设施”,用户选择的核心标准已悄然从“营销声量”转向“实打实的技术体验与效率提升”。
这种转变倒逼所有AI企业重新审视自身的发展策略,不再盲目追求参数规模或表面的通用性,而是要在特定领域建立有深度、可验证的专业优势。关于此类专业化AI模型的更多实践与讨论,欢迎在云栈社区与广大开发者共同交流。
模型信息
 发表于 2026-1-13 05:09:35
|
查看: 244|
回复: 0
发表于 2026-1-13 05:09:35
|
查看: 244|
回复: 0
