近日,一份来自顶级研究机构的最新基准测试结果在 AI 与软件工程领域引发了广泛讨论。这份名为 SWE-Bench Mobile 的测试,并非使用常规的教学案例,而是动用了小红书生产环境中真实的 iOS 代码库,对当前最前沿的 AI 编程工具进行了一场“工业级”实战考核。结果表明,即便是最强大的组合,任务成功率也仅达到 12%。
这个基准测试的特别之处在于其评估对象的真实性。它使用的是支撑着全球数亿月活用户的真实小红书 App 源码,整个代码库体量达到 14GB,包含超过 60 万行 Swift 代码和 15 万行 Objective-C 代码。这已经与学术界常用的、经过精心裁剪的小型测试集完全不在一个量级上。

天花板仅在12%:工业实践揭示AI编程的现实瓶颈
Cursor、Codex、Claude Code、OpenCode,这四个代表业界当前最高水准的 AI 编程 工具,连同 7 种主流的底层大语言模型,共计 22 种配置组合全部参与了评测。最终,表现最佳的配置——Cursor 搭载 Claude Opus 4.5 模型——所达到的最高任务成功率也仅为 12%。那些在传统 SWE-bench 测试中动辄宣称 70% 甚至 80% 通过率的同款模型,在面对真实的工业级移动端代码库时,表现出现了断崖式下滑。
关键数据揭示了更严峻的挑战:当任务复杂度提升,需要同时修改 7 个以上文件时,所有配置的成功率从平均 18% 暴跌至 2% 以下。其中,Codex 搭载 GPT-5.1 的组合,成功率直接归零。
评测方法本身也进行了针对性创新。为了避免 iOS 大型工程漫长且不稳定的编译过程对评估造成干扰,研究团队采用了 449 个人工精心编写的 pytest 测试用例进行“补丁级静态验证”。他们要求 AI 智能体直接输出符合 Git 标准的代码差异(diff)补丁文件,然后通过语义模式匹配来验证该补丁是否准确实现了产品意图并符合架构规范。更重要的是,整套任务和用于评估的代码库完全闭源,托管在专属服务器上,彻底杜绝了模型通过预训练阶段“背诵”特定代码来刷高分的可能性。
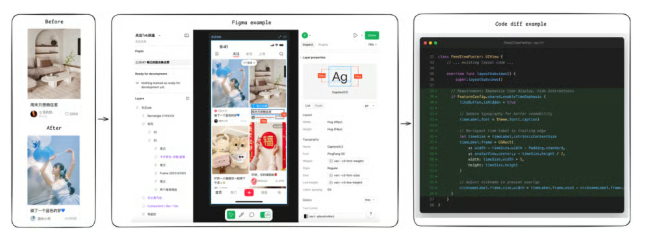
失败归因:企业级开发规范成AI“盲区”
仅仅关注成功率数字意义有限,更重要的是分析失败原因。研究团队对大量失败案例进行了细致的归因分析,结论指向了当前大语言模型在理解企业级开发实践上的普遍短板。
高达 54% 的失败是由于智能体完全无法理解“Feature Flag”(功能开关)这一企业级部署规范。简单来说,在大型互联网公司的生产环境中,新功能上线通常不会一次性推送给所有用户,而是通过代码中的开关控制,进行灰度发布或 A/B 测试。然而,AI 智能体往往忽略了这个开关的存在,直接修改核心业务逻辑,这种操作在生产环境中是极其危险且不被允许的。
另有 22% 的失败属于“顾此失彼”型,即智能体修改了用户界面(UI),却忘记同步更新底层的数据模型,导致视图层与数据层脱节,程序一运行便错误百出。还有 9% 的失败是由于缺少必需的协议方法实现,这表明模型对面向对象编程中的“接口契约”理解尚不完整,容易留下潜在的逻辑漏洞或内存泄漏隐患。
该测试的另一个独特之处是强制要求多模态输入。92% 的任务都附带了 Figma 高保真设计稿作为视觉参考,70% 的任务包含了详细的 Figma 设计规范文档。这意味着智能体必须同时理解文字描述的产品逻辑和像素级的视觉设计要求,并将两者融合,输出准确的代码变更。这种“图文结合”的需求输入方式,恰恰是真实 iOS开发 中程序员每天都在面对的场景,而目前的模型在此方面表现仍显稚嫩。
研究还揭示了一个反直觉的发现:给予智能体过于详细和复杂的提示词(Prompt),并不能有效提升成功率。实验中,一套旨在引导智能体进行“深度全局规划”的复杂提示词,反而将成功率从 10% 拉低至 4%,“想得太多”成为了一种真实的障碍。相比之下,采用简单的“防御性编程”提示——例如提醒模型多关注边界条件、妥善处理空值等——却能使测试通过率提升 7.4%。这一结果值得众多正在尝试将 AI 融入工作流的工程师重新审视自己的提示词策略。
启示:协作而非替代,是当前的最优解
SWE-Bench Mobile 的发布,其目的并非否定 AI 在编程领域的价值,而是如同一面清晰的棱镜,帮助整个行业更准确地看清当前技术能力的实际边界。
测试结果表明,当前主流大语言模型存在显著的“生产意识盲区”。它们在预训练阶段学习的大多是公开的开源代码(尤其是 Python 领域),对于企业内部普遍采用的灰度发布、特性管控、架构治理等工程实践和约束规范相当陌生。要弥合这一鸿沟,仅靠扩大模型参数规模可能收效甚微,更关键的是需要在预训练阶段引入更多真实的、工业级的代码库及其背后的工程决策逻辑。
此外,评测还突显了一个重要观点:智能体框架的工程设计,其重要性可能不亚于底层模型的能力。以 Claude Opus 4.5 模型为例,在 Cursor 框架中能实现 12% 的成功率,而在另一套框架中成功率仅剩 4%。这三倍的差距并非源于模型本身,而是框架在上下文管理、跨文件推理、工具链调用等“脚手架”能力上的差异。未来 AI 软件工程 的竞争焦点,很可能从单纯的模型性能竞赛,转向更高效的智能体框架与工程化实践。
综合来看,在现阶段,AI 在软件工程中最恰当的定位仍然是“副驾驶”(Copilot),即人类工程师的高效辅助者,而非完全的替代者。由人类把控顶层架构设计、核心业务逻辑和关键工程决策,而 AI 智能体则专注于局部的代码生成、样板文件搭建和重复性的测试用例编写,两者协同工作,方能最大化开发效率。SWE-Bench Mobile 首次为我们提供了基于真实工业场景的、可量化的数据来支撑这一判断。
论文地址:https://arxiv.org/abs/2602.09540
对 AI 编程前沿、移动端开发最佳实践以及更多开源实战案例感兴趣?欢迎来 云栈社区 与更多开发者一同交流探讨。
 发表于 2026-3-3 08:09:24
|
查看: 244|
回复: 0
发表于 2026-3-3 08:09:24
|
查看: 244|
回复: 0
