数据库是大型系统架构的核心,支撑千万级QPS(每秒查询率)是许多高并发场景下的硬性需求。本文将系统性地解析MySQL实现千万QPS的核心架构方案。
读写分离
核心思想是将读写操作分离:将写请求集中在主库节点,而将读请求分摊到多个从库节点。
通过主从复制或多主复制技术,可以将读请求导向只读副本,从而显著降低主库的压力。在数据延迟可接受的业务场景下,部署大量的只读副本是横向扩展读QPS的有效手段。
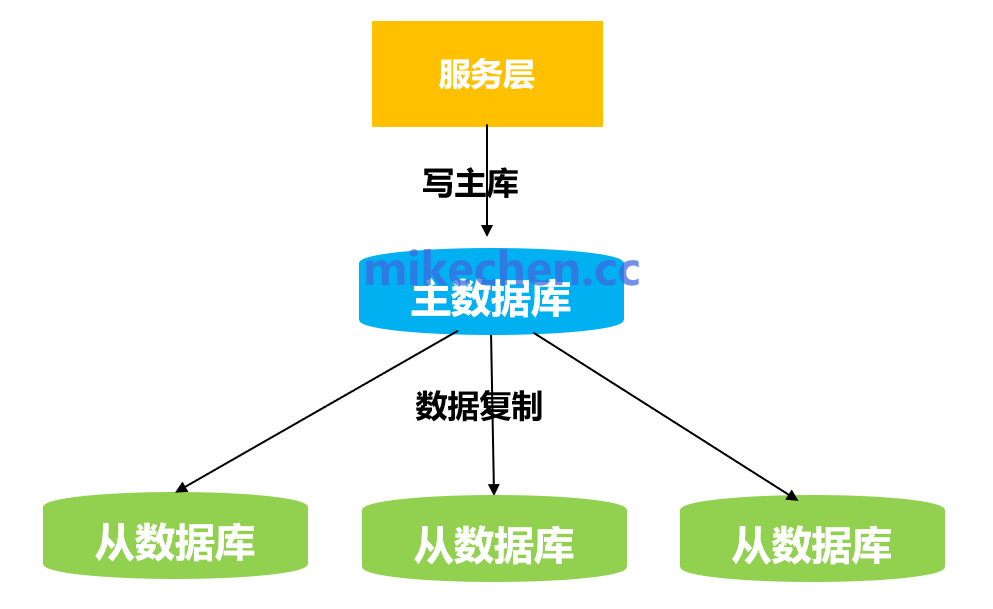
为什么读写分离是提升性能的第一层放大器?这源于现实业务中的流量特征:读请求通常占据总请求量的80%至95%,而写请求占比极低。其架构效果可以抽象为:
1 个主库(负责写)
+
N 个从库(负责读)
这种架构能充分利用多个节点的资源,有效分担负载。关于更多 分布式系统 的设计思路,可以参考相关专题。
存储引擎优化
MySQL性能的底层决定因素来自于其存储引擎(如默认的InnoDB)的设计与索引策略。

关键优化技术包括:
- 索引设计与覆盖索引:创建高效的索引,并尽可能使用覆盖索引来避免回表操作,减少磁盘IO。
- 行格式与页大小优化:选择合适的行格式(如Dynamic)和页大小(如16KB或8KB),可以降低磁盘与内存的占用,提升处理效率。
- 并发控制:利用MVCC(多版本并发控制)和合理的锁机制来减少锁争用,提高并发吞吐量。
- 缓冲池(Buffer Pool)调优:合理设置缓冲池大小,优化数据预读和刷新策略,可以极大提升热点数据的命中率。
- 复制通道优化:使用基于GTID的非阻塞复制,并开启并行应用二进制日志(binlog),可以优化主从间的数据同步效率。
引入缓存层
在应用层或中间件层引入分布式缓存(如 Redis 或 Memcached),是截流热点数据请求、大幅减少对MySQL直接访问的利器。
缓存设计需要考虑多种模式,包括显式缓存、二级缓存、热点数据预热以及应对缓存穿透和雪崩的防护策略。配合合理的缓存失效与更新策略(如经典的Cache Aside Pattern,即延迟双删),可以在性能与数据一致性之间取得良好平衡。

上图清晰地展示了缓存旁路模式的工作流程:读请求优先查询缓存,未命中则读数据库并回填缓存;写请求直接更新数据库,然后使相关缓存失效。
数据库拆分(分库分表)
当单机性能达到瓶颈时,数据库拆分是实现千万QPS目标的“入场券”。既然单台机器的承载能力有上限,那么就将数据和请求分散到上百甚至上千台机器上。
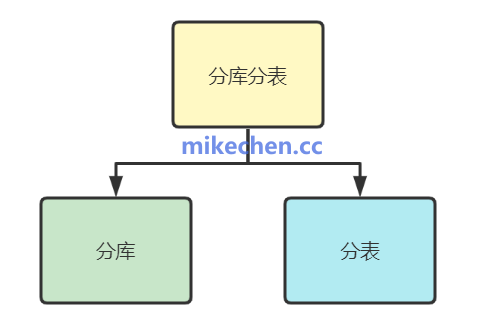
其核心逻辑是通过哈希(Hash)或范围(Range)等分片算法,将海量数据均匀分布到多个物理数据库节点中。从理论上计算,如果100个节点每个能承担10万QPS,那么整体就能支撑1000万QPS。
当然,分库分表在解决容量和性能问题的同时,也引入了分布式事务、跨库关联查询(Join)、全局有序ID生成等复杂挑战。在实际应用中,通常需要借助 ShardingSphere 或 Vitess 这类成熟的数据库中间件来简化开发难度。
总结
实现MySQL千万级QPS并非依靠单一技术,而是一个从架构到细节的立体化优化过程。它始于基础的读写分离与存储引擎调优,强化于缓存层的引入,最终通过水平拆分(分库分表)突破单机物理极限。每种方案都需要根据具体的业务场景、数据特性和一致性要求进行权衡与设计。希望这些思路能为你的高性能系统架构提供参考。更多数据库与高并发架构的深度讨论,欢迎在云栈社区交流分享。 |  发表于 2026-1-13 23:18:19
|
查看: 170|
回复: 0
发表于 2026-1-13 23:18:19
|
查看: 170|
回复: 0
