选错架构,半年白干;选对组合,事半功倍。在大数据技术栈快速演进的今天,Hudi、Iceberg、Paimon 和 Doris 成了构建现代数据平台的“四大金刚”。但它们到底是什么?能一起用吗?该选谁?怎么避坑?
本文从 架构选型视角 出发,帮你理清这四者的定位、适用场景、组合方式,并给出实战优化与避坑建议。
一、先搞清楚:它们根本不是一类东西!
很多人一上来就问:“Hudi 和 Doris 哪个好?”——这就像问“MySQL 和 Kafka 哪个好”一样,类别都错了。
| 系统 |
类型 |
核心作用 |
| Hudi |
数据湖表格式 |
支持增量更新、CDC 入湖,兼容 Hive/Spark |
| Iceberg |
数据湖表格式 |
面向 PB 级离线分析,元数据解耦,多引擎友好 |
| Paimon |
数据湖表格式(原 Flink Table Store) |
专为流批一体设计,Flink 原生支持,CDC 实时入湖王者 |
| Doris |
MPP 分析型数据库(OLAP) |
实时查询、高并发、低延迟,不是数据湖! |
关键结论:
- Hudi / Iceberg / Paimon 是“存储层”的表格式,用于构建 数据湖(Data Lake)或 湖仓一体(Lakehouse)。
- Doris 是“计算+存储一体”的 OLAP 引擎,用于 实时分析,类似 ClickHouse、StarRocks。
它们不是互斥关系,而是互补关系——湖存原始数据,仓做加速查询。
二、各自擅长什么?适用场景全解析
1. Apache Hudi:传统数仓的“平滑迁移者”
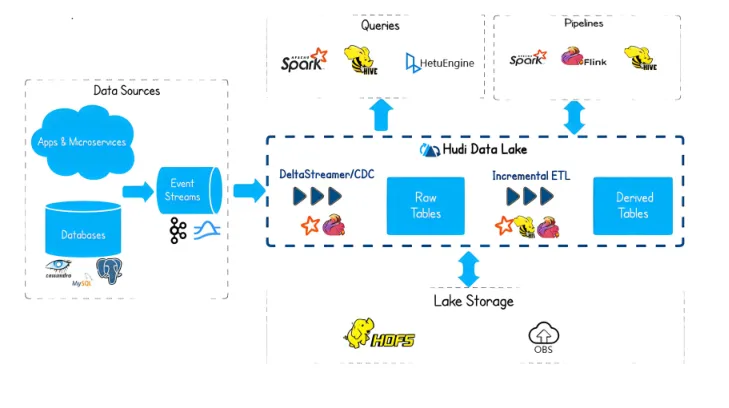
- 优势:
- 与 Hive 兼容性极佳,适合已有 Hive 数仓的企业
- 支持 COW(写时复制)和 MOR(读时合并),可做增量 ETL
- 劣势:
- 架构复杂,参数繁多,运维成本高
- Flink 支持弱,流处理性能不如 Paimon
- 适用场景:
“我们有大量 Hive 表,想逐步迁移到数据湖,但不能停业务。”
2. Apache Iceberg:开放湖仓的“标准制定者”
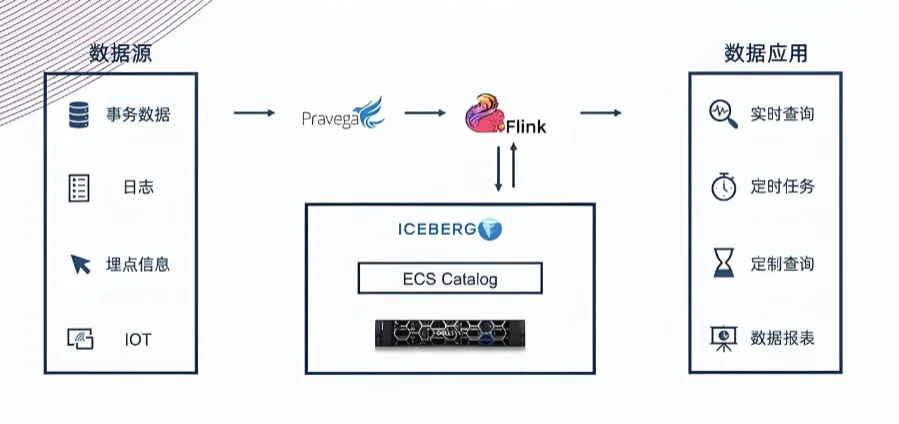
- 优势:
- 元数据三层结构(Table → Snapshot → Manifest → Data),扩展性强
- 多引擎支持好(Spark/Flink/Trino/Presto)
- 支持 Time Travel、Schema Evolution、文件级加密
- 劣势:
- 不擅长 CDC 实时更新,写入延迟较高
- 流式消费能力弱
- 适用场景:
“我们要建一个 PB 级开放数据湖,供多个团队用不同引擎查,还要支持数据治理。”
3. Apache Paimon:流批一体的“新锐黑马”
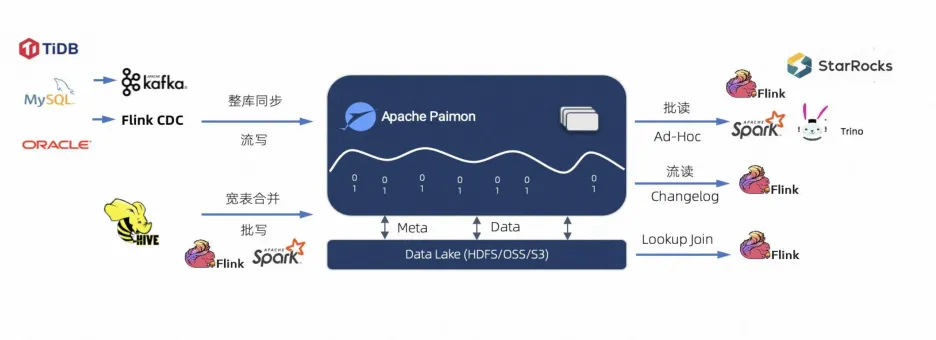
- 优势:
- Flink 原生集成,CDC 实时入湖延迟可到毫秒级
- Upsert 性能碾压 Hudi(实测写入快 2–3 倍)
- 支持 Changelog 流式订阅,可直接对接下游 Flink 作业
- 劣势:
- 社区较新(2023 年进入 Apache 孵化器)
- 批处理生态、Python 支持尚不成熟
- 适用场景:
“我们用 Flink 做实时数仓,需要把 MySQL Binlog 实时写入湖,并支持后续流式聚合。”
4. Apache Doris:实时分析的“性能王者”
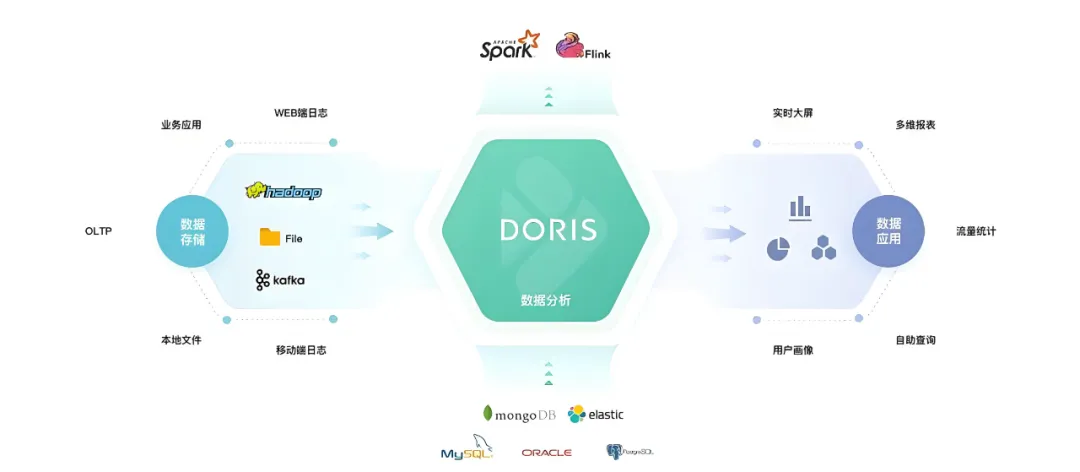
- 优势:
- 亚秒级查询响应,支持高并发点查和复杂聚合
- 自动聚合、物化视图、向量化执行
- 部署简单,运维成本低
- 劣势:
- 不适合存储原始明细数据(成本高)
- 不是数据湖,无法替代 Hudi/Iceberg/Paimon
- 适用场景:
“我们需要给 BI 系统、运营后台提供实时报表,QPS 要求高,延迟要低于 1 秒。”
三、横向对比:一张表看懂差异
| 维度 |
Hudi |
Iceberg |
Paimon |
Doris |
| 核心定位 |
增量更新湖 |
开放湖仓标准 |
流批一体湖 |
实时 OLAP |
| CDC 支持 |
中等 |
弱 |
强(Flink 原生) |
强(通过 Routine Load) |
| 多引擎兼容 |
Spark/Hive |
强 Spark/Flink/Trino |
主要 Flink |
自有引擎 |
| 实时查询 |
弱 |
弱 |
中(需配合计算引擎) |
极强 |
| 存储成本 |
低(存 S3/HDFS) |
低 |
低 |
高(需 SSD) |
| 适合规模 |
TB–PB |
PB+ |
TB–PB(实时) |
GB–TB(热数据) |
| 学习曲线 |
高 |
中 |
中 |
低 |
四、如何组合使用?湖仓一体最佳实践
真正的高手,从来不是“单打独斗”,而是组合出拳。
推荐架构:分层解耦 + 按需加速

场景 1:实时数仓(Flink 技术栈)
Kafka → Flink CDC → Paimon(明细层)- Flink 聚合 → Doris(服务层)
- 优势:端到端延迟 < 1s,支持 Changelog 流式消费
场景 2:混合负载(T+1 + 实时)
- 实时链路:Paimon 存最新 7 天数据
- 离线链路:Spark 每日构建宽表 → Iceberg
- 同步任务:Iceberg → Doris(每日凌晨导入)
- 优势:兼顾实时性与历史分析,成本可控
场景 3:传统数仓升级
- 旧 Hive 表 → Hudi(过渡期)
- 新链路 → Paimon + Doris
- 最终目标:Hudi 退场,全面转向湖仓一体
小技巧:Doris 2.0+ 支持 External Catalog,可直接读 Iceberg/Hudi 表(只读),实现“湖上查询”,但性能不如导入 Doris。
五、优化建议 & 避坑指南
优化建议
- Paimon 写入调优:
- 合理设置
bucket 数量,避免小文件
- 开启
changelog-producer=lookup 提升 Upsert 性能
- Iceberg 小文件合并:
- 定期运行
rewrite_data_files 任务
- 使用
Z-Order 或 Equality Delete 优化查询
- Doris 导入策略:
- 实时数据用 Routine Load(
Kafka)
- 批量数据用 Broker Load(HDFS/S3)
- 避免频繁小批量导入,合并成大批次
- 统一元数据管理:
- 使用 Hive Metastore 或 AWS Glue 管理 Hudi/Iceberg/Paimon 元数据
- Doris 通过 Catalog 对接,避免元数据孤岛
避坑指南(血泪经验)
| 坑点 |
正确做法 |
| 把 Doris 当数据湖用 |
错!Doris 存储成本高,只存热数据/聚合表 |
| Hudi + Flink 做大规模实时写入 |
易 OOM,State 管理差;改用 Paimon |
| Iceberg 直接接 Kafka 实时写 |
不支持;需通过 Flink/Spark 中转 |
| 忽略小文件问题 |
定期合并,否则查询性能暴跌 |
| Paimon 表不分桶,导致写倾斜 |
根据主键合理设置 bucket 数 |
| Doris 导入不加过滤,全量重刷 |
用分区替换或条件更新,避免资源浪费 |
六、总结:没有最好,只有最合适
- 如果你是 Flink 用户 + 要做实时数仓 → 选 Paimon + Doris
- 如果你是 Spark 用户 + 做 PB 级离线分析 → 选 Iceberg + Doris
- 如果你有 Hive 遗产 → Hudi 过渡,逐步迁移到 Paimon/Iceberg
- 如果你需要 高性能实时查询 → Doris 必上,但别让它存原始日志
未来的数据架构,不是“湖 or 仓”,而是“湖 + 仓”。
用数据湖承载灵活性,用 OLAP 引擎兑现性能承诺——这才是真正的湖仓一体。
希望这篇关于现代数据架构的解析能为你带来启发。如果你想了解更多关于大数据技术栈的深度讨论和实战经验,欢迎来云栈社区与其他开发者交流。 |  发表于 2026-1-13 23:15:21
|
查看: 300|
回复: 0
发表于 2026-1-13 23:15:21
|
查看: 300|
回复: 0
