在实时数据处理领域,Kafka 长期以来一直是流存储的事实标准。然而,阿里云实时计算 Flink 版产品专家黄睿指出,将 Kafka 用作流存储其实是一种“无奈之举”。这次分享将详细介绍阿里云流存储 Fluss,一个专为流式分析设计的新一代系统,以及它如何与 DLF(Paimon) 共同构建湖流一体架构,从根本上解决 Kafka 作为流存储的诸多问题。
主要内容包括:
- Kafka 作为流存储的三大痛点
- 阿里云流存储 Fluss:原生的流存储服务
- 实时宽表新范式:Delta Join 彻底改变双流 Join
- Fluss 三大核心能力:高性能、低成本、秒级延时
- 湖流一体:Fluss + DLF(Paimon) 构建统一存储
- 面向 AI 的湖流一体:实时特征工程新基础
- 客户案例:某头部车企车联网安全主动运维项目
- Fluss 公测邀请:免费体验下一代流存储
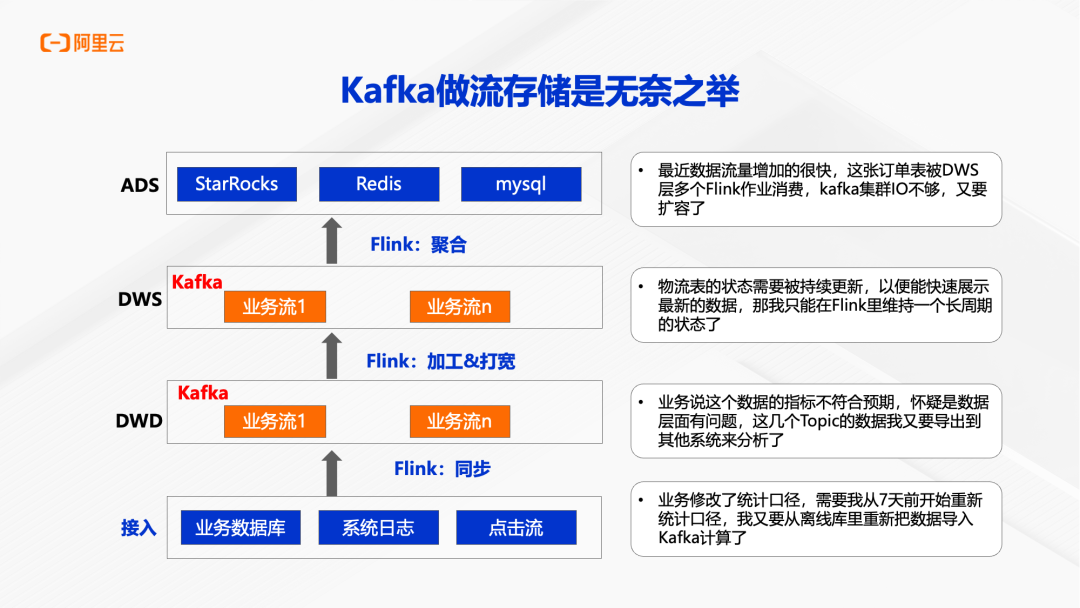
Kafka 作为流存储的三大痛点
在典型的实时数据架构中,Kafka 常被用作流存储层,但这种使用方式存在诸多问题。
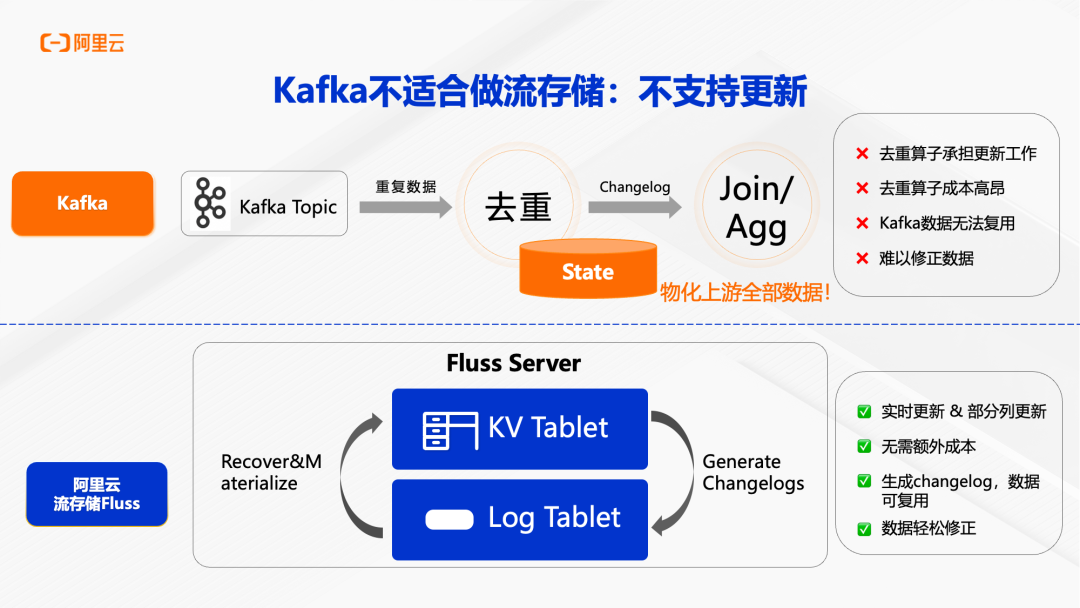
第一个痛点是不支持更新。 Kafka 只能追加写入,无法对已有数据进行更新。当业务数据库中的一条记录发生变更时,Kafka 只能再写入一条新记录,下游的 Flink 作业必须通过去重算子来维护数据的最新状态。这意味着 Flink 需要在 State 中物化上游的全部数据,成本高昂且容易成为性能瓶颈。当业务口径调整需要从历史数据重新计算时,还需要从离线库将数据重新导入 Kafka,整个流程非常繁琐。
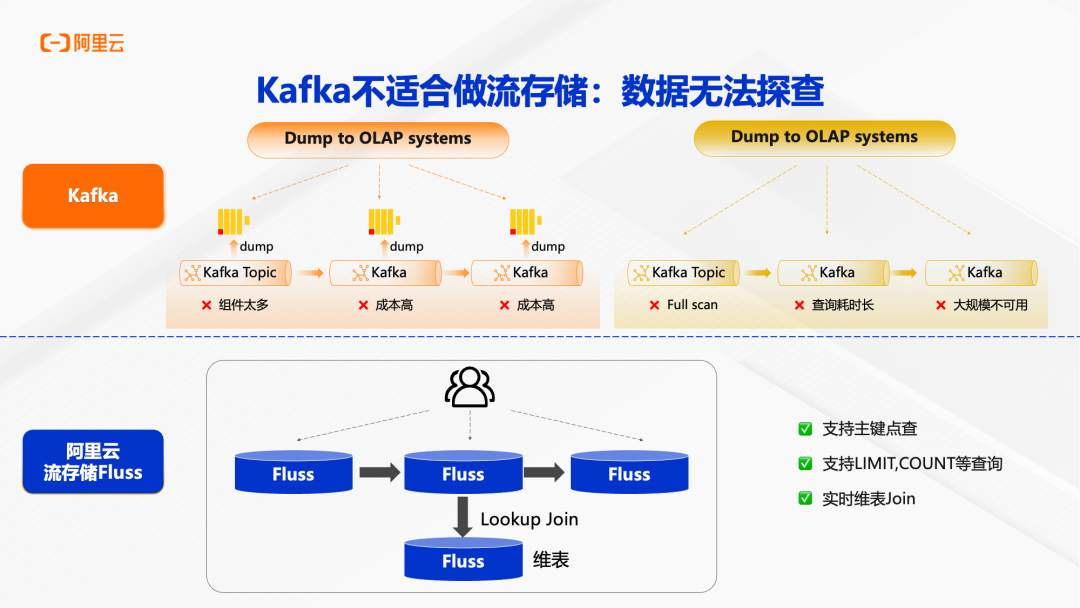
第二个痛点是数据无法探查。 Kafka 中的数据只能通过流式订阅消费,无法进行 SQL 查询或点查。当业务怀疑数据质量有问题时,需要将 Kafka 的数据导出到 OLAP 系统(如 StarRocks、Hologres)才能进行分析,这个过程不仅成本高、耗时长,而且在大规模场景下几乎不可用。对于维表 Join 场景,Kafka 也无法直接提供维表的点查能力,需要额外的组件支持。
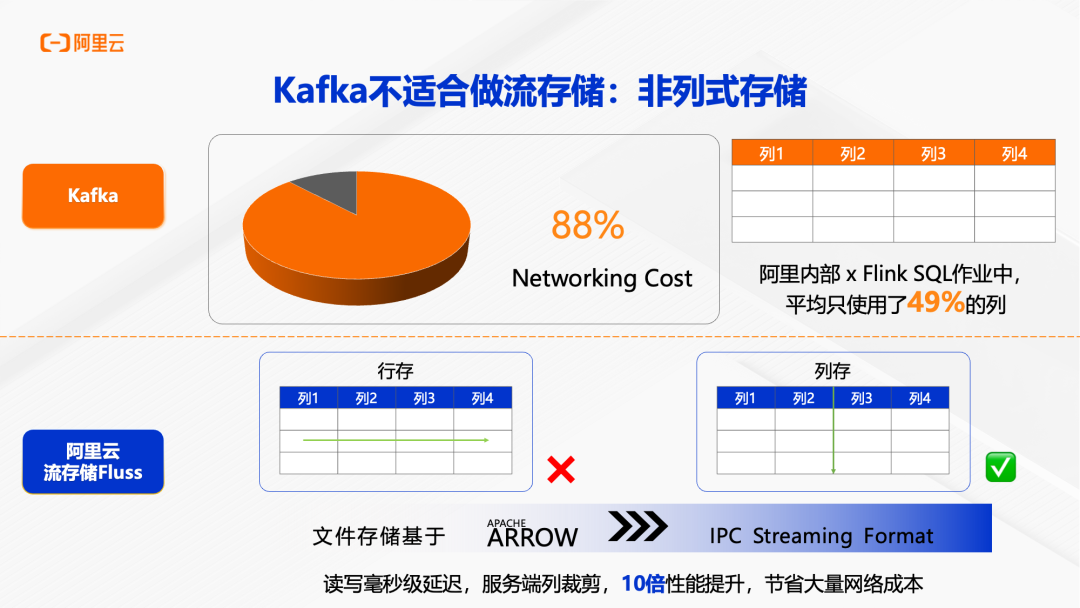
第三个痛点是 IO 开销巨大。 Kafka 采用行存储格式,而在阿里内部的统计中,Flink SQL 作业平均只使用了 49% 的列,这意味着有超过一半的数据读取是浪费的。行存储无法进行列裁剪,导致网络传输成本高昂,性能也受到严重影响。随着数据流量的增长,Kafka 集群的 IO 很快成为瓶颈,频繁需要扩容。
这些问题的根源在于 Kafka 的设计初衷是消息队列,而非流存储。当我们将其用作流存储时,本质上是在用一个不合适的工具解决问题。阿里云流存储 Fluss 正是为了从根本上解决这些痛点而设计的新一代流存储系统。
阿里云流存储 Fluss:原生的流存储服务
Fluss 从设计之初就定位为流存储,而非消息队列。它同时支持更新、变更日志订阅和列裁剪,从根本上解决了 Kafka 的三大痛点。
在更新支持方面,Fluss 的 KV Tablet 提供了原生的 Key-Value 存储能力,支持实时更新和部分列更新。上游数据库的变更可以直接在 Fluss 中进行更新,无需额外的去重算子。Fluss 会自动根据 KV 数据生成 Changelog(变更日志),下游系统可以订阅这些变更进行流式处理。这种设计使得 Flink 作业无需维护大状态,实现了状态与作业的解耦,大幅降低了成本并提升了稳定性。
在数据探查方面,Fluss 原生支持主键点查、LIMIT、COUNT 等 SQL 查询,可以像数据库一样对数据进行探查和分析。对于维表 Join 场景,Flink 可以直接对 Fluss 表进行 Lookup Join,无需额外组件。Fluss 的查询性能经过深度优化,具备条件下推、分析下推等分析型存储的特性。
在存储效率方面,Fluss 采用 Apache Arrow 列式存储格式,支持服务端列裁剪。当 Flink 作业只需要部分列时,Fluss 只会传输这些列的数据,大幅节省网络带宽。根据实测,列裁剪可以带来 10 倍的性能提升,对于宽表场景尤为明显。同时保证了读写延迟仍然在毫秒级别,满足实时性要求。
实时宽表新范式:Delta Join 彻底改变双流 Join
在传统的双流 Join 场景中,Flink 需要在 State 中维护两个流的全量数据,当其中一个流的数据量很大时,State 会成为严重的性能瓶颈。Checkpoint 耗时长、资源消耗大、状态恢复慢是常见问题,而且大状态作业的稳定性也难以保证。
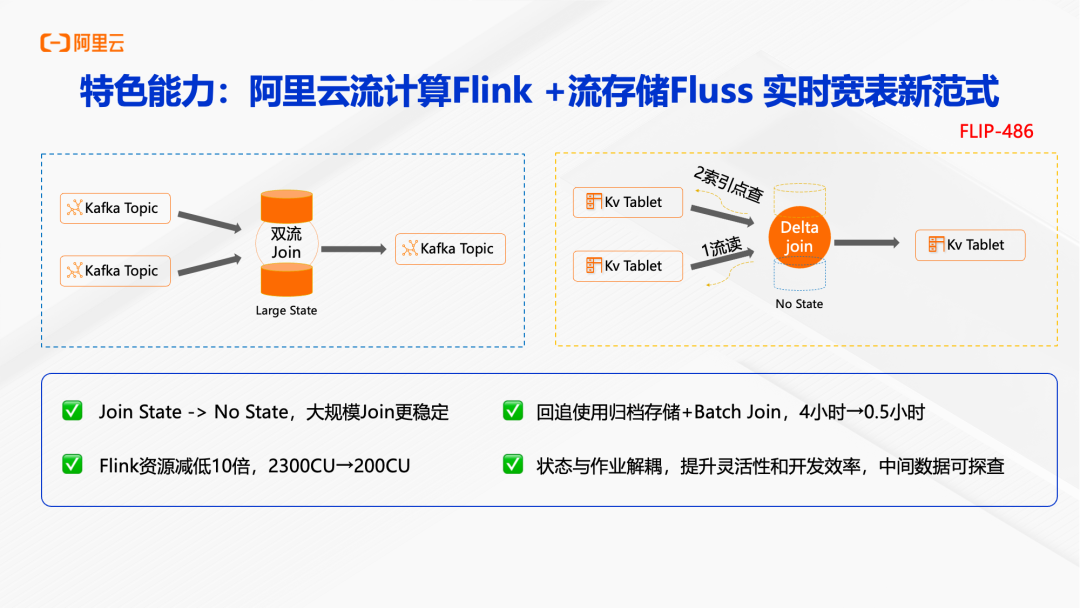
Fluss 引入的 Delta Join 机制彻底改变了这一局面。我们充分利用 Fluss 的 CDC 流读 + 索引点查的能力研发了一套新的 Flink 的 Join 算子实现,叫 Delta Join。Delta Join 可以简单理解成双边驱动的维表 Join,就是左边来了数据,就根据 joinkey 去点查右表;右边来了数据,就根据 joinkey 去点查左表。全程就像维表 Join 一样不需要 state,但是实现了双流 Join 一样的语义。
Delta Join 的优势非常明显。在实际案例中,100TB 大状态的作业,通过 Delta Join 将 Flink 资源从 2300CU 降低到 200CU,降低了 86%。Checkpoint 耗时从 90 秒降低到 1 秒,作业稳定性大幅提升。
对于需要历史数据回追的场景,Delta Join 可以利用 Fluss 的归档存储和 Batch Join 能力,将回追时间从 4 小时缩短到 0.5 小时。
更重要的是,Delta Join 实现了状态与作业的解耦。中间数据存储在 Fluss 中,可以被多个下游作业复用,也可以随时探查和分析。这种架构大幅提升了开发效率和灵活性,让实时宽表的构建变得简单高效。
Fluss 三大核心能力:高性能、低成本、秒级延时
阿里云流存储 Fluss 结合 Flink 实时计算,构建了高性能低成本的流处理完整方案,核心能力可以概括为三个方面。

实时宽表新方案 通过 Delta Join 机制,避免了大状态造成的高成本和稳定性问题。支持部分列更新,且更新后仍能生成 binlog 供下游订阅。支持基于主键的多流实时拼接,灵活构建宽表。对于超大规模的 Join 场景,这套方案已经在多个客户的生产环境中验证。
流查询下推能力 源于 Fluss 基于 Apache Arrow 的列存储设计。支持列裁剪、分区下推、条件下推、聚合下推等多种优化,大幅降低 IO 成本,实现 10 倍性能提升。对于分析型查询,这些下推优化可以将大量计算推到存储层执行,减少数据传输量,提升整体性能。
全链路秒级 是 Fluss 的重要特性。高吞吐、低延时的架构设计,支持实时更新和 binlog 订阅,数据写入即可见,端到端延迟可以达到秒级。这对于实时风控、实时推荐等对延迟敏感的业务场景至关重要。相比传统的 Lambda 架构需要维护实时和离线两条链路,Fluss 实现了真正的流批一体,一条链路同时满足实时和历史数据的查询需求。
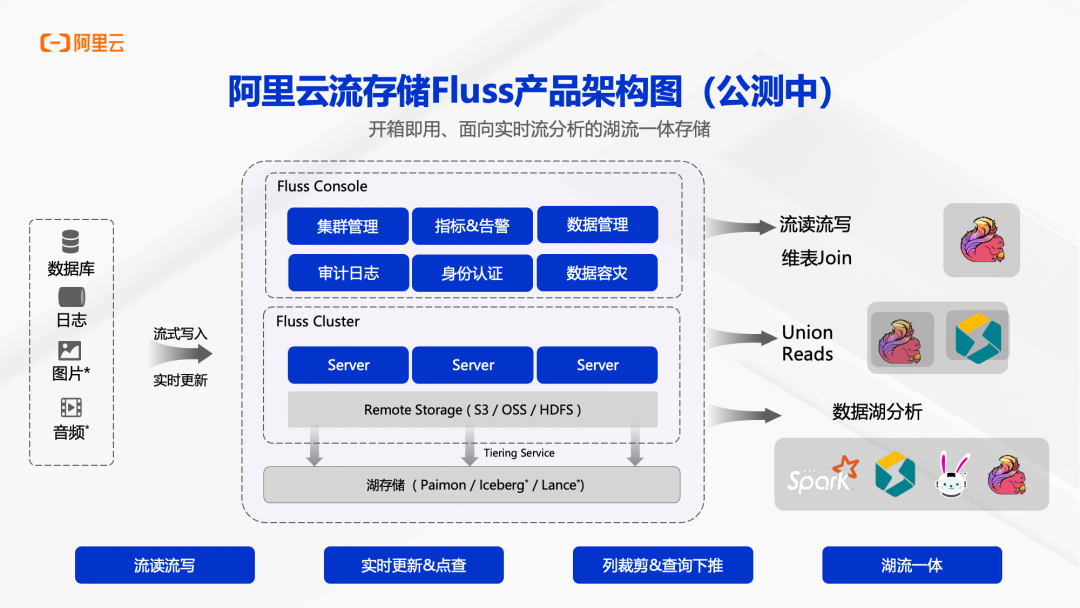
Fluss 产品架构采用 Serverless 设计,通过 Fluss Console 提供数据管理、指标告警、集群管理等完整的运维能力。底层的 Fluss Cluster 由多个 Server 节点组成,支持水平扩展。Remote Storage 层支持 S3、OSS、HDFS 等多种对象存储,Tiering Service 负责将热数据下沉到湖存储(Paimon/Iceberg/Lance),实现湖流一体。产品还提供了身份认证、审计日志、数据容灾等企业级功能,满足生产环境的严格要求。
湖流一体:Fluss + DLF(Paimon) 构建统一存储
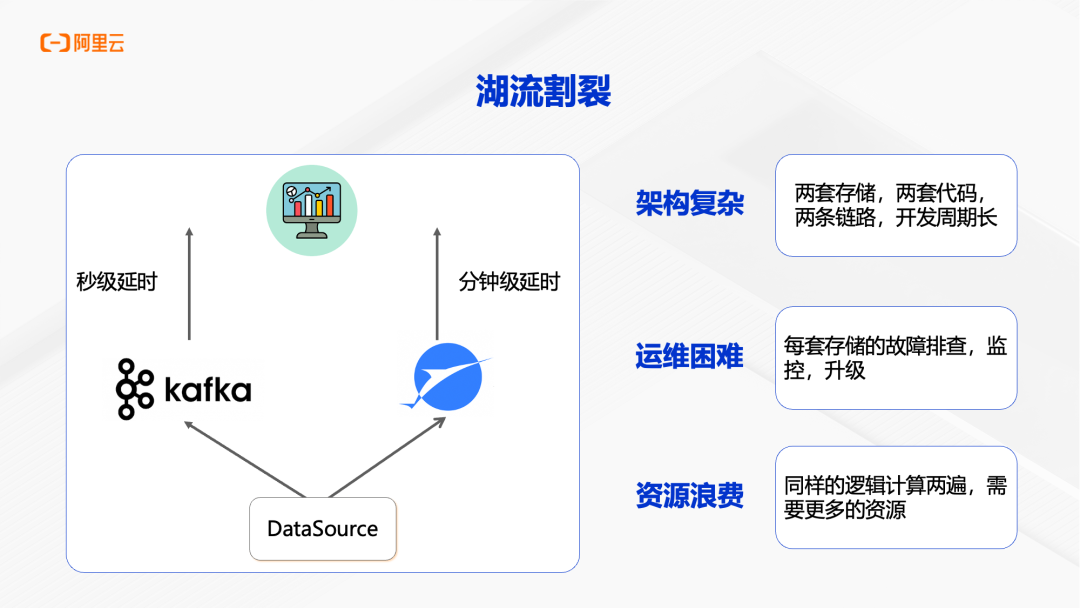
传统的实时架构面临“湖流割裂”的问题:实时数据存储在流存储(如 Kafka)中,历史数据存储在数据湖(如 Paimon)中,两套存储、两套代码、两条链路,开发周期长、架构复杂、运维困难、资源浪费。实时链路和离线链路之间还存在数据一致性问题,增加了系统的复杂度。
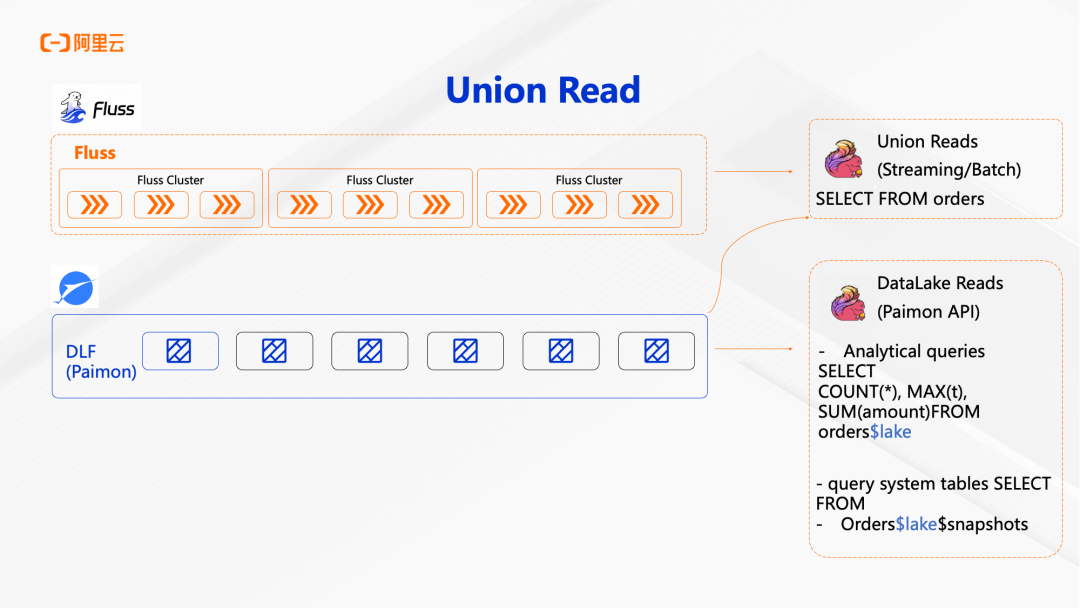
Fluss + DLF(Paimon) 方案通过湖流一体架构彻底解决了这一问题。实时数据层使用 Fluss Cluster 存储,通过 Tiering Service 自动将数据下沉到历史数据层 DLF(Paimon)。下游应用通过 Union Read 接口,可以统一读取 Fluss 中的实时数据和 Paimon 中的历史数据,对应用透明。

这套方案带来了显著的业务收益。首先,无需冗余存储,流存储的数据保留时间可以从传统的 5 天×24 小时大幅缩短到 1 小时,因为历史数据会自动归档到成本更低的湖存储。其次,延迟更低,湖上数据的可见时间是可配置的,可以根据业务需求灵活调整。再次,链路简化,开发运维成本更低,不需要维护两套系统和两套代码。
技术上,Fluss 内置了湖流通道服务,实现文件到文件的高效数据格式转换(Arrow 到 Parquet),Schema Evolution 等元数据变化也会自动同步。Union Read 支持流式和批式两种模式,可以从 Fluss 和 Paimon 统一读取数据。对于分析型查询,还可以直接查询 Paimon 的 System Tables,获取快照、分区等元数据信息,进行 COUNT、MAX、SUM 等聚合统计。
这种湖流一体架构实现了真正的流批统一,一份数据、一套代码、一条链路,同时满足实时和离线场景的需求,大幅降低了系统复杂度和运维成本。
面向 AI 的湖流一体:实时特征工程新基础
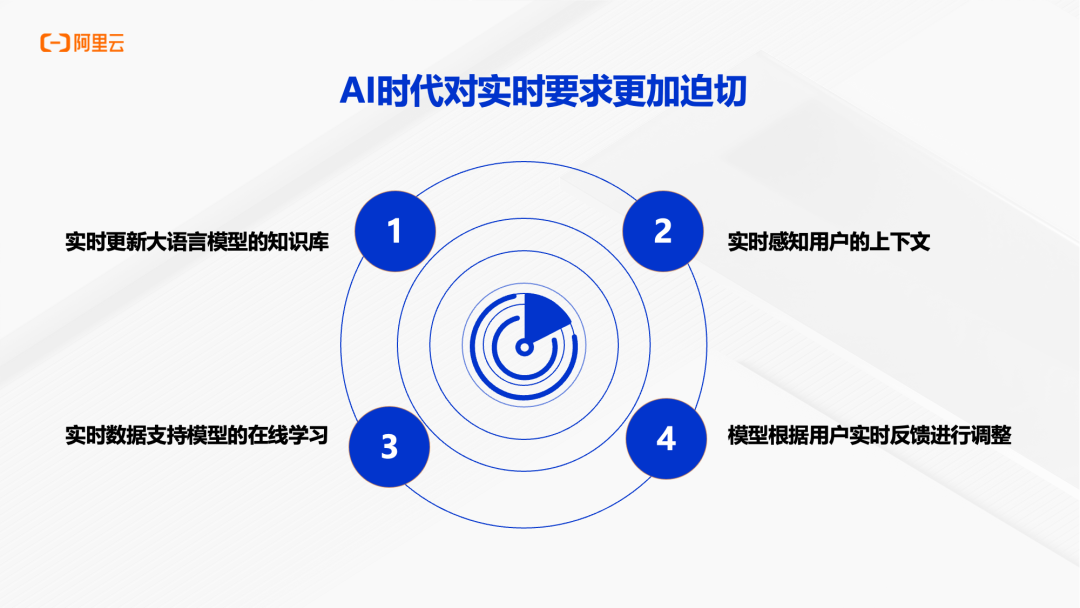
AI 时代对实时性的要求更加迫切,主要体现在四个方面:实时更新大语言模型的知识库、实时感知用户的上下文、实时数据支持模型的在线学习、模型根据用户实时反馈进行调整。这些需求都要求底层的数据架构具备实时数据处理和多模态数据管理能力。
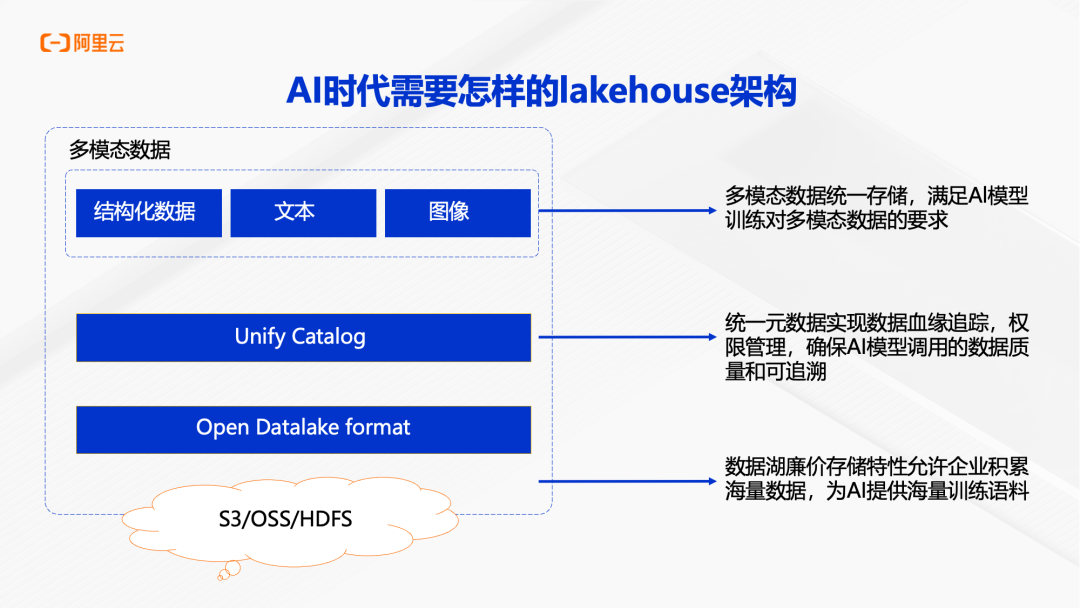
AI 时代的 Lakehouse 架构需要满足三个核心要求。第一,多模态数据的统一存储,包括文本、图像、音频、视频等,满足 AI 模型训练对多模态数据的要求。第二,统一元数据实现数据血缘追踪和权限管理,通过 Unify Catalog 确保 AI 模型调用的数据质量和可追溯性。第三,数据湖的廉价存储特性允许企业积累海量数据,为 AI 提供海量训练语料,同时 Open Datalake Format 保证了数据的开放性和生态兼容性。
Fluss + Lance 组合为 AI 数据湖提供了理想的解决方案。Fluss 作为实时层,支持高吞吐的实时特征写入和更新;Lance 作为湖存储层,提供多模态数据(Text、Images、Audio、Videos)的统一存储和高效查询。两者通过湖流一体架构无缝连接,实现了从实时特征工程到历史数据训练的完整链路。
Python 生态对 AI 应用至关重要,Fluss 和 Lance 都提供了 Python 原生接口,AI 工程师可以像操作本地数据一样访问湖流一体的数据。多模态实时 Agent 可以基于这套架构构建,实时获取最新的特征数据,进行在线推理和反馈优化。这种架构为 AI 应用提供了实时、完整、高质量的数据基础,是构建智能应用的关键基础设施。

客户案例:某头部车企车联网安全主动运维项目
在实际应用中,Fluss 已经在多个行业场景中验证了其技术价值。某头部车企的车联网安全主动运维项目是一个典型案例,充分展示了 Fluss 在高并发写入、多规则计算、湖流一体架构方面的优势。
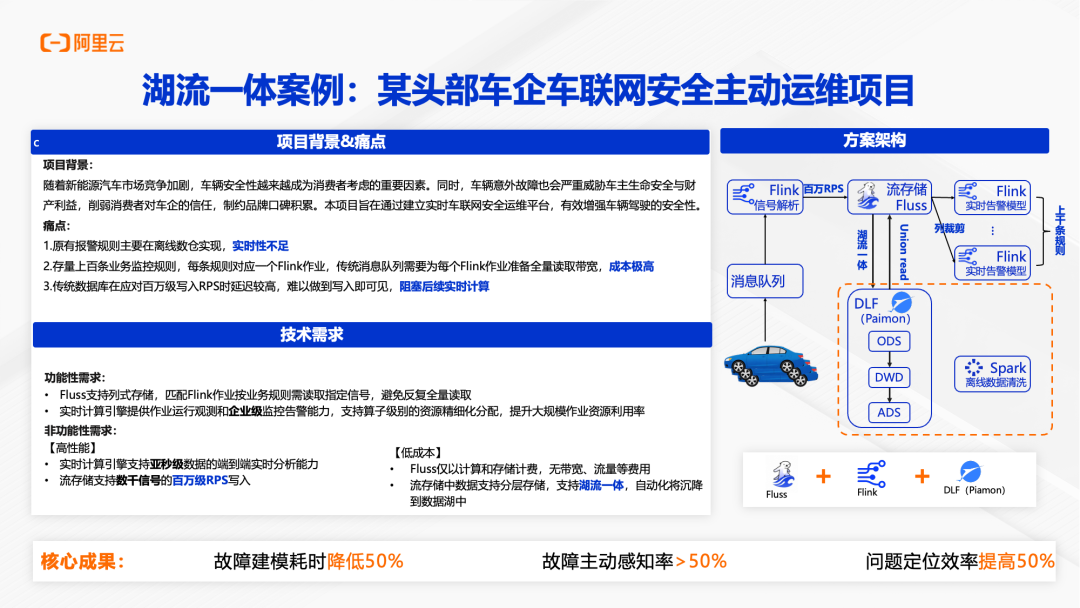
项目背景是随着新能源汽车市场竞争加剧,车辆安全性越来越成为消费者考虑的重要因素。车辆意外故障不仅威胁车主的生命安全和财产利益,也会削弱消费者对车企的信任。该项目旨在通过建立实时车联网安全运维平台,有效增强车辆驾驶的安全性。
原有方案面临三大痛点:报警规则主要在离线数仓实现,实时性不足;存量上百条业务监控规则,每条规则对应一个 Flink 作业,传统 Kafka 需要为每个作业准备全量读取带宽,成本极高;传统数据库在应对百万级写入 RPS 时延迟较高,难以做到写入即可见,阻塞后续实时计算。
采用 Fluss 方案后,架构得到了根本性优化。车辆信号通过 Flink 进行实时解析,写入 Fluss 流存储,支持百万 RPS 的高并发写入。上千条实时告警规则通过多个 Flink 作业并行执行,每个作业通过 Fluss 的列裁剪能力只读取需要的信号列,避免了全量读取的浪费。Fluss 支持 Union Read,可以统一查询实时数据和历史归档数据。历史数据通过湖流一体通道自动下沉到 DLF(Paimon),Spark 作业在 Paimon 上进行离线数据清洗和分析。
项目取得了显著成果:故障建模耗时降低 50%,通过实时数据分析可以更快地建立故障模型;故障主动感知率超过 50%,可以在故障发生前预警;问题定位效率提高 50%,通过实时数据探查快速定位问题根因。这些成果充分验证了 Fluss 在高并发、多任务、湖流一体场景下的技术优势。
Fluss 公测邀请:免费体验下一代流存储
阿里云流存储 Fluss 版正式开启免费公测,这是基于 Apache Fluss 打造的高性能列式流存储系统,具备毫秒级读写响应、实时数据更新及部分字段更新能力,可替换 Kafka 构建面向分析的流式存储,结合 DLF(Paimon) 等数据湖产品构建湖流一体架构。
公测期间,单用户可免费使用 2 个集群,单个集群上限 80 Core。如果您在使用过程中向阿里云提出改进建议或评测报告,阿里云将依据反馈内容的深度与质量,向优质测评者赠送定制的 Fluss 周边礼品。

Fluss 与 Flink、DLF(Paimon)、StarRocks 等产品深度集成,形成了完整的流式湖仓解决方案。流式数据更新提升数据新鲜度,在成本与延时方面具备显著优势。湖流一体的一体化流存储 + 湖存储架构,相比传统方案更加简洁高效。对于 Real-Time AI 场景,Fluss 还支持基于 LLM 的流式推理与 Agent 构建,为 AI 应用提供实时数据基础。
阿里云在流计算和流存储领域拥有多种场景的方案:Serverless Flink 提供全托管、100% 兼容开源的 Flink 服务,性能提升 200%;实时数仓解决方案 Flink+Hologres 提供极致性能;流式湖仓解决方案 Flink+DLF(Paimon)+StarRocks 在成本与延时方面具备显著优势;湖流一体解决方案 Flink+Fluss+DLF(Paimon) 代表了流式数据处理的未来方向。
欢迎加入钉钉交流群,与更多企业交流 Flink 和 Fluss 的使用经验,共同探索流式数据处理的最佳实践。
对于希望深入了解大数据技术演进和架构选型的开发者,可以到 云栈社区 的大数据板块进行交流讨论,这里有更多关于实时计算、数据湖等技术的深度内容分享。
 发表于 2026-2-13 03:45:34
|
查看: 224|
回复: 0
发表于 2026-2-13 03:45:34
|
查看: 224|
回复: 0
