说到高并发I/O,大家肯定会想到 Nginx 和 Kafka。一个能轻松扛住百万级并发请求,一个能支撑每秒百万条消息传输,它们到底靠什么“开挂”?其实答案很简单,高并发场景下的 I/O 性能瓶颈,核心破局就是今天要跟大家深度拆解的「零拷贝技术」。
一、为什么 Nginx、Kafka 能轻松扛住高吞吐?
咱们先拿最常见的 Web 服务器传输静态文件举例,传统 I/O 的操作流程,说出来你可能都会觉得“绕”。当客户端请求一个静态图片时,数据得先从磁盘通过 DMA 拷贝到内核缓冲区,接着 CPU 还要手动把数据从内核缓冲区搬到用户缓冲区,然后用户程序再把数据从用户缓冲区拷回内核的 socket 缓冲区,最后才由 DMA 把数据从 socket 缓冲区送到网卡,发给客户端。这一套下来,光是数据拷贝就有 4 次,还得加上多次上下文切换,CPU 全耗在“搬数据”上了,哪有精力处理真正的业务逻辑?高并发下能不卡吗?
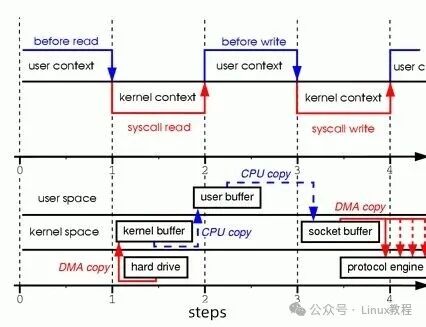
再看 Kafka,咱们平时用它传输海量日志,要是用传统 I/O,生产者发消息到 Broker,Broker 得先把数据从内核缓冲区拷到用户缓冲区,再拷回 socket 缓冲区才能发给消费者,不仅慢,还特别耗资源。而 Kafka 之所以快,就是因为用了零拷贝——结合 Page Cache 和 sendfile 系统调用,数据直接从内核缓存送到网卡,不经过用户空间,拷贝和切换次数直接减半,吞吐量自然就上去了。
由此可见,零拷贝技术通过减少数据拷贝和上下文切换,极大地提升了 I/O 性能,成为解决高并发 I/O 瓶颈的核心手段。接下来,我就从原理、实现方案到实战应用,一步步带大家吃透它,以后不管是优化项目性能,还是面试被问到,都能轻松应对。
二、传统 I/O 的 “致命缺陷”
在聊零拷贝之前,我们先来剖析传统 I/O 的工作流程,传统 I/O 到底差在哪?很多同学平时用 read/write 调用习惯了,觉得“能传数据就行”,但在数据传输过程中,却隐藏着多次数据拷贝和上下文切换的开销,这些开销在高并发场景下会被无限放大,成为制约系统性能的关键因素。
2.1 传统 read/write 的完整数据流路径
当我们执行一个简单的文件传输操作,比如将磁盘上的一个文件通过网络发送出去,传统 I/O 的流程其实特别繁琐:
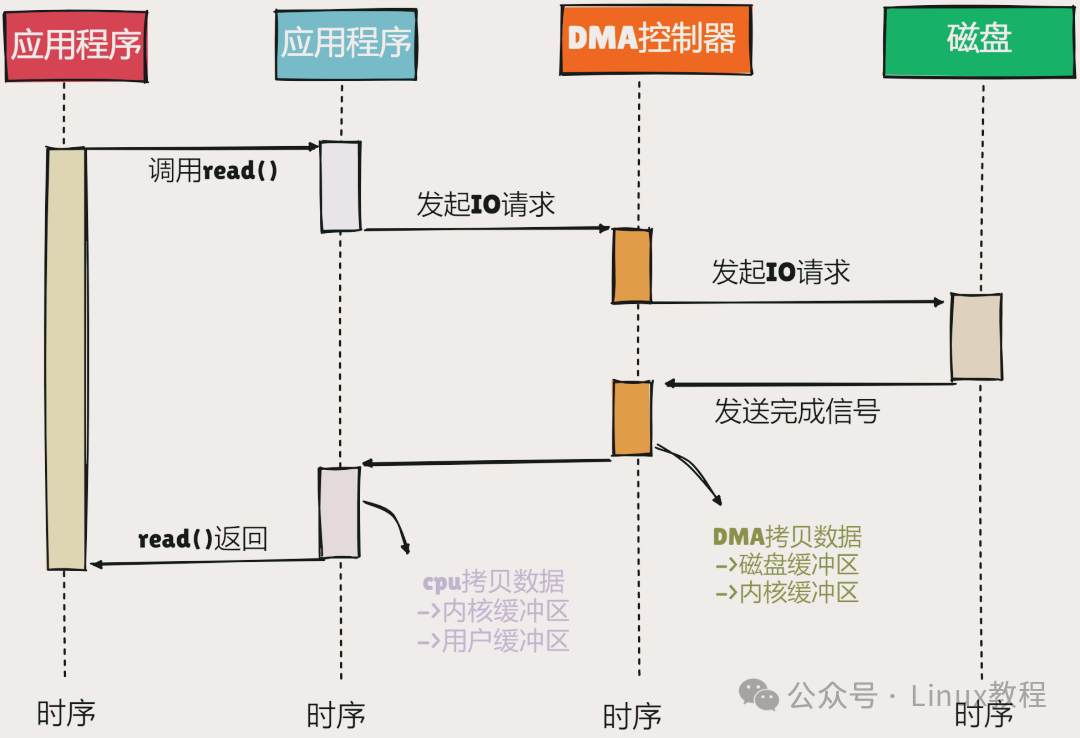
- 磁盘数据读取到内核缓冲区:应用程序调用
read 系统调用,操作系统内核通过 DMA(直接内存访问)技术,将磁盘数据直接拷贝到内核缓冲区。DMA 技术允许硬件设备(如磁盘控制器)直接访问内存,而不需要 CPU 的干预,这一步减轻了 CPU 的负担,但是数据仍然停留在内核空间。
- 内核缓冲区数据拷贝到用户缓冲区:由于用户空间和内核空间是相互隔离的,数据不能直接在两者之间传递。因此,CPU 需要将内核缓冲区中的数据拷贝到用户空间的应用程序缓冲区,这一步需要 CPU 的参与,增加了 CPU 的开销。
- 用户缓冲区数据拷贝到 socket 缓冲区:应用程序处理完数据后,调用
write 系统调用,请求将数据发送到网络。此时,数据需要从用户缓冲区拷贝到内核空间的 socket 缓冲区,准备通过网络发送出去,这一步同样需要 CPU 的参与。
- socket 缓冲区数据发送到网卡:最后,内核通过 DMA 技术,将 socket 缓冲区中的数据拷贝到网卡缓冲区,然后通过网络发送出去。
光说流程可能有点抽象,给大家放一段简单的代码示例,可以更直观地看到这个过程:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 1024
int main(){
int file_fd, socket_fd;
char buffer[BUFFER_SIZE];
ssize_t bytes_read, bytes_written;
// 打开文件
file_fd = open("example.txt", O_RDONLY);
if (file_fd == -1) {
perror("open file");
exit(EXIT_FAILURE);
}
// 创建socket
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
if (socket_fd == -1) {
perror("socket");
close(file_fd);
exit(EXIT_FAILURE);
}
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(8080);
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// 连接到服务器
if (connect(socket_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("connect");
close(file_fd);
close(socket_fd);
exit(EXIT_FAILURE);
}
// 读取文件数据并发送
while ((bytes_read = read(file_fd, buffer, BUFFER_SIZE)) > 0) {
bytes_written = write(socket_fd, buffer, bytes_read);
if (bytes_written == -1) {
perror("write");
break;
}
}
// 关闭文件和socket
close(file_fd);
close(socket_fd);
return 0;
}
大家看这段代码,read 函数负责把数据从内核缓冲区拷到用户缓冲区,write 函数再把数据从用户缓冲区拷到 socket 缓冲区,这两次 CPU 拷贝,就是传统 I/O 的“性能杀手”。
2.2 不可忽视的上下文切换成本
除了数据拷贝,传统 I/O 还有一个隐形开销——上下文切换。可能有同学对这个概念不太敏感,简单说就是:CPU 在用户态和内核态之间“来回切换”,每次切换都要保存当前任务的状态,再加载新任务的状态,特别耗时间。
- 第一次上下文切换:应用程序调用
read 系统调用,CPU 从用户态切换到内核态,开始执行内核中的代码,将磁盘数据读取到内核缓冲区。
- 第二次上下文切换:
read 系统调用返回,CPU 从内核态切换回用户态,应用程序可以处理用户缓冲区中的数据。
- 第三次上下文切换:应用程序调用
write 系统调用,CPU 再次从用户态切换到内核态,将用户缓冲区的数据拷贝到 socket 缓冲区。
- 第四次上下文切换:
write 系统调用返回,CPU 从内核态切换回用户态,数据传输完成。
频繁的上下文切换会带来额外的开销,包括保存和恢复寄存器的值、切换页表等操作,这些操作都会消耗 CPU 资源。在高并发场景下,大量的上下文切换会使 CPU 忙于处理这些切换操作,哪还有精力处理业务逻辑?这就是为什么传统 I/O 在高并发下,性能会急剧下降的核心原因。
传统 I/O 的四次数据拷贝和多次上下文切换,在高并发场景下成为了性能瓶颈。为了突破这一瓶颈,零拷贝技术应运而生——它的核心就是解决“拷贝多、切换多”的问题,把 CPU 从“搬数据”的体力活里解放出来。
三、零拷贝核心概念
聊到零拷贝,很多同学可能会有一个误解:是不是“完全不拷贝数据”?
其实不是的,我先跟大家澄清一下——零拷贝的核心,是“减少CPU参与的拷贝”,不是真的“零拷贝”。
搞懂这个概念,才算真正入门零拷贝。
3.1 零拷贝的本质定义
零拷贝(Zero-Copy),从严格意义上来说,并不是指数据完全不进行任何拷贝,而是一种通过操作系统内核优化,减少数据在用户空间(User Space)与内核空间(Kernel Space)之间冗余拷贝的技术。在传统的 I/O 操作中,数据往往需要在用户空间和内核空间之间多次拷贝,这不仅占用了大量的内存带宽,还消耗了 CPU 资源。而零拷贝技术的目标就是让数据尽可能地在内核空间中直接传输,避免不必要的 CPU 搬运。
还是拿文件传输举例,传统 I/O 里,数据从磁盘读到内核缓冲区后,要经过 CPU 两次拷贝,才能到 socket 缓冲区;而零拷贝的思路,就是让数据从内核缓冲区直接到 socket 缓冲区,甚至直接从磁盘到网卡,不经过用户空间,这样就省去了 CPU 的两次拷贝,效率自然就上去了。
总结一下,零拷贝的核心目标就三个,大家记好:
- 减少数据拷贝次数:核心就是省去用户态和内核态之间的冗余拷贝,最好能做到“零CPU拷贝”。
- 减少上下文切换次数:少调用一次系统调用,就少一次上下文切换,CPU就能多处理点有用的事。
- 避免内存冗余占用:数据不用在用户缓冲区和内核缓冲区重复存储,节省内存,也减少了数据管理的麻烦。
3.2 零拷贝的两大技术支撑
零拷贝技术的实现,离不开两个“底层帮手”——DMA(直接内存访问) 和内存映射。这两种技术为零拷贝提供了底层的技术保障,使得数据能够高效地传输,减少 CPU 的参与。
DMA(直接内存访问)技术:大家可以把 DMA 理解成“CPU 的助理”,专门帮 CPU 处理“搬数据”的活。以前没有 DMA 的时候,磁盘、网卡和内存之间传数据,都要 CPU 全程盯着,逐字节搬运,CPU 根本没时间干别的;有了 DMA 之后,CPU 只要告诉 DMA “要搬什么数据、从哪搬到哪”,DMA 就会自己完成传输,CPU 可以去执行其他任务,实现“并行工作”,效率直接翻倍。
比如读取磁盘文件时,CPU 只要初始化 DMA 控制器,设置好传输参数,DMA 就会把磁盘数据直接读到内核缓冲区,全程不用 CPU 插手——这也是零拷贝能“省CPU”的基础。
内存映射技术:这个技术更关键,它能让内核空间和用户空间“共享一块内存”。简单说,就是通过 mmap 系统调用,把磁盘文件映射到用户进程的虚拟内存里,这样用户程序就能像访问内存一样,直接访问内核缓冲区里的数据,不用再做“内核→用户”的拷贝。
比如咱们频繁读取一个大文件,用 mmap 映射之后,数据不用每次都从磁盘读到内核,再拷到用户缓冲区,直接在内存里操作就行,速度快很多。而且因为是“共享内存”,也省去了拷贝的冗余,内存利用率也更高。
简单总结一下:DMA 负责“帮CPU搬数据”,减少 CPU 的参与;内存映射负责“让用户态和内核态共享数据”,避免冗余拷贝。两者配合,才让零拷贝成为可能。
四、Linux 零拷贝的四大实现方案
Linux 系统里,零拷贝有多种实现方案,今天和大家拆解最常用的 4 种。
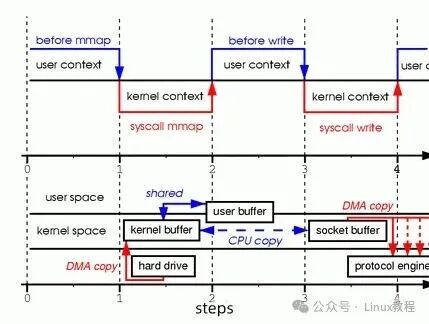
4.1 mmap + write:内存映射,减少一次 CPU 拷贝
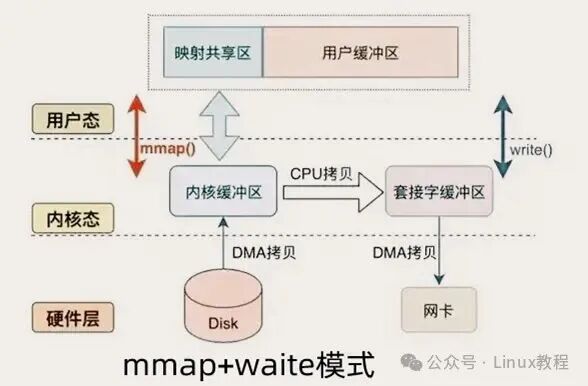
mmap 应该是大家最熟悉的零拷贝方案之一了,它的核心思路很简单:把内核缓冲区和用户缓冲区做“内存映射”,让用户程序直接访问内核数据,省去“内核→用户”的 CPU 拷贝。其工作流程如下:
- 内存映射:应用程序调用
mmap,把磁盘文件映射到用户空间的虚拟内存。这时候,内核会用 DMA 把文件数据读到内核缓冲区,然后建立“虚拟内存地址→内核缓冲区”的映射——注意,这时候数据还没拷贝到用户空间,用户程序只是能“看到”内核缓冲区的数据。
- 数据传输:调用
write 系统调用,把数据“写”到 socket 缓冲区。因为有了内存映射,这一步其实是直接把内核缓冲区的数据,拷贝到 socket 缓冲区,省去了“内核→用户”的拷贝。
- DMA 发送:最后,内核用 DMA 把 socket 缓冲区的数据发到网卡,完成传输。
对比传统 I/O,mmap+write 直接省去了一次 CPU 拷贝,大数据量传输时,性能提升很明显。
给大家放一段实战代码,大家可以直接参考:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#define BUFFER_SIZE 1024
int main(){
int file_fd, socket_fd;
struct stat st;
char *map_start;
ssize_t bytes_written;
// 打开文件
file_fd = open("example.txt", O_RDONLY);
if (file_fd == -1) {
perror("open file");
exit(EXIT_FAILURE);
}
// 获取文件状态(拿到文件大小)
if (fstat(file_fd, &st) == -1) {
perror("fstat");
close(file_fd);
exit(EXIT_FAILURE);
}
// 创建socket
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
if (socket_fd == -1) {
perror("socket");
close(file_fd);
exit(EXIT_FAILURE);
}
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(8080);
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// 连接到服务器
if (connect(socket_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("connect");
close(file_fd);
close(socket_fd);
exit(EXIT_FAILURE);
}
// 内存映射文件(核心步骤)
map_start = mmap(NULL, st.st_size, PROT_READ, MAP_PRIVATE, file_fd, 0);
if (map_start == MAP_FAILED) {
perror("mmap");
close(file_fd);
close(socket_fd);
exit(EXIT_FAILURE);
}
// 直接写入socket(本质是内核缓冲区→socket缓冲区)
bytes_written = write(socket_fd, map_start, st.st_size);
if (bytes_written == -1) {
perror("write");
}
// 取消内存映射(必须做,避免内存泄漏)
if (munmap(map_start, st.st_size) == -1) {
perror("munmap");
}
// 关闭文件和socket
close(file_fd);
close(socket_fd);
return 0;
}
不过这里要提醒大家,mmap+write 有个隐藏坑,很多同学第一次用都会踩——如果你的程序正在用 mmap 映射文件、调用 write 发送数据,这时候另一个进程截断了这个文件,你的 write 调用会被 SIGBUS 信号中断,直接杀死进程,还会生成内核转储,特别麻烦。
给大家说两种解决方案,推荐第二种,更规范:第一种是给 SIGBUS 信号装个处理程序,中断后直接 return,让 write 返回已写入的字节数,但这只是“治标不治本”,毕竟 SIGBUS 是严重错误信号,不建议这么做。
第二种是用内核文件租赁(Windows 里叫“机会锁定”),这才是正确解法。简单说,就是在 mmap 之前,向内核申请“读/写租约”,如果有其他进程想截断文件,内核会先给你发一个 RT_SIGNAL_LEASE 信号,让你的 write 调用先中断,避免被 SIGBUS 杀死。
下面是示例代码,表示怎么从内核获取一个租约:
// 设置租约信号
if(fcntl(fd, F_SETSIG, RT_SIGNAL_LEASE) == -1) {
perror("kernel lease set signal");
return -1;
}
/* l_type可以是F_RDLCK(读租约)、F_WRLCK(写租约),根据需求选 */
if(fcntl(fd, F_SETLEASE, l_type)){
perror("kernel lease set type");
return -1;
}
记住,租约要在 mmap 之前申请,用完之后一定要用 F_UNLCK 类型调用 fcntl,撕毁租约,避免资源泄漏。
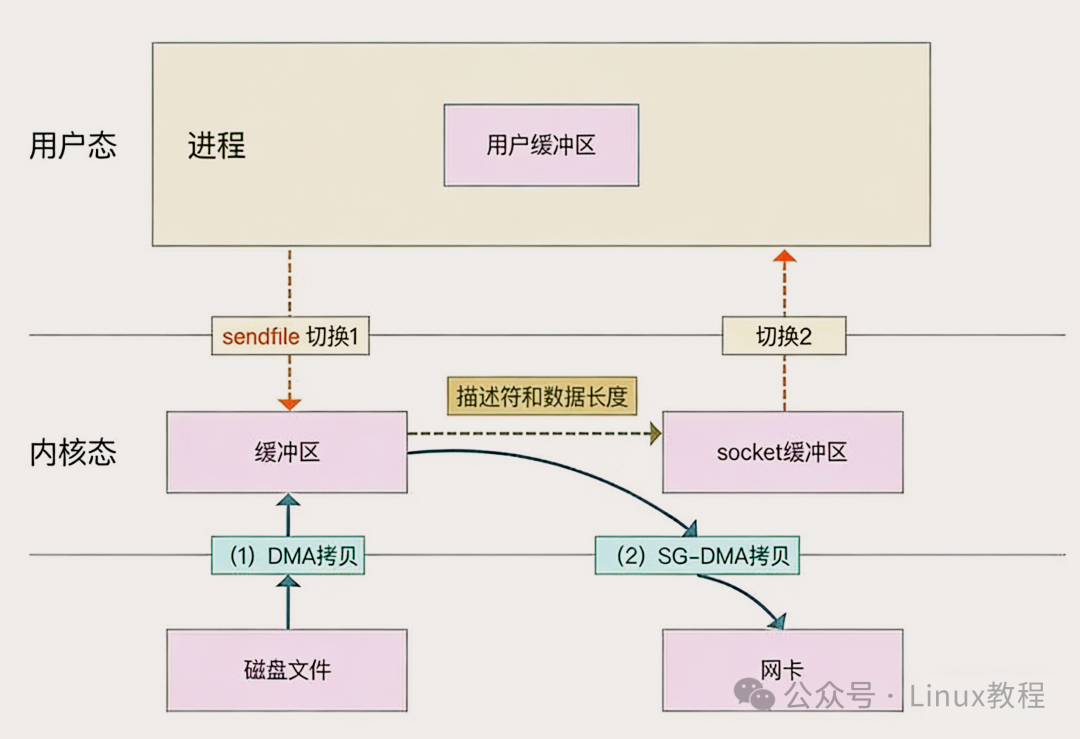
4.2 sendfile:内核态直接传输,专为文件到套接字设计
sendfile 系统调用是 Linux 2.1 引入的,用于简化网络通过两个通道之间的数据传输过程,它可以直接在内核空间进行 I/O 传输,省去了用户空间和内核空间之间的数据拷贝,极大地提高了数据传输效率。
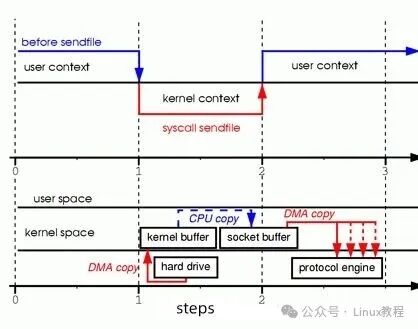
它的工作原理特别简单:
- 数据读取:当应用程序调用
sendfile 时,内核通过 DMA 将文件数据从磁盘读取到内核缓冲区(Page Cache)。
- 数据传输:内核直接将内核缓冲区中的数据拷贝到 socket 缓冲区,这个过程不需要用户空间的参与,数据直接在内核空间中传输。
- 数据发送:最后,内核通过 DMA 将 socket 缓冲区的数据发送到网卡,完成数据的传输。
sendfile 的函数原型如下:
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
out_fd:目标文件描述符,通常是一个 socket 文件描述符,数据将被发送到这个描述符对应的套接字。in_fd:源文件描述符,必须是一个支持 mmap 的普通文件描述符,数据将从这个文件中读取。offset:指向一个 off_t 类型的变量,用于指定从源文件的哪个位置开始读取数据。如果为 NULL,则从当前文件偏移量开始读取,并且读取后会更新文件偏移量;如果不为 NULL,则从offset 指定的字节位置开始读取,此时 in_fd 的文件偏移量不会被修改,而offset 的值会在 sendfile 返回时被更新为新的偏移量(即 offset = offset + number of bytes sent)。count:指定要传输的最大字节数。
以下是一个使用 sendfile 的简单示例,展示了如何将一个文件的内容发送到 socket:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/sendfile.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#define PORT 8080
int main(){
int in_fd, out_fd;
struct stat st;
off_t offset = 0;
ssize_t bytes_sent;
// 打开源文件(必须是普通文件)
in_fd = open("example.txt", O_RDONLY);
if (in_fd == -1) {
perror("open file");
exit(EXIT_FAILURE);
}
// 获取文件大小,用于指定传输字节数
if (fstat(in_fd, &st) == -1) {
perror("fstat");
close(in_fd);
exit(EXIT_FAILURE);
}
// 创建socket(目标描述符必须是socket)
out_fd = socket(AF_INET, SOCK_STREAM, 0);
if (out_fd == -1) {
perror("socket");
close(in_fd);
exit(EXIT_FAILURE);
}
struct sockaddr_in server_addr;
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// 连接到服务器
if (connect(out_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("connect");
close(in_fd);
close(out_fd);
exit(EXIT_FAILURE);
}
// 核心:用sendfile直接传输,全程内核态
bytes_sent = sendfile(out_fd, in_fd, &offset, st.st_size);
if (bytes_sent == -1) {
perror("sendfile");
}
// 关闭文件和socket
close(in_fd);
close(out_fd);
return 0;
}
sendfile 的优势很明显:减少了两次上下文切换(比传统 I/O 少两次),还省去了用户态和内核态的拷贝,效率极高。但它的限制也很突出:不能在用户态修改数据(比如加密、压缩),因为数据不经过用户空间;而且源文件必须是普通文件,目标必须是 socket,适用场景比较单一。
4.3 sendfile + DMA 聚集:真正的 “零 CPU 拷贝”
Linux 2.4 版本的内核对 sendfile 系统调用进行了改进,引入了 DMA gather 操作,进一步提升了零拷贝的性能,实现了真正意义上的 “零 CPU 拷贝”。在传统的 sendfile 实现中,虽然数据可以直接在内核空间从文件传输到 socket 缓冲区,但在内核缓冲区到 socket 缓冲区这一步,仍然需要 CPU 参与数据拷贝。而 DMA 聚集技术的出现,改变了这一现状。
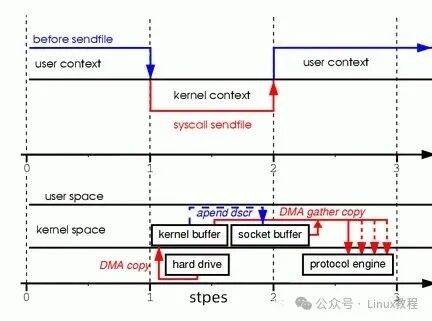
其工作原理如下:
- 数据读取:内核通过 DMA 将文件数据从磁盘读取到内核缓冲区(Page Cache),这一步与传统
sendfile 相同。
- 描述信息传递:当数据需要从内核缓冲区传输到 socket 缓冲区时,内核不再直接进行数据拷贝,而是将内核缓冲区中数据的地址和长度信息记录到 socket 缓冲区。这里的关键在于,网卡支持 DMA 聚集功能,它能够根据这些地址和长度信息,直接从内核缓冲区中读取数据。
- DMA 发送:网卡通过 DMA 直接从内核缓冲区中读取数据,并将其发送出去。整个过程中,CPU 不需要参与数据的拷贝操作,真正实现了 “零 CPU 拷贝”。
通过这种方式,sendfile + DMA 聚集不仅减少了数据拷贝的次数,还进一步降低了 CPU 的负载,提高了系统的整体性能。在高并发、大数据量传输的场景下,这种优化效果尤为显著。例如,在大规模的文件下载服务中,大量用户同时请求下载文件,使用 sendfile + DMA 聚集技术可以大大减轻服务器的 CPU 压力,提高文件传输的效率,确保每个用户都能获得快速、稳定的下载体验。
4.4 splice:管道助力,支持任意文件描述符的零拷贝
sendfile 的限制太多(源必须是普通文件,目标必须是 socket),如果大家需要在“任意两个文件描述符”之间传输数据,比如“socket→文件”“管道→socket”,那 splice 就很合适——它是 Linux 2.6.17 引入的,核心是用管道做中介,实现内核态的直接传输。
它的工作原理不难理解,就是用管道“搭桥”,让数据在内核态直接流转:
- 创建管道:先创建一个管道,管道有两个描述符——读端(
pipe[0])和写端(pipe[1]),这是 splice 的核心中介。
- 数据传输到管道:用
splice 把源描述符(比如文件、socket)的数据,传到管道的写端。这一步全程在内核态,不用经过用户空间。
- 数据从管道传输到目标:再用
splice 把管道读端的数据,传到目标描述符(比如 socket、文件),同样在内核态完成,没有 CPU 拷贝。
先给大家看 splice 的函数原型,参数比 sendfile 多一点,重点看 flags:
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
fd_in:输入文件描述符(可以是文件、socket、管道)。off_in:输入文件的偏移量,如果 fd_in 不是普通文件(比如 socket),设为 NULL 即可。fd_out:输出文件描述符(和 fd_in 一样,支持多种类型)。off_out:输出文件的偏移量,非普通文件设为 NULL。len:要传输的数据长度。flags:控制行为,常用的有 3 个:SPLICE_F_NONBLOCK(非阻塞模式)、SPLICE_F_MORE(提示后续还有数据,优化 TCP 聚包)、SPLICE_F_MOVE(尽量移动页所有权,现代内核基本忽略)。
这里要重点提醒大家 splice 的限制:两个文件描述符中,至少有一个是管道。这是它的核心要求,也是唯一的大限制。比如我们要实现“socket 接收数据→写入文件”,就可以用 splice+管道,全程零拷贝,比传统 I/O 快很多。
给大家放一段实战代码,实现“socket 接收数据,通过 splice 写入文件”:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#define PORT 8080
#define BUFFER_SIZE 4096
int main(){
int sock_fd, client_fd, file_fd, pipe_fd[2];
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
ssize_t bytes_transferred;
// 1. 创建socket
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 绑定端口
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
if (bind(sock_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("bind");
close(sock_fd);
exit(EXIT_FAILURE);
}
// 监听
if (listen(sock_fd, 10) == -1) {
perror("listen");
close(sock_fd);
exit(EXIT_FAILURE);
}
// 2. 创建管道(splice必须有一个描述符是管道)
if (pipe(pipe_fd) == -1) {
perror("pipe");
close(sock_fd);
exit(EXIT_FAILURE);
}
// 3. 接收客户端连接
client_fd = accept(sock_fd, (struct sockaddr *)&client_addr, &client_len);
if (client_fd == -1) {
perror("accept");
close(sock_fd);
close(pipe_fd[0]);
close(pipe_fd[1]);
exit(EXIT_FAILURE);
}
// 4. 打开目标文件(用于写入接收的数据)
file_fd = open("recv_data.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (file_fd == -1) {
perror("open file");
close(sock_fd);
close(client_fd);
close(pipe_fd[0]);
close(pipe_fd[1]);
exit(EXIT_FAILURE);
}
// 5. 用splice传输数据:client_fd → 管道写端 → 管道读端 → file_fd
while (1) {
// 第一步:socket数据 → 管道写端
bytes_transferred = splice(client_fd, NULL, pipe_fd[1], NULL, BUFFER_SIZE, SPLICE_F_MORE);
if (bytes_transferred <= 0) break; // 传输完成或出错
// 第二步:管道读端 → 文件
bytes_transferred = splice(pipe_fd[0], NULL, file_fd, NULL, bytes_transferred, 0);
if (bytes_transferred <= 0) break;
}
// 关闭所有文件描述符
close(sock_fd);
close(client_fd);
close(file_fd);
close(pipe_fd[0]);
close(pipe_fd[1]);
return 0;
}
4.5 用户态直接 I/O:绕过内核缓冲区,适合自缓存应用
最后一种零拷贝方案,比较特殊——用户态直接 I/O。它的核心思路是“绕开内核缓冲区”,让应用程序直接和硬件存储(比如磁盘)交互,数据不经过内核,自然也就没有内核和用户态的拷贝。
传统 I/O 里,数据要经过“磁盘→内核缓冲区→用户缓冲区”,而用户态直接 I/O,直接跳过内核缓冲区,变成“磁盘→用户缓冲区”,省去了内核缓冲区的中转,也减少了一次拷贝。
这种方案最适合什么场景呢?就是那些自身有缓存机制的应用,比如数据库(MySQL、PostgreSQL)。数据库会在用户空间维护自己的缓存,不需要内核缓冲区再做一次缓存——如果用传统 I/O,数据先到内核缓冲区,再拷到数据库缓存,纯属浪费资源;而用户态直接 I/O,数据直接进入数据库缓存,效率大幅提升。
不过大家要注意,用户态直接 I/O 也有明显的局限:第一,它直接操作磁盘 I/O,没有内核缓冲区的优化,小数据量频繁读写时,性能反而不如传统 I/O;第二,应用程序要自己处理很多底层细节,比如 I/O 错误、设备驱动,开发难度更高;第三,为了避免 CPU 浪费,通常要配合异步 I/O(AIO)使用,让 CPU 在 I/O 传输时能做其他事。
一起来看一段用户态直接 I/O 的实战代码,以“直接读取磁盘文件”为例:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#define BUFFER_SIZE 4096
int main(){
int file_fd;
char *buffer;
ssize_t bytes_read;
// 1. 分配内存缓冲区(必须是页对齐的,否则直接I/O会失败)
if (posix_memalign((void **)&buffer, getpagesize(), BUFFER_SIZE) != 0) {
perror("posix_memalign");
exit(EXIT_FAILURE);
}
// 2. 打开文件,设置O_DIRECT标志,开启用户态直接I/O
file_fd = open("example.txt", O_RDONLY | O_DIRECT);
if (file_fd == -1) {
perror("open file");
free(buffer);
exit(EXIT_FAILURE);
}
// 3. 直接读取文件(数据不经过内核缓冲区)
bytes_read = read(file_fd, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
perror("read");
} else {
printf("Read %zd bytes: %.*s\n", bytes_read, (int)bytes_read, buffer);
}
// 4. 关闭文件,释放缓冲区
close(file_fd);
free(buffer);
return 0;
}
五、零拷贝的实战应用场景
聊完了原理和实现方案,大家最关心的肯定是:实际开发中,哪些场景能用零拷贝?用了之后能提升多少性能?
接下来,我就结合 3 个最常见的实战场景,给大家讲清楚。
5.1 Web 服务器:Nginx 开启 sendfile 提升静态文件传输效率
在 Web 服务器领域,Nginx 以其高性能和低资源消耗而闻名,其中零拷贝技术功不可没。Nginx 通过配置 sendfile 指令来启用零拷贝功能,这一配置在处理静态文件传输时发挥了关键作用。
当客户端请求 Nginx 服务器上的静态文件(如 HTML、CSS、JavaScript、图片等)时,若开启了 sendfile,Nginx 会直接将磁盘上的文件数据从内核页缓存(Page Cache)传输到套接字(Socket),而无需将数据拷贝到用户空间。具体过程如下:
- 文件读取:内核首先通过 DMA 将磁盘上的静态文件数据读取到内核缓冲区(Page Cache),这一步利用了内核的页缓存机制,将经常访问的文件数据缓存在内核空间,提高后续访问的速度。
- 数据传输:Nginx 调用
sendfile 系统调用,直接将内核缓冲区中的数据拷贝到 socket 缓冲区,这个过程完全在内核空间进行,不需要用户空间的参与,避免了传统 I/O 中数据从内核缓冲区到用户缓冲区再到 socket 缓冲区的多次拷贝。
- 数据发送:最后,内核通过 DMA 将 socket 缓冲区的数据发送到网卡,完成数据的传输。
通过开启 sendfile,Nginx 减少了数据拷贝的次数和上下文切换的次数,大大提升了静态资源的响应速度。在高并发场景下,大量的客户端同时请求静态文件,传统的 I/O 方式会导致 CPU 忙于数据拷贝和上下文切换,而开启 sendfile 的 Nginx 则可以将更多的 CPU 资源用于处理其他任务,从而显著提高了服务器的吞吐量和并发处理能力。这也是 Nginx 能够在高并发场景下保持高性能的关键配置之一,使得它成为了众多大型网站和应用的首选 Web 服务器。
下面是一段“模拟 Nginx 静态文件传输”的 C 语言案例代码,基于 sendfile 实现,帮大家理解底层逻辑:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/sendfile.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <string.h>
#define PORT 80
#define DOC_ROOT "/usr/share/nginx/html" // 静态文件根目录
// 发送HTTP响应头
void send_response_header(int client_fd, int status_code, const char *content_type, off_t file_size){
char header[1024];
snprintf(header, sizeof(header),
"HTTP/1.1 %d OK\r\n"
"Content-Type: %s\r\n"
"Content-Length: %lld\r\n"
"Connection: close\r\n\r\n",
status_code, content_type, (long long)file_size);
write(client_fd, header, strlen(header));
}
// 获取文件的Content-Type
const char *get_content_type(const char *filename){
if (strstr(filename, ".html")) return "text/html";
if (strstr(filename, ".css")) return "text/css";
if (strstr(filename, ".js")) return "application/javascript";
if (strstr(filename, ".png")) return "image/png";
if (strstr(filename, ".jpg") || strstr(filename, ".jpeg")) return "image/jpeg";
return "application/octet-stream"; // 默认类型
}
int main(){
int sock_fd, client_fd, file_fd;
struct sockaddr_in server_addr, client_addr;
socklen_t client_len = sizeof(client_addr);
char request[1024];
char filename[256];
struct stat st;
off_t offset = 0;
// 1. 创建socket
sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 2. 绑定端口,设置地址复用
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT);
server_addr.sin_addr.s_addr = INADDR_ANY;
int opt = 1;
setsockopt(sock_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
if (bind(sock_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) == -1) {
perror("bind");
close(sock_fd);
exit(EXIT_FAILURE);
}
// 3. 监听客户端连接
if (listen(sock_fd, 100) == -1) {
perror("listen");
close(sock_fd);
exit(EXIT_FAILURE);
}
printf("Static file server running on port %d...\n", PORT);
while (1) {
// 4. 接收客户端连接
client_fd = accept(sock_fd, (struct sockaddr *)&client_addr, &client_len);
if (client_fd == -1) {
perror("accept");
continue;
}
// 5. 读取客户端HTTP请求(简化版,只处理GET请求)
ssize_t n = read(client_fd, request, sizeof(request)-1);
if (n <= 0) {
close(client_fd);
continue;
}
request[n] = '\0';
// 解析请求行,获取请求的文件名(如GET /static/test.png HTTP/1.1)
if (sscanf(request, "GET %s HTTP/1.1", filename) != 1) {
send_response_header(client_fd, 400, "text/plain", 11);
write(client_fd, "Bad Request", 11);
close(client_fd);
continue;
}
// 拼接文件路径(如/static/test.png → /usr/share/nginx/html/static/test.png)
char file_path[512];
snprintf(file_path, sizeof(file_path), "%s%s", DOC_ROOT, filename);
// 6. 打开文件,获取文件信息
file_fd = open(file_path, O_RDONLY);
if (file_fd == -1) {
send_response_header(client_fd, 404, "text/plain", 9);
write(client_fd, "Not Found", 9);
close(client_fd);
continue;
}
if (fstat(file_fd, &st) == -1) {
perror("fstat");
close(file_fd);
close(client_fd);
continue;
}
// 7. 发送HTTP响应头,然后用sendfile发送文件(零拷贝)
const char *content_type = get_content_type(file_path);
send_response_header(client_fd, 200, content_type, st.st_size);
sendfile(client_fd, file_fd, &offset, st.st_size);
// 8. 关闭文件和客户端连接
close(file_fd);
close(client_fd);
offset = 0; // 重置偏移量,用于下一次请求
}
// 关闭监听socket(实际不会执行到这里,可忽略)
close(sock_fd);
return 0;
}
这段代码模拟了 Nginx 静态文件传输的核心逻辑,全程用 sendfile 实现零拷贝,没有用户态和内核态的冗余拷贝,性能和 Nginx 的核心传输逻辑一致。大家可以编译运行(gcc server.c -o static_server),把静态文件放到指定目录,就能实现一个简易的高性能静态文件服务器。
5.2 消息中间件:Kafka 用 mmap+sendfile 实现海量日志传输
Kafka 作为一款高性能的分布式消息中间件,在处理海量日志数据的传输和存储时,充分利用了零拷贝技术,其中 mmap 和 sendfile 的结合使用是其实现高性能的核心技术之一。
在 Kafka 的日志写入过程中,使用 mmap 将日志文件映射到内存,实现了高效的日志写入。具体原理是:当生产者发送消息到 Kafka Broker 时,Broker 通过 mmap 将磁盘上的日志文件映射到内存地址空间,生产者发送的消息直接写入到内存映射区域。由于内存映射共享了内核和用户空间的内存,消息写入时不需要进行数据的显式拷贝,直接在内核空间完成,大大提高了写入效率。同时,mmap 还支持随机访问,这对于 Kafka 的日志读取和查找操作非常重要,例如消费者根据 Offset 快速定位数据时,可以通过 mmap 直接在内存中进行查找,避免了频繁的磁盘 I/O 操作。
在数据消费阶段,Kafka 使用 sendfile 实现高效的网络传输。当消费者从 Kafka Broker 拉取消息时,Broker 通过 sendfile 系统调用,直接将内核缓冲区(Page Cache)中的数据发送到网络套接字。在这个过程中,数据直接在内核空间从文件传输到 socket 缓冲区,然后通过 DMA 发送到网卡,无需经过用户空间,减少了数据在内存中的多次拷贝,提高了数据传输的效率。这种方式特别适合批量消息的发送,能够充分发挥零拷贝技术的优势,支撑 Kafka 实现百万级别的消息吞吐量,满足了大数据场景下对消息传输性能的极高要求。
5.3 视频流媒体 / 云存储:低延迟传输的必备技术
在视频流媒体和云存储领域,对数据传输的低延迟和高吞吐量有着极高的要求,零拷贝技术成为了实现这些要求的关键技术之一。
在视频直播场景中,为了给观众提供流畅的观看体验,视频数据需要实时、快速地传输到观众的设备上。使用零拷贝技术,如 sendfile 或 splice,视频数据可以直接从内核缓冲区传输到网卡,避免了用户态参与带来的延迟。以 sendfile 为例,当视频服务器接收到客户端的播放请求时,内核通过 DMA 将视频文件从磁盘读取到内核缓冲区(Page Cache),然后使用 sendfile 直接将内核缓冲区中的数据拷贝到 socket 缓冲区,最后通过 DMA 将数据发送到网卡,传输到客户端。整个过程减少了数据拷贝和上下文切换的次数,大大降低了视频传输的延迟,确保观众能够实时观看视频内容,减少卡顿现象。
在云存储文件分发场景中,同样需要高效的数据传输。当用户请求下载云存储中的文件时,零拷贝技术可以直接将存储文件从内核传输到网卡,实现快速的文件分发。例如,通过 splice 系统调用,将存储文件的数据从内核缓冲区通过管道直接传输到 socket 缓冲区,然后发送到用户设备,避免了数据在用户空间和内核空间之间的多次拷贝,提高了文件下载的速度,提升了用户体验。无论是视频流媒体还是云存储,零拷贝技术都通过减少数据传输的延迟和提高传输效率,为用户提供了更优质的服务。
5.4 不同场景如何选择零拷贝方案?
| 应用场景 |
推荐零拷贝方案 |
核心优势 |
注意事项 |
| 静态文件传输(Nginx、Apache) |
sendfile(优先)、mmap+write |
效率高、配置简单,专为文件→socket传输设计 |
配合 tcp_nopush 优化,大文件设置 sendfile_max_chunk |
| 消息队列(Kafka、RocketMQ) |
sendfile+Page Cache、mmap |
支持高吞吐,消息可共享缓存,减少资源占用 |
合理设置 Page Cache 大小,避免缓存溢出 |
| 数据库(MySQL、PostgreSQL) |
用户态直接 I/O(O_DIRECT) |
绕开内核缓冲区,避免数据重复缓存,提升读写效率 |
仅适合有自身缓存的数据库,小数据量场景不适用 |
| 任意文件描述符传输(socket→文件、管道→socket) |
splice |
支持多种描述符,灵活度高,全程内核态传输 |
必须有一个描述符是管道,注意非阻塞模式的使用 |
| 用户态需要修改数据(加密、压缩) |
mmap+write |
用户程序可直接访问内核数据,方便修改后传输 |
注意文件截断导致的 SIGBUS 信号,建议用内核租约 |
六、零拷贝的优势与局限
6.1 核心优势
- 减少 CPU 拷贝次数:在传统的 I/O 操作中,数据需要在用户空间和内核空间之间多次拷贝,这需要 CPU 的参与,占用了大量的 CPU 资源。而零拷贝技术通过优化数据传输路径,减少了 CPU 参与的数据拷贝次数。例如,在使用
sendfile 系统调用时,数据可以直接在内核空间从文件传输到 socket 缓冲区,避免了数据从内核缓冲区到用户缓冲区再到 socket 缓冲区的多次 CPU 拷贝,使得 CPU 可以将更多的资源用于执行其他任务,提高了 CPU 的利用率。
- 减少上下文切换:上下文切换是指 CPU 从一个任务切换到另一个任务时,需要保存和恢复任务的状态信息,这个过程会消耗一定的时间和资源。传统的 I/O 操作需要多次系统调用,会导致多次用户态和内核态之间的上下文切换。而零拷贝技术通过减少系统调用的次数,从而减少了上下文切换的次数。例如,使用
mmap + write 的方式,相比于传统的 read + write 方式,减少了一次系统调用,也就减少了一次上下文切换,降低了上下文切换的开销,提高了系统的响应速度。
- 降低内存带宽消耗:在数据传输过程中,数据拷贝会占用内存带宽。零拷贝技术减少了数据拷贝的次数,也就降低了对内存带宽的消耗。特别是在大数据量传输的场景下,内存带宽往往是性能瓶颈之一,零拷贝技术能够有效地减少内存带宽的占用,提高数据传输的吞吐量,使得系统能够更高效地处理大量的数据传输任务。
6.2 适用局限:这些场景别用零拷贝
- 不适合用户态修改数据的场景:零拷贝技术的核心是减少数据在用户空间和内核空间之间的拷贝,数据往往直接在内核空间传输。这就导致在需要在用户态对数据进行修改、处理的场景下,零拷贝技术并不适用。因为数据不经过用户空间,用户程序无法直接对其进行操作。例如,在数据加密、数据压缩等需要在用户态对数据进行加工处理的场景中,传统的 I/O 方式可能更合适,因为它允许数据进入用户空间,方便用户程序进行处理。
- 部分方案依赖硬件支持:一些零拷贝方案,如
sendfile + DMA 聚集,需要硬件(如网卡)支持特定的功能(如 DMA 聚集)才能实现真正的 “零 CPU 拷贝”。如果硬件不支持这些功能,那么就无法充分发挥零拷贝技术的优势,甚至可能无法使用这些零拷贝方案。在一些老旧的硬件设备上,可能不具备支持 DMA 聚集的网卡,此时使用 sendfile + DMA 聚集的零拷贝方案就无法实现最佳性能。
- sendfile 等方案存在文件描述符类型限制:以
sendfile 系统调用为例,它要求输入文件描述符必须是一个支持 mmap 的普通文件描述符,这就限制了它的使用范围。对于一些不支持 mmap 的文件描述符,如管道、套接字等,无法使用 sendfile 进行零拷贝传输。在实际应用中,如果需要处理这些类型的文件描述符,就需要选择其他合适的零拷贝方案,如 splice 系统调用,它可以在更广泛的文件描述符类型之间进行零拷贝传输,但也有其自身的限制,如要求至少有一个文件描述符是管道。
如果想深入了解 后端架构 和 网络/系统 相关的底层知识,欢迎在 云栈社区 与更多开发者一起交流探讨。
 发表于 2026-4-2 02:11:52
|
查看: 143|
回复: 0
发表于 2026-4-2 02:11:52
|
查看: 143|
回复: 0
