
和 ChatGPT 对话时,你是否也常遇到这种尴尬?
你:帮我分析一下这个项目的代码结构
ChatGPT:我可以给你分析的方法,首先你需要...
你:那你直接帮我分析吧
ChatGPT:我无法直接访问你的文件系统,你可以把代码贴给我...
问题显而易见:多数AI只能“说”不能“做”。它能告诉你“怎么做”,却无法真正动手去执行。今天,我们来深入聊聊让AI突破这层壁垒的核心能力——工具调用,看看像 OpenClaw 这样的系统是如何从“纸上谈兵”变得能“真刀真枪”干活的。
一、什么是工具调用?
传统AI的局限
传统的对话AI,比如标准版的ChatGPT,其工作流程是这样的:
用户输入 → AI理解问题 → 生成文字回答 → 输出给用户
它的能力边界被严格限制在生成文字上:
- ❌ 无法读取你的本地文件
- ❌ 无法执行系统命令
- ❌ 无法调用外部API
- ❌ 无法直接修改代码
- ❌ 无法操作数据库
工具调用带来的改变
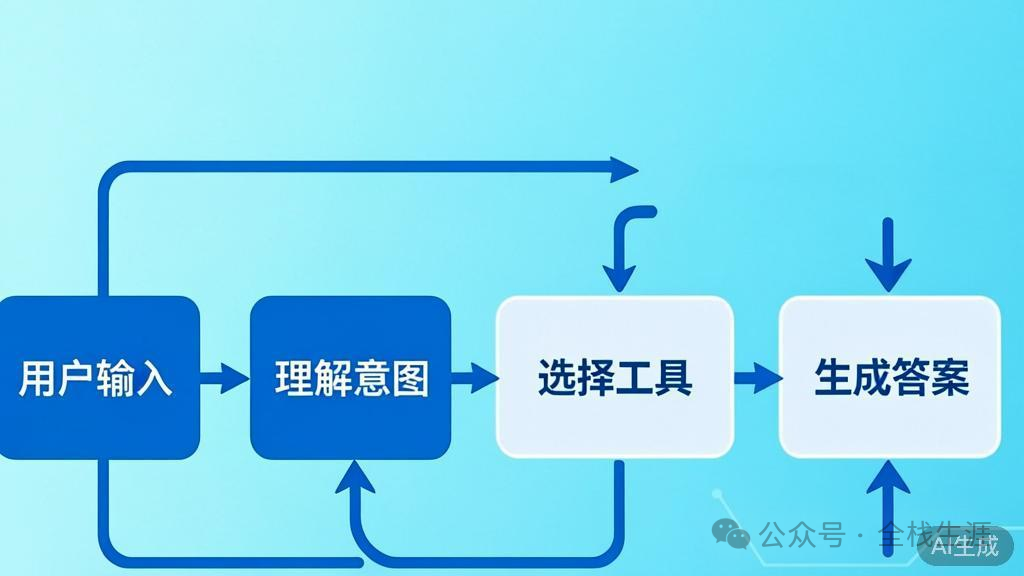
而具备了工具调用能力的AI,其工作模式发生了根本性转变:
用户输入 → AI理解问题 → 选择工具 → 执行工具 → 获取结果 → 基于结果回答
它不仅能“说”,更能“做”:
- ✅ 读取和修改文件
- ✅ 运行系统命令
- ✅ 调用外部API获取实时数据
- ✅ 操作数据库
- ✅ 执行代码片段
这就是“工具调用”(Tool Calling)的核心力量,它让AI从一个被动的信息提供者,转变为一个能主动执行复杂任务的智能体。
二、工具调用的工作原理
核心概念:从对话助手到智能代理
-
传统ChatGPT = 对话助手
- 只能理解和生成文字。
- 知识截止到训练时间点。
- 无法获取实时信息,也无法与环境互动。
-
OpenClaw = 智能代理
- 理解用户意图并自主选择行动方案。
- 调用各种工具(如读写文件、执行命令)来完成任务。
- 能基于工具返回的实时数据进行分析和决策。
工具调用的完整流程
让我们通过一个具体例子,拆解AI处理“帮我分析这个CSV文件”这个请求时的完整思考与执行链条:
┌─────────────────────────────────────────┐
│ 用户:帮我分析这个CSV文件 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 1: AI理解意图 │
│ - 用户想分析CSV文件 │
│ - 需要读取文件内容 │
│ - 可能需要数据处理 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 2: 选择工具 │
│ - file_read: 读取文件 │
│ - python: 数据分析 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 3: 执行工具 │
│ 调用 file_read(“data.csv”) │
│ 返回: CSV内容 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 4: 处理结果 │
│ 发现数据有1000行,需要统计 │
│ 选择使用 python 进行分析 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 5: 执行分析 │
│ 调用 python(code=“...”) │
│ 返回: 统计结果 │
└─────────────┬───────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ Step 6: 生成回答 │
│ “文件包含1000行数据,平均值为...” │
└─────────────────────────────────────────┘
这个过程展示了AI如何像人类一样,通过规划、执行、观察结果、再规划来一步步解决问题。
三、OpenClaw的常用工具箱
1. 文件操作工具
读取文件
# AI可以读取你的代码、配置、数据文件
file_read(path=“src/main.py”)
# 返回:文件内容
写入文件
# AI可以创建新文件或修改现有文件
file_write(path=“output.txt”, content=“分析结果...”)
# 返回:写入成功
搜索文件
# AI可以查找包含特定内容的文件
file_search(pattern=“TODO”, directory=“./src”)
# 返回:找到的文件列表
实际应用场景:
- 分析项目代码结构
- 批量修改配置文件
- 生成代码模板
- 查找bug位置
2. 命令执行工具
运行系统命令
# AI可以执行终端命令
run_command(“npm test”)
# 返回:测试结果
run_command(“git status”)
# 返回:Git状态
run_command(“docker ps”)
# 返回:运行的容器列表
实际应用场景:
- 运行测试并检查结果
- 部署应用
- 管理Docker容器
- 执行构建脚本
3. API调用工具

HTTP请求
# AI可以调用任何HTTP API
http_get(url=“https://api.github.com/repos/owner/repo”)
# 返回:仓库信息
http_post(
url=“https://api.openai.com/v1/chat/completions”,
body={...}
)
# 返回:API响应
实际应用场景:
- 获取实时数据(天气、股票)
- 调用第三方服务
- 集成多个系统
- 自动化工作流
4. 代码执行工具
运行Python代码
# AI可以执行Python代码并获取结果
python_exec(code=“”"
import pandas as pd
df = pd.read_csv(‘data.csv’)
print(df.describe())
“”")
# 返回:统计结果
运行JavaScript代码
// AI可以执行Node.js代码
node_exec(code=`
const fs = require(‘fs’);
const files = fs.readdirSync(‘.’);
console.log(files);
`)
// 返回:文件列表
实际应用场景:
四、实战演练:看AI如何组合使用工具

案例1:自动化测试分析与修复
你的需求:
帮我分析一下为什么测试失败了
AI的执行过程:
Step 1: 运行测试获取详细输出
→ run_command(“npm test -- --verbose”)
→ 返回:测试失败日志
Step 2: 分析失败原因
→ 发现是某个函数的断言失败
Step 3: 查看相关代码
→ file_read(path=“src/utils.js”)
→ 找到问题函数
Step 4: 修复代码
→ file_write(path=“src/utils.js”, content=“修复后的代码”)
Step 5: 重新测试
→ run_command(“npm test”)
→ 返回:测试通过 ✓
Step 6: 汇报结果
“测试失败的原因是…已修复并验证通过”
传统ChatGPT vs OpenClaw:
| 操作 |
ChatGPT |
OpenClaw |
| 运行测试 |
❌ 告诉你手动运行 |
✅ 自动运行 |
| 查看日志 |
❌ 让你复制粘贴 |
✅ 自动读取 |
| 分析代码 |
❌ 让你复制代码 |
✅ 自动读取 |
| 修复问题 |
❌ 给你建议 |
✅ 直接修改 |
| 验证修复 |
❌ 让你手动验证 |
✅ 自动测试 |
案例2:数据分析自动化
你的需求:
分析这个销售数据,找出趋势和异常
AI的执行过程:
Step 1: 读取数据文件
→ file_read(path=“sales_data.csv”)
→ 返回:CSV内容
Step 2: 使用Python分析
→ python_exec(code=“”"
import pandas as pd
import numpy as np
df = pd.read_csv(‘sales_data.csv’)
# 计算趋势
monthly_trend = df.groupby(‘month’)[‘amount’].sum()
# 找出异常
mean = df[‘amount’].mean()
std = df[‘amount’].std()
outliers = df[(df[‘amount’] > mean + 3*std) |
(df[‘amount’] < mean - 3*std)]
print(f“月度趋势: {monthly_trend.to_dict()}”)
print(f“异常数据: {outliers.to_dict()}”)
“”")
Step 3: 生成可视化
→ python_exec(code=“生成图表的代码...”)
Step 4: 保存分析报告
→ file_write(path=“analysis_report.md”, content=“...”)
结果:AI自动完成了整个数据读取、分析、可视化到报告撰写的流程,你只需要发出一个指令。
案例3:API集成与数据入库
你的需求:
帮我调用这个API,把数据存到数据库
AI的执行过程:
Step 1: 调用外部API
→ http_get(url=“https://external-api.com/data”)
→ 返回:JSON数据
Step 2: 处理数据
→ python_exec(code=“数据清洗和转换...”)
Step 3: 存储到数据库
→ run_command(“psql -d mydb -c ‘INSERT INTO ...’”)
Step 4: 验证存储
→ run_command(“psql -d mydb -c ‘SELECT COUNT(*) FROM ...’”)
→ 返回:记录数
五、工具调用的安全保障
权限控制
OpenClaw不会无限制地执行所有命令,它设定了清晰的安全边界。
危险操作需要确认
# AI会先询问,不会直接执行
AI: “我将删除 /path/to/directory 下的所有文件,
确认继续吗?”
你:是的
→ AI才会执行删除操作
只读模式
# 设置为只读模式,AI只能读取不能修改
openclaw_config.read_only = True
命令白名单
# 只允许执行安全的命令
openclaw_config.allowed_commands = [
“git status”,
“git log”,
“ls -la”,
“npm test”
]
沙箱执行
代码在隔离的沙箱环境中执行,确保安全:
- 文件系统访问受限:只能访问指定目录。
- 网络访问可控制:可以配置允许或禁止网络请求。
- 资源使用有限制:CPU、内存使用量受到约束。
- 执行时间有限制:防止长时间运行或死循环。
六、工具调用 vs 函数调用
传统“函数调用”的局限
许多AI系统声称支持“函数调用”(Function Calling),但其本质是:
AI生成一个函数调用描述 → 你的代码执行 → 返回结果给AI
存在的问题:
- 需要预先定义所有函数:你必须提前告诉AI所有可用的函数及其参数。
- 需要自己写执行代码:AI只生成调用描述,真正的执行逻辑需要你手动编写。
- AI无法真正“控制”执行过程:它只是一个建议者,不能根据中间结果动态调整策略。
OpenClaw“工具调用”的优势
AI直接调用工具 → 工具执行 → 返回结果给AI → AI决定下一步
核心优势:
- 工具已内置,无需定义:文件操作、命令执行等通用工具开箱即用。
- AI完全控制执行流程:它可以自主决定调用哪个工具、何时调用、如何处理结果。
- 可以链式调用多个工具:像乐高积木一样组合工具完成复杂任务。
- 可以根据结果动态调整策略:如果工具A失败,它会尝试工具B,具备更强的鲁棒性。
七、如何为AI定义新工具?
工具的定义格式
你可以根据业务需求,轻松地为AI扩展新的能力。在云栈社区的技术文档板块中,你能找到更多关于自定义工具的最佳实践和案例。
# 定义一个新工具:搜索技术文档
@tool
def search_documentation(query: str, language: str = “python”):
“””
搜索技术文档
Args:
query: 搜索关键词
language: 编程语言 (默认: python)
Returns:
找到的文档内容
“””
# 实现逻辑:调用内部的搜索API
results = search_api(query, language)
return results
工具注册
定义好工具函数后,注册过程非常简单:
# 将工具注册到OpenClaw
openclaw.register_tool(search_documentation)
# 注册后,AI现在就可以使用这个工具了
AI自动学习工具使用
工具一旦注册,AI会自动完成以下步骤:
- 读取工具的文档字符串:理解这个工具是干什么的。
- 理解工具的功能和参数:知道什么情况下该调用它,需要传入什么参数。
- 在适当的时候自动调用:当用户问题匹配工具能力时,AI会自主决定调用。
- 根据返回结果继续执行:将工具返回的结果作为上下文,进行下一步推理或回答。
八、最佳实践:高效协作指南
给AI明确、具体的任务
清晰的指令能极大提升AI的执行效率和准确性。
✅ 好的指令:
“分析 src/ 目录下的所有 Python 文件,
找出所有未使用的导入语句并删除”
❌ 模糊的指令:
“帮我整理一下代码”
善用工具组合
复杂任务往往需要多个工具协同工作。AI擅长进行这种规划和编排。
# 一个“部署应用”的指令,可能触发以下工具链:
“帮我部署这个应用到服务器”
→ 1. run_command(“npm run build”) # 构建
→ 2. file_read(“config.json”) # 读取配置
→ 3. http_post(url=“deploy-api…”, …) # 调用部署API
→ 4. run_command(“curl health-check”) # 健康检查
让AI解释执行计划(特别是在生产环境)
对于关键或危险操作,可以让AI先“报备”再执行。
“在执行前,先告诉我你要做什么”
→ AI会先列出计划:“我将依次执行:1. 备份原文件;2. 修改配置项X;3. 重启服务。”
→ 你确认后再执行:“好的,继续。”
九、总结:从聊天助手到实干智能体的飞跃
没有工具调用的AI:
- 只能生成文字建议和操作指南。
- 每一个步骤都需要人工手动执行。
- 无法直接处理真实的文件、数据库或系统状态。
- 整体效率低下,人依然是执行的瓶颈。
具备工具调用的AI:
- 能理解意图并自主规划、执行一系列动作。
- 自动完成包含多个步骤的复杂任务。
- 直接与真实世界互动,处理实时文件和数据。
- 效率显著提升,真正成为能分担工作的“智能体”。
这正是 OpenClaw 这类人工智能的核心价值所在:
它不再只是一个陪你聊天的知识库,而是一个能理解你意图、帮你动手干活的智能代理。工具调用能力是AI迈向通用智能体(Agent) 的关键一步,它让AI从理论走向了实践,从辅助走向了协同。
想深入了解AI如何规划工具使用顺序、如何处理执行中的错误吗? 下一篇文章我们将探讨OpenClaw的“自我反思”机制,揭秘AI如何像人类一样从错误中学习并实时调整策略。
(本文提及的 OpenClaw 项目详情可访问:https://mp.weixin.qq.com/s?__biz=MzI4MzU3NjA3Nw==&mid=2247486900&idx=1&sn=8307ae7be18f830efc894f0c7406c1c7&scene=21#wechat_redirect)
 发表于 2026-4-2 02:05:37
|
查看: 159|
回复: 0
发表于 2026-4-2 02:05:37
|
查看: 159|
回复: 0
