Agent 长期记忆终于不用靠堆 token 了
最近跑长任务 Agent 时,总在中途卡住。上下文塞满工具日志、错误栈、搜索结果,模型开始胡乱总结,任务就崩了。换个对话窗口,又得从头解释项目背景、个人偏好、SOP 流程。重复劳动把人累死,也把 token 烧光。
TencentDB Agent Memory 把这个问题直接拆成两层解决:短期用符号压缩,长期用分层沉淀。 它完全本地运行,零外部 API 依赖,集成 OpenClaw 后,token 最高砍掉 61.38%,部分基准通过率相对提升超 50%,PersonaMem 准确率从 48% 拉到 76%。这些数据来自连续长会话测试,而不是单轮。
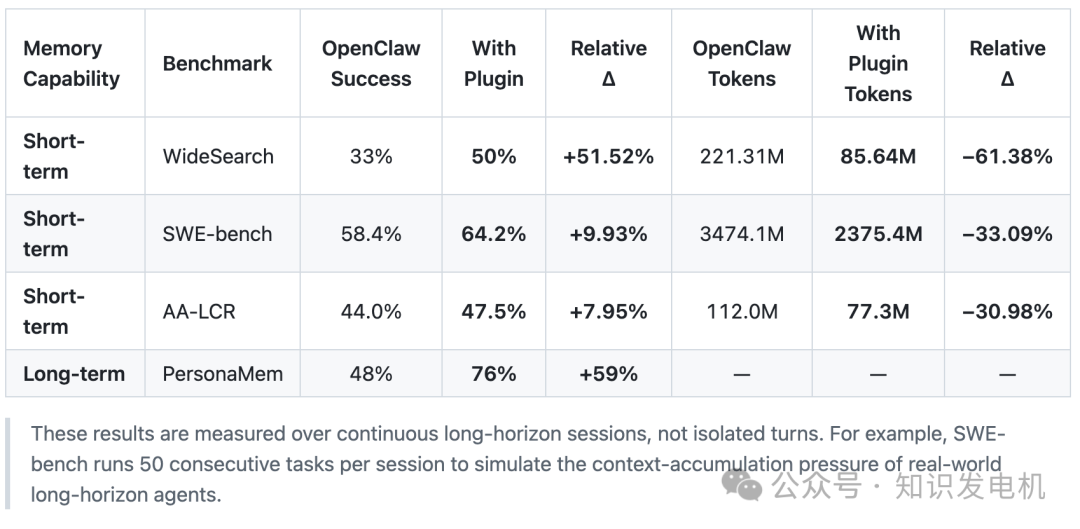
这不是又一个向量数据库插件。它拒绝把所有历史砸进扁平向量堆,而是用 4 层渐进管道(L0 到 L3),让 Agent 既能记住该记住的,又不把上下文撑爆。普通用户觉得“Agent 越来越懂我了”,同行会看到它在存储、召回、溯源上的工程取舍。
为什么扁平记忆在长任务里必然翻车
日常用 Agent 像请了个实习生。你今天教它项目架构、代码规范、输出格式,明天它又忘得干干净净,只能再讲一遍。技术上,这是因为传统记忆把所有对话切成碎片塞进向量库,召回时变成无结构的盲搜。长任务里工具输出动辄几十万 token,上下文窗口迅速见底,模型注意力稀释,决策质量雪崩。
更要命的是不可逆压缩。 很多方案直接总结历史,结果丢了原始证据,事后排查像大海捞针。TencentDB Agent Memory 反其道而行:记忆不是“存更多”,而是“分层存、按需取”。底层保全证据,上层保结构,让 Agent 日常只看高密度符号,需要细节时一键钻取。
在本地试过类似扁平方案,跑 20 轮工具调用后,上下文就乱套了。切换到这个分层后,模型能一直盯着 Mermaid 画布级任务图,细节随时 grep node_id 拉取。感受最明显的是排查效率:以前翻整个聊天记录,现在直接定位符号节点,秒级拿到原始日志。
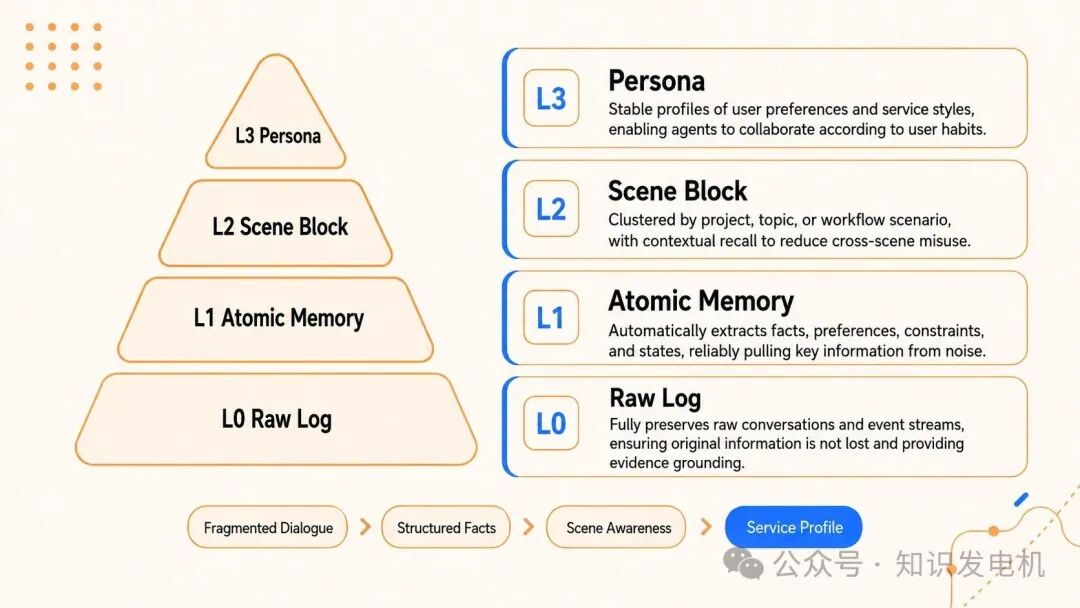
分层架构:从 raw 对话到 Persona 的语义金字塔
核心是 memory layering。不管短期任务还是长期个性化,都按层次组织。
短期上下文分层:底层存 raw 工具输出(refs/*.md 文件),中层抽取步骤摘要(jsonl),顶层浓缩成轻量 Mermaid 画布。Agent 上下文里只塞顶层结构,出错时通过 node_id 向下钻取。这实现了上下文卸载:海量日志扔到外部存储,只留高密度符号在 prompt 里。
长期个性化分层更像语义金字塔:L0 Conversation(原始对话)→ L1 Atom(原子事实)→ L2 Scenario(场景块)→ L3 Persona(用户画像)。Persona 层承载日常偏好、风格、长期目标;需要细节时才下钻到 Atom 或原始对话。技能生成也复用这套逻辑,从执行轨迹提炼 Scenario,再浓缩成可复用的 SOP。
异构存储 + 渐进披露是关键。底层事实日志放数据库,支持强全文检索;上层 Persona、场景、画布存成人类可读的 Markdown 文件,便于白盒检查和人工干预。下层保证据,上层保结构。压缩但不丢失溯源路径:顶层符号 → 中层索引 → 底层 raw text,确定性可逆。
我之前总担心压缩会牺牲可解释性,用了这个之后发现反而更透明。Markdown 格式的 Persona 文件直接打开就能看,改几个关键事实就能影响后续行为。理论上这对企业级 Agent 落地特别友好——审计时能逐层回溯,不用担心黑箱。
符号记忆:Mermaid 画布把 verbose logs 压成可解析结构
长任务里最吃 token 的就是工具中间结果。TencentDB Agent Memory 结合上下文卸载和 符号记忆 解决它。
核心是用 Mermaid 语法把任务状态变迁编码成图。不是模糊摘要,而是带 node_id 的精确关系图。完整日志卸载到文件系统,上下文只注入几百 token 的画布。Agent 基于图推理,验证细节时 grep node_id 瞬间拉回原始文本。

(实际项目里还有样式定义,这里简化了。)
跑完后你会看到上下文窗口占用显著下降,同时模型对任务整体结构的把握反而更清晰。容易出错的地方是 offload 开关和 patch 脚本的配合——第一次集成时建议严格按文档走,否则符号和 raw 可能对不上。
之前踩过一个坑:早期没打 runtime patch,after-tool-call 消息没正确钩住,导致部分节点追踪失败。后来补上就稳了。不知道你们集成其他框架时有没有遇到类似对齐问题。
快速上手与可调参数
OpenClaw 集成最简单(推荐日常使用):
# 安装插件
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
openclaw gateway restart
然后在 ~/.openclaw/openclaw.json 里启用:
{
"memory-tencentdb": {
"enabled": true
}
}
默认用本地 SQLite + sqlite-vec。想开短期压缩再加 offload 配置,并打 patch 脚本。Hermes 用户也能用 Docker 一键启动,带持久化 volume。
可配置参数分三层:日常调 90% 场景够用,高级参数应对超长任务,底层参数支持自定义 embedding/LLM。pipeline.everyNConversations 默认 5,persona 每 50 条新记忆更新一次,基本开箱就能用。
⚠️ 注意:生产环境建议先评估 L0/L1 保留天数,避免日志无限增长。
TencentDB Agent Memory 真正厉害的地方在于,它把“Agent 记住”这件事从玄学变成了可工程化的分层系统。 不再是盲目堆历史或不可逆总结,而是有结构、可溯源、可人工干预的记忆金字塔。短期省 token,长期沉淀经验,人和 Agent 终于能各干各的擅长事。
以前我总觉得 Agent 记忆是锦上添花,现在看它是长任务落地的必备基础设施。你在实际项目里,是继续靠 prompt 堆记忆,还是试试这种分层方案?💬 更多 Agent 记忆相关讨论,欢迎来云栈社区交流。
 发表于 2026-5-18 19:48:37
|
查看: 118|
回复: 0
发表于 2026-5-18 19:48:37
|
查看: 118|
回复: 0
