你有没有这种感觉——
团队里买了一大堆 AI 工具,装了一堆别人写好的 Agent 提示词,跑起来也像那么回事,但效果总是不是你的。问它你们公司的业务流程,它答不上来;让它处理你们的数据,它一堆幻觉。
问题在哪?
问题不在工具本身,而在于:你从来没有用过自己的数据,构建自己的 Agent。
你停在 Agent 的哪个段位?
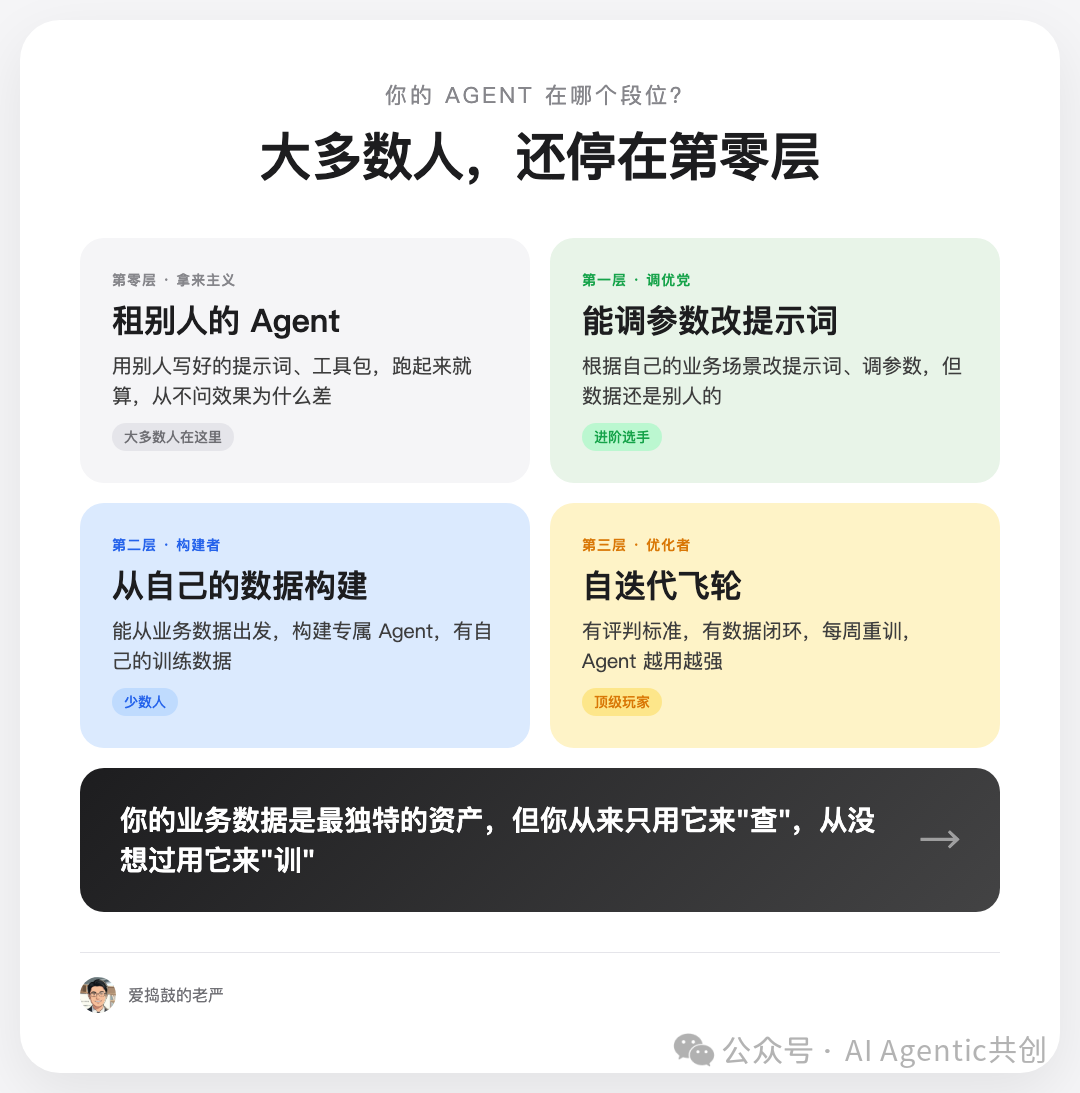
我把团队用 Agent 的水平分成四层,看看你卡在哪。
第零层:拿来主义。 别人写好的提示词,拿过来就跑。从不问效果为什么差,也不清楚它是怎么工作的。反正跑起来像 AI 就够了。
第一层:调优党。 已经开始根据自己的业务场景改提示词、调参数。进步了,但数据还是别人的,底层逻辑还是别人的。
第二层:构建者。 能从自己的业务数据出发,构建专属 Agent。有自己的训练数据,有自己的判断标准。这一层已经开始拉开差距。
第三层:优化者。 有数据闭环,每周重训,Agent 越用越强。这已经不是工具层面了,而是系统层面。
你现在在哪一层?
大多数团队,还在第零层和第一层之间晃悠。买了工具,装了提示词,以为这就叫“AI 转型”了。
你用别人的配方,没有自己的招牌菜
为什么要从自己的数据构建 Agent?三个理由。
第一,差异化会消失。 别人用同样的提示词,你用同样的工具,大家产出差不多。在 AI 普及的时代,“用了 AI”已经不是优势,“用得好”才是。
第二,你的数据在白白浪费。 大多数团队的 AI 策略是“买工具、接 API”,但从来没想过:自己沉淀了几年的业务数据,才是真正的护城河。你用别人没有的数据训练出来的 Agent,别人的 Agent 永远抄不到。
第三,效果无法控制。 租来的 Agent,你不知道它怎么想的,也不知道它什么时候会出错。更关键的是,你没办法优化它——你没有它的评判标准,没有它的数据闭环。
你的业务数据是最独特的资产,但你从来只用它来“查”,从没想过用它来“训”。

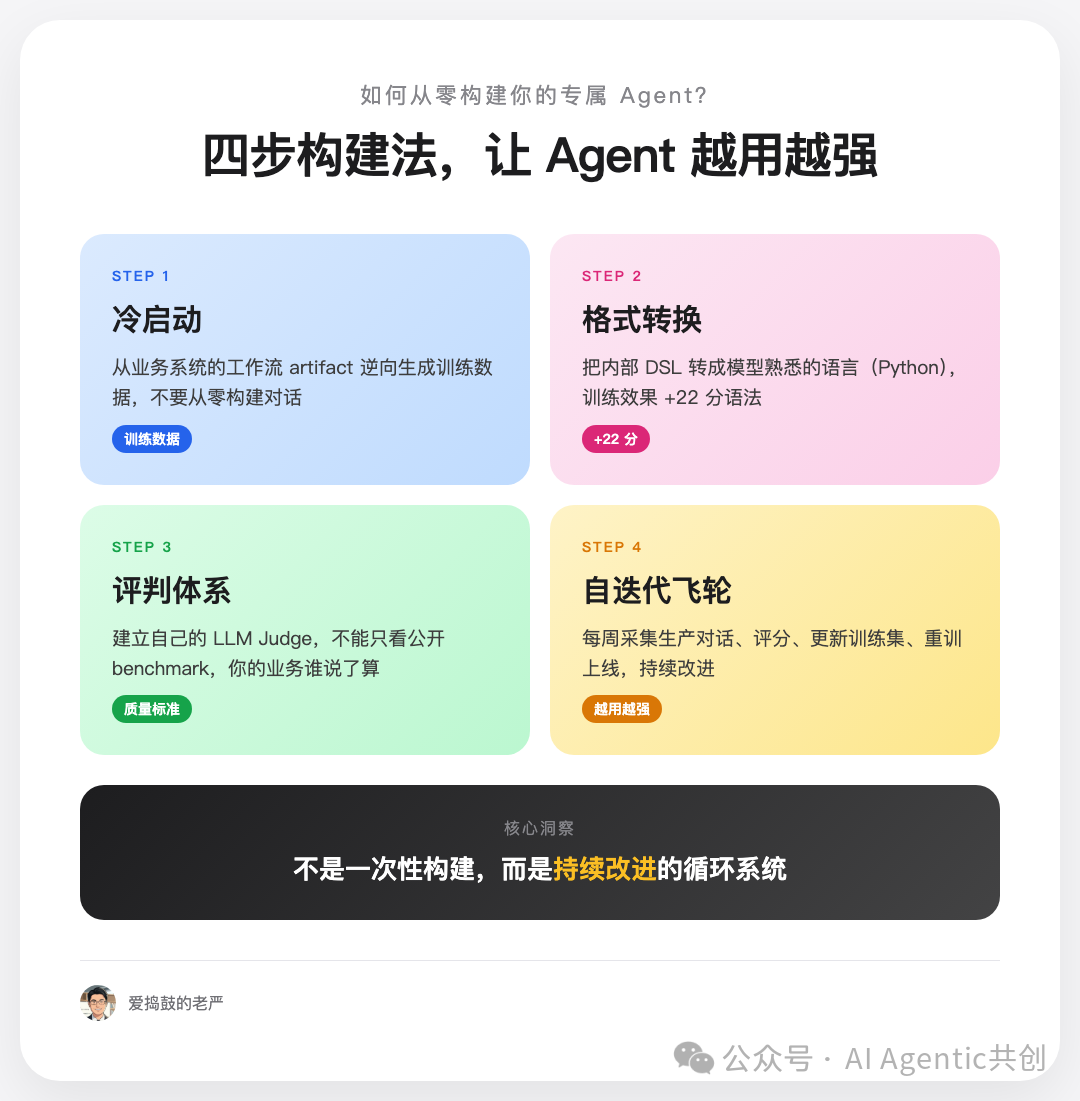
四步构建法:让 Agent 从“租”到“自有”
那怎么从自己的数据构建 Agent? Shopify 工程师在 2026 年发了一篇文章,完整记录了他们怎么从零构建一个 Flow 生成 Agent,其中的方法论完全可以平移。
Step 1:数据怎么来?用哪些数据?——从已有 artifact 逆向生成训练数据
第一个卡点是:我的业务还没有真实对话,怎么生成训练数据?
Shopify 的解法是从已有的工作流 artifact 逆向生成。不要从零构建对话,从已验证的工作流出发,反向推断用户会怎么问这个工作流。
具体三步:
- 采样已验证的工作流:从生产环境筛选最近 7 天运行过的、确认有效的业务流
- 生成用户 Query:用更强的 LLM,为每个工作流生成“用户可能怎么描述这个需求”
- 构造工具调用轨迹:构建完整的执行路径——这个工作流需要哪些步骤、调用哪些工具
这个方法本质上就是:你的业务系统里已经沉淀了几年的工作流记录,这就是你的训练数据。
Step 2:格式转换——把你的 DSL 变成训练语言
有了训练数据,还有关键一步:格式转换。
Shopify 发现,直接训练 Flow 原生的 JSON DSL 格式,效果很差——因为模型不熟悉这种嵌套结构。Shopify 把 JSON 转成 Python 格式训练,推理时再转回去。
结果:语法正确率 +22 分,语义正确率 +13 分。
同样的道理:如果你的业务有自己内部的数据格式,不要硬喂给模型。转成模型熟悉的语言(Python、JSON、结构化文本),训练效果会大幅提升。
Example Json:
{
"messages": [
{
"role": "user",
"content": "用户原始 Query"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_001",
"function": {
"name": "工具名",
"arguments": "{\"param\": \"value\"}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_001",
"content": "工具返回结果(原始 JSON)"
},
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_002",
"function": {
"name": "下一个工具名",
"arguments": "{\"param\": \"value\"}"
}
}
]
},
{
"role": "tool",
"tool_call_id": "call_002",
"content": "工具返回结果"
},
{
"role": "assistant",
"content": "最终回复(用户看到的内容)"
}
],
"metadata": {
"session_id": "会话 ID",
"domain": "领域/场景",
"success": true,
"tags": ["标签1", "标签2"]
}
}
Step 3:评判体系——你的业务谁说了算
第三个卡点:怎么知道 Agent 效果好还是不好?
不能只看公开 benchmark。 公开评测集覆盖不了你的业务场景,用公开指标优化出来的 Agent,到了你的业务里不一定 work。
解法是建立自己的 LLM Judge:
- 收集几百条人工标注的对话样本
- 训练一个 LLM Judge 对齐人工判断
- 用生产激活率作为 guardrail(但不是唯一指标)
关键是用业务标签体系分析每个维度的 gap:哪个场景准确率低?哪个意图识别错了?哪个工具选错了?打标签不是为了好看,是为了知道下一轮训练该补什么数据。
Step 4:自迭代飞轮——让 Agent 每周变强一点
前面三步是冷启动,接下来才是真正的壁垒:持续迭代的飞轮。
每周做这样一件事:
- 采集生产对话
- LLM Judge 评分
- 高质量对话进入训练集;低质量的隔离审查
- 打标定位 gap
- 补数据,重新训练,上线
不是一次性构建,而是持续改进的系统。Shopify 的数据是:每周重训一次,质量稳步提升。
为什么大多数团队没做?
方法论说完了,为什么大多数团队还是停在“租 Agent”阶段?
两个卡点。
第一个卡点:不知道数据可以被这样用。 大多数团队的认知还是:数据用来查询、用来报表、用来分析。“用数据训练 AI”这件事,听说过,没想过自己也能做。
第二个卡点:没有评判标准就没有优化。 很多团队根本没有定义过“好的 Agent 输出”是什么。没有标准就没有迭代,没有迭代就永远不知道自己的 Agent 在变好还是变坏。
这两个卡点其实是一件事:你的团队,还没有把数据资产当能力资产来运营。
你的第一步是什么?
方法论听起来复杂,但第一步其实很简单。
从现有的业务系统里,导出最近 100 条被成功执行的工作流记录。 注意不是对话记录,是执行结果——这些是已经被验证过的有效数据。
然后用 Shopify 三步法跑一遍:
- 采样 + 生成 Query
- 构造调用轨迹
- 过一遍质量过滤
不要想全貌,先跑通一个小闭环。不需要一开始就建完整的评判体系和飞轮,先验证这个思路在你业务上是否 work。
剩下的,慢慢来。
但关键是:不要再租了,是时候建自己的了。
这篇文章强化了我之前朴素的 Agent 工具调用链分析及优化的想法,在对于 OpenClaw 等 Agent 使用过程中的可观测数据虽然做了一些分析和优化,但还没有建立起完整的飞轮。这不仅仅是 Agent 的问题,更多的是围绕 LLM 的能力构建一套完整的运行时保障和优化逻辑,也就是构建企业自己的 “Harness”。如果你也在做类似尝试,不妨来云栈社区和更多同行聊聊踩过的坑与验证过的路径。
参考资料
- Shopify Engineering - Flow generation through natural language: An agentic modeling approach (2026) - https://shopify.engineering/fine-tuning-agent-shopify-flow
 发表于 2026-5-18 20:56:55
|
查看: 88|
回复: 0
发表于 2026-5-18 20:56:55
|
查看: 88|
回复: 0
