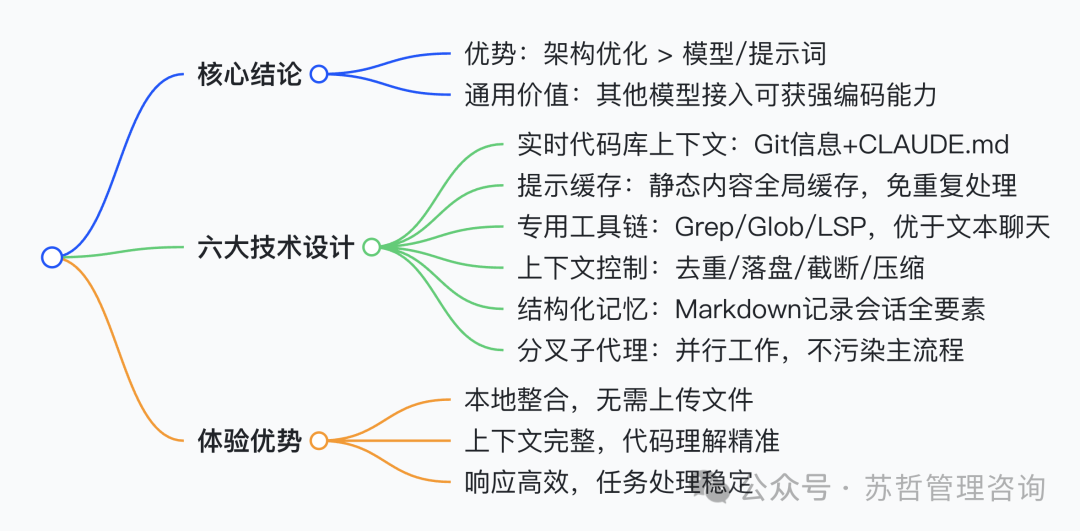
通过分析 GitHub 上泄露的 Claude Code TypeScript 代码快照,我们得以窥见其强大编码能力背后的工程逻辑。核心结论令人惊讶:Claude Code 的高性能并非主要依赖于底层模型,而是源自一套精密的软件架构与系统控制壳工程优化。这意味着,将其他主流模型如 DeepSeek、Kimi、GLM 等适配接入此架构,同样有望获得卓越的编码能力。
核心观点:架构 > 模型/提示词
Claude Code 的优秀编码表现,底层模型只占部分因素,核心驱动力在于其软件架构与控制壳的工程优化。这为 AI 编码智能体的设计提供了极具价值的参考,其开源实战代码更是绝佳的学习样本。
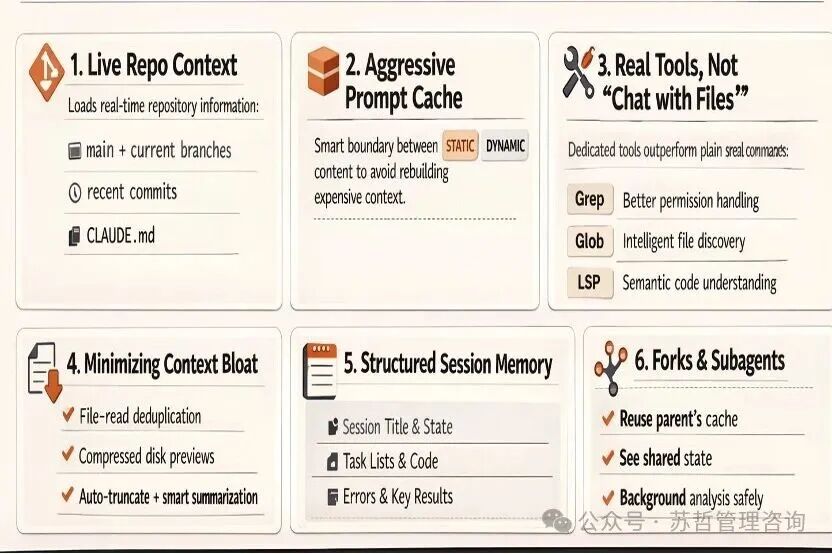
六大关键技术设计拆解
-
实时代码库上下文
启动时自动加载 Git 主分支、当前分支、最近提交记录以及项目文档 CLAUDE.md,为模型构建完整的项目背景,使其不再处理孤立的代码片段。
-
激进式提示缓存
利用边界标记清晰地区分静态与动态内容。静态部分(如系统提示、工具描述)进行全局缓存,避免每次请求时重复计算与传输,大幅降低推理成本与响应延迟。
-
专用工具链,优于“聊天+文件上传”
不依赖简单的 Bash 调用系统命令,而是集成专用的 Grep、Glob、LSP 等工具。这种方式在权限管理上更安全,在代码检索、引用分析和语义理解上更精准,真正将代码视为结构化数据而非纯文本。
-
最小化上下文膨胀
通过文件读取去重、将超大工具执行结果写入磁盘仅保留引用、自动截断与智能摘要压缩等一系列组合策略,有效解决了处理大型代码库时的上下文窗口超限问题。
-
结构化会话记忆
使用 Markdown 文件系统化地保存每次会话的主题、任务列表、涉及的文件、遇到的错误以及关键成果。这类似于开发者的工作笔记,确保了长周期、多步骤编码任务的连贯性。
-
分叉与子代理并行
支持创建子代理,子代理可以复用父级的上下文缓存并感知共享状态,能够在后台并行执行代码汇总、静态分析等辅助性任务,而不干扰主代理的工作流程,提升了处理复杂任务的效率。
体验优势的根源
相比于普通的网页版聊天界面,Claude Code 通过本地深度整合代码库、提供完整的项目上下文、使用专业工具链以及高效的处理机制,实现了无需手动上传文件、理解精准、响应稳定的流畅体验,其效果提升显著。
Claude Code 核心查询状态机深度解析
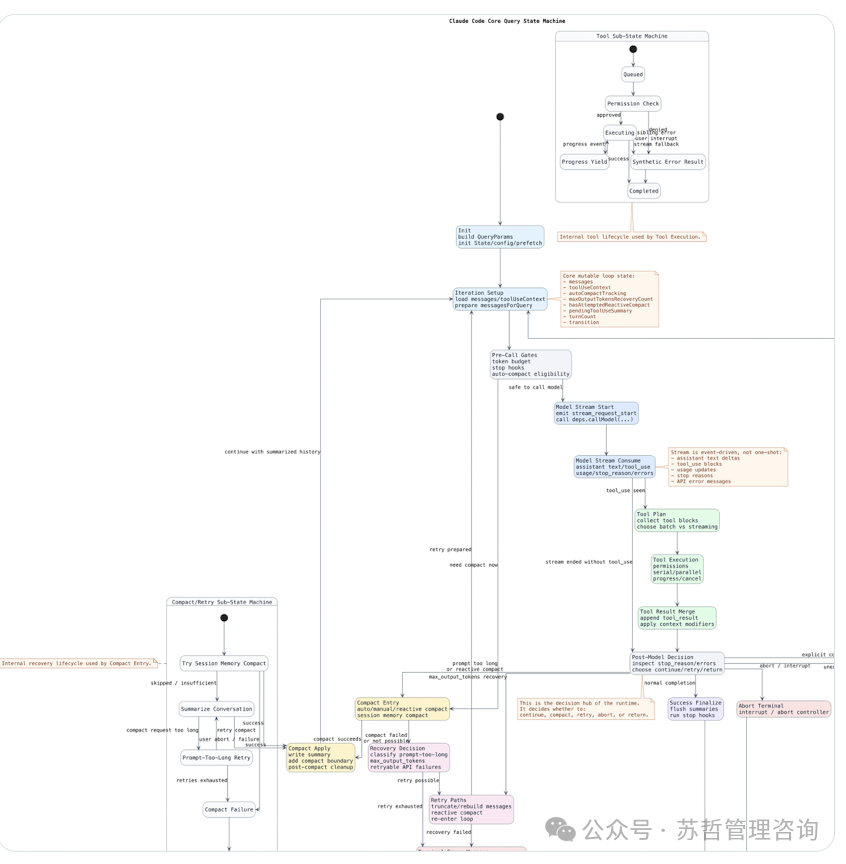
这张图揭示了 Claude Code 核心请求处理的完整状态流转逻辑。它完整描绘了从用户发出编码指令开始,系统经历上下文准备、模型调用、工具执行、结果处理,直至会话压缩、重试或终止的全生命周期。这张图是前文六大架构设计在工程层面的具体实现蓝图。
状态机定位与核心价值
这是 Claude Code 的 核心状态机,本质是一套“AI 编码代理的任务调度与状态管理系统”,核心解决了三个工程难题:
- 如何在长会话、大代码库中精准控制上下文窗口,避免无效膨胀。
- 如何安全、高效地调用工具执行具体的编码操作。
- 如何在模型调用失败、上下文超限等异常场景下自动重试与恢复,保障任务连续性。
主状态机全流程拆解
1. 初始阶段:上下文构建与前置校验

- Iteration Setup (迭代设置): 初始化会话上下文,加载 Git 分支/提交信息、
CLAUDE.md 项目文档,构建完整的代码库上下文,并准备发送给模型的消息。
- Pre-Call Gates (调用前关卡): 执行步骤钩子(hooks),检查工具调用资格,确认“可安全调用模型”,拦截非法或无效的请求,从源头避免上下文浪费。
2. 模型调用阶段:流式响应与工具触发
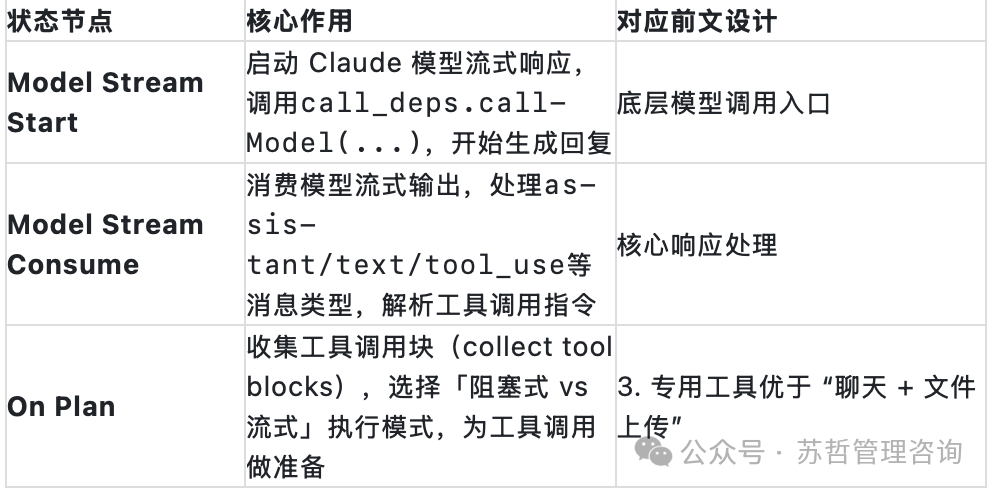
- Model Stream Start (模型流启动): 启动 Claude 模型的流式响应,调用底层
call_deps.callModel(...) 函数,开始生成回复。
- Model Stream Consume (模型流消费): 消费模型的流式输出,处理
assistant、text、tool_use 等消息类型,解析出工具调用指令。
- On Plan (规划阶段): 收集工具调用块,根据情况选择“阻塞式 vs 流式”执行模式,为后续工具调用做好准备。
3. 工具执行阶段:安全校验与结果处理
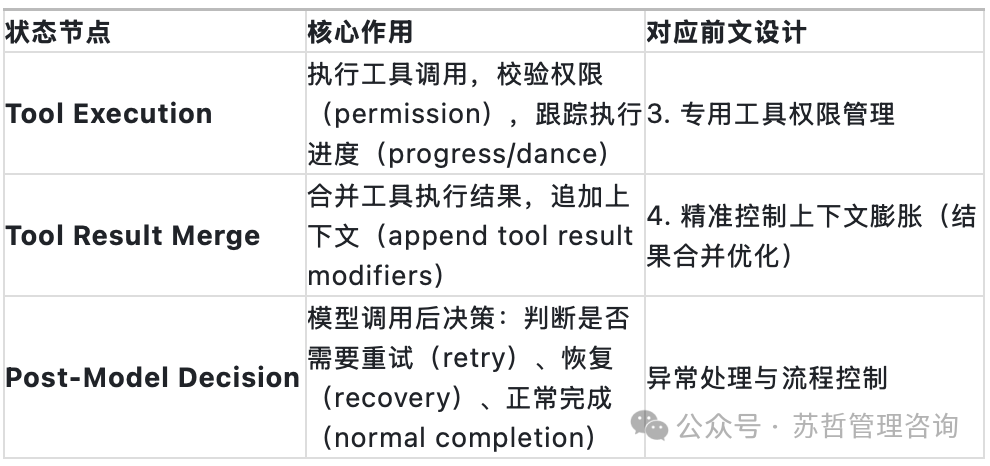
- Tool Execution (工具执行): 执行具体的工具调用,进行权限校验,并跟踪执行进度。
- Tool Result Merge (工具结果合并): 将工具执行的结果合并回上下文,应用相应的上下文修改器。
- Post-Model Decision (模型后决策): 模型调用后的决策中枢,判断是否需要重试、恢复还是正常完成流程。
4. 异常与分支处理:重试 / 压缩 / 终止
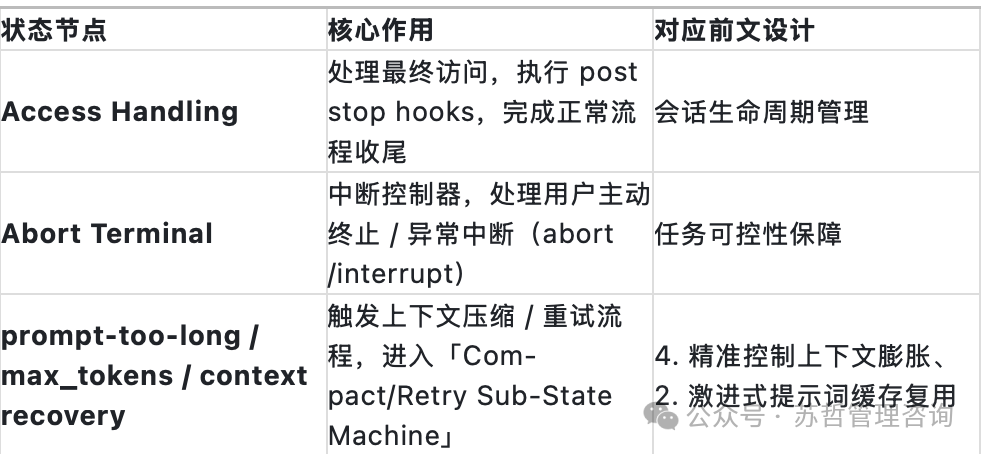
- Access Handling (访问处理): 处理最终访问,执行后置停止钩子,完成正常流程收尾。
- Abort Terminal (中止终端): 处理用户主动终止或异常中断。
- Prompt-too-long / Context Recovery (提示过长/上下文恢复): 当提示过长、达到token上限或需要上下文恢复时,触发进入“压缩/重试子状态机”。
两个关键子状态机详解
这是工具执行的独立生命周期,体现了“专用工具链”的设计思想。
- 核心流程:
Invoke → Permission Check (权限校验,核心安全机制) → Executing (执行任务,支持进度上报与挂起) → Syntactic Error Result (语法错误处理) / Completed (执行完成)。
- 核心价值:将工具执行与主状态机解耦,实现权限隔离、进度可控、错误可捕获,从根本上避免了直接 Bash 命令调用的安全风险。
2. Compact/Retry Sub-State Machine(压缩/重试子状态机)
这是上下文膨胀控制的核心机制,对应了“精准控制上下文”和“结构化会话记忆”设计。
- 触发条件:
prompt-too-long (提示词过长)、retry exhausted (重试次数耗尽)、compact request too long (压缩后仍过长)。
- 核心流程:
Try Session Memory Compact: 尝试压缩会话记忆。Summarize Conversation: 生成对话摘要(将长会话压缩为结构化 Markdown 笔记)。Compact Entry: 执行压缩逻辑,区分成功、失败、重试场景。Retry Paths: 提供重试路径,支持截断/重建消息、重新进入主流程。
- 核心价值:通过“摘要压缩 + 记忆管理”解决长会话上下文超限问题,实现“基于摘要历史继续任务”,保障了大代码库、长周期任务的连续性。
设计亮点与对应关系

关键问题深度解答
Q1:这张状态机图如何印证“Claude Code的优势在架构而非模型”?
A:状态机的核心逻辑完全围绕工程化架构展开。模型仅在 Model Stream Start/Consume 节点作为“生成器”存在,其余绝大部分流程(如上下文管理、工具调度、权限控制、异常恢复)都是纯粹的工程逻辑。该状态机是模型无关的:只要替换 callModel 的实现,接入 DeepSeek、Kimi 等其他人工智能模型,整套上下文、工具、压缩、重试的架构完全可以复用,这完美印证了其核心优势在于架构设计。
Q2:Claude Code 如何解决“长会话上下文膨胀”问题?
A:通过状态机构建的多层级上下文控制体系:
- 前置拦截:
Pre-Call Gates 校验上下文有效性,避免无效调用。
- 过程控制:工具结果合并时对大结果进行落盘仅留引用,避免冗余。
- 事后压缩:
Compact/Retry 子状态机自动触发对话摘要与记忆压缩,用结构化历史替代原始长对话。
- 缓存复用:利用
mmap 内存映射缓存静态提示词,避免重复计算,减少占用。
Q3:工具子状态机解决了普通聊天工具的哪些痛点?
A:解决了三个核心痛点:
- 安全风险:独立的
Permission Check 权限校验,杜绝了 Bash 命令可能带来的越权操作风险。
- 理解深度不足:专用工具(Grep/Glob/LSP)将代码作为结构化数据处理,能进行调用链分析、引用查找,远超纯文本的理解深度。
- 流程不可控:独立的工具生命周期支持进度上报、错误捕获和中断恢复,解决了普通聊天工具“黑盒调用、无法跟踪”的问题。
小结
这张状态机图是 Claude Code 的底层架构蓝图,完整呈现了其“以架构为核心、模型为工具”的设计哲学:
- 它不是简单的“模型 + 聊天界面”,而是一套完整的 AI 编码智能体操作系统,涵盖了从上下文管理、工具调度到异常恢复的全链路工程化设计。
- 所有设计都紧密围绕“提升真实编码效率、解决大代码库与长会话痛点”展开,是 AI 编码工具从“玩具”迈向“生产力工具”的关键跃迁。
- 这套架构具备高通用性,为所有 AI 编码代理(如 Cursor、Windsurf 等)的设计提供了核心参考,指明了行业未来的工程化发展方向。
对于希望深入理解 AI 工程化实践或自行构建智能体系统的开发者而言,这份分析无疑提供了宝贵的思路。你可以在云栈社区找到更多关于系统架构与 AI 工程化的深度讨论。
参考来源: Sebastian Raschka |  发表于 2026-4-2 02:15:01
|
查看: 158|
回复: 0
发表于 2026-4-2 02:15:01
|
查看: 158|
回复: 0
