在电商行业,数据驱动决策早已不是口号,而是生存法则。然而,面对高频、高并发、低延迟的指标分析需求(如长周期同环比、多维度下钻),传统的OLAP架构往往力不从心。唯品会的实践,为我们提供了一个教科书级的范例——如何通过StarRocks的持续演进,将分析效率提升5-10倍,并最终迈向“One Fits All”的统一分析愿景。这一演进历程也是大数据领域经典架构升级的缩影。
一、 痛点诊断:为什么传统的Presto/ClickHouse不够用?
在引入StarRocks之前,唯品会的分析体系面临严峻挑战,这正是许多大型电商企业的缩影:
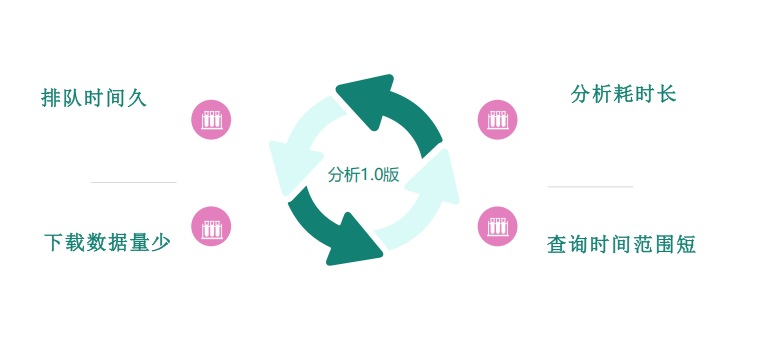
- 用户体验差:基于PrestoDB+Alluxio的分析1.0版,查询耗时动辄上百秒(P90超60秒),且仅支持14天内的流量数据查询,无法满足业务对长周期、全量数据的分析需求。
- 资源瓶颈:在双11、双12等大促期间,资源利用率长期高达85%以上,计算和存储资源紧耦合,导致弹性扩展能力不足,无法应对查询量的2倍增长。
- 数据孤岛:数仓(Hive)与分析引擎之间存在巨大的数据交换成本,形成事实上的“湖仓割裂”,阻碍了实时、高效的智能BI分析。
这些问题的核心,在于引擎能力与业务需求之间的鸿沟。业务需要的是“快、准、全”,而旧架构只能提供“慢、窄、割裂”。
二、 解决之道:StarRocks的三步走战略
唯品会没有选择简单的技术替换,而是规划了一条清晰的演进路径,分阶段解决不同层次的问题。

阶段一:存算一体,夯实分析底座(StarRocks 2.5)
- 目标:解决“快”和“全”的问题,替代Presto,提升5-10倍查询效率。
- 关键举措:
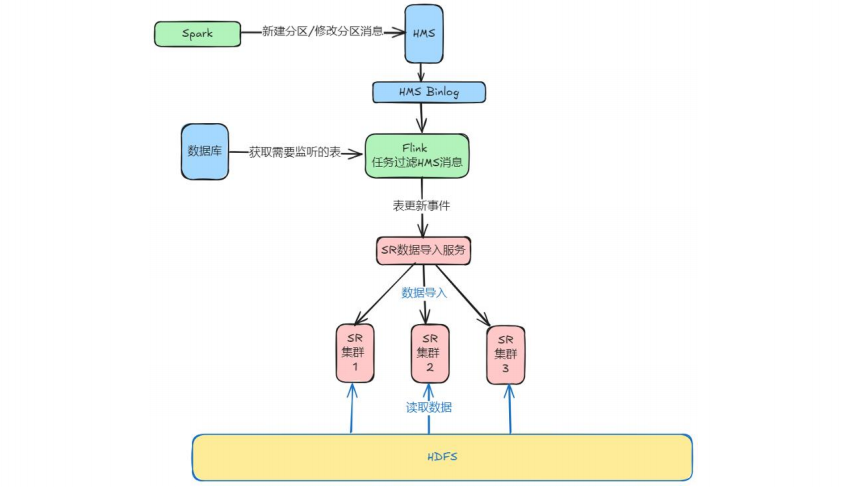
- 向量化引擎:利用StarRocks强大的向量化执行能力,将P85查询时间压缩至5秒内。
- 智能下推:将更多计算逻辑下推至存储层,减少数据传输,极大提升性能。
- 定制化导入优化:针对数据导入场景(如回刷历史数据),开发批量导入功能,并智能调度任务在空闲时段执行,保障查询稳定性与时效性。
- 成果:流量查询时间范围从14天延伸至一年以上,交易、流量等主题的平均耗时下降7倍以上,为后续演进打下坚实基础。
阶段二:存算分离,释放弹性潜能(StarRocks 3.1)
- 目标:解决“弹性”和“成本”问题,应对PB级数据和2倍查询增长。
- 关键举措:
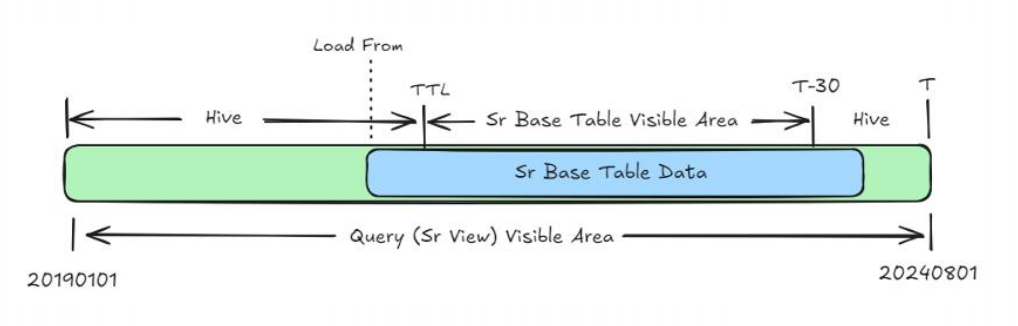
- 自研SQL路由与改写:灵活定义视图范围,动态调配内表(热数据)与外表(Hive冷数据)的分区比例,实现存储利用率最大化。
- Block Cache加速:对外部Hive表的数据块进行缓存,弥补纯外表查询的性能短板。
- HyperLogLog(HLL)优化:引入Velox的C++ HLL实现,替换原生函数,使亿级数据的秒级去重汇总性能提升4-5倍,并与Spark预聚合结果二进制兼容。
- 成果:在保证极致性能的同时,实现了计算与存储资源的独立弹性伸缩,大幅降低TCO。这标志着数据湖仓架构理念的落地。
阶段三:湖仓一体,赋能智能BI(StarRocks 3.x+)
- 目标:解决“智能”和“统一”问题,满足高并发、低延迟的智能BI分析需求。
- 关键举措:
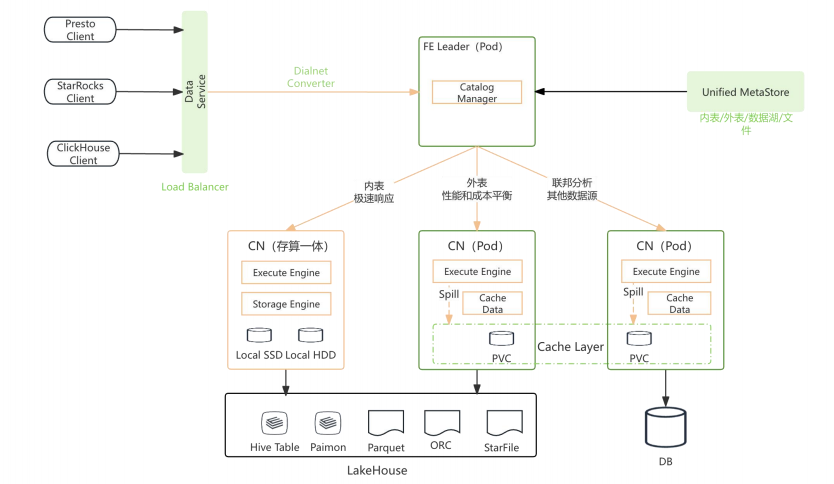
- 统一湖仓分析:通过存算分离架构,无缝融合数据湖(Hive)与数据仓库(StarRocks内表),业务无需关心数据物理位置。
- 多集群架构:根据SLA要求,将不同负载(如高并发BI查询 vs. 复杂ETL)自动路由到对应的专用集群,保障核心业务体验。
- Serverless架构:实现资源的动态扩缩容,按需付费,进一步提升资源效率。
- 成果:成功支撑了智能BI场景下,大量指标的并发查询(长周期30-180天、同环比等),真正实现了“指标全—数据湖仓;扩分析能力——多集群、存储分离”的解决方案。
三、 避坑指南:唯品会踩过的“雷”
- 不要忽视数据导入的稳定性:海量数据导入是常态,必须对导入任务进行精细化管理(如数量限制、批量回刷、空闲调度),否则会严重冲击在线查询服务。
- 纯内表模式不可持续:随着数据量激增,将所有数据存入内表会导致存储成本飙升且弹性受限。必须拥抱存算分离,灵活使用内外表混合模式。
- 预聚合与明细查询需平衡:虽然HLL等预聚合技术能极大加速汇总查询,但必须确保与上游(如Spark)的预聚合结果兼容,避免数据口径不一致。

四、 持续优化:从“能用”到“好用”
唯品会的优化是持续性的,体现在多个层面:
- 查询性能:通过向量化、下推、HLL优化等手段,不断压低P90/P95延迟。
- 资源效率:通过智能调度、潮汐混部(Spark和Presto)、Serverless架构,最大化资源利用率。
- 用户体验:通过延长查询时间范围、提升并发能力,让分析师能自由探索数据,而非被系统限制。
五、 未来展望:StarRocks Next - 统一分析场景
唯品会的终极目标,是构建一个 “One Fits All” 的统一分析平台。这意味着:
- 统一接入:所有分析请求通过统一的对外服务接入。
- 智能路由:平台根据查询的SLA、复杂度、数据源等特征,自动将其路由到最合适的执行引擎(可能是StarRocks内核,也可能是其他计算框架)。
- 场景全覆盖:无论是实时监控、即席查询、BI报表还是AI特征工程,都能在这个平台上得到最优解。
这不仅是技术的胜利,更是数据架构理念的升华——从“为不同场景建不同烟囱”,到“用一个平台服务所有场景”。这些前沿的架构思考与实践,在云栈社区这样的技术论坛中常常引发深度讨论。
结语
唯品会的StarRocks实践,是一部生动的现代数据架构演进史。它告诉我们,技术选型不是一锤子买卖,而是一个持续迭代、与业务共同成长的过程。从解决眼前痛点的存算一体,到面向未来的湖仓一体和统一分析,每一步都紧扣业务价值。对于所有正在构建或优化自己数据平台的企业而言,这份来自一线的深度实践,无疑是一盏宝贵的指路明灯。 |  发表于 2026-1-22 23:21:08
|
查看: 138|
回复: 0
发表于 2026-1-22 23:21:08
|
查看: 138|
回复: 0
