一、概述:Doris TVF的核心价值与湖仓一体定位
Apache Doris 的 Table Value Function(TVF)功能是实现“湖仓一体”(Lakehouse)架构理念的核心组件。它让分析师和工程师能够直接使用标准的 SQL 语句,将位于对象存储(如 S3)或分布式文件系统(如HDFS)上的原始数据文件,当作一张虚拟表来查询和分析。
借助 TVF,用户可以在数据湖(Data Lake)的探查敏捷性与数据仓库(Data Warehouse)的分析性能之间找到最佳平衡点。这恰恰是现代数据架构所追求的“湖仓一体”目标。
二、查询外部数据:语法、格式与自动推断机制
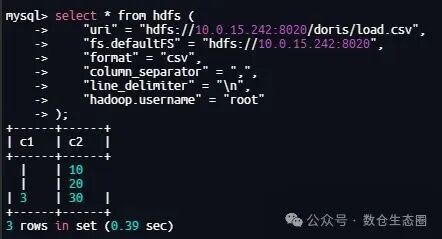
TVF 的核心操作非常直观,就是通过一个“函数调用”来访问外部数据。下面是一个查询 HDFS 上 CSV 文件的典型语法:
select * from hdfs (
"uri" = "hdfs://10.0.15.242:8020/doris/load.csv",
"fs.defaultFS" = "hdfs://10.0.15.242:8020",
"format" = "csv",
"column_separator" = ",",
"line_delimiter" = "\n",
"hadoop.username" = "root"
);
参数详解
| 参数 |
描述 |
| hdfs (函数名) |
指定数据源类型。TVF 支持多种协议,例如 s3() 用于访问 S3 兼容对象存储。 |
| uri |
外部文件的具体路径。支持通配符(*)、范围模式({1..3})进行多文件匹配。 |
| format |
文件格式。除 csv 外,还支持 parquet、orc 等高性能列式存储格式。 |
| column_separator |
列分隔符。 |
| line_delimiter |
行分隔符。 |
| hadoop.username |
访问 HDFS 集群的用户名。 |
| csv_schema |
手动指定列定义,格式为 col1:type;col2:type。 |
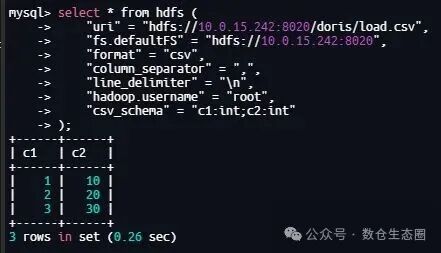
TVF 具备自动类型推断能力,但有时推断结果可能不符合预期(例如将整数误判为文本)。这时,你可以通过 csv_schema 参数进行手动矫正:
select * from hdfs (
"uri" = "hdfs://10.0.15.242:8020/doris/load.csv",
"fs.defaultFS" = "hdfs://10.0.15.242:8020",
"format" = "csv",
"column_separator" = ",",
"line_delimiter" = "\n",
"hadoop.username" = "root",
"csv_schema" = "c1:int;c2:int"
);
三、创建视图:封装查询逻辑,实现安全与复用
如果某个外部数据源需要频繁查询,反复编写冗长的 TVF 参数既低效也不利于维护。这时,你可以通过 CREATE VIEW 语句,将 TVF 查询逻辑封装成一个逻辑视图,真正做到“一次定义,多次使用”。
CREATE VIEW v1 AS
select * from hdfs (
"uri" = "hdfs://10.0.15.242:8020/doris/load.csv",
"fs.defaultFS" = "hdfs://10.0.15.242:8020",
"format" = "csv",
"column_separator" = ",",
"line_delimiter" = "\n",
"hadoop.username" = "root",
"csv_schema" = "c1:int;c2:int"
);
创建视图后,后续的所有分析都只需执行简单的 SELECT * FROM v1;。
视图的核心价值主要体现在以下场景:
- 简化查询:隐藏底层复杂的参数配置。
- 权限管理:你可以使用标准的 SQL 授权语句(如
GRANT SELECT_PRIV ON db1.v1 TO user1;)对视图进行细粒度访问控制,而无需暴露底层文件系统的认证信息。
- 逻辑抽象:即使底层文件路径或格式发生变化,也只需修改视图定义,上层应用代码无需任何改动。
四、数据导入:将外部数据持久化至Doris表
TVF 不仅仅用于查询,它更是数据从湖到仓(ELT过程)的桥梁。对于需要高频分析或与 Doris 内部表进行关联计算的场景,你可以将外部文件数据一次性导入到 Doris 内置的存储引擎中,从而获得极致的查询性能。
步骤一:创建Doris内部表
首先,定义目标表结构并指定数据分布策略。
CREATE TABLE IF NOT EXISTS insto
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`age` SMALLINT COMMENT "用户年龄"
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
步骤二:使用 INSERT INTO ... SELECT ... FROM TVF 导入
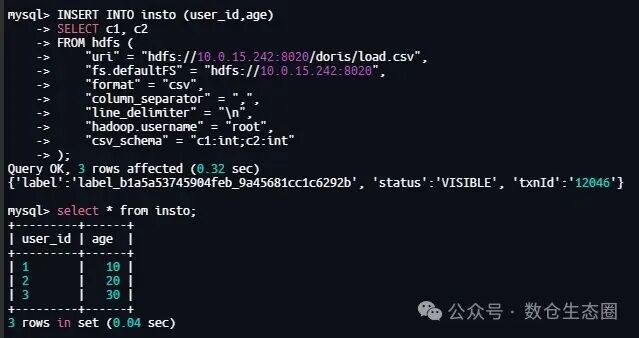
通过一条 SQL 语句,直接将 TVF 的查询结果写入到目标表中。
INSERT INTO insto (user_id,age)
SELECT c1, c2
FROM hdfs (
"uri" = "hdfs://10.0.15.242:8020/doris/load.csv",
"fs.defaultFS" = "hdfs://10.0.15.242:8020",
"format" = "csv",
"column_separator" = ",",
"line_delimiter" = "\n",
"hadoop.username" = "root",
"csv_schema" = "c1:int;c2:int"
);
在进行数据导入时,有几点性能与架构上的考虑:
- 批量导入:TVF 支持通配符,可以一次性导入像
file_*.csv 这样的多个文件。
- 列式格式优先:对于海量数据,优先从 Parquet 或 ORC 等列式存储文件导入,可以极大减少网络传输量和后端节点的扫描开销。
- 资源隔离:大规模数据导入属于重计算任务,建议在业务低峰期执行,或利用 Doris 的资源标签功能,将其导向专用的后端节点集群,避免影响在线查询服务的稳定性。
五、总结:Doris TVF的核心优势
Apache Doris 的 Table Value Function 远不止是一个查询文件的工具,它是连接数据湖与数据仓库的“智能管道”。其核心优势可以总结为三点:
- 敏捷性与性能的统一:TVF 既保留了数据湖对原始数据进行灵活、即时探查的能力,又能通过简单的 SQL 将数据无缝导入高性能的数仓引擎,轻松应对后续复杂的分析与高并发查询需求。
- 极简的 SQL 接口:全部操作都通过标准 SQL 完成,无需编写额外代码或依赖复杂的 ETL 工具,显著降低了数据分析的技术门槛和运维成本。
- 强大的生态集成:作为 Apache Doris 湖仓一体战略的关键组件,TVF 能够与外部表(如 Iceberg、Hudi)、数据集成工具(如 Flink、Spark)以及各类 BI 工具形成完整生态,为企业构建统一、高效的数据分析平台提供了坚实的技术底座。
掌握 TVF,数据团队就能构建一个既能敏捷响应探索性需求,又能稳定支撑核心报表的现代化数据架构。在云栈社区,你可以找到更多关于现代数据架构的深度讨论与实战案例。
 发表于 2026-2-23 03:51:00
|
查看: 189|
回复: 0
发表于 2026-2-23 03:51:00
|
查看: 189|
回复: 0
