本文整理自阿里采集分析平台工程技术负责人吴宝国老师在 Flink Forward Asia 2025 城市巡回深圳站中的分享。
在引入 Fluss 之前,我们的实时数据架构长期面临两个根本性挑战。
(1)成本高昂:行式消息队列导致资源浪费严重
我们过去主要依赖阿里内部的行式消息队列 TT(TimeTunnel)。以手淘的实时流量公共层为例,这张表包含了首页、闪购、搜索等多个业务的数据。每个下游业务(比如推荐系统)都需要一个独立的 Flink 作业来消费这张全量表,然后在作业内进行过滤,只保留自己关心的部分。

这种模式带来了三重成本问题:
- 存储与流量成本倍增:计费通常基于读写流量。即使每个业务只关心 1% 的数据,也需要为 100% 的全量数据付费。如果有 N 个业务,就要支付 N 倍的费用。
- Flink CU 资源浪费:Flink 作业需要消耗大量计算单元(CU)来读取、反序列化并丢弃无用的数据。很多时候,作业空跑不做任何逻辑处理,但依然产生高昂开销。
- 字段冗余读取:一张表可能包含数百个字段,但单个业务往往只需要其中几个。行式存储迫使消费者读取整行数据,造成巨大的 IO 和网络带宽浪费。
Fluss 通过其三大核心能力完美解决了上述问题:
- 多级分区(Multi-level Partitioning):支持按业务、按场景等维度对数据进行精细划分。
- 过滤下推(Filter Pushdown):消费者可以在订阅时声明过滤条件,数据在源头即可被精确过滤,避免全量拉取。
- 列式存储(Columnar Storage):允许消费者只读取所需的字段,极大降低数据消费量和 Flink CU 消耗。
(2)湖流割裂:Lambda 架构的运维与一致性困境
业界经典的 Lambda 架构虽然能同时提供实时和离线视图,但维护两套独立的批处理和流处理链路,带来了开发、运维成本高企以及数据统计口径不一致等问题。
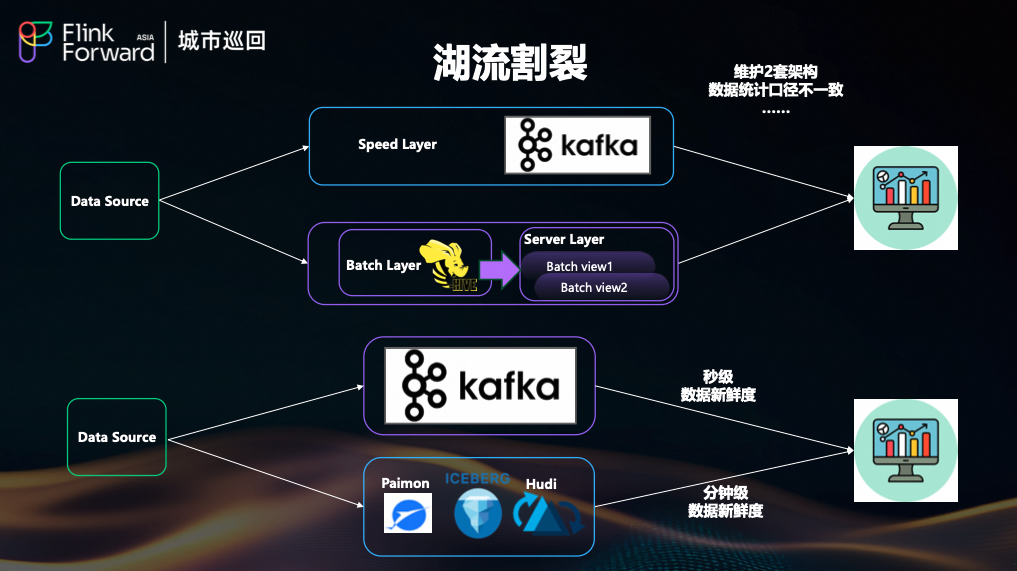
随着数据湖技术(如 Paimon、Hudi)的发展,湖仓一体架构成为主流,但它通常只能提供分钟级的数据新鲜度。对于搜索、推荐等要求秒级延迟的核心场景,我们仍需引入 Kafka 这类流式中间件,这实际上又回到了 Lambda 架构的老路,导致“湖”与“流”的割裂。
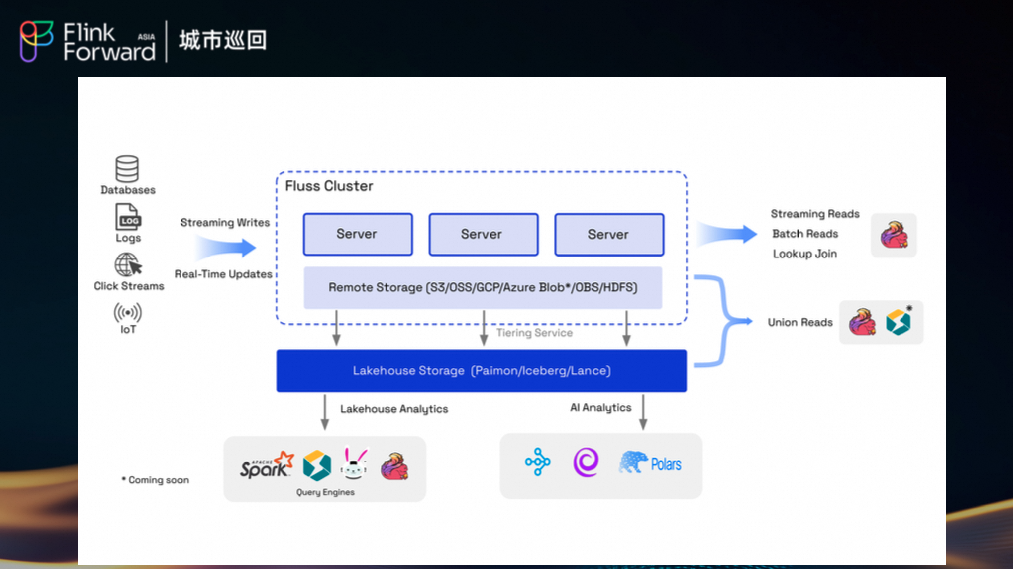
Fluss 的出现为我们提供了一个统一的解决方案:它既能作为高性能的流存储提供秒级数据新鲜度,又能通过其内置的分层存储(Tiering)能力无缝对接数据湖(如阿里内部的 Alake),真正实现了“湖流一体”,消除了双架构的痛点。
首次双11落地情况:大规模生产验证
2025 年的双 11 是 Fluss 在阿里集团的首次大促实战。目前,Fluss 已稳定服务于淘天(含通天塔、阿里妈妈等)、集团数据公共层、饿了么、淘宝闪购、高德、阿里影业等多个核心业务,核心场景主要集中在搜索、推荐、流量等。

在本次双十一期间,Fluss 展现了强大的承载能力:
- 数据量:4 PB/天
- TPS峰值:1 亿
- BPS峰值:100 GiB/s
这些数据充分证明了 Fluss 在大规模、高并发场景下的稳定性和可靠性,验证了其作为核心 实时数仓 组件的能力。
集群部署与架构设计
阿里集团内部的业务特点与云上有所不同,因此我们的部署架构也进行了针对性设计。
我们采用了“大集群 + 区域化部署”的模式。不同地域(如张北、上海)拥有独立的 Fluss 集群,而同一地域内的不同业务(如高德、钉钉、淘天)则通过数据库(DB)级别进行逻辑隔离。数据持久化在阿里自研的分布式文件系统盘古上,并通过 Tiering Service 同步至内部数据湖 Alake。
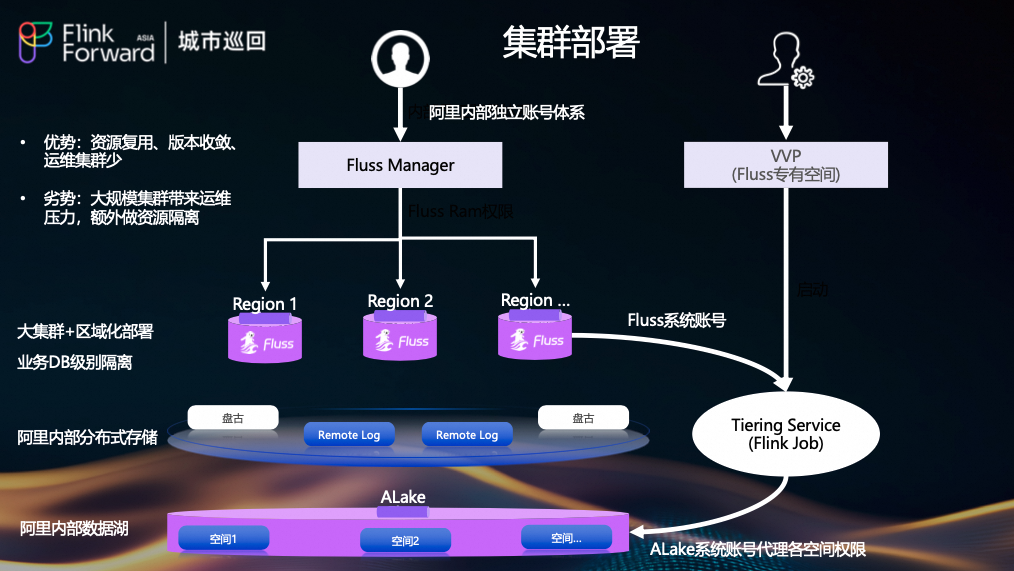
此架构的优势在于:
- 资源复用:多个业务共享一个大集群,提高资源利用率。
- 版本收敛:集群数量少,便于统一升级和管理。
- 运维集约:减少运维复杂度。
但也带来挑战:
- 运维压力:单一集群机器数量庞大,运维难度增加。
- 资源隔离:需要额外机制保障不同业务间的资源隔离。
为此,我们开发了独立的 Fluss Manager 来管理账号权限和集群配置,并在 VVP(Fluss 专有空间)中独立部署 Tiering Service(Flink Job),确保其稳定运行。为了保障如此大规模集群的稳定运行,我们在多个方面进行了深度建设。
稳定性建设
(1) 机架感知(Rack Awareness)
为防止物理机或机架故障导致数据丢失,我们实现了严格的副本放置策略。
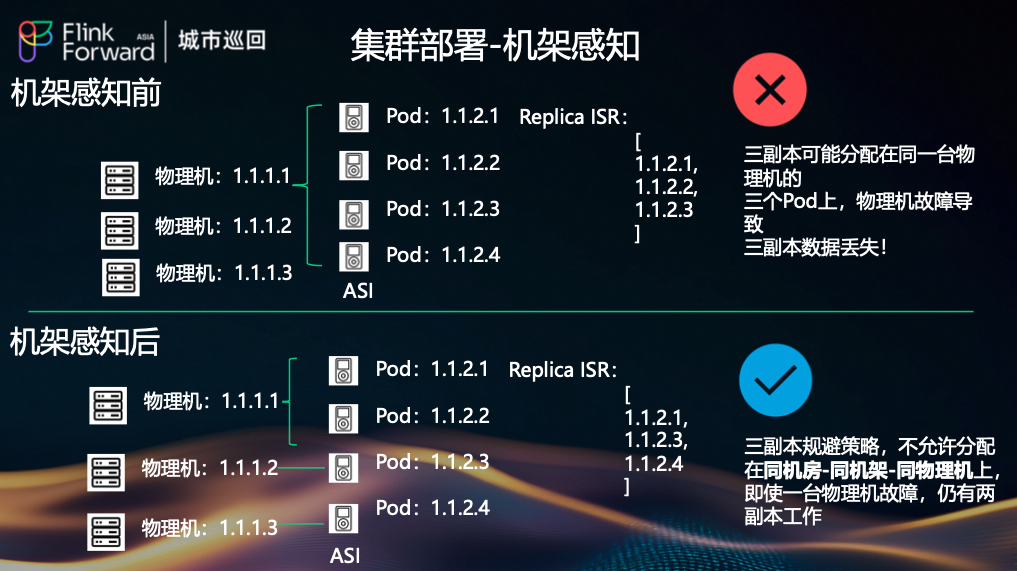
- 机架感知前:三个副本可能分配在同一台物理机上的三个 Pod 上。一旦该物理机故障,将导致三副本数据丢失!
- 机架感知后:三副本规避策略,不允许分配在同机房-同机架-同物理机上。即使一台物理机故障,仍有两副本工作,保障数据安全。
(2) 监控告警体系
我们建立了覆盖全栈的立体化 监控体系 告警体系:
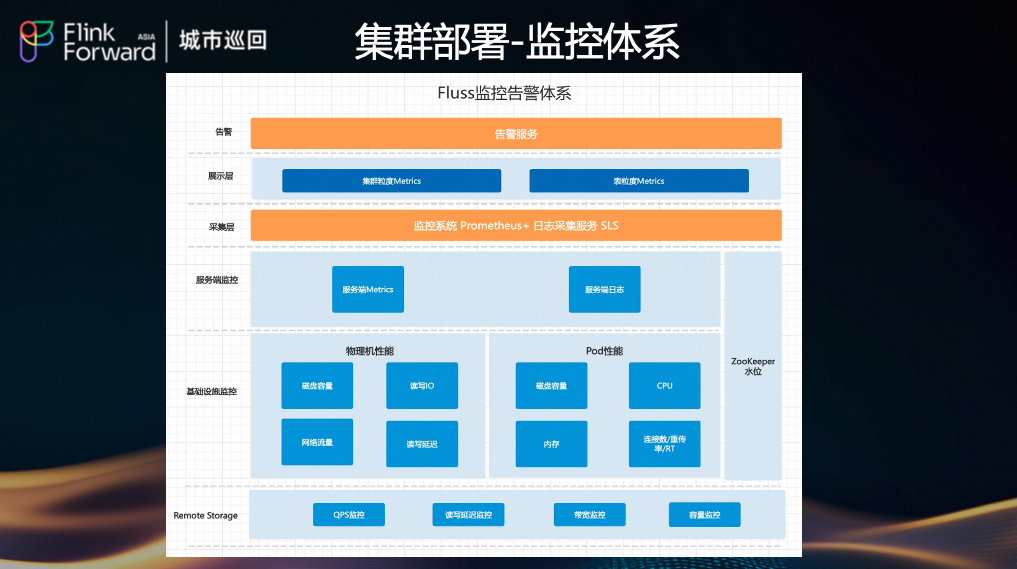
- 基础设施监控:包括物理机性能(磁盘容量、读写IO、网络流量、CPU、内存)和 Pod 性能。
- 服务端监控:监控 CoordinatorServer、Tablet Server 等核心组件的 Metrics 和日志。
- 远程存储监控:监控 Remote Storage (OSS/Pangu/HDFS) 的 QPS、读写延迟、带宽和容量。
- 数据湖监控:监控 Alake 的水位、读写情况,防止因数据灌入过载而影响湖仓。
- 告警服务:基于 Prometheus + SLS 的监控系统,实现及时告警。
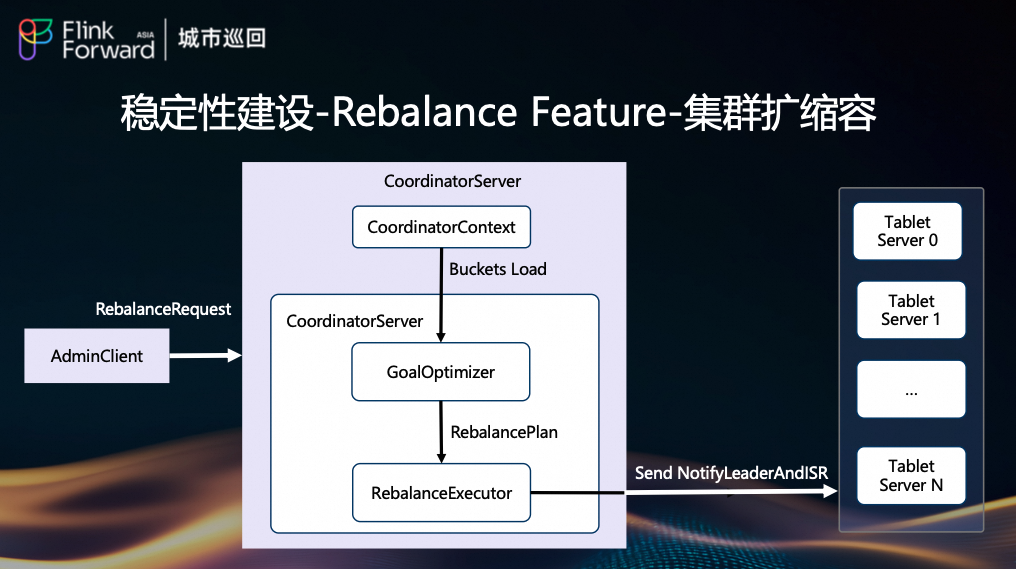
(3) 集群扩缩容(Rebalance Feature)
随着业务增长,集群需要动态扩容。我们实现了 Rebalance 功能:
AdminClient 发起 RebalanceRequest。CoordinatorServer 收到请求后,GoalOptimizer 生成 RebalancePlan。RebalanceExecutor 执行计划,通知 Tablet Server 迁移 Bucket Leader 和 ISR。- 新节点加入后,负载均衡,完成扩容。
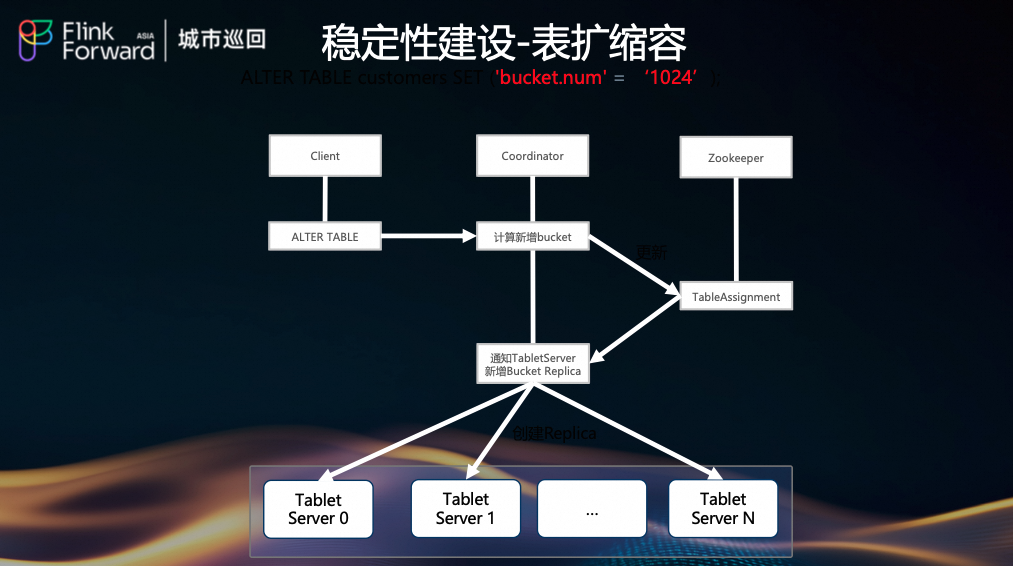
(4) 表扩缩容(Bucket Rescale)
当单表流量增大时,可通过 ALTER TABLE 增加 Bucket 数量。
- Client 发起
ALTER TABLE 命令。
- Coordinator 计算新增 Bucket 的分布,并更新
ZooKeeper 中的 TableAssignment。
- Coordinator 通知所有 Tablet Server 创建新的 Bucket Replica。
- Tablet Server 创建 Replica 并开始接收数据。
注意:客户端需重启以感知新分区,期间消费任务可能有短暂波动。
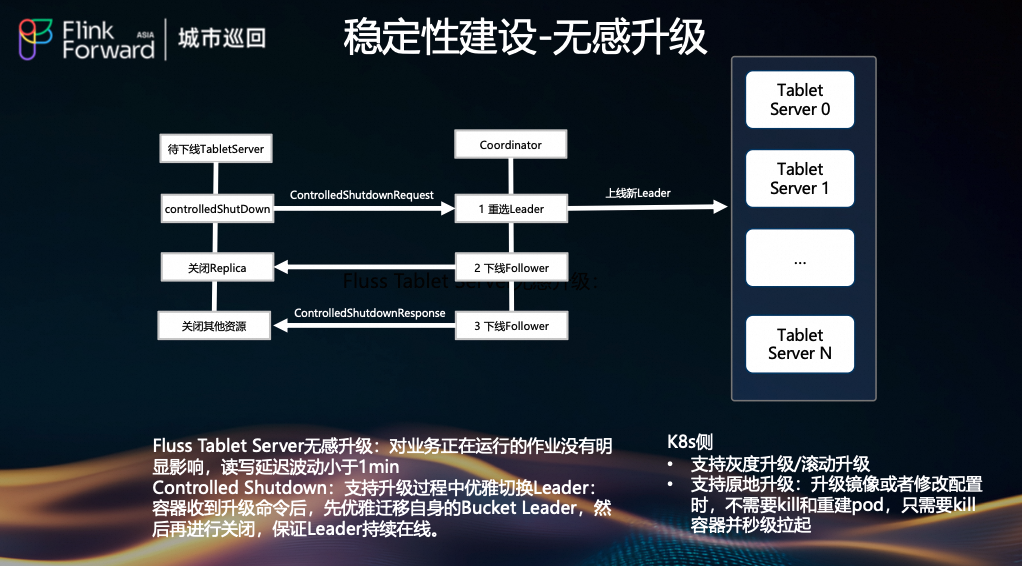
(5) 无感升级(Controlled Shutdown)
为保障升级过程对在线作业无明显影响,我们实现了无感升级:
-
待下线 Tablet Server 发送 controlledShutdownRequest 给 Coordinator。
-
Coordinator 执行
- 步骤1:重选 Leader(新 Leader 上线)。
- 步骤2:下线 Follower。
- 步骤3:关闭其他资源。
-
整个过程保证读写延迟波动小于 1 分钟,Leader 持续在线。
-
K8s 侧支持:支持灰度升级、滚动升级和原地升级(kill pod 并秒级拉起),提升升级效率。
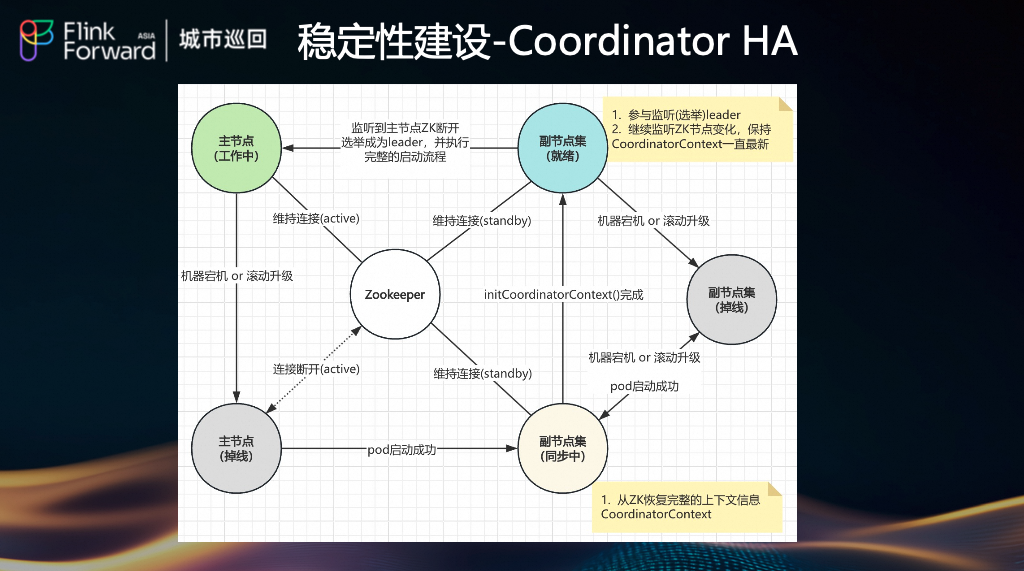
(6) Coordinator HA
Coordinator 是集群的“大脑”。我们为其构建了高可用架构:
- 主备选举:通过 Zookeeper 实现主备选举。
- 状态同步:副节点持续监听 ZK 节点变化,保持
CoordinatorContext 一致。
- 故障恢复:主节点宕机后,副节点自动选举为新主节点,并从 ZK 恢复上下文信息,确保元数据连续性。
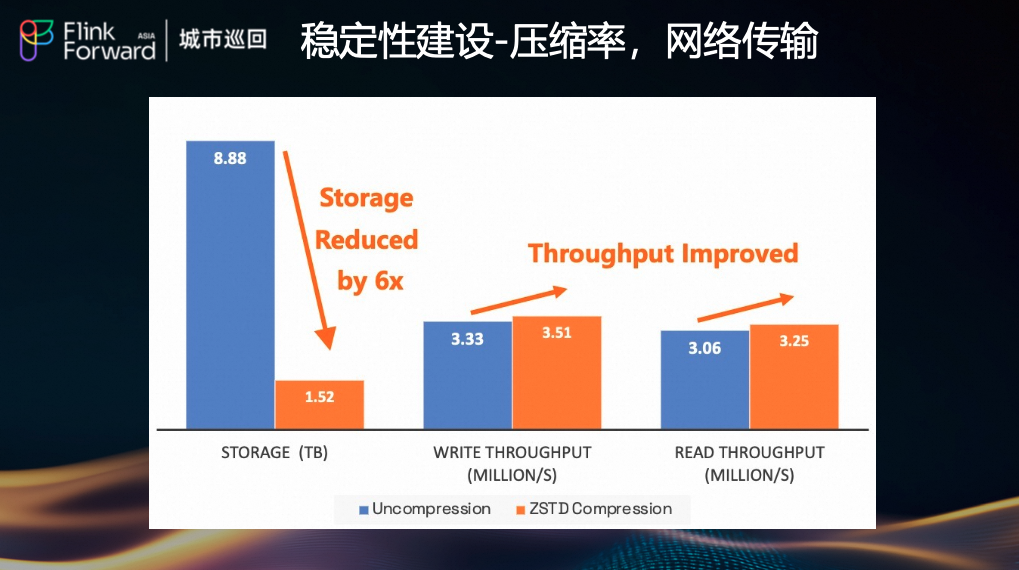
(7) 压缩率与网络传输优化
为应对大规模集群的网络带宽瓶颈,我们集成了 ZSTD 列压缩算法。
- 实测效果:在淘系数据上,开启 ZSTD 后,存储空间下降 6 倍(8.88TB → 1.52TB)。
- 性能影响:写吞吐略有提升(3.33M/s → 3.51M/s),读吞吐基本持平(3.06M/s → 3.25M/s),CPU/内存开销可控。
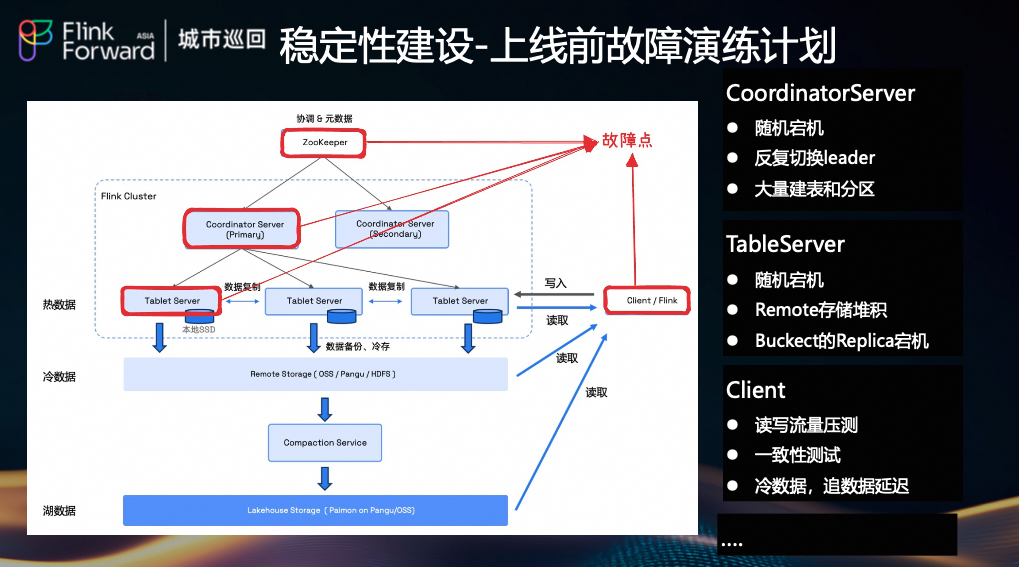
(8) 上线前故障演练计划
上线前,我们执行了详尽的故障演练计划,模拟极端场景:
- CoordinatorServer:随机宕机、反复切换 leader、大量建表和分区。
- TableServer:随机宕机、Remote 存储堆积、Bucket 的 Replica 宕机。
- Client:读写流量压测、一致性测试、冷数据追数据延迟测试。
- 其他:网络拥塞、磁盘挂掉、Zookeeper 故障等。
通过这些演练,全面验证了系统的健壮性、容错能力和数据一致性。
湖流一体:统一架构的演进
在湖流一体这块,我们会直接从 Fluss Manager 发起“湖流一体表”的创建操作。创建完成后,会使用 Fluss 的生产账号(而不是业务自己的账号),在 Paimon 中为业务直接创建一张对应的 Paimon 表。
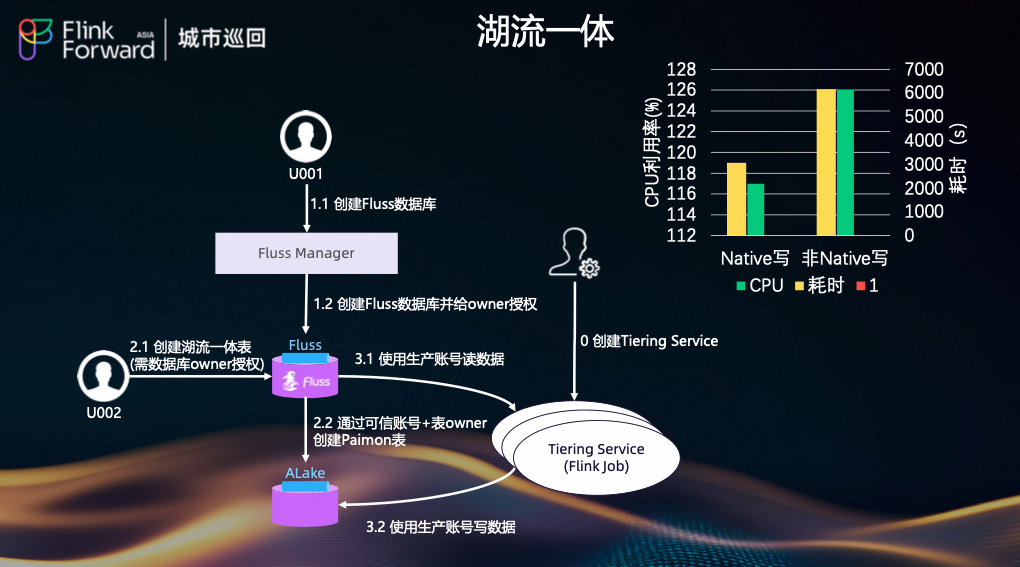
这张 Paimon 表与 Fluss 中的表在命名上完全一致,包括 Namespace 和 DB 名称都保持统一。这样一来,业务在 Paimon 侧可以给这张表打上“湖流一体表”的标记,在 Fluss 侧也能看到它是“湖流一体表”,对业务来说是一张“看起来统一”的表,但在底层实际上是两张独立的物理表。
数据同步方面,我们通过 Tiering Service 集群配合内部 Flink 集群,由生产账号将 Fluss 中的数据以分钟级或秒级的粒度同步到 Paimon。与此同时,在 Tiering Service 上做了一系列 Native 级别的优化,使得整体性能相较于通用的 Flink 接入方式(Flink Native)会更好一些。
业务实践案例与核心收益
Fluss 的落地为多个业务场景带来了显著收益,下面我将逐一介绍。
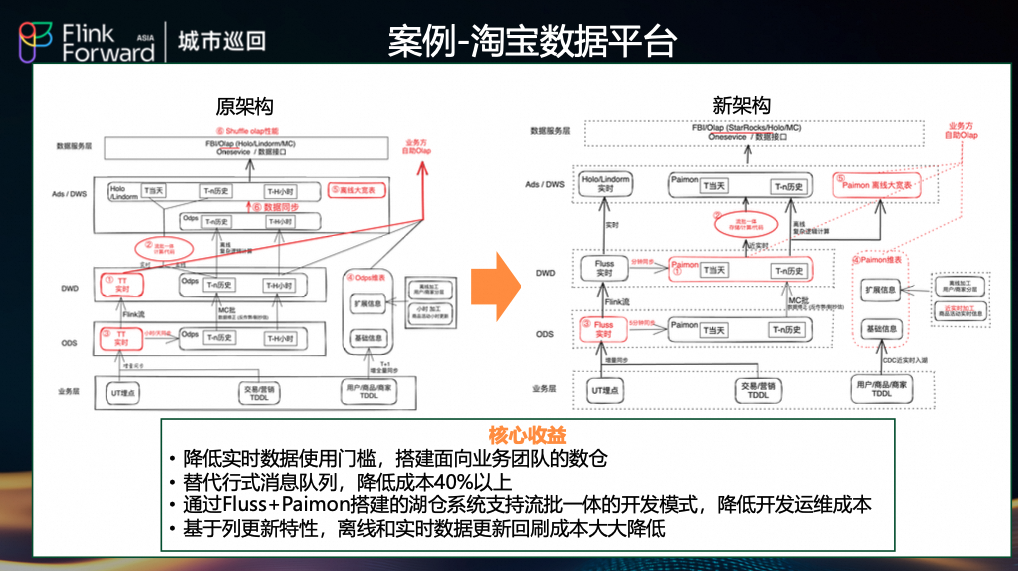
(1)淘宝数据平台:实时数仓重构
- 原架构:依赖行式消息队列(TT)和离线数仓(MaxCompute/ODPS),数据新鲜度在小时级。
- 新架构:采用 Fluss + Paimon 湖仓架构,数据新鲜度提升至秒级。
- 收益:
- 替代行式消息队列,整体成本降低 40% 以上。
- 基于 Fluss 的列更新特性,离线/实时数据回刷时只需更新变更字段,回刷成本大幅降低。
- 简化了数据链路,下游 OLAP 引擎(如 StarRocks)可直接查询 Paimon 表。
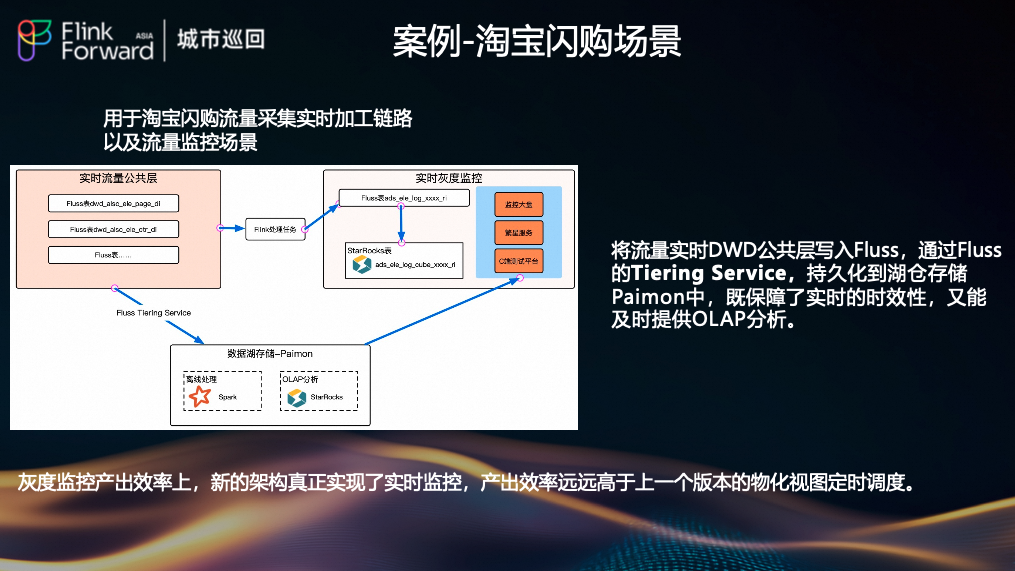
(2)淘宝闪购:实时监控与加工
将流量实时 DWD 公共层写入 Fluss,并通过 Tiering Service 持久化到 Paimon。此架构既保障了秒级时效性,又支持高效的 OLAP 分析,真正实现了实时监控,产出效率远超旧版基于物化视图定时调度的方案。
(3)通天塔(AB实验平台):降本增效
- 痛点:行式存储导致整行消费,资源消耗高(曝光表 44 个字段,平台仅需 13 个);数据探查困难;大 State 作业运维复杂、不稳定。
- 方案:利用 Fluss 的列裁剪能力,结合 Paimon 存储和 StarRocks 查询。
- 收益:读 Fluss 的 Flink 作业CPU 占用减少 59%,内存占用减少 73%,IO 减少 20%。同时,通过 KV 表的 Merge 引擎和 Delta Join 技术,解耦了作业与状态,提升了灵活性。

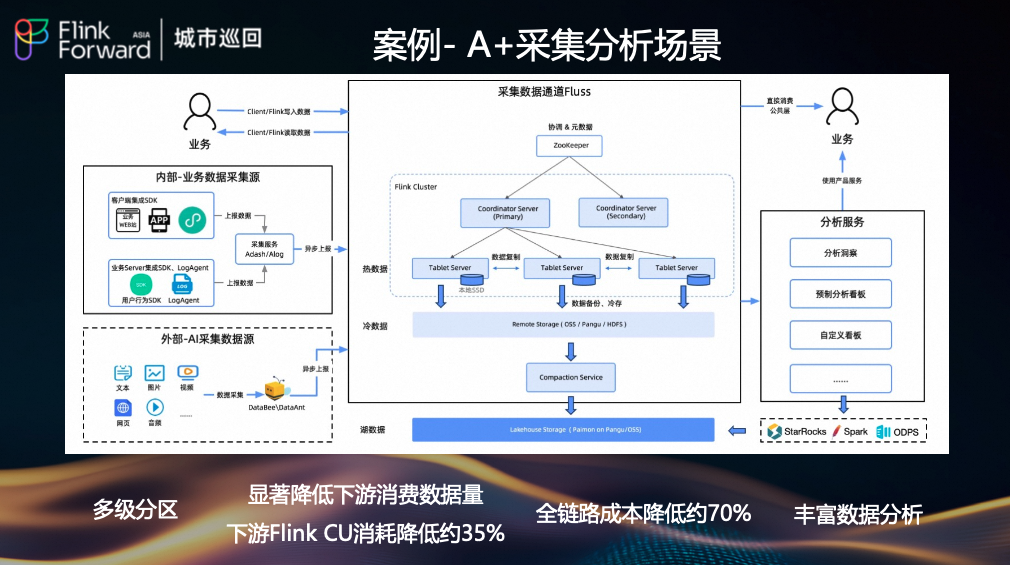
(4)A+ 采集分析平台:全链路优化
在流量公共层应用 Fluss 的多级分区能力,显著降低了下游消费的数据量,使得下游 Flink CU 消耗降低约 35%,全链路成本降低约 70%。
未来规划
展望未来,我们将从以下方向持续投入:

- 扩大服务规模:将 Fluss 服务推广至更多集团业务,巩固其作为统一实时数据通道的地位。
- 全面推进湖流一体:深化 Fluss 与 Paimon/Alake 的集成,打造更成熟、易用的湖流一体解决方案。
- 追求更高性能:持续优化 Fluss 内核,在吞吐、延迟、资源利用率等方面达到业界领先水平。
- 探索新场景:构建业界领先的 Agent 采集与评测一体化平台,为 AI Agent 在代码、电商、数据等场景的效果评估与优化提供数据基石。
以上便是我们在阿里双11万亿级流量场景下,落地Fluss列式流存储,并实现显著成本优化与稳定性保障的核心实践。如果你对大规模实时数据处理架构有更多的想法,欢迎到 云栈社区 参与交流。
 发表于 2026-1-31 04:28:18
|
查看: 174|
回复: 0
发表于 2026-1-31 04:28:18
|
查看: 174|
回复: 0
