本次分享将介绍快手实时数据湖在 AI 与 BI 场景下的架构升级实践,主要内容围绕以下三点展开:
- 快手引入数据湖技术的背景
- Hudi 在快手的实践经验与核心技术优化
- 未来的规划与展望
01 快手引入数据湖技术的背景
1. 历史痛点
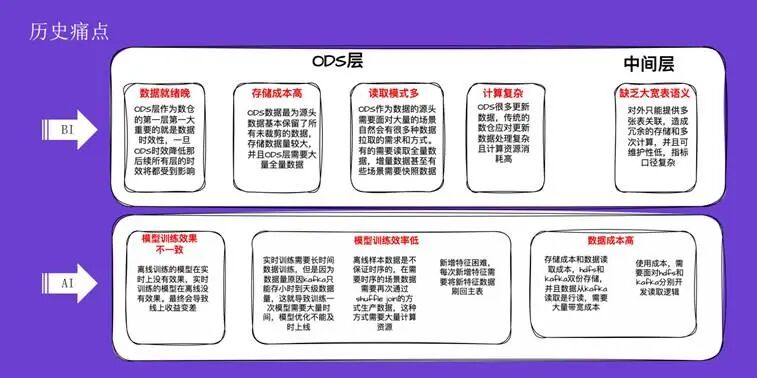
在历史架构中,无论是 BI 还是 AI 场景,都存在诸多痛点。
首先是 BI 方向,ODS 层和中间层分别面临不同挑战。ODS 层数据就绪晚,会直接影响下游所有数据层的时效性,存在数据交付延迟的风险。其次是存储成本高,ODS 层作为源头数据,保留了大量未经裁剪的数据,且数据量庞大,许多场景需要全量存储。第三是读取模式多样,作为数据源头,ODS 层需要支持全量、增量乃至快照级别的数据拉取需求。最后是计算复杂,尤其在处理数据流更新场景时,merge 逻辑的资源消耗非常高,在任务高峰期资源抢占严重。
在中间层,传统的加工方式缺乏大宽表语义。业务方为满足需求,不得不对外提供多张表的关联,这不仅造成了冗余存储,也使加工逻辑变得复杂,可维护性低,指标口径也难以统一。
AI 方向 的痛点则更多体现在业务层面。第一是模型训练效果不一致。传统架构中,离线和实时的数据存储、读取逻辑与接口均不相同,导致同一个模型在离线和实时环境下训练出的效果存在差异。第二是模型训练效率低下,主要由三个原因导致:
- 在实时训练场景,传统实时数据存储(如 Kafka)生命周期短,无法回放大量历史数据进行训练。
- 在离线场景,数据不保证时序性,而许多训练任务需要时序数据,导致需要进行二次开发。
- 新增特征困难,每次新增特征列都需要重新关联和计算,涉及大量重复工作。
最后一个痛点是成本高昂,主要体现在 大数据 存储(HDFS)与消息队列(Kafka)的双份存储带来的成本,以及针对不同存储介质开发不同服务所带来的高昂开发成本。
2. Hudi 如何助力快手 AI & BI
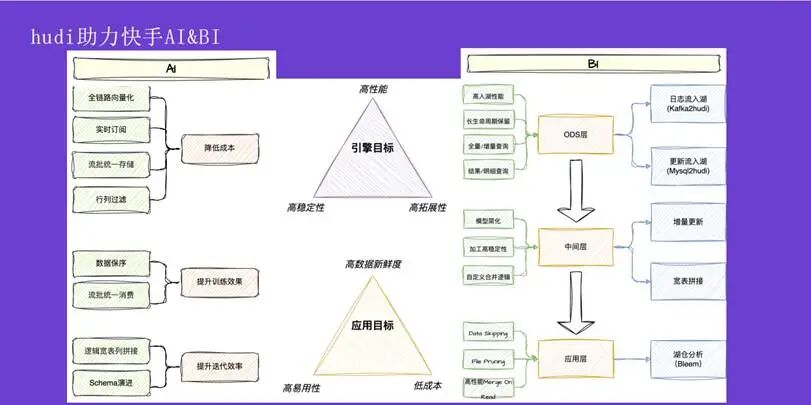
为了解决上述痛点,我们基于 Apache Hudi 为 AI 和 BI 场景开发了针对性的功能。
在 AI 方向,通过实现全链路向量化、流批一体存储和实时订阅,显著降低了成本。通过保障数据顺序以及流批统一消费,确保了模型在离线和实时数据上训练效果的一致性。此外,借助逻辑宽表和 Schema 自动演进能力,大幅提升了特征迭代的效率。
在 BI 方向,为 ODS 层开发了 kafka2hudi 和 mysql2hudi 两款产品,分别应对日志数据与变更数据的入湖需求。这些产品实现了高性能入湖、长生命周期数据保留,并支持增量、全量、明细等多种查询模式。在中间层,通过支持增量更新和宽表拼接,解决了传统架构缺乏大宽表语义的问题,简化了加工逻辑,提升了稳定性,并允许用户自定义合并策略。在应用层,结合 Hudi 的读取优化与快手内部的 Bleem 技术,极大地加速了数据查询性能。
02 Hudi 在快手的实践经验
1. BI 传统数仓架构升级
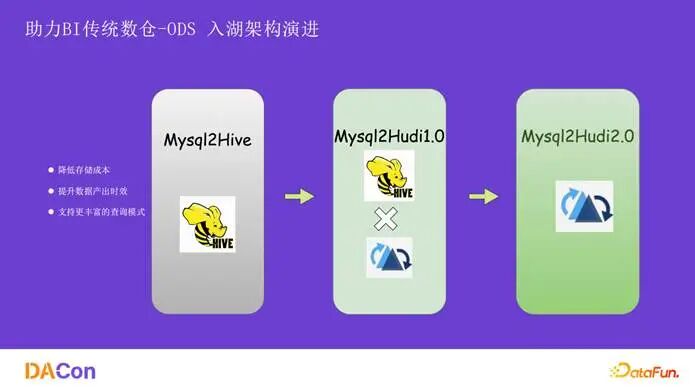
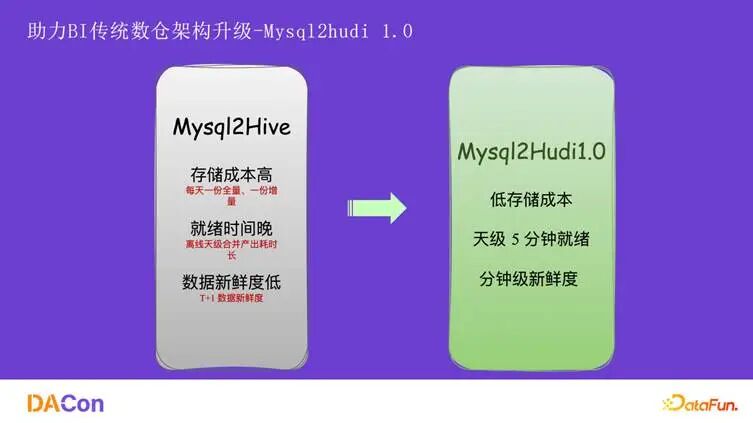
首先介绍在 BI 方向,特别是 ODS 入湖架构的演进。如图所示,架构从 mysql2hive 演进到 mysql2hudi1.0,再到如今的 mysql2hudi2.0。经过这三代演进,主要实现了三方面的提升:降低了存储成本、提升了数据产出时效、支持了更丰富的查询模式。
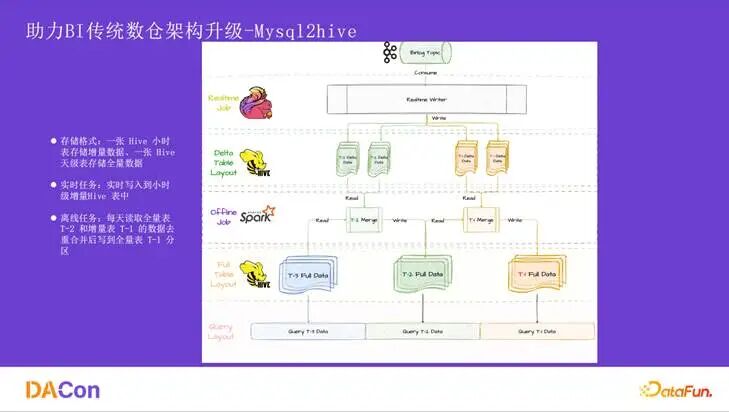
Mysql2Hive 的架构如图所示,数据通过 Flink 消费后写入增量分区,同时每天会有一个全量分区。合并逻辑是使用 T-2 的全量分区与 T-1 的增量分区进行合并,生成 T-1 的全量分区。这种模式导致每天都需要存储一份全量数据,外加一份增量数据,存储成本很高。此外,merge 操作集中在凌晨高峰期,资源抢占严重,导致数据就绪时间很晚。
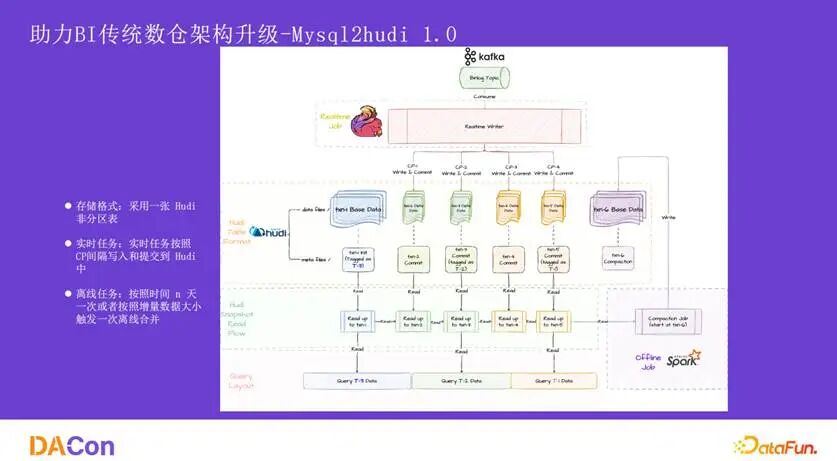
为了解决 Mysql2Hive 的问题,我们开发了 Mysql2Hudi 1.0。数据摄入方式相同,但写入的是一张非分区的 Hudi 表。每 5 分钟写入一次 log 文件,通过 Hudi 的 time travel(时间旅行)能力,可以读取任意时间点的全量数据快照。这种方式实现了“一份存储,支持多个时间点的全量读取”,无需每天存储全量数据,显著降低了成本。
同时,Hudi 的 Merge On Read 表类型无需在固定时间点进行全量合并,只要数据写入,下游即可读取,数据就绪时间从原来的数小时缩短到 5 分钟以内。
尽管 1.0 版本在成本和时效上取得了巨大提升,但它也存在问题。由于是单张非分区表,当数据生命周期很长时,单目录下的文件数量会急剧增长,影响 HDFS 的 ls 性能,进而影响 Hudi 的读写效率。为此,我们采用了折中方案:近 30 天的热数据存放在 Hudi 表,30 天前的冷数据则归档到原来的 Hive 表。
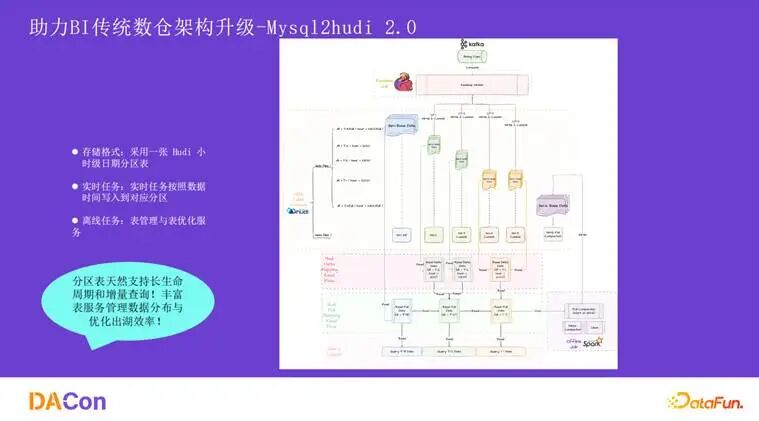
今年我们推出了 Mysql2Hudi 2.0。最大的变化是设计了一张分区 Hudi 表,支持混合分区(增量分区和全量分区)。实时任务将数据写入增量分区,并定期/定量触发 full compaction,将数据合并后写入全量分区。读取时,例如需要 3 号的全量数据,系统会读取 1 号的全量分区以及 1 号到 3 号之间的所有增量分区,通过跨分区 bucket join 得到结果。
分区设计天然解决了长生命周期带来的单目录文件过多问题,并且很好地支持了分区级别的增量查询。同时,通过 table service 来保证数据出湖的效率。
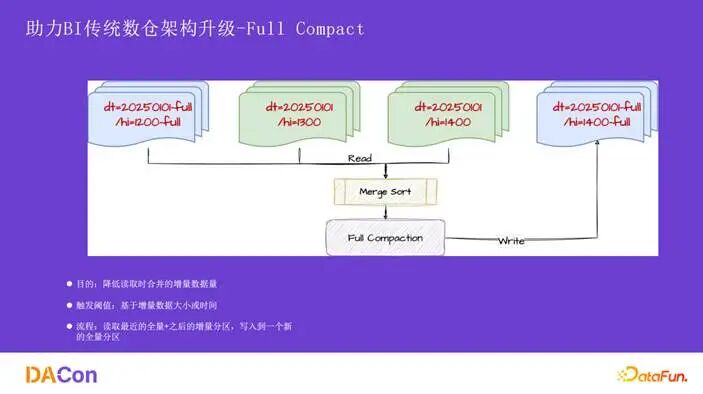
Full Compaction 会定期或定量地将增量分区数据与最近的全量分区数据合并,写入一个新的全量分区。触发策略有两种:一是基于增量数据大小,当单个 bucket 下累积的 log 文件总大小达到阈值时触发;二是基于时间,例如 7 天未进行 full compaction 则自动触发,以控制增量文件数量,保障读取性能。
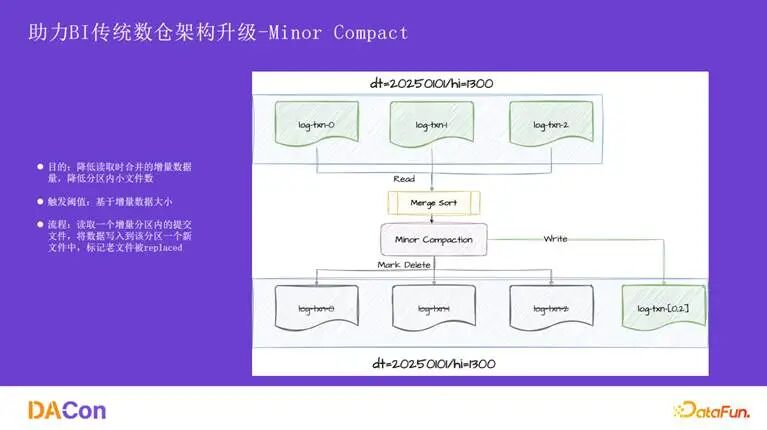
Minor Compaction 则用于解决单个增量分区内部的小文件问题。它会将一个分区内的多个 log 文件合并为一个大文件,减少 log block 的数量,从而降低读取开销。其触发阈值基于分区内的 log 文件数量。
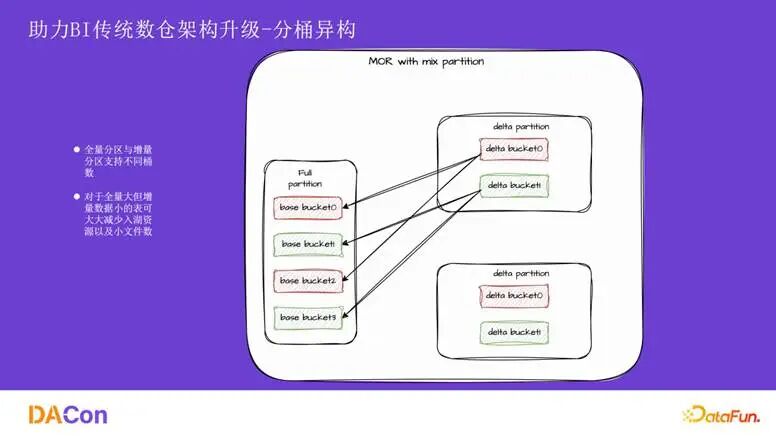
对于存量数据巨大的表,如果 bucket 数设置过少,会导致单个文件过大,影响读写并发度;如果 bucket 数过多,则实时写入时需要缓存大量文件的数据,消耗过多资源。我们引入了分桶异构机制,允许全量分区和增量分区设置不同的桶数。
如图所示,全量分区设置为 4 个桶,增量分区则设置为 2 个桶。读取时,全量分区的 bucket0 和 bucket2 的数据会共同读取增量分区的 bucket0,再通过数据过滤得到正确结果。这样,对于存量数据大、增量数据少的表,可以将增量分区的桶数设置得较小,降低实时读写压力。
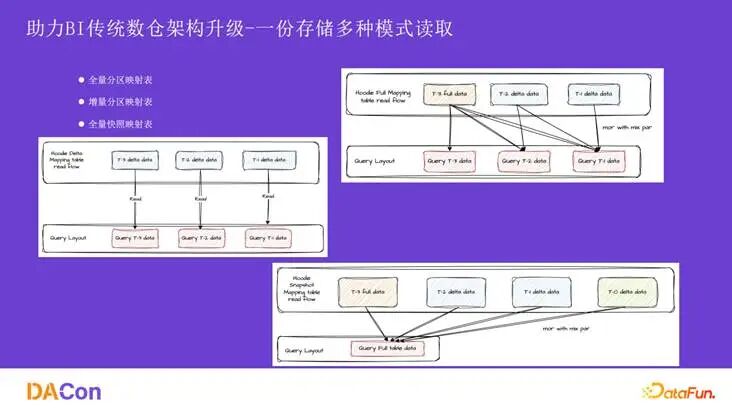
为了应对多种数据拉取需求,我们基于同一份物理存储,设计了三种逻辑映射表:
- 全量分区映射表:基于 Hive 分区语义,读取时自动合并对应的全量与增量分区。
- 增量分区映射表:直接映射物理表的增量分区。
- 全量快照映射表:支持读取任意提交时刻的全量数据快照,逻辑与全量分区映射表类似,但会将所有已提交的增量分区数据纳入合并范围。
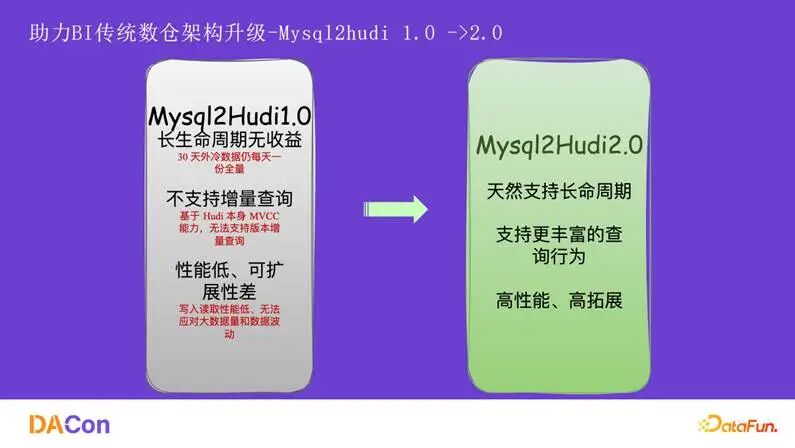
从 1.0 升级到 2.0,我们实现了对长生命周期的原生支持、更丰富的查询模式(如增量查询),并在性能与扩展性上做了大量优化(如分桶异构、sort merge 优化)。
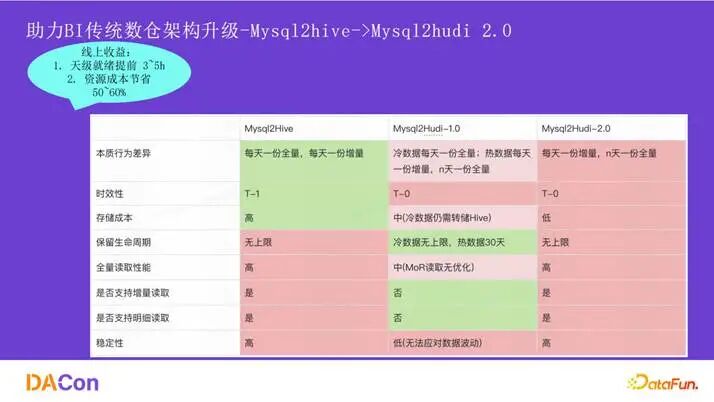
上图展示了全面的指标对比。Mysql2Hudi 2.0 在成本、生命周期、查询灵活性等方面表现最优。总体成本相比 Mysql2Hive 和 1.0 版本平均节约了 50% 到 60%。
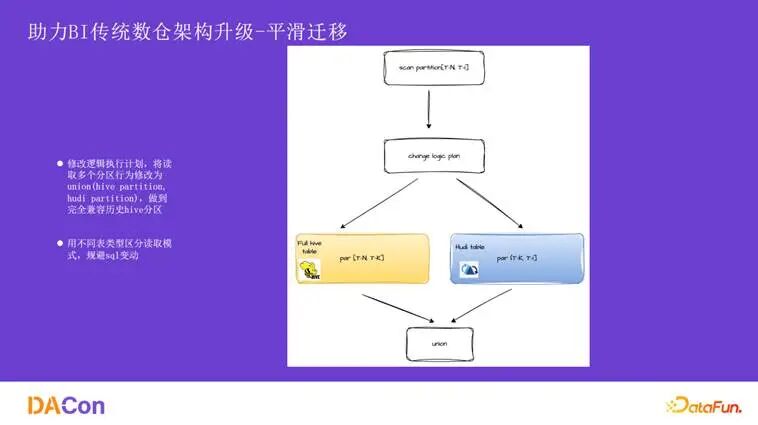
为了让用户无感、低成本地迁移到 2.0,我们做了两件事:
- 逻辑计划改写:在读取映射表时,引擎会自动将查询改写成
union 逻辑,一部分读取历史 Hive 分区数据,另一部分读取新的 Hudi 分区数据,避免了历史数据的迁移。
- 表类型区分:通过不同的映射表类型(全量、增量、快照)来区分读取模式,避免了在业务 SQL 中暴露复杂参数或进行修改,对下游任务透明。
2. AI 存储架构升级
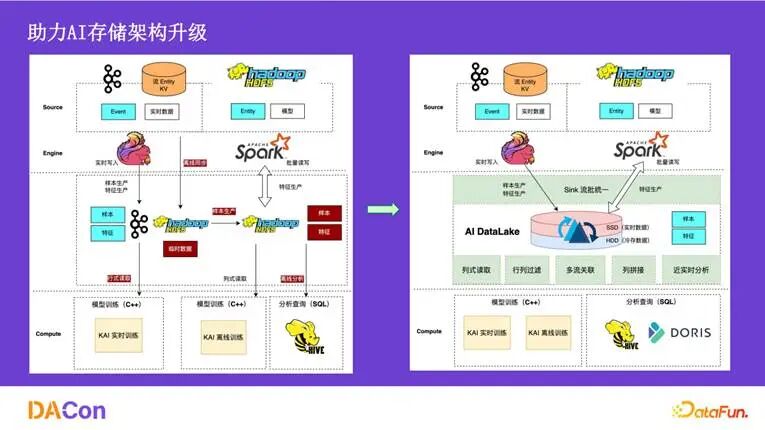
接下来分享 AI 场景的架构升级。上图展示了从历史架构到新架构的演进。核心变化在于中间层,历史架构中离线和实时是两套独立的处理链路和存储介质,导致数据不一致。统一到 AIDataLake 后,无论是数据摄入、存储还是读取层都实现了统一,并且支持批处理以进行数据修正。
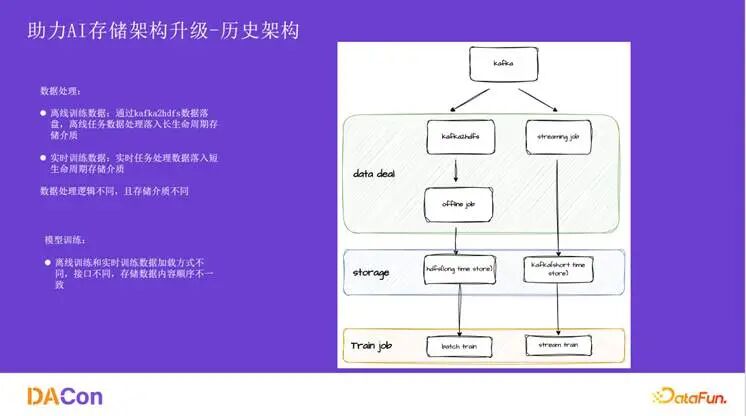
历史架构中,离线数据通过 Kafka 落盘到 HDFS,实时数据则通过流处理任务写入另一套短生命周期存储。训练任务需要为这两条链路开发不同的数据加载逻辑,导致存储介质和数据内容都可能不一致。
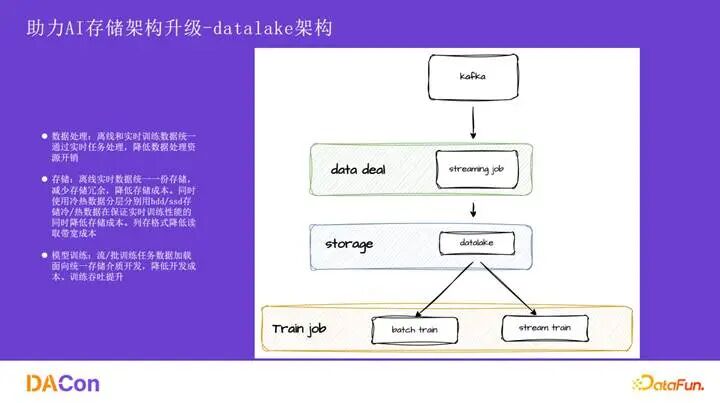
切换到 AIDataLake 后,所有数据都通过实时任务逻辑写入统一的 Hudi 存储层。在模型训练的数据读取侧,我们抽象了一个中间服务层,使得离线和实时场景的数据消费逻辑完全一致。这大大降低了数据摄入和转化的计算成本。
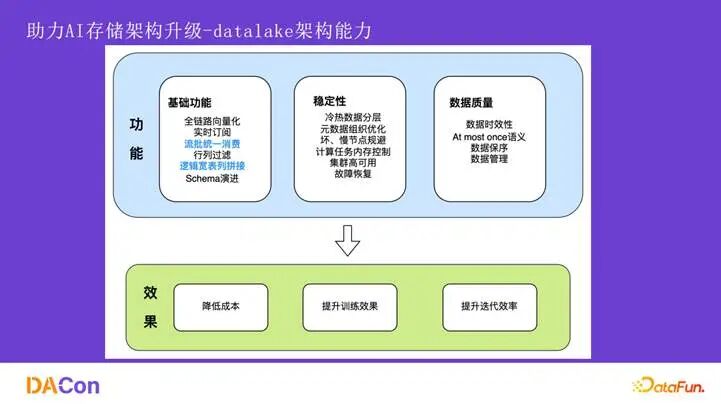
整体上,我们实现了流批一体消费、逻辑宽表列拼接、向量化等功能,并在稳定性和数据质量上做了大量工作。最终取得了三方面效果:降低了千万级别成本、保证了离/实时训练效果一致、在部分场景将特征迭代效率提升了10倍以上。
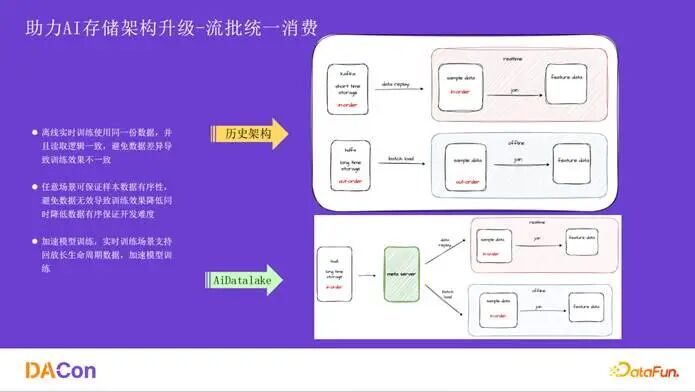
流批统一消费 是保证训练效果一致的关键。历史架构中流批处理链路和存储介质分离,且数据时序无法保证。新架构通过统一的 meta server 服务来抽象数据读取逻辑,解决了多语言调用问题,并基于保证时序的长生命周期存储,使得离线和实时训练都能读取到有序且可大量回放的一致数据。
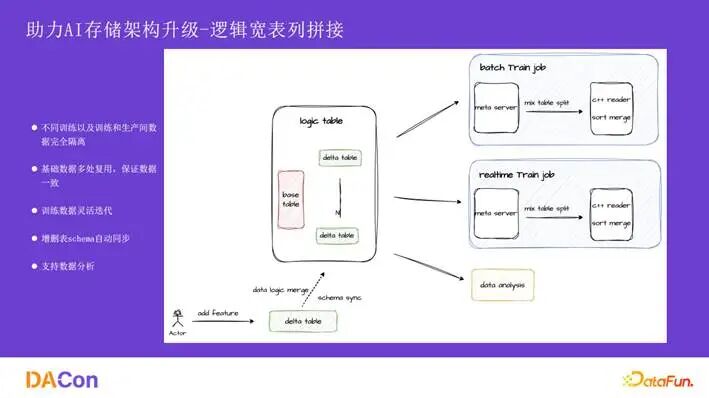
逻辑宽表 解决了新增特征迭代效率低的问题。以往加特征需要将样本与特征数据物理拼接并回写,周期长。现在,我们在逻辑上关联稳定的 base 表与可灵活增删的 delta 表。新增特征只需在逻辑上加一张 delta 表,Schema 自动同步,对用户无感。不同的训练任务可通过不同的逻辑宽表进行隔离,避免相互影响,同时实现了基础数据的复用。
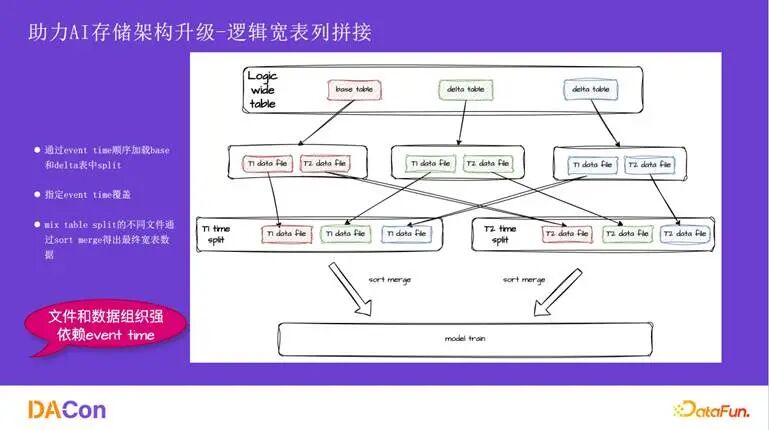
逻辑宽表的拼接依赖于元数据层对 base 表和 delta 表的组织,要求文件与数据在保证时序 (eventtime) 的前提下能够正确对应。业务实现和技术实现都强依赖 eventtime,而社区版 Hudi 的 timeline 是基于 process time 的,无法灵活支持按事件时间范围的数据变更。
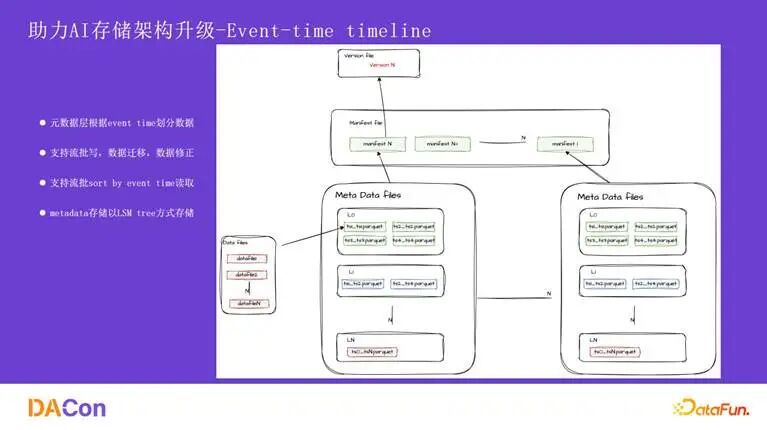
为此,我们设计了 Event-time timeline。其最终效果是支持按 eventtime 顺序消费数据,并能根据 eventtime 灵活覆盖数据。在此基础上,我们还实现了无锁提交以避免写入阻塞,支持了流批一体消费,并在数据分析层面做到了与实体表无差异的体验。
3. 快手数据湖核心技术优化
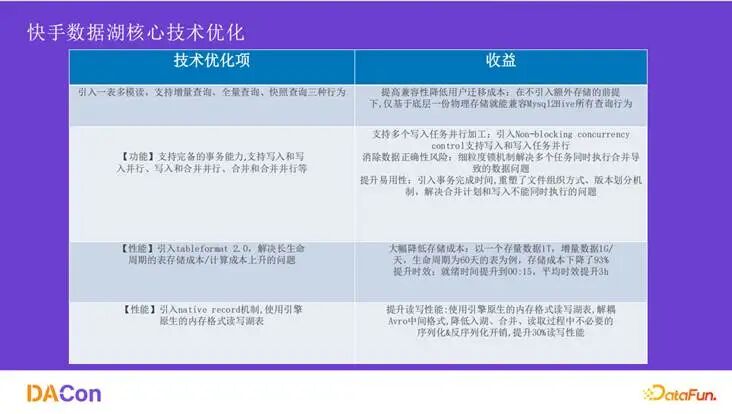
在核心技术优化方面,我们主要取得了以下进展:
- 一份存储多模式读取:解决了
mysql2hudi2.0 的长生命周期和灵活查询问题。
- Tableformat 2.0:大幅降低了长生命周期表的存储与计算成本。
- Native Record 机制:使用计算引擎原生内存格式读写数据,解耦了 Avro 中间格式,避免了不必要的序列化/反序列化开销,提升了约30%的读写性能。
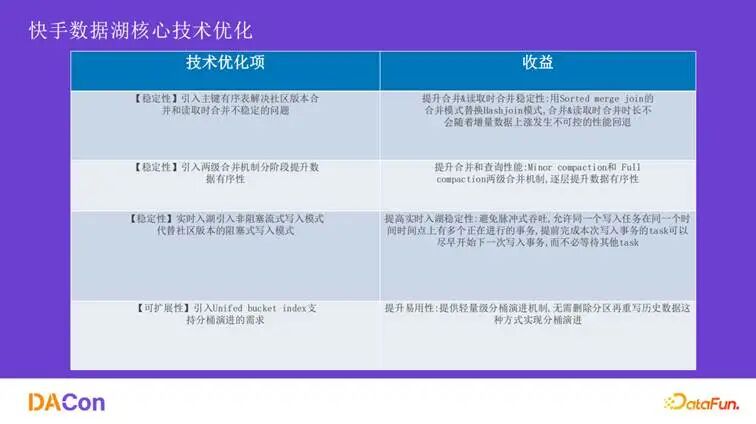
- 稳定性优化:引入主键有序表提升合并稳定性;采用两阶段合并机制;实现实时非阻塞写入模式。
- 可扩展性优化:引入
unified bucket index 支持轻量级的分桶演进,无需重写历史数据。
03 未来展望
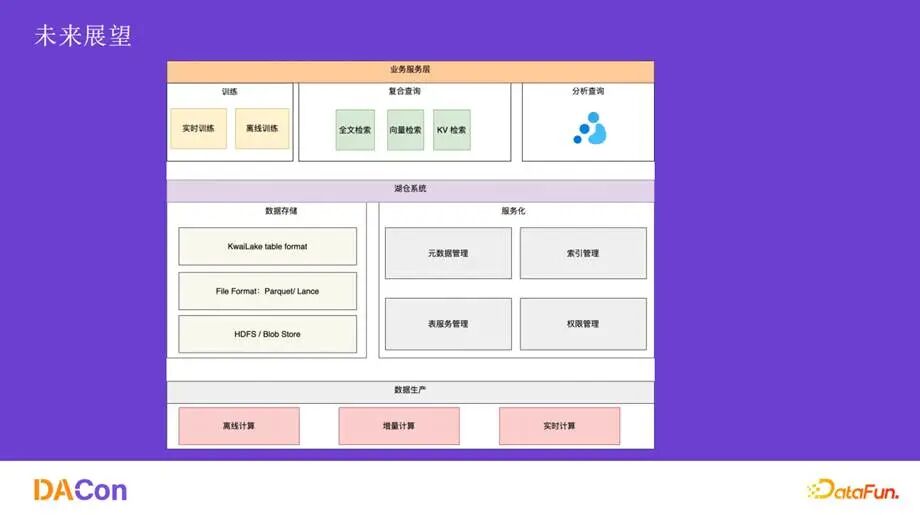
展望未来,我们计划在以下几个方向持续探索:
- AI 方向:深入研究向量检索、多模态数据存储等技术。
- BI 方向:进一步深化实时入湖的覆盖范围,推广至更多离线场景。
- 服务化:建设更内聚的元数据服务、表管理服务,提升 数据湖 的易用性和可管理性。
- 数据生产:在现有离线和实时加工模式之外,继续探索增量计算等更高效的数据加工方式。
以上就是本次关于快手基于 Hudi 构建实时数据湖,并驱动 AI 与 BI 场景架构升级的实践经验分享。更多关于大数据和流计算的技术讨论,欢迎访问 云栈社区 进行交流。
 发表于 2026-2-9 05:35:14
|
查看: 201|
回复: 0
发表于 2026-2-9 05:35:14
|
查看: 201|
回复: 0
