当前,大模型的规模和复杂度持续攀升,对训练和推理所需的算力提出了远超摩尔定律所能满足的要求。为应对这一挑战,NVIDIA 采取了“极致协同设计”(extreme codesign)策略——通过在多芯片硬件与庞大软件栈之间进行深度协同优化,实现 AI 工厂在性能和能效上的代际跃升。
在这一战略中,低精度数值格式扮演着关键角色。降低计算精度可显著提升算力效率并减少能耗,但要在保持高准确率的前提下将超低精度引入 AI训练 和推理,需要在技术栈的每一层进行系统性工程创新:从数值格式的定义、芯片上的硬件实现,到各类软件库的支持,再到与生态伙伴共同开发新的训练方法和推理优化技术。
NVFP4 正是这一努力的成果。该格式由 NVIDIA 为 Blackwell 架构及后续平台开发并部署,首次在 GPU 上实现了 4 比特浮点(4-bit floating-point)精度的完整支持,在大幅提高性能与能效的同时,保持了与更高精度格式相当的模型准确率。
对于希望最大化 AI 训练与推理性能的开发者和企业,以下是关于 NVFP4 的三个关键事实。
01 NVFP4 在 Blackwell 架构上带来显著性能跃升,并将持续演进
NVIDIA Blackwell Ultra GPU 的峰值密集型 NVFP4 算力高达 15 petaFLOPS,是同一 GPU 上 FP8 精度的 3 倍。这种提升不仅体现在理论峰值,更在实际工作负载中得到验证。
在推理方面,以热门的 6710 亿参数混合专家模型 DeepSeek-R1 为例,从 FP8 切换到 NVFP4 后,在相同交互延迟水平下,单 GPU 的 token 吞吐量显著提升。这意味着系统不仅能维持原有响应速度,还能支持更高的并发请求或更复杂的生成任务,从而改善用户体验。
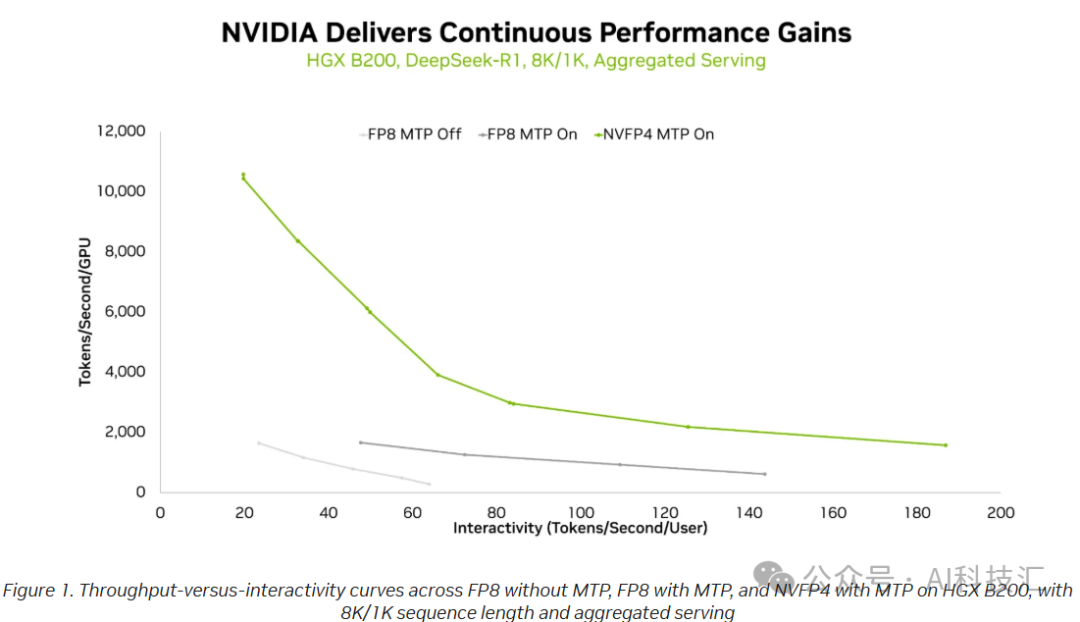
在训练方面,NVIDIA 近期发布了基于 NVFP4 的训练方案。在最新版 MLPerf Training 基准测试中,512 颗 Blackwell Ultra GPU 组成的 GB300 NVL72 系统使用 NVFP4 完成 Llama 3.1 405B 模型的预训练仅耗时 64.6 分钟,比此前使用 FP8 的 512 颗 Blackwell GPU 快 1.9 倍。
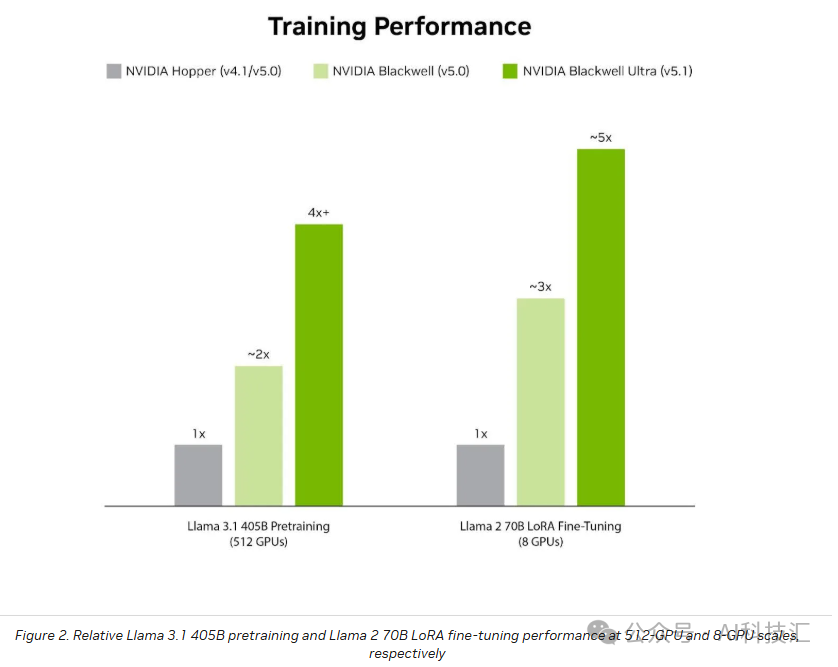
展望未来,NVIDIA 即将推出的 Rubin 平台将进一步放大 NVFP4 的优势:其训练算力将达到 35 petaFLOPS,Transformer Engine 推理算力达 50 petaFLOPS,分别是 Blackwell 的 3.5 倍和 5 倍。
02 NVFP4 在主流基准测试中验证了高准确率
MLPerf 基准测试的“封闭分区”(closed division)对提交结果有严格的准确率要求:推理需满足特定任务的精度阈值,训练则必须使模型收敛至指定质量目标。
在最新一轮 MLPerf 中,NVIDIA 使用 Blackwell 和 Blackwell Ultra GPU,基于 NVFP4 成功提交了所有大型语言模型(LLM)测试项的结果,涵盖训练与推理多个场景,包括 DeepSeek-R1、Llama 3.1(8B 与 405B)、Llama 2 70B 等。所有模型均采用 NVFP4 量化版本,并完全满足基准的准确率标准。
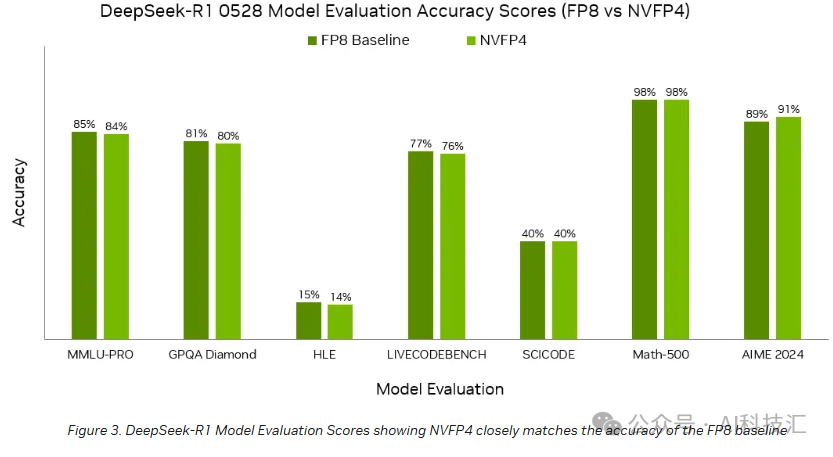
这表明,NVFP4 不仅能提升性能,还能在真实应用场景中维持模型的核心能力。
03 NVFP4 获得广泛且快速增长的生态支持
NVIDIA 已构建完整的工具链支持 NVFP4 的落地。开发者可通过 NVIDIA Model Optimizer、LLM Compressor 和 PyTorch 的 torch.ao 等工具,将高精度训练好的模型量化为 NVFP4 格式,并启用 NVFP4 KV 缓存,以支持长上下文和大批次推理,同时保持准确率。
主流推理框架如 TensorRT-LLM、vLLM 和 SGLang 均已支持 NVFP4 模型运行。在 Hugging Face 上,用户可直接获取多个 ready-to-deploy 的 NVFP4 模型,包括 Llama 3.3 70B、FLUX.2、DeepSeek-R1-0528、Kimi-K2-Thinking、Qwen3-235B-A22B 和 NVIDIA Nemotron Nano 等。
多家企业已在生产环境中采用 NVFP4 提升效率:
- Black Forest Labs 在 Blackwell 上为 FLUX.2 模型部署 NVFP4 推理,结合 CUDA Graphs、torch.compile 和 TeaCache 等优化,单颗 B200 GPU 实现最高 6.3 倍加速,显著降低延迟。
- Radical Numerics 利用 NVFP4 加速科学世界模型的扩展,其首席 AI 科学家表示,低精度方案对处理超长上下文和多模态融合至关重要。
- Cognition 在大规模强化学习中观察到“显著的延迟降低和吞吐提升”。
- Red Hat 通过 NVFP4 量化,在严格内存限制下运行前沿模型和 MoE 模型,既保持接近原始精度,又支持更大上下文窗口和更高并发。
此外,NVIDIA Transformer Engine 库已集成 NVFP4 训练方案,Megatron-Bridge 等训练框架也提供相应实现,帮助开发者快速上手。
04 结语
NVFP4 代表了 NVIDIA 在 AI 算力效率上的重大突破。通过极致的软硬件协同设计,它在 Blackwell 及未来的 Rubin 平台上实现了性能、能效与准确率的平衡。随着大量开源模型提供 NVFP4 版本,开发者现在即可部署更高吞吐、更低每百万 token 成本的服务。
随着 Rubin 平台进一步增强 NVFP4 能力,AI 模型的训练与推理将迎来新一轮效率革命——更快、更省、更强。对这类前沿硬件加速和 深度学习 优化技术感兴趣的开发者,可以关注云栈社区,获取更多深度解析和实践分享。
 发表于 2026-2-9 07:40:18
|
查看: 251|
回复: 0
发表于 2026-2-9 07:40:18
|
查看: 251|
回复: 0
