今天我们来深入探讨我个人非常看好的一代内存技术——LPDDR6。它的出现,极有可能点燃消费端AI变革的导火索,让手机、个人PC上的AI应用告别“鸡肋”体验,甚至可能推动芯片形态发生根本性的改变。
LPDDR6:一次打破常规的全面提升
作为第六代LPDDR技术,LPDDR6在内存带宽上的提升堪称“史诗级”。为什么这么说?因为以往的LPDDR世代升级,通常只提升内存速率。而LPDDR6这次是“双管齐下”,同时增加了内存速率和内存位宽。
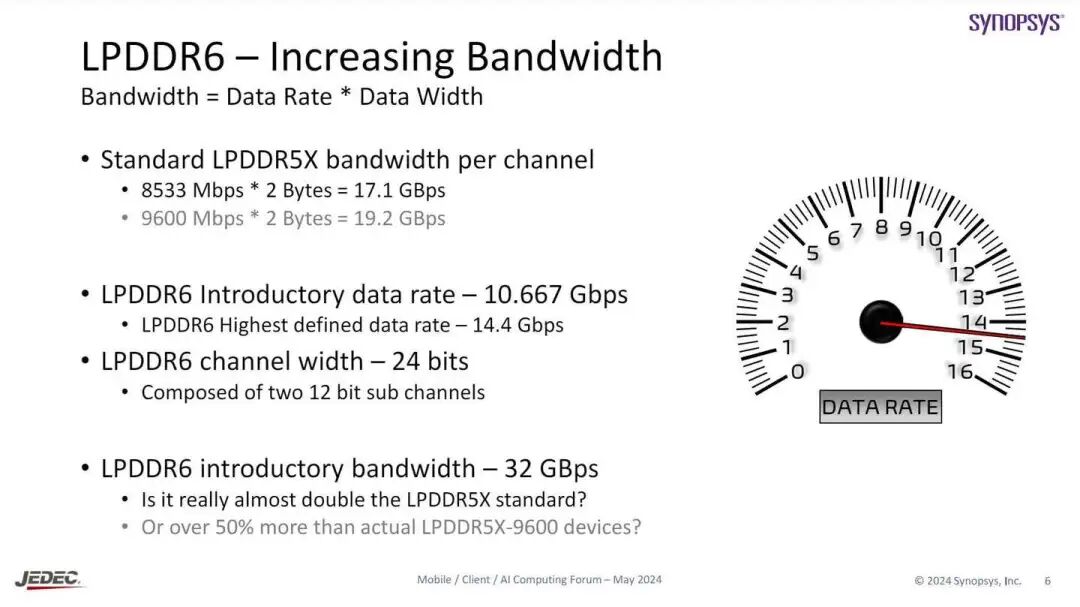
过去,手机和PC上主流配置的双通道LPDDR内存,其等效位宽分别是64bit和128bit,这对应的原始LPDDR通道宽度是16bit。从LPDDR/DDR1到LPDDR5/DDR5,这个位宽标准几十年来从未改变。但到了LPDDR6,规则被打破了。LPDDR6的原始通道宽度从16bit提升到了24bit,这意味着手机和PC主流配置的双通道LPDDR位宽,将自然而然地变为96bit和192bit。

伴随速率和位宽的双重提升,LPDDR6初代主流型号(例如12.8Gbps)相比于当前主流的LPDDR5X 9.6Gbps,提升会有多大呢?(注:这里我们只考虑大概率会成为主流的型号,因此暂不考虑10.7Gbps的LPDDR5X和14.4Gbps的LPDDR6)既然这么问,那这显然不是简单的“位宽×速率”计算。LPDDR6引入了容错机制,每传输288bit数据中,只有256bit是有效数据。因此,计算LPDDR6带宽时,还需要乘以一个有效数据比率:256/288 ≈ 0.889。
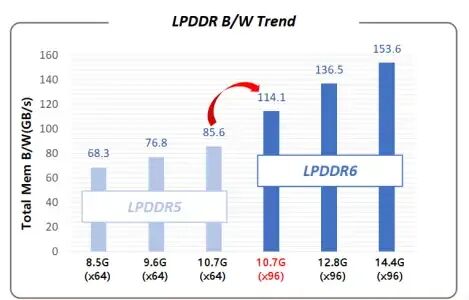
接下来我们就可以计算了:手机端的双通道LPDDR5X 9.6Gbps带宽为 64/8 * 9.6 = 76.8 GB/s。如果升级到12.8Gbps的LPDDR6,带宽则是 96/8 * 12.8 * 0.889 ≈ 136.55 GB/s。整体带宽提升接近80%!这个增幅,远超以往任何一次LPDDR世代升级。
LPDDR6:开始疯狂追赶GDDR7
一般来说,内存带宽提升意味着集成GPU和AI推理的性能上限又提高了。但为什么说它能引发消费电子变革?这就不得不提当前处在AI风口的独立显卡了。
独立显卡也需要存储系统,通常采用GDDR显存。GDDR、DDR、LPDDR同属DRAM大家族,只是分工和特性不同。以前大家相安无事,但现在看来,LPDDR6很可能要抢走不少原本属于GDDR的市场。
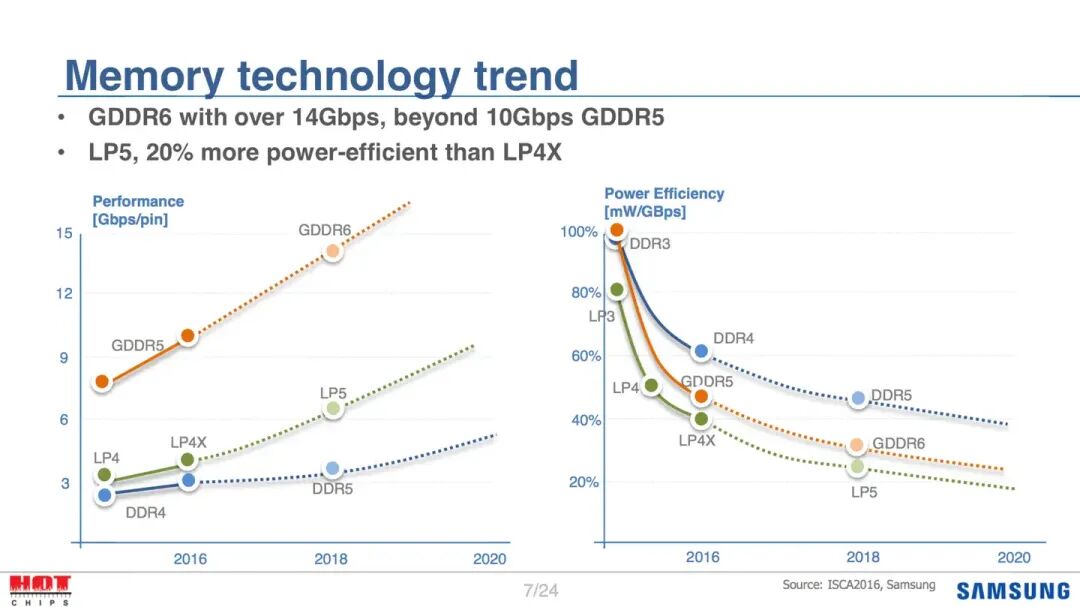
过去,搭载GDDR显存的独显,在总带宽上远胜LPDDR方案。例如,LPDDR5系列的典型速率是5.5-10.6Gbps,而同时期的GDDR6速率可达14-20Gbps,GDDR7初期更是达到24-30Gbps。在相同位宽下,GDDR的带宽几乎是LPDDR的3倍。PC端(不含Mac)出于成本考虑,大规模量产的产品最多也就做到类似AMD Strix Halo那样的四通道256bit方案,折算下来,其理论带宽大概只能匹敌Nvidia 96bit位宽的独显。即便是Mac Studio上成本极高的M3 Ultra(16通道内存,1024bit位宽),其带宽也才勉强达到Nvidia RTX 4090系列384bit位宽的水平。
但到了LPDDR6时代,情况发生了变化。在DRAM市场中,高端专业AI卡清一色使用HBM,PC和手机则用LPDDR或DDR,GDDR显存的市场需求其实很小,这导致其发展速度相对缓慢。未来几年,GDDR7将与LPDDR6长期共存。仔细计算后你会发现,GDDR7对比LPDDR6的带宽优势已经大幅缩小。

以今年主流的移动端RTX 5060为例,它搭载了128bit、24Gbps的GDDR7显存,显存带宽为 128/8 * 24 = 384 GB/s。而AMD明年计划推出的“Medusa Halo”等产品将采用四通道LPDDR6内存方案,其保守估计带宽为 (96*4)/8 * 12.8 = 614.4 GB/s。这个数字已经非常接近传闻中RTX 5070 Ti(192bit,28Gbps)约672 GB/s的带宽了。
看出问题了吗?RTX 60系列显卡的位宽很可能长期停留在128bit,这意味着它的显存带宽将被LPDDR6时代四通道大核显方案长期压制。即使128bit的GDDR7未来超频到36Gbps,带宽也不过 384 * 1.5 = 576 GB/s,而那时的LPDDR6速率也早已不止12.8Gbps了。别忘了,Nvidia显卡的显存位宽不会轻易提升,RTX 6060甚至7060都可能维持128bit。
因此,这就是LPDDR6带来的第一个巨大优势:采用四通道LPDDR6的大核显产品(如AMD Medusa Point、Intel Nova Lake AX),其核显性能上限,将超过搭载128bit GDDR7显存的RTX 60系列独显。
LPDDR6的终极杀器:统一内存
四通道LPDDR6的大核显方案,除了在带宽上压制128bit独显,还有一个真正的“杀手锏”——统一内存架构。
在传统的“CPU内存 + 独显显存”方案中,内存和显存是分离的,二者容量无法直接叠加。这对于运行大型AI模型来说,无论是从便利性还是经济成本上看,都不够高效。而如果CPU和GPU共享同一块大容量、高带宽的LPDDR6内存呢?情况就完全不一样了。RTX 60系显卡通常从8GB显存起步,未来几年顶多到12GB。但如果采用共享的统一内存,32GB只是起步,64GB很轻松,128GB以上也不是难事。

很容易看出,四通道LPDDR6方案无论是在内存带宽还是容量上,其优势都远胜于“双通道LPDDR6内存 + 128bit 60系显卡”的传统组合方案。
因此,我的核心观点是:进入LPDDR6时代后,128bit位宽的独显在笔记本市场应该被淘汰了。 从技术角度看,四通道LPDDR6的集成方案在带宽、容量和能效上,都比搭配128bit入门独显的方案更具优势。
不出意外,AMD的Medusa Halo就会采用这种思路。Intel的Nova Lake是否会跟进尚不确定,但Intel自己是否做不重要,关键是Nvidia和Intel已经确认合作,其联合产品的形态大概率也会如此。因为在这篇文章里我反复论证了一个事实:在LPDDR6的高带宽面前,128bit的入门级独显真的不够看了。
展望:LPDDR6会侵蚀更多GDDR7市场吗?
总结一下,进入LPDDR6时代后,具备经济可行性的四通道LPDDR6大核显方案,在技术上显著优于搭配128bit RTX 60系独显的方案。只要GPU核心本身的性能不拉胯,就不建议再考虑这类入门独显方案。

对于苹果而言,其本身就拥有8通道的Max方案和16通道的Ultra方案,可以在带宽上轻松压制256bit/384bit的GDDR7方案,同时在能效比和“显存”(即统一内存)容量上形成绝对碾压。

因此,稍微夸张点说,如果不考虑Intel和AMD的大核显产品市场接受度问题,LPDDR6可能比GDDR7更适合当今的GPU需求。LPDDR虽然单Pin速率相对较低,但其在内存管理和容量扩展上的优势,在AI时代至关重要,堪称“青春版HBM”。Intel用于数据中心推理的Crescent Island GPU就采用了LPDDR5X方案,未来也很可能升级到LPDDR6。GDDR系列相对缓慢的速率提升和难以解决的容量瓶颈,可能会让其本就不大的市场份额进一步萎缩。
技术进步总是伴随着市场格局的变迁,LPDDR6带来的高带宽与统一内存优势,正在模糊高性能核显与入门独显的界限。这场由计算机基础层创新引发的连锁反应,最终会如何重塑我们的设备,值得所有开发者持续关注。想了解更多前沿技术趋势与深度解析,欢迎来到云栈社区交流探讨。
 发表于 2026-2-21 04:47:25
|
查看: 226|
回复: 0
发表于 2026-2-21 04:47:25
|
查看: 226|
回复: 0
