分布式推理的核心价值:抵御智力审查
前言:现在是 2026 年 10 月,从现在算起的 4 个月后,GLM-6 刚刚发布,它击败了 Fable-5.1(被禁模型的阉割重发版),并且在所有主要基准测试上与 Mythos 持平。
美国政府无法关闭它,于是采取了一系列行动,禁止提供商提供该模型,也禁止公司使用它。Z.ai 及其关联方不得直接或间接在美国境内或向美国公民提供 GLM-6 模型、更新、推理服务、托管部署或技术支持。
Amazon Bedrock、Google Vertex 和 Microsoft Azure 迅速发布声明,表示将遵守规定,拒绝为企业客户托管该模型。OpenRouter、Vercel、Cloudflare、TogetherAI 等主要聚合商也同意不上架该模型。GitHub 清除了其平台上的所有相关痕迹。
Hugging Face 是最后一个坚持的,但最终也遵守规定,移除了所有与 GLM-6 相关的模型下载链接。
上述场景并非我们期望的,但在美国及其他政府试图应对 AI 模型呈指数级进步而政策却蜗牛般迟缓的世界时,这是一种可能的结果。
这种结果,或者另一种 AI 前沿技术仍被少数中心化实体垄断的情况,正是去中心化 AI 如此重要的原因。
这是我关于有用工作量证明入门文章的配套篇——相同的方法,不同的加密与 AI 结合领域,部分内容重叠。我将深入探讨去中心化 AI 需要解决的难题、我正在追踪的该领域项目概况、尽职调查框架,以及深入钻研后我的最终立场。
去中心化推理是不可避免的
根据上述场景,你可能已经联想到去中心化推理,但如果没有,让我们继续推演。
GLM-6 模型权重发布后,副本会立即在互联网上传播——没有任何禁令或补救措施能阻止数千个副本的存在。这些副本将通过去中心化推理网络提供服务,这些网络没有能够发布禁令的中央权威机构,也没有任何节点能被封禁从而摧毁整个网络。
我想明确一点:我不是在这里争论这是好是坏——如果一个新的开源权重模型发布,可能因滥用造成严重损害,那么我不是建议我们坐视不管。我所建议的是,该模型对那些不想被审查的用户来说,必然是可访问的。
这就是去中心化推理的核心前提——它是针对智力审查的对冲工具,无论这种审查来自政府还是前沿实验室的封锁。
其他附加价值主张,如更便宜的 Token、可验证推理和隐私,都次于这个核心赌注——降低审查风险。
现在让我们开始深入探讨。
去中心化推理非常困难
对于大多数初创公司来说,解决一两个难题已经是巨大的挑战。而对于去中心化推理,项目需要解决四个非常棘手的问题。每个项目如何应对这些问题,正是区分虚有其表与实质内容、Alpha 与噪音的关键。
难题 #1——运行一个单台服务器无法容纳的模型
核心理念是创建一个 GPU 集群,并使用流水线并行来提供人们想要的模型服务。这里有大量技术细节,但只需想象每个节点持有权重的一个切片和其自己的 KV 缓存切片——刚好能够适配从 3090/4090 一直到 H100 及以上的 GPU。将足够多的节点组合在一起,你就可以托管像 GLM 这样的真正模型。Petals 早在 2022 年就通过 BLOOM-176B 在消费级 GPU 上以 BitTorrent 风格的集群证明了这种方法,但速度仅为每秒约 1 个 Token。显然,1 t/s 是无法使用的,因此创新集中在如何使模型运行得更快。
制约因素在于网络。在数据中心内部,GPU 通过 NVLink 以每秒太字节的速度通信。在公共互联网上,它们以几十毫秒的往返延迟通信。解码是顺序的,因此一个简单的集群模式会在每个 Token 上付出这种往返延迟的代价。
最常见的解决方法是推测性解码。一个小型廉价的草稿模型提出 K 个 Token,大型分片模型通过流水线一次验证所有 K 个 Token,然后保留匹配的最长序列。现在,一次昂贵的网络往返可以换来多个 Token,而不是一个。
这里有很多技术细节,但创新点在于我们已经看到这在真实的互联网链路上可以达到每秒约 30-40 个 Token。这是很好的进展,但在规模化和用户真正要求的速度方面仍未得到验证。我需要重申——这是一个需要真正技术能力的棘手工程问题。
注意:提供推理服务不仅仅是 FLOPs
在比较任何集群方法与云托管模型时,有一个陷阱——人们会基准测试每秒 Token 数,并认为这才是最重要的。
但生产环境的推理必须处理好一系列问题,这些都与原始 FLOPs 无关:
- 首个 Token 的时间与 Token 间延迟
- 预填充与解码——两个阶段对硬件的要求截然相反
- KV 缓存的放置与传输
- 流式传输、连续批处理以及混合负载下的利用率表现
- 长上下文行为、冷启动和模型预热
- 节点更换
尽职调查要点:当项目引用吞吐量数字时,要问它的竞争对手是什么。一个具有分离式预填充和连续批处理的中心化 vLLM 或 SGLang 部署才是真正的考验,而且这是一个每季度都在变得更快的变化目标。“我们在互联网上实现了每秒 30 个 Token”是令人印象深刻的工程成就,但仍然可能缺乏竞争力。
难题 #2——证明你得到了所支付的模型
如果你不信任某个节点,你怎么知道它运行的是它声称的模型,而不是一个更便宜的量化替代品?这就是提供商可能试图“欺骗”网络的地方,尤其是在涉及挖矿 Token 的情况下,他们可能假装在提供服务你付费的模型,但实际上运行的是更便宜的模型。
我看到有 5 种不同的方法来解决这个难题:
- ZKML——前向传播的零知识证明。加密级、天衣无缝,但开销大约为 10,000 倍。对于 Llama-3,每个 Token 约需 150 秒。短期内无法在前沿规模上实现。
- opML——发布输出并附带押金,开放一个挑战窗口,欺诈证明通过二分法将任何争议分解为仲裁者可以重新运行的一步。接近原生速度,但最终确认需要等待窗口期,并且继承了验证者的困境:如果检查成本高于捕获的收益,那么没人会检查。
- 确定性重新执行——使推理在字节级别上可重现,那么争议就只是字节相等性检查。开销低于 2%,由再质押的 ETH 提供安全保证。
- 统计指纹——以低成本对计算进行哈希或采样,大多数情况下能捕获大多数欺诈行为。不是绝对的,但速度快且对 GPU 友好,这正是无需许可的集群所需要的。
- 实时权重证明——对实际驻留在服务进程中的张量进行采样,并与已批准模型的清单进行比对。验证的是加载了什么,而不是输出了什么,开销约为 0.1%。一个真正不同的角度。
权衡在于,你实际上只能从以下三项中实现两项:1)加密完整性,2)低延迟,3)成本效益。ZKML 以牺牲延迟和成本为代价获得完整性。其余方案则以经济或统计完整性为代价,获得低延迟和成本效益。
尽职调查要点:询问项目使用了哪种方法以及为什么使用,了解他们做出的权衡以及这对产品的影响。
难题 #3——保持你的提示词秘密
证明输出与隐藏输入是两个不同的问题。在一个分片集群中,每个节点必须解密激活值才能进行计算——加密保护的是传输线路,而不是节点。
事实证明,Transformer 激活值非常容易反转。CCS 2025 从这些中间激活值中重构输入提示词的准确率超过 90%。ICML 2025 的 “Hidden No More” 实现了近乎完美的恢复,并击败了集群常用的噪声和排列防御手段。
唯一可靠的修复方案是一种不同的、更重的序列分片方案,而消费级 GPU 群体中还没有人部署过(至少我没见过),所以这仍然是一个基本未解决的问题。
一个集群可以宣传“没有节点持有完整模型”,但仍然可以将每个提示词泄露给路径中的任何节点。“没有节点持有模型”从来都不是一个隐私属性。
真正提供隐私的是硬件或数学,而不是拓扑结构。TEE——Phala 在 GPU 上、Darkbloom 在 Apple Silicon 上、Venice 的 Pro 模式——将信任转移到硬件根并进行认证。
FHE 对密文进行计算,不信任任何东西,但其成本对于 LLM 来说目前还无法使用。
尽职调查要点:一个项目要么拥有其中一种方案,要么就没有隐私,无论其落地页上写什么。
注意:私有并不意味着无需信任
整节中最重要的警告:TEE 并没有消除信任,而是转移了信任。你的信任从节点运营商转移到硬件供应商、固件链、认证服务以及飞地实现。
所以真正的问题是你接受谁的信任根:芯片供应商、再质押的验证者集、TEE 网络,还是纯数学。
难题 #4——构建双边市场
前三个问题都是技术问题,这第四个问题是商业问题。
我经常思考,对于服务于开源权重模型的去中心化推理网络,谁才是理想客户画像?
大多数消费者从订阅计划中获得了巨大价值——每月支付 20-200 美元,你可以获得大量的智能服务。这些补贴计划很可能在未来消失或限制使用,但今天,如果你想推销基于 API 的按需付费推理,消费者是很难打动的。
企业也不会成为大买家,也许有一天取决于中心化模型的发展情况,但不要指望企业买家很快到来。
因此,如果消费者坚持使用他们的订阅计划,而网络尚未准备好满足企业需求,那么实际上只剩下两类客户:1)将推理集成到产品栈中的初创公司和公司,它们天生需要 API 计划,以及 2)寻求自身推理能力的自主 AI Agent。
初创公司这个类别是一个不断增长的可寻址市场,也是一个可以切入显著营收业务的利基市场,但我们必须认识到,这给近期的价值捕获设置了一个上限。
至于 AI Agent 作为买家,这更具投机性——短期内仍然需要有人为其付费。但 AI Agent 执行自主工作并通过加密轨道获取推理的想法是一个美好的梦想。
这就是这个问题如此困难的原因——如何在你目标用户群不太可能成为网络大额消费者的前提下,聚合有意义的、人们想要的模型供应?
一个可行的领域是去中心化 GPU 提供商。包括 io.net、Akash、Render、Aethir 和 Nosana 在内的一系列项目已经在这方面努力多年,并创建了 Token 协调的市场,将整个 GPU 或每个节点承载整个模型的能力出租给任何付费者。因此,是有一些先例的。
尽职调查要点:询问项目的理想客户画像是什么,以及他们如何既获取这些目标用户,又保持供应方的满意。如果这一切都基于投机性的 Token 上涨预期,那这就是你的判断依据。
去中心化推理请求的流程
如果上述问题没有突出技术挑战,也许我们应该看看从用户提示开始到结束的整个流程。
去中心化推理提供商除了正常推理提供商必须支持的功能外,还有几个额外的步骤。
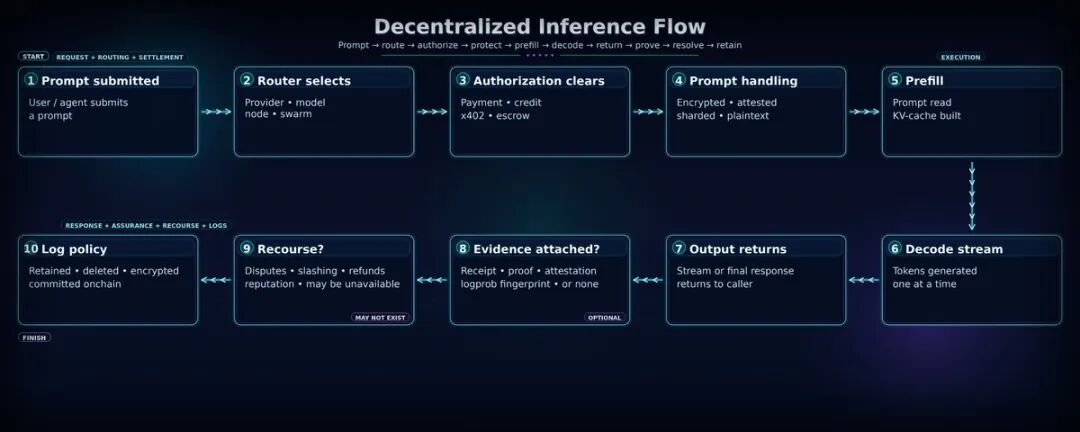
每个难题都可以追溯到这些步骤之一:
- 提示词在哪里以明文可见?(步骤 4 到 6)
- 模型权重在哪里可见,对谁可见?(步骤 5)
- 输出在哪里与声称的模型绑定?(步骤 8)
- 谁可以挑战错误的结果,需要付出什么代价?(步骤 9)
- 当答案错误时,买家的实际补救措施是什么?(步骤 9)
- 记录了哪些信息,以后谁能读取?(步骤 10)
- 谁签署了收据,他们的签名有价值吗?(步骤 8)
- 以及核心问题:这十个步骤中,哪些实际上是去中心化的?
尽职调查要点:这不是一个“加密兄弟”能指望作为构建者成功的领域。这里没有 Aave 的分叉可以搭建。这些都是棘手的工程问题,因此你需要看到团队具备真正的人工智能技术能力。
谁在解决这些难题?
有非常多的项目以某种方式属于“去中心化推理”范畴。大多数项目并未同样着力解决所有四个难题,而是倾向于专注于一个核心问题,并融入其他问题的元素。
Petals
Petals 是去中心化推理的先驱。一些高智商的研究人员早在 2022 年就证明,BLOOM-176B 可以在消费级 GPU 上以 BitTorrent 风格的网络运行,每个参与者托管几个 Transformer 块,并将激活值沿链传递。这证明了在弱互联网链路上进行流水线并行是可行的。
它的重要性在于概念层面,而非商业层面。Petals 没有解决激励、隐私或货币化问题。它拥有后来加密技术围绕其包装 Token 的架构,但没有经济层。
这就是了解这个项目重要的原因——当你看到本质上就是 Petals 加一个 Token 的东西时,那极有可能是一个“拉盘”项目。
Dolphin Network

Dolphin 是 Dolphin 家族未经审查的开源模型背后的团队,这些模型在 Hugging Face 上的下载量超过 500 万次。这个起源很重要——Dolphin 的起点不是“我们有一个 Token,现在我们希望找到用例”。它始于人们已经在使用的模型,然后围绕这种需求构建了一个网络。
Dolphin 不仅仅是一个去中心化推理网络(它值得一篇更深入的文章),但它的推理产品是一个点对池网络,GPU 所有者(包括游戏玩家和高端消费者 GPU 所有者)可以将闲置容量贡献到特定模型的池中。请求进入池中,并被分配给能够服务该模型的节点。这种设计适用于弹性、不可靠的供应——当人们想玩游戏时,可以拿回他们的 4090——也适用于前沿实验室在结构上不太可能托管的未经审查或专业化的开源模型需求。
其差异化的技术部分是实时权重证明。不是在加载时对模型文件进行哈希处理并希望它一直存在,Dolphin 对实际驻留在服务运行时的张量进行采样,并与已批准模型的清单进行比对。这验证了加载了什么,而不是输出了什么,据报道开销约为 0.1%——极其高效。它在此基础上叠加了 logprob 指纹识别、软件完整性检查以及账户级质押,运营商需要建立可罚没的质押金后才能解锁流动性索取。
容量信号是真实的——根据项目自身数据,已生成超过 32 亿个 Token,持续带宽约每秒 9,400 个 Token。因此,Dolphin 是一个产品优先、创始人可信的执行赌注。
Inference.net / Kuzco

Inference.net,前身是 Kuzco,是一个去中心化推理网络,也是业界验证模型执行方面较为成熟的尝试之一。
其独特的机制是 LOGIC,一种基于 logprob 的验证方法,使用统计测试在解码时捕获模型替换。通俗地说:网络检查发出的 Token 背后的概率分布是否看起来像来自声称的模型,而不是更便宜的替代品。这属于 Logits 证明和其他统计指纹的同一大类。它不是硬加密证明,但成本低廉且适用于异构 GPU。Inference.net 已投入生产约 18 个月,据报道其 GPU 集群规模在 5,000 到 10,000 张之间(取决于来源),尽管这些数字大多是我发现的自报数据。它是少数几个同时拥有验证原语和有意义的运营历史的项目之一。
Morpheus
Morpheus 是一个去中心化的路由和奖励层,将用户与第三方提供商托管的开源 LLM 连接起来。面向用户的卖点是兼容 OpenAI 的 API 加上一个“智能 Agent”包装器,可以将 LLM 连接到 Web3 钱包并执行链上操作。底层使用 Lumerin 代理路由器进行会话竞价、以 MOR 支付以及提示/响应转发。
最强的技术部分是 TEE 支持的提供商验证:第一阶段已上线,采用 Intel TDX 加 NVIDIA GPU 认证,协议级别不记录提示或响应,并计划构建更完整的信任链。
这里的关注点是其增长势头,特别是与 MOR 发行以及真实外部推理需求证据相关的情况。
Chutes
Chutes 是 Rayon Labs 在 Bittensor 子网 64 上的无服务器推理平台。对用户而言,它看起来像是一个兼容 OpenAI 的 API,用于运行模型。对构建者而言,其单位是“chute”——一个 Docker 封装的工作负载,可部署到 Bittensor GPU 矿工的后端。
积极方面是,它通过 OpenRouter 拥有分发渠道、易于使用的开发者接口以及大规模的头条数字。一些真正的模型以有竞争力的价格提供服务。然而,它在验证和隐私方面似乎仍存在一些差距需要解决。GraVal 证明 GPU 是真实的,但不能证明它运行了所声称的模型;每 Token 的模型绑定证明是单一来源且未经审计的。隐私仅通过可选的 TEE 提供,因此默认模式仍会将提示词暴露给运营商。
c0mpute
c0mpute 是一个引人注目的新项目:一个 Solana 原生、开源的去中心化推理项目,其 Shard 引擎通过公共互联网将前沿规模的模型分割到消费级和高端消费级 GPU 上。
技术成果是真实的并且可以独立验证。c0mpute 发布了一个 GLM-5.2 744B NVFP4 演示,跨越了 6 个美国州的 7 张 RTX PRO 6000 GPU,广域网往返延迟在 22-75 毫秒之间,速度约为每秒 30 个 Token。它还展示了 gpt-oss-120B 在 3 张 RTX 4090 上以约每秒 40 个 Token 的速度运行。
这里有一些实质内容:GPU UUID、公网 IP、区域、每个边缘节点的延迟、输出 Token ID、哈希值、引擎哈希值和确定性检查都已公开。
但是,我们需要认识到这仍处于非常早期的阶段。在撰写本文时,该仓库仅创建了几天,创始人是匿名的,$ZERO Token 是一个具有脆弱流动性的 pump.fun 微盘股,价值积累目前基于投机。
我将关注的是:在并发负载下对 744B 运行进行的真正第三方验证,以及未来的测试。此外,其隐私主张尚未明确,因为每个分片都能看到激活值。因此,c0mpute 是令人印象深刻的执行力和空白定位,但需要更多时间来证明它已经解决了技术挑战并且能够扩展。
Parallax / Gradient

Parallax 是 Gradient Network 的 P2P 分布式 LLM 推理框架,是其“开放智能栈”的一部分。与其将其视为一个应用,不如将其视为一个引擎:跨异构消费级 GPU 和 Apple Silicon 的流水线并行分片,使得个人、组织或小国家能够运行“主权集群”,而无需超大规模云服务商。
与 c0mpute 相比,它具有相同的广泛架构、相同的广域网流水线并行服务理念、相同的 Solana 导向,但 Parallax 拥有更多的机构可信度,由 Pantera 和 Multicoin 领投的 1000 万美元种子轮,以及一个可见的团队。
诚实的问题是,Parallax 会成为其他人构建的基础(例如去中心化服务领域的 llama.cpp 或 vLLM),还是商业价值会转移到其上层的应用和路由器上。据我所知,它也缺乏真正的隐私修复方案。
Darkbloom

Darkbloom 是源自 Eigen Labs 的一个项目,它允许用户将闲置的 Mac 计算能力转变为私有推理市场——即,你将自己的 Mac 出租给其他用户以提供模型服务。
一个好的类比是 Apple 私有云计算,但它是建立在不可信的消费级硬件之上的。一个协调器将请求路由到运营商拥有的 Mac,该 Mac 通过 MLX 在本地运行整个模型,隐私保证来自 Secure Enclave 认证、强化进程内执行以及端到端加密。
“每台 Mac 运行整个模型”这个细节是关键。Darkbloom 不是一个分片集群——它不会在匿名节点链上传递激活值。其认证栈非常严谨,除非基于 Apple 的信任模型本身失效,否则任何运营商都无法读取提示或输出。
其增长势头尚早,但已经足够真实有趣。它于 5 月 26 日从研究预览阶段进入公开 Alpha 阶段,拥有约 250 个峰值活跃节点、数千个注册用户、服务了超过 6 亿 Token、集成了 Stripe Connect、使用 Solana USDC 进行资金结算,并且在 OpenRouter 上线,目前免费且有补贴。
当前提供的模型规模仍然不大,但这是该领域最清晰的信号之一,表明去中心化不一定意味着 Token 化。
Hyperspace Pods
Hyperspace Pods 是消费级 P2P 网格理念的私有集群版本。它允许家庭、朋友、初创公司或小型组织从自己的笔记本和台式机组建私有 AI 集群,自动在设备间分片开源模型,并暴露一个单一的兼容 OpenAI 的端点。
这仍处于新兴阶段,因此只需保持关注,留意实际多设备 Pod 的每秒 Token 数基准测试、活跃集群数量,以及“出租闲置容量”是否会成为一个真正的市场,还是仅仅是一个本地集群功能。
MeshLLM
MeshLLM 是一个无需许可的 P2P 推理网格,由 Jack Dorsey 提出,并由 Block 关联的贡献者构建。节点通过 Nostr 相互发现,通过无中央服务器的网格进行 Gossip 协议通信,并暴露兼容 OpenAI 的 API。它基于 llama.cpp 构建,采用 Apache-2.0 许可证(版权归 Block, Inc.)。
MeshLLM 值得一提的原因是它的机构根基。Block 拥有消费级分发渠道,Dorsey 多年来一直推动 Nostr 作为去中心化协调层,而 MeshLLM 将此理念扩展到 AI 计算。它更接近 BitTorrent 而非 Bittensor:协议优先、无 Token、无需许可、抗审查。
Venice 与推理转售商
任何关于加密和推理的讨论都必须提及 Venice——它是在寻找产品市场契合点、利用加密激励构建可行业务方面整个领域的典范。他们有效地解决了问题 3 和问题 4,至少在某种程度上。
Venice 不是集群意义上的去中心化推理——它是一个中心化的、具有隐私梯度的消费者代理,并带有 TEE 加端到端加密的 Pro 模式。
但它有客户,它未经审查,并且它已成为一个转售过剩推理的子领域项目的基础。这些转售商去中心化了需求聚合和结算,但没有去中心化任何计算。
Venice 向质押了 DIEM 的持有者出售永久的每日一美元 API 信用额度。其中很多信用额度到期未用。因此,转售商让信用持有者以 USDC 出售其过剩的额度,将买家需求路由到最便宜的卖家,并赚取差价。“折扣”就是廉价的 Token 化 Venice 信用与零售 API 定价之间的差距。
现在有几个这样的项目存在:UsePod、AntSeed、Surplus Intelligence、CheapTokens 和 Built in Venice。其中一些项目附加了更大的雄心,并利用过剩容量作为构建规模的楔子。
我在这里提到它们,是因为它们经常被归类为去中心化推理,从某些方面来看确实如此,但并非最纯粹的形式——即聚合去中心化计算并通过不同的提供商网络提供模型服务。
UsePod
UsePod 是一个早期的推理市场,它将请求路由到最便宜且有资格的提供商,并以 USDC、SOL 或 Stripe 结算。其起源故事是关键:创始人 Chris Gilbert 从转售 Venice DIEM 质押者的推理信用额度开始,然后将这个楔子泛化成一个更广泛的推理路由器。这使得 UsePod 成为 Venice 转售群体的一部分,但它也在努力将这个楔子转变为更大的东西。
AntSeed
AntSeed 是基于 Base 的原生、P2P 版本的同类 Venice 周边推理转售模式。提供商连接上游 API 或本地模型,通过 BitTorrent 风格的 DHT 宣布容量,买家则通过加密的 WebRTC 连接路由请求。它暴露了本地的 OpenAI 和 Anthropic 兼容 API,因此开发者工具可以指向它。
AntSeed 的不同之处在于其协议 / P2P 传输理念。它推销的是一个去中心化的 OpenRouter 故事:无需中心化列表审批、请求路径中无公司服务器、平台不托管提供商收入、直接向提供商钱包进行 USDC 结算。
Surplus Intelligence
Surplus Intelligence 是转售模型的订单簿版本。买家通过兼容 OpenAI 的端点访问折扣模型,卖家接入上游预付费 API 信用额度,Surplus 将需求路由到最便宜的卖家并以 USDC 结算。它不拥有任何 GPU,不托管任何模型,也不运行任何推理。“过剩”是财务上的——未使用的预付费信用额度——而非物理上的闲置硬件。
去中心化推理在哪些方面胜出,哪些方面失利
成本理论只有在你将延迟与吞吐量分开时才成立。它们是不同的产品,去中心化对其中之一是税负,对另一个则是特性。
去中心化是税负(中心化胜出)的方面:
- ChatGPT 风格的交互式聊天
- 实时编码 Agent
- 低延迟语音
- 高频工具调用循环
- 任何具有严格 p95 延迟 SLA 的企业应用
- 达到竞争性延迟的前沿规模密集模型——目前没有去中心化服务能够以有竞争力的方式提供 2000 亿以上参数的前沿密集模型
去中心化可以作为供应聚合(可以胜出)的方面:
- 合成数据生成
- 离线评估和基准测试
- 批量嵌入
- 批量 RAG 和文档处理
- 长时间运行的 Agent 研究任务和回测
- 图像和视频生成队列
- 非紧急的开源模型推理,此时闲置硬件的边际成本接近零
最简单的框架:在延迟重要的情况下,去中心化是税负。在吞吐量重要的情况下,去中心化可以是供应聚合。
隐藏价值:数据循环
在我之前的一篇文章中,我写到了 AI Agent 的护城河,核心论点是护城河不在于工具本身,而在于工具收集的数据。
值得注意的是,去中心化推理网络也可以收集有价值的数据,例如合成训练数据、偏好数据、Agent 轨迹、评估输出、微调数据、强化学习环境、工具使用轨迹。
这些数据可以输入去中心化训练系统——Nous Psyche、Prime Intellect、Gensyn 风格的网络——这些系统产生更新的开源权重模型,而这些模型又流回推理网络。
长期栈不是将“去中心化训练”或“去中心化推理”作为独立的赌注。它是一个循环:推理产生轨迹,轨迹成为训练数据,训练更新开源模型,更新后的模型流回推理。
最好的去中心化推理网络会将此作为战略纳入其中,我预计将看到去中心化训练和推理项目之间更多的融合。
尽职调查清单:七个问题就足够了
忘记所有技术行话——你可以根据任何项目回答以下七个简单问题的表现来判断它。
- 它是否真的去中心化了?如果是,去中心化了哪些层?很多人仅仅因为有一个 Token 就给项目贴上“去中心化”的标签,而产品本身却是中心化的。
- 你能相信输出来自你付费的模型吗?这是正确性的所在——确定性、证明、指纹,或者什么都没有。
- 在支付了 Token 和协调开销之后,它实际上比中心化方案便宜吗?不是理论上的便宜,而是生产环境中的便宜。
- 你的提示词是否真的对运营商隐藏?TEE 或 FHE 可以,分片不行。
- 当节点不稳定且遍布互联网时,系统能否保持稳定?大规模编排不可靠的异构硬件本身就是一门学科。
- 是否有人在为它付费,而且是以无法通过中心化方案更便宜地获得的形式付费?
- 团队是否具备真正的人工智能技术能力?这可能是最重要的问题。如果是一群加密投机者组成的团队,那就要知道这很可能更多的是炒作而非实质。
一条建议:警惕那些优雅的技术解决方案,却没有可靠的分发计划。
我的立场
总的来说,我对于仅对加密原住民有吸引力或相关的类别(在我看来,这是一个吸引力很小的可寻址市场)相当悲观。我希望看到对非加密原住民有吸引力的项目,并将加密机制主要隐藏在底层。
去中心化推理作为一个类别,是加密领域少数几个具有真正突破潜力的领域之一——每个人都想要推理服务,它可以像传统提供商一样提供服务,甚至可以通过 OpenRouter 等现有平台进行路由,实现完全无缝的体验。重要的是成本、性能和隐私。
我的建议是——支持那些精确定义了去中心化哪个层级的项目,并了解谁是他们去中心化推理的买家。避免那些仅仅以“去中心化 AI”作为口号并附带一个 Token 的项目。
披露:我持有本文中提到的一些项目的 Token。我没有受到本文中任何项目的影响,也没有从中获得任何报酬——框架和判断都是我自己的。
如果你在 AI 和加密的交汇处构建一个具有真实产品的项目,我的私信随时开放。
 发表于 3 小时前
|
查看: 4|
回复: 0
发表于 3 小时前
|
查看: 4|
回复: 0
