NVIDIA近日推出了一个面向通用游戏智能体的视觉-动作基础模型NitroGen。该模型基于超过1000款游戏的4万小时游戏视频进行训练,标志着游戏AI领域的一个重要进展。NitroGen融合了三个关键要素:
- 通过从公开的游戏视频中自动提取玩家动作构建的互联网规模的视频-动作数据集;
- 能够衡量跨游戏泛化能力的多游戏基准测试环境;
- 采用大规模行为克隆训练的统一视觉-动作策略。
NitroGen在多个领域展现出强大的能力,包括3D动作游戏中的战斗、2D平台游戏中的高精度控制以及程序生成世界中的探索。它能够有效地迁移到未见过的游戏中,与从零开始训练的模型相比,任务成功率的相对提升高达52%。目前数据集、评估套件和模型权重已开源。

相关链接
介绍

构建能够在未知环境中运行且具备通用能力的具身智能体,长期以来被视为人工智能研究的终极目标。虽然计算机视觉和大型语言模型(LLM)已通过对互联网数据进行大规模预训练实现了这种泛化能力,但由于缺乏大型、多样化且带有标签的动作数据集,具身人工智能领域的类似进展却受到阻碍。
电子游戏为推进具身人工智能的发展提供了一个理想的领域,因为它们提供了视觉丰富的环境以及涵盖广泛复杂性和时间跨度的任务。然而,以往的方法面临着诸多局限性。
基于LLM的方法要么利用(1)手工设计的程序化API来暴露内部游戏状态并控制智能体,要么利用(2)复杂的感知模块进行文本信息提取和目标检测。它们能够解决复杂的任务,但需要复杂的领域特定设计和调优。强化学习在《星际争霸II》和《Dota 2》等个别游戏中实现了超越人类的性能,但这些智能体的应用范围有限,训练成本高昂,并且依赖于很少能用于所有游戏的专用模拟器。基于像素观测的行为克隆方法依赖于昂贵的承包商收集的演示数据,由于数据收集成本过高,训练仅限于少数游戏。
方法概述
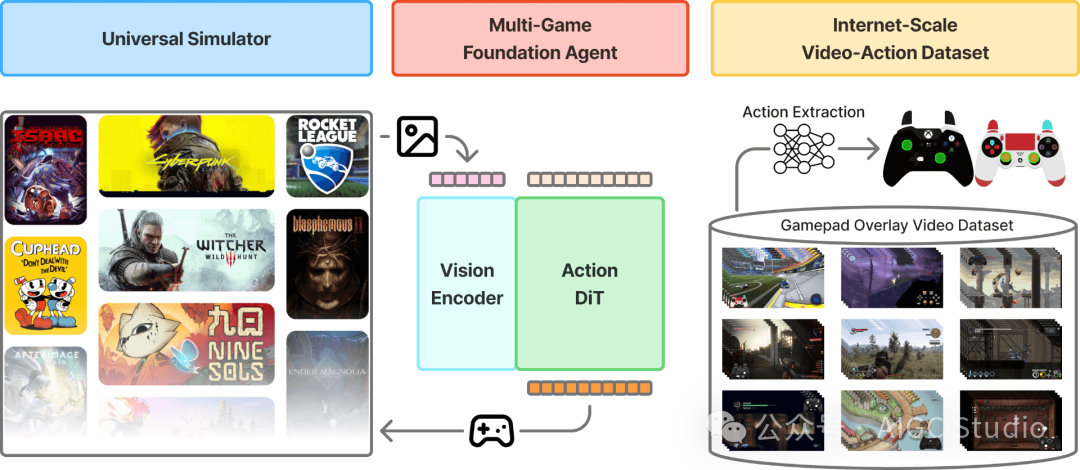
NitroGen由三个主要组件构成:
- 多游戏基础代理(中心) —— 一个通用的视觉-动作模型,它接收游戏观察结果并生成游戏手柄动作,从而实现跨多个游戏的零失误游戏体验,并为新游戏的微调奠定基础;
- 通用模拟器(左) —— 一个环境封装器,允许通过 Gymnasium API 控制任何商业游戏;
- 互联网规模数据集(右) —— 规模最大、种类最丰富的开源数据集,由 40,000 小时的公开游戏视频整理而成,涵盖 1,000 多款游戏,并提取了动作标签。
行动质量控制
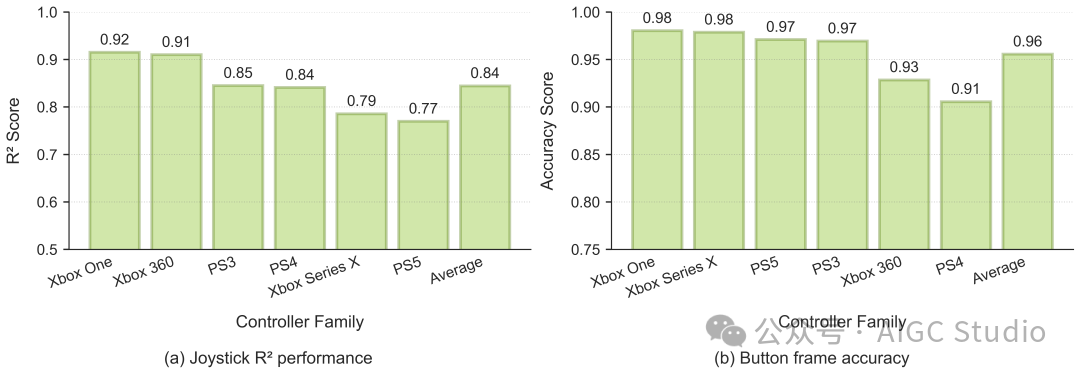
动作提取质量。通过将不同控制器系列的性能与真实数据进行比较,来验证动作提取流程的正确性。
(a) 显示了摇杆 R² 相关性得分(左右摇杆的平均值),总体平均值为 0.84。
(b) 显示了按钮帧准确率,总体平均值为 0.96。
数据集分析
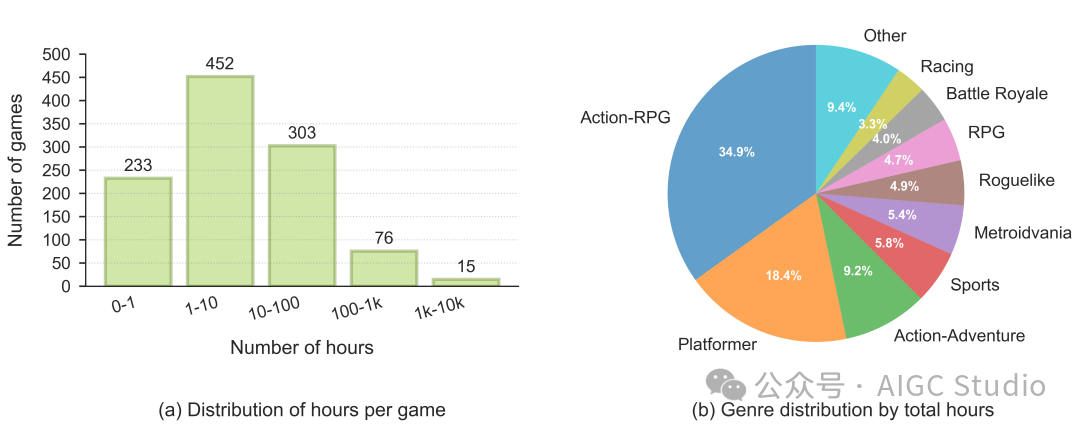
NitroGen 数据集在游戏和类型上的分布情况。经过筛选后,该数据集包含 40,000 小时的游戏视频,涵盖 1,000 多款游戏。
(a) 每款游戏的时长显示覆盖范围广泛,其中 846 款游戏的数据时长超过 1 小时,91 款游戏超过 100 小时,15 款游戏超过 1,000 小时。
(b) 类型分布显示,动作角色扮演游戏最为常见(占总时长的 34.9%),其次是平台游戏(18.4%)和动作冒险游戏(9.2%),其余部分分布在各种类型中。
实验
现成的多游戏功能
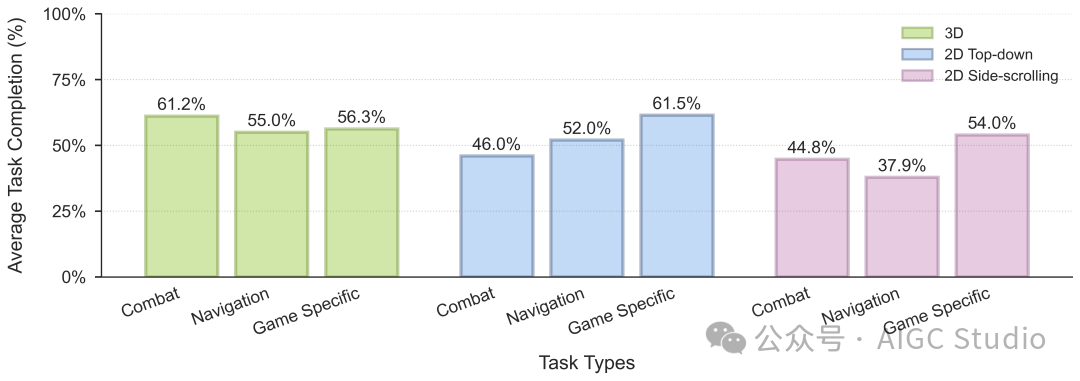
NitroGen 5亿参数预训练模型结果在不同游戏中的表现。我们使用基于流程匹配的GR00T架构,在整个NitroGen数据集上训练了一个5亿参数的单一模型。在进行行为克隆预训练后,我们对该模型进行了评估。对于每款游戏,我们测量了3个任务的平均完成率,每个任务进行5次迭代。尽管NitroGen是在一个噪声很大的互联网数据集上训练的,并且无需进一步微调,它就能在不同视觉风格(3D、2D俯视、2D横版)和类型(平台游戏、动作角色扮演游戏、Roguelike游戏等)的游戏中完成复杂的任务。
未见过的比赛的赛前训练迁移
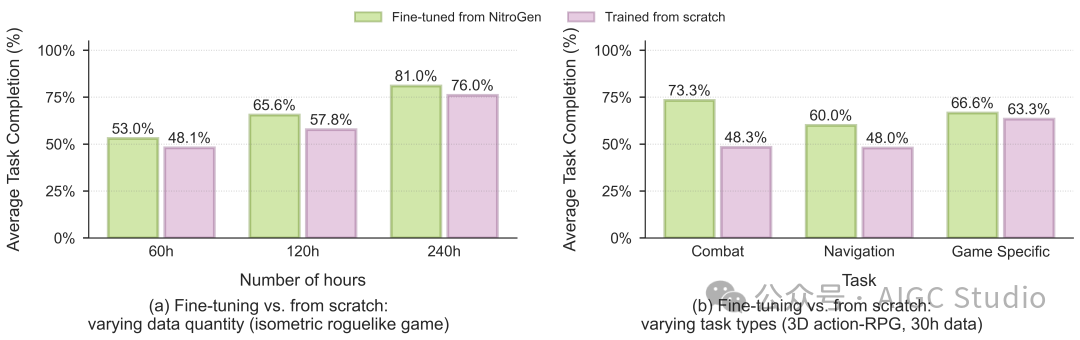
训练后实验。NitroGen 预训练可以提升下游智能体在未见过的环境中的表现。我们在上述数据集上预训练 NitroGen,并预留一个游戏作为测试集。然后,我们在预留的游戏集上对预训练的检查点进行微调,并将结果与使用相同架构、数据和计算预算从头开始训练的模型进行比较。
(a) 当数据量变化时,任务完成率随数据集大小而变化,微调平均可使任务完成率相对提升 10%。
(b) 在低数据量(30 小时)条件下,当任务类型变化时,微调可使任务完成率相对提升高达 52%。
结论
论文介绍了一种名为 NitroGen 的方法,用于扩展视频游戏智能体的基础预训练规模,并展示了互联网预训练如何产生通用策略。利用新的公开数据源构建了一个互联网规模的视频动作数据集,并通过成功训练一个多游戏策略,验证了其有效性。NitroGen 在微调实验中展现出良好的泛化能力。通过降低在新环境下训练智能体的门槛,NitroGen 为开发更强大、更通用的智能体奠定了基础。对游戏AI和通用智能体技术感兴趣的开发者,可以到云栈社区与同行交流更多前沿动态。 |  发表于 2026-2-25 09:41:02
|
查看: 241|
回复: 0
发表于 2026-2-25 09:41:02
|
查看: 241|
回复: 0
