随着人工智能技术的快速发展,大规模语言模型已成为自然语言处理领域的核心驱动力。然而,模型规模的急剧膨胀也给传统的训练方法带来了严峻挑战:单块 GPU 的内存和算力很快成为瓶颈。在这一背景下,Megatron-LM应运而生。它是由 NVIDIA 在 2019 年首次推出的研究性框架,旨在系统性地解决超大规模语言模型训练的技术难题。
如今,Megatron-LM 的技术理念已深刻影响了整个 AI 开发生态,许多流行的 LLM 训练框架,如 Colossal-AI、Hugging Face Accelerate 和 NVIDIA 自家的 NeMo,都基于或借鉴了其核心思想。2024 年 1 月,NVIDIA 将 Megatron-LM 的核心能力产品化,发布了Megatron-Core。这是一个模块化库,将经过实战检验的 GPU 优化技术和系统级优化抽象为可组合的 API,为开发者和研究者在 NVIDIA 加速计算平台上高效、灵活地训练定制化 Transformer 模型提供了强大支持。
一、 Megatron-LM 模型架构设计
1.1 层内模型并行(张量并行)
Megatron-LM 在整体上保持了标准 Transformer 的架构,但其精髓在于在每一层内部引入了显式的并行化设计。这种被称为“层内模型并行”的策略,核心思想是将 Transformer 单层内部的计算拆分到多个 GPU 上并行执行,从而突破单卡内存限制。
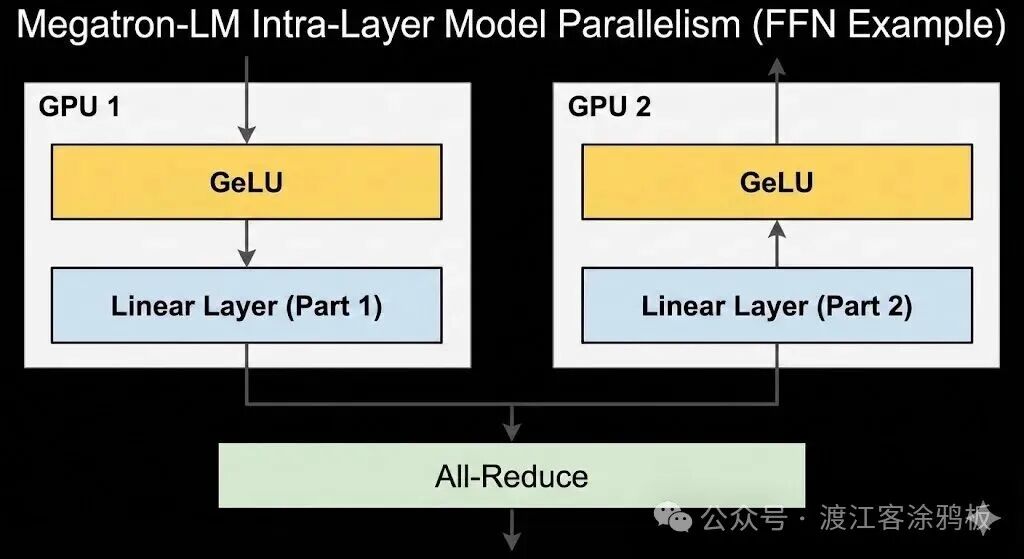
具体实现上,Megatron-LM 走了一条简洁高效的路线。它不依赖特殊的编译器或定制框架,而是通过在现有 PyTorch 的计算图中插入必要的 NCCL 通信原语来实现并行。例如,对于 Transformer 中的多层感知机(MLP)部分,Megatron-LM 将第一层全连接的权重矩阵按列拆分到不同 GPU,GeLU 非线性激活可以在各 GPU 上独立计算;第二层全连接则按行拆分,并在汇聚最终输出前进行一次全规约(All-Reduce)通信。
这种设计的优势在于高度的灵活性和可扩展性。通过少量的通信原语改动,Megatron-LM 就实现了模型权重和中间激活值(activation)的分片存储,大幅降低了单卡内存占用,同时保持了较高的计算效率。开发者无需重写整个模型,只需对标准实现进行局部修改,就能以较低成本将模型扩展到多 GPU 训练。
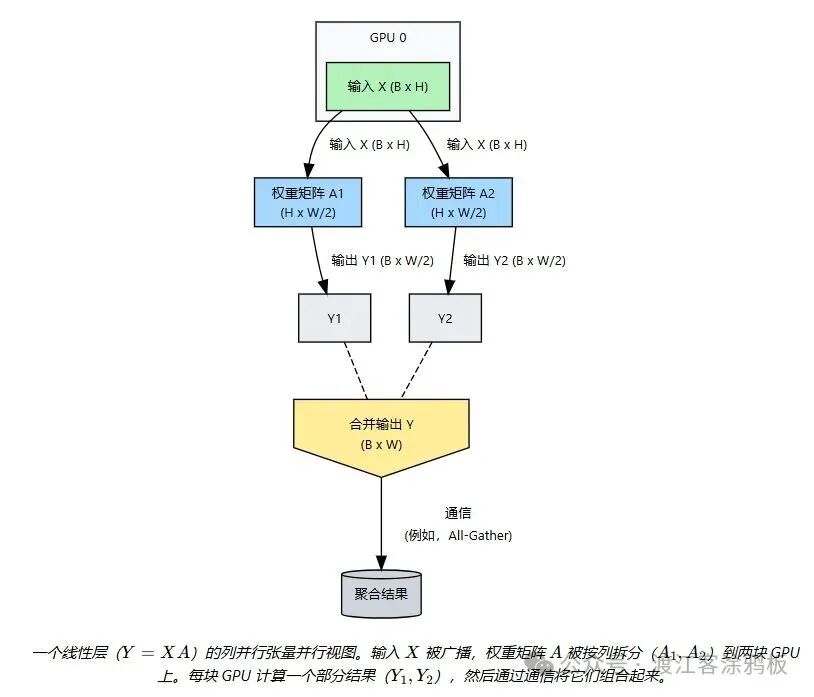
简单来说,层内模型并行就是张量并行(Tensor Parallelism),它将层内的张量操作(如大型矩阵乘法)水平切分到多个设备上,实现真正的计算并行。对于一个线性层 Y = XA,张量并行可以将矩阵 A 按列拆分到 N 块 GPU 上(A = [A1, A2, ..., AN]),每块 GPU 计算 Yi = XAi,然后通过 All-Gather 通信聚合结果 Y = [Y1, Y2, ..., YN]。Megatron-LM 为这些拆分计算提供了优化实现,并集成了必要的通信操作(如 All-Gather、Reduce-Scatter、All-Reduce),通常借助 NVIDIA 的 NCCL 库,以利用 NVLink 等高速互联。
1.2 层间模型并行(流水线并行)
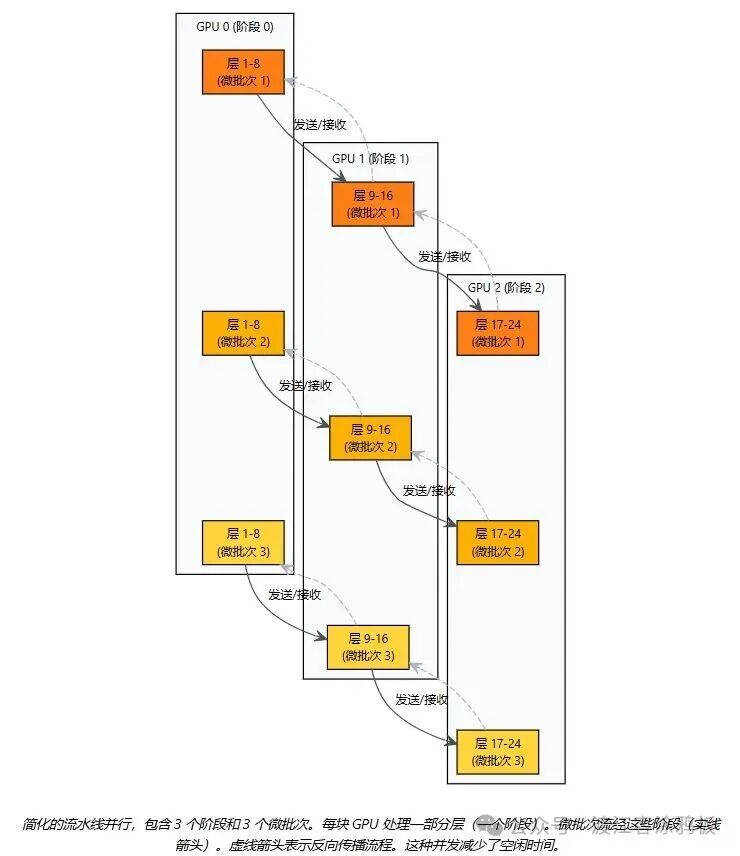
当模型变得极深(层数非常多)时,仅靠张量并行可能仍然不够,或者在过多设备上进行张量并行会导致通信开销过高。这时,流水线并行(Pipeline Parallelism) 登场了。它通过将模型的层按顺序划分成若干“阶段”(Stage),每个阶段分配给一组 GPU(或单个 GPU)。数据像流水线一样依次流经这些阶段。
一个朴素的实现会导致严重的“流水线气泡”问题,即后面的阶段必须等待前面的阶段完成计算,造成大量 GPU 空闲时间。Megatron-LM 通过引入微批次(Micro-batch) 技术来缓解这个问题。它将一个输入批次(Batch)进一步拆分成更小的微批次,然后按序送入流水线。这样,不同的阶段就能并发处理不同的微批次,从而显著提高了硬件的整体利用率。
二、 三维并行策略
Megatron-LM 分布式训练技术的集大成者是其三维并行策略。它将数据并行、张量并行和流水线并行有机结合起来,旨在保持计算效率的同时,最大化模型规模的可扩展性。这套组合拳让训练万亿参数级别的模型成为可能。
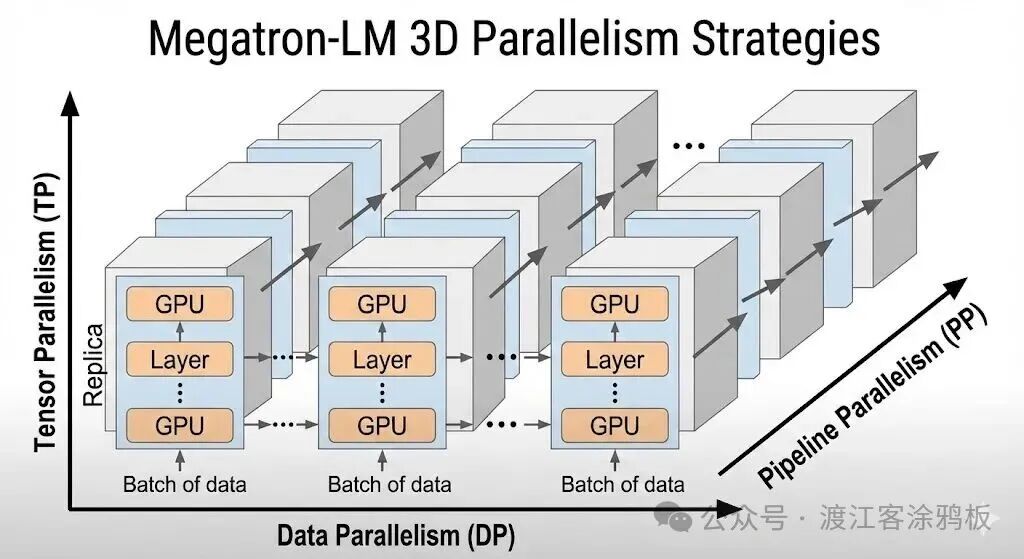
- 数据并行:这是最经典的并行方式。它将训练数据批次拆分到多个设备组,每组设备都维护一份完整的模型副本,独立进行前向和反向计算,最后同步聚合所有设备的梯度来更新模型。但它要求整个模型必须能放入单卡显存,因此无法单独用于训练超大模型。
- 张量并行:如前所述,这是 Megatron-LM 的核心并行策略,专注于层内计算的分解。它让单层模型可以分布在多卡上,突破了单卡内存对层大小的限制。
- 流水线并行:它将模型的不同层组(阶段)分布到不同的设备上,解决了模型深度带来的内存和计算压力。
在实际部署中,这三种并行方式可以灵活组合。例如,可以在一个 GPU 节点内部使用张量并行来切分单个大层,在多个节点之间使用流水线并行来堆叠模型深度,最后再跨多个这样的“模型副本”使用数据并行来加速训练。值得注意的是,当使用 MoE(混合专家)架构并结合专家并行与张量并行时,必须启用序列并行。序列并行能进一步减少激活值的内存占用,这对于高效训练 MoE 模型至关重要。想深入了解此类前沿 开源项目 的实现细节与最佳实践,可以持续关注相关技术社区的讨论。
三、 最新技术进展与发展趋势
Megatron-LM(及其核心组件 Megatron-Core)的技术发展呈现以下几个显著趋势:
- 向多模态训练扩展:Megatron-Core v0.7 版本新增了对多模态训练的原生支持,集成了完整的 LLaVA 流水线。它支持使用 Megatron 开源的多模态数据加载器,以确定性和可重现的方式混合多模态数据集,这一特性在模型检查点的保存和加载中也能完好工作。
- 深度集成 MoE 架构:最新版本对混合专家模型进行了深度优化。例如,为 Mamba 混合模型新增了完整的 FP8 支持、CUDA Graph 加速和多模态分词器集成。新增的 FP8 配方选择参数允许用户灵活配置首尾层的精度,大幅降低推理内存占用。全新的 DeepEP 架构兼容所有并行技术,并支持多种令牌路由策略。
- 通信优化持续增强:框架不断引入新的通信优化技术,包括 GroupedGEMM(当本地专家数大于1时)、FP8 训练支持、无令牌丢弃/带填充的令牌丢弃策略、分布式检查点等,旨在减少通信开销,提升整体训练效率。
- 系统性能系统性提升:集成最新的底层计算库是性能飞跃的关键。例如,通过集成 cuDNN 9 和 CUTLASS,Megatron-Core 在部分场景下将训练速度提升了 2-5 倍。同时,它对 NVIDIA Hopper 和 Blackwell GPU 架构提供了原生支持,进一步释放了新一代硬件的 计算潜力。
这些持续的技术演进,使得 Megatron-Core 不仅仅是一个研究框架,更成为一个能够支撑工业级超大规模模型训练的生产力工具。对于希望深入掌握大规模 深度学习 训练核心技术细节的工程师和研究者而言,理解 Megatron-LM 的设计哲学与实现原理,是构建高效 AI 基础设施的必修课。你可以在 云栈社区 找到更多关于分布式训练、模型优化及 GPU 编程的深度技术讨论与资源分享。
参考资料
 发表于 2026-2-12 11:29:20
|
查看: 367|
回复: 0
发表于 2026-2-12 11:29:20
|
查看: 367|
回复: 0
