在深入学习卷积神经网络(Convolutional Neural Networks, CNN)之前,我们已经走过了深度学习的基础阶段:掌握了如何将图像转为张量、如何用参数化模型进行预测、如何用损失函数评估模型,并通过反向传播与梯度下降优化参数。
深度学习的核心在于,通过前向计算和反向传播,让模型自动学习从输入到输出的映射关系。那么,面对具有强烈空间结构的图像数据,模型该如何高效且可靠地“观察”并提取有用信息?这正是今天的主角——卷积神经网络(CNN)所要解决的核心问题。
一、计算机视觉的新篇章:从特征工程到端到端学习
在深度学习成为主流之前,计算机视觉长期依赖人工特征工程。研究者需要根据经验手动设计颜色直方图、梯度方向直方图(HOG)、SIFT等特征,再交给传统机器学习模型去分类。这种方式高度依赖人的直觉,难以应对复杂多变的真实场景,一旦场景变化,特征往往失效。
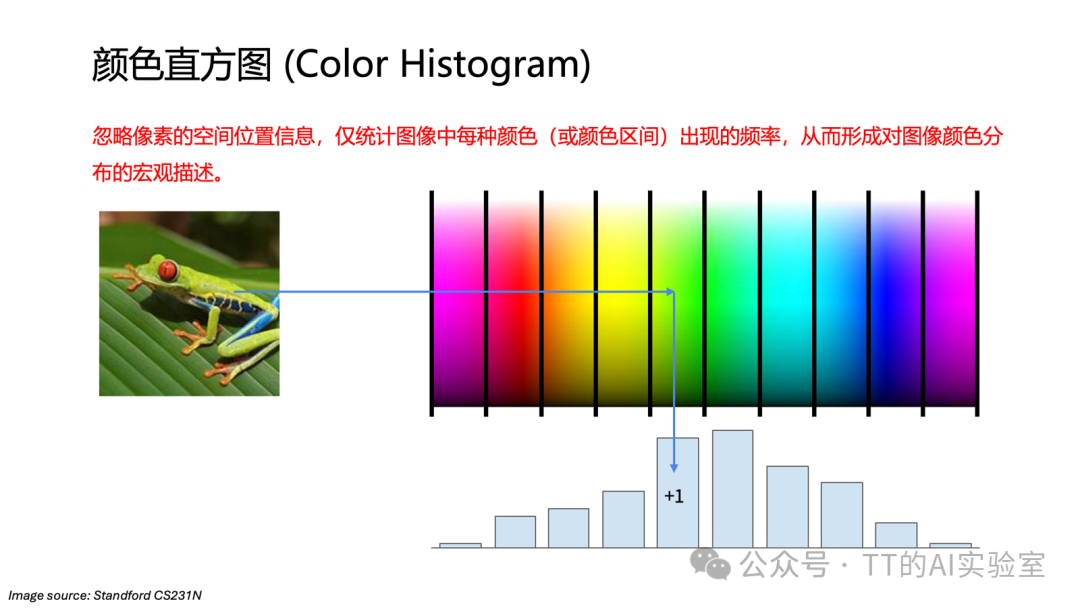

卷积神经网络的出现,正是为了解决这一核心矛盾:能否让模型自己从数据中学习“什么是有用的视觉特征”,而不是由人事先设定?
CNN的思想渊源可以追溯到上世纪50年代对生物视觉系统的研究,揭示了视觉皮层中“局部感受野”和“层级处理”的机制。

真正让CNN成为可用工程模型的是Yann LeCun在1990年代提出的LeNet,用于手写数字识别。但受限于当时的算力和数据规模,CNN并未立即流行。
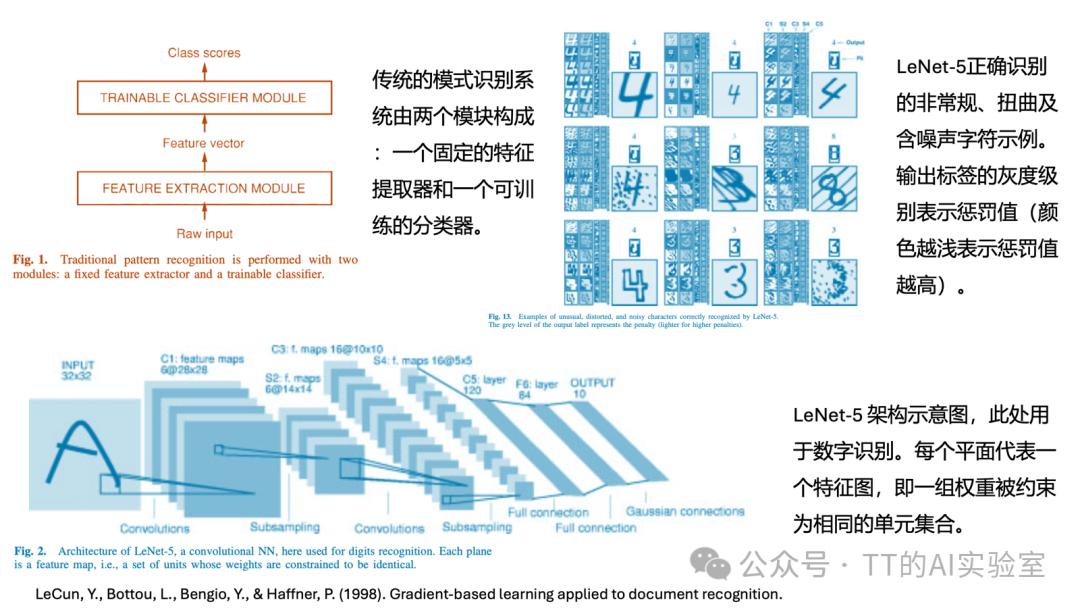
直到2012年,AlexNet 在ImageNet竞赛中以压倒性优势夺冠,CNN才真正引爆整个计算机视觉领域。AlexNet在结构思想上继承了LeNet,但将其理念放在了更深的网络、更大的数据集、更强的算力之上。从那一刻起,视觉任务的主流范式发生了根本转变:从“先设计特征,再训练模型”变为“端到端地让模型自己学习特征”。
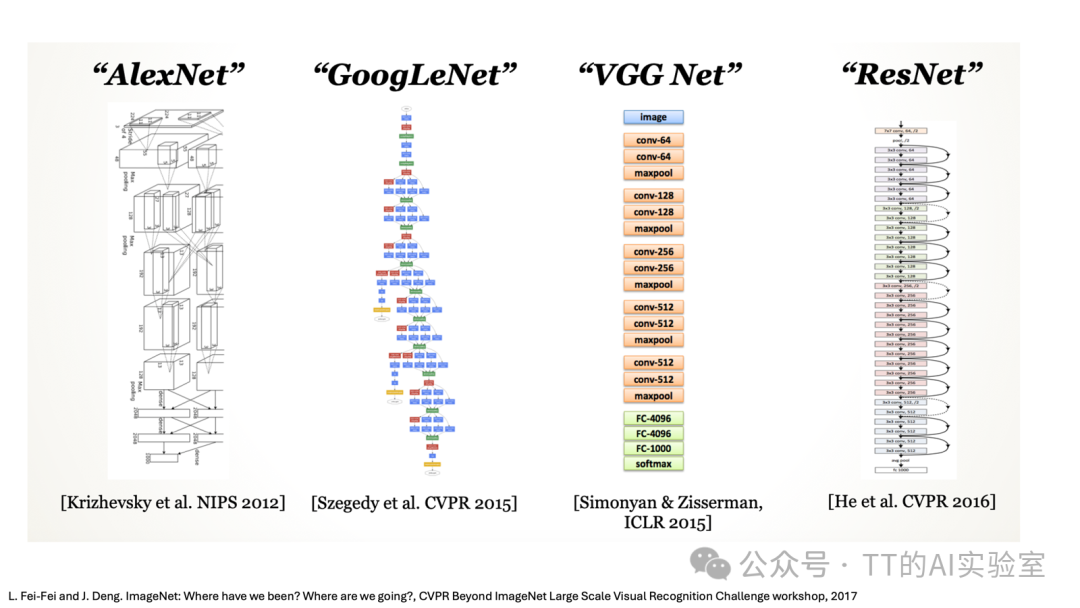
从2012年到2020年,CNN几乎统治了所有主流计算机视觉任务:
- 目标检测(Detection):识别物体并定位。
- 语义分割(Segmentation):对图像中每个像素进行分类。
- 图像描述(Image Captioning):将图像内容转化为文字描述。
- 早期生成模型:为Stable Diffusion等系统的早期视觉架构奠定了基础。
可以说,在这八年间,几乎所有主流视觉任务的演进都是围绕CNN展开的。2020年后,随着Transformer从自然语言处理领域被引入视觉建模(Vision Transformer, ViT),视觉领域开始了新的范式迁移。在超大规模数据与算力条件下,Transformer凭借其全局建模能力展现出新的潜力。
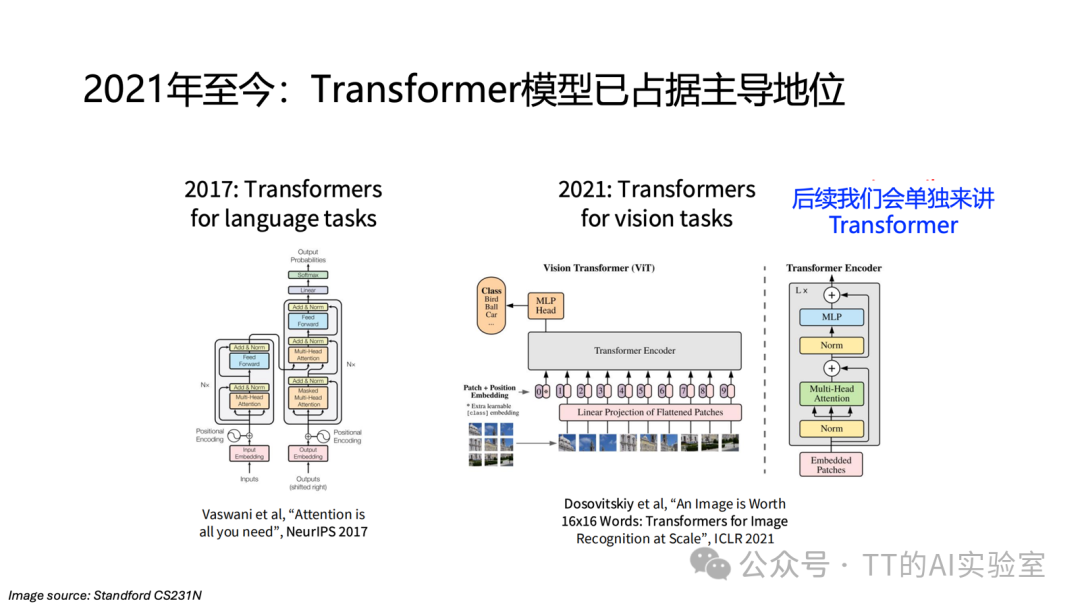
但这绝不意味着CNN已经“过时”。恰恰相反,理解CNN在今天依然至关重要,原因至少有三点:
- 它是计算机视觉历史上第一套真正成功、可规模化的建模范式。
- 现实世界中许多高效的视觉系统,仍然是CNN与Transformer的混合体。
- CNN能帮助我们建立对图像空间结构、局部性与层级表示的深刻直觉,这是理解一切视觉模型的基础。
二、卷积神经网络的核心组成
卷积神经网络本质上是一个处理图像的计算图,由四种基本“原语”(构建网络的最基本操作单元)构成。我们已经学过全连接层和激活函数,今天将重点学习另外两个核心层:卷积层和池化层。
在深入卷积层之前,我们先快速回顾一下全连接层。以一张32×32×3的彩色图像(32×32是空间尺寸,3是RGB通道)为例:
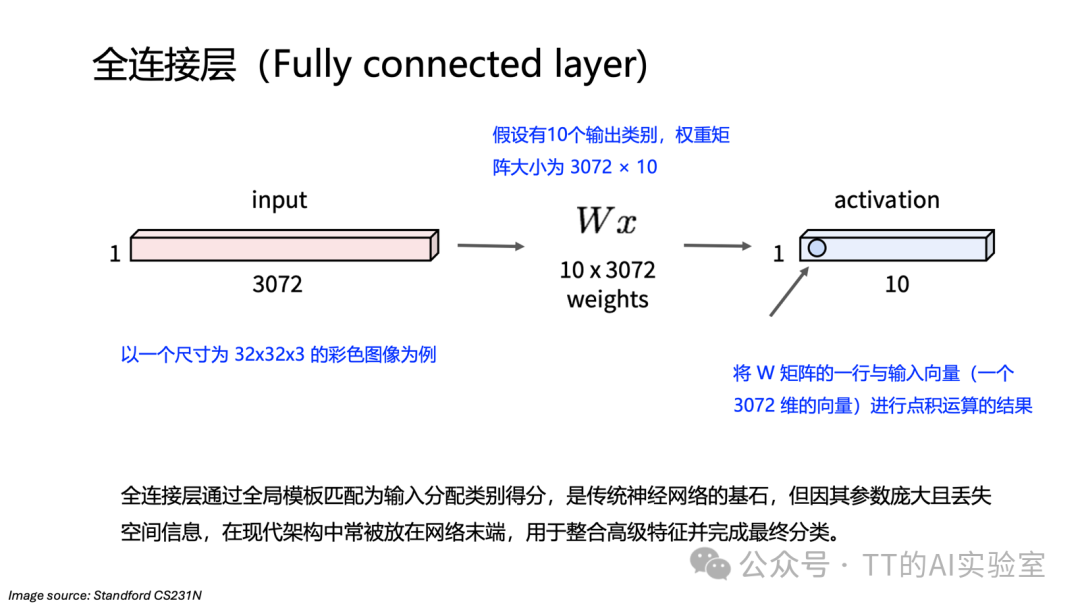
- 操作:将图像展平成一个3072维的向量。
- 计算:假设有10个输出类别,权重矩阵大小为3072×10,通过矩阵乘法得到10个类别的得分。
- 本质:可以理解为“模板匹配”,当输入向量的方向与某个权重模板一致时,得分最高。
但这也暴露了全连接层的关键问题:参数量巨大,且完全破坏了图像的空间结构,无法高效利用像素间的局部关联信息。
三、卷积层:局部模板匹配
为了保持空间结构并大幅减少参数,CNN引入了卷积层。其核心思想是局部模板匹配。卷积层保持输入的三维结构(高度×宽度×通道),并引入一个称为滤波器(Filter) 或卷积核(Kernel) 的小矩阵。滤波器的深度与输入通道数一致,空间尺寸(如3×3或5×5)则远小于图像本身。
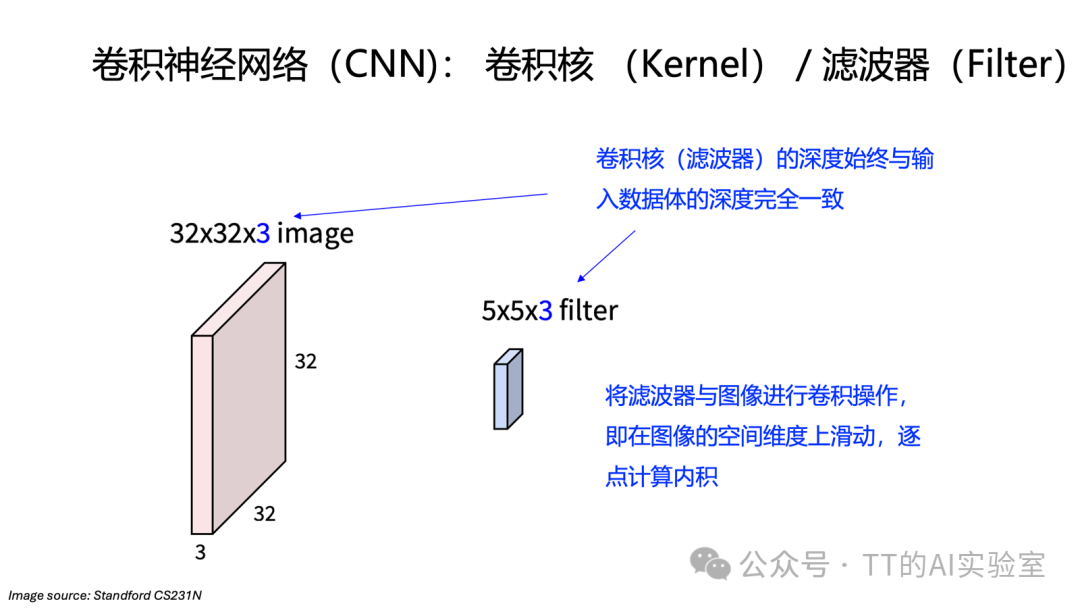
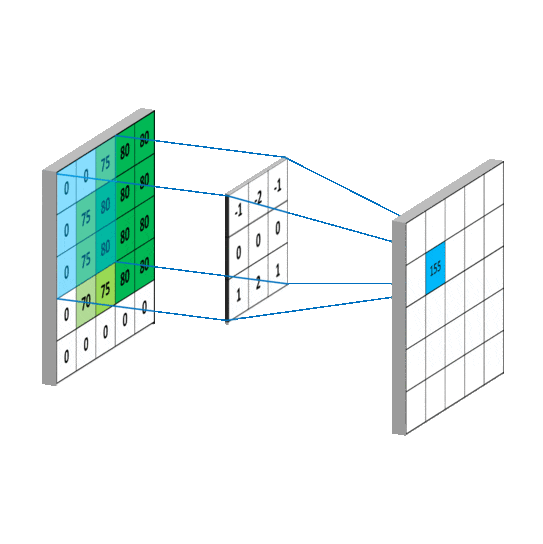
卷积操作就是让这个滤波器在输入图像的空间维度上滑动,在每个位置计算滤波器与对应局部图像块的点积,得到一个标量输出。所有位置的输出组合起来,便形成一张二维的激活图,表征了该特定特征在图像中的空间分布。
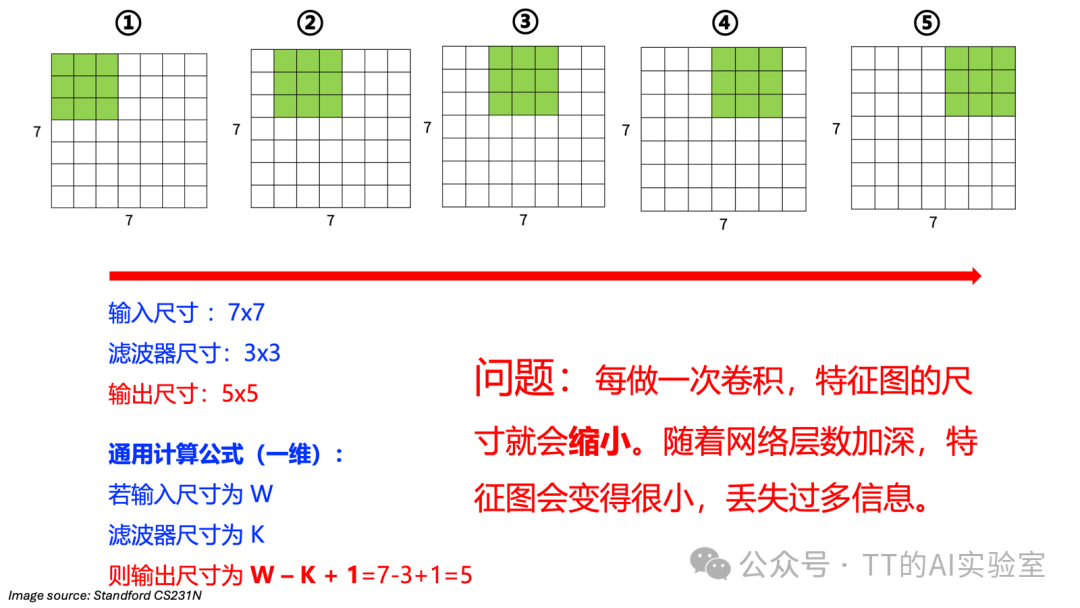
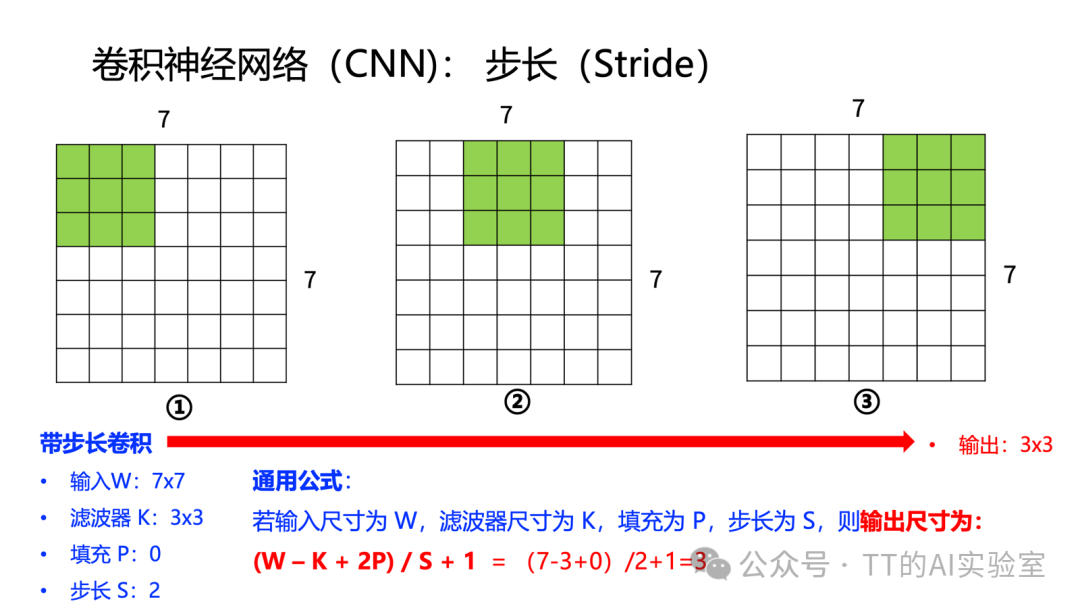
然而,每进行一次卷积,输出特征图的尺寸就会缩小。例如,对7×7的输入应用3×3卷积(无填充),输出会变成5×5。随着网络层数加深,特征图可能迅速变小,导致信息丢失。
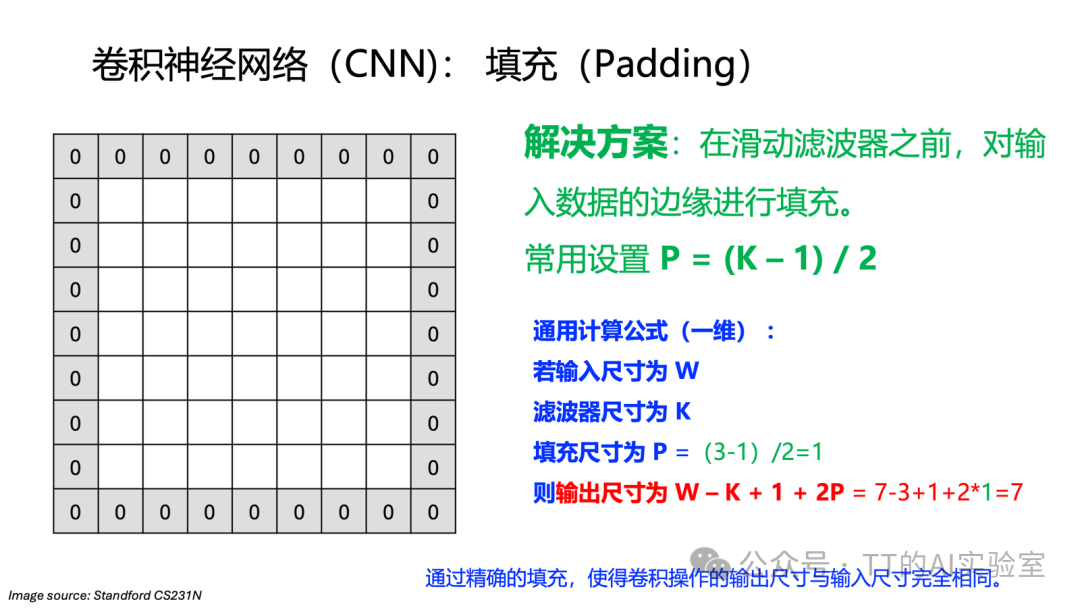
为了解决这个问题,我们引入填充(Padding):在输入图像的边缘添加额外的像素(通常补零),以控制卷积后的输出尺寸。一个常用的设置是P = (K - 1) / 2,其中K是滤波器尺寸。例如对于3×3卷积,P=1,在四周补一圈零后,输出尺寸就能与输入保持一致。
另一个关键概念是步长(Stride),它定义了滤波器每次滑动时移动的像素数。步长越大,输出特征图的尺寸越小,计算量也随之减少,同时感受野增长得更快。
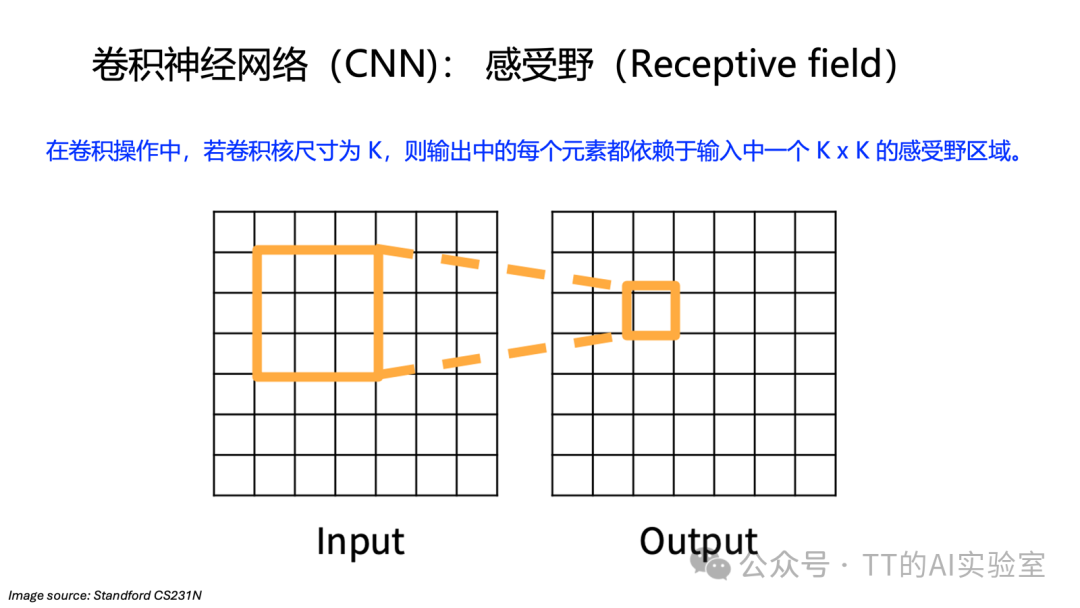
感受野是指网络中某个神经元输出所对应输入图像的区域大小。它是理解深度学习网络如何逐层组合信息的关键。
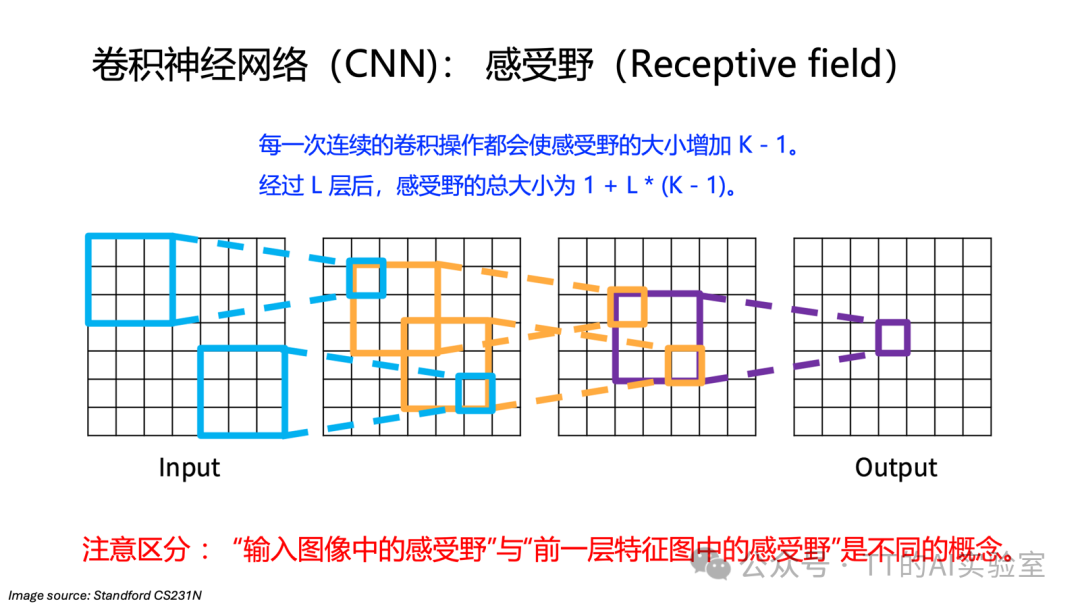
通过堆叠卷积层,高层神经元能够感知越来越大的输入区域,从而从简单的边缘、纹理逐步组合成复杂的形状和物体结构。
来看一个具体计算例子:
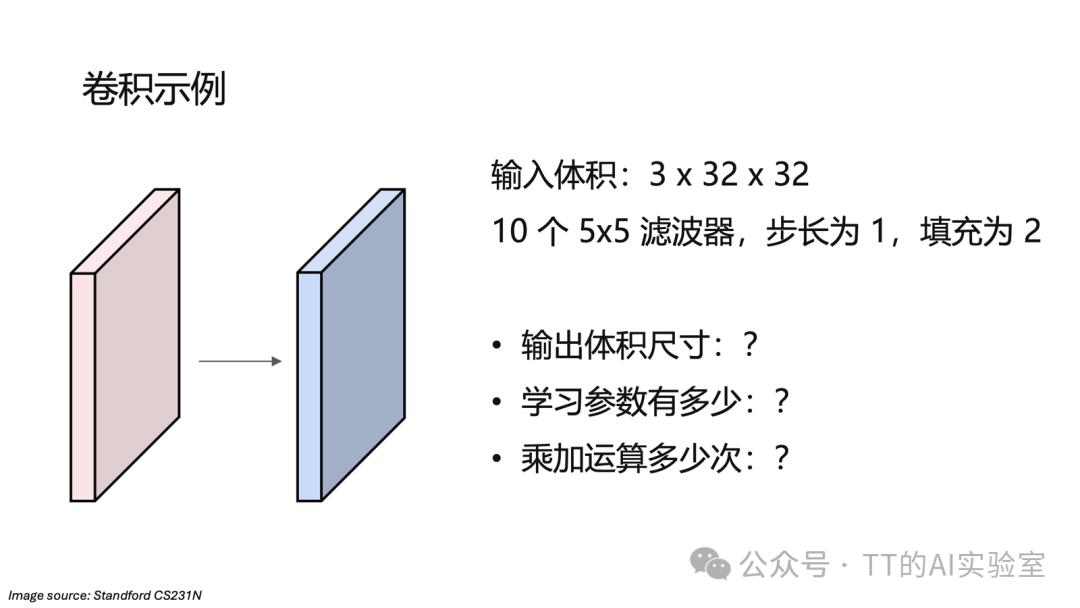
假设输入是3×32×32的图像,使用10个5×5的滤波器,步长S=1,填充P=2。
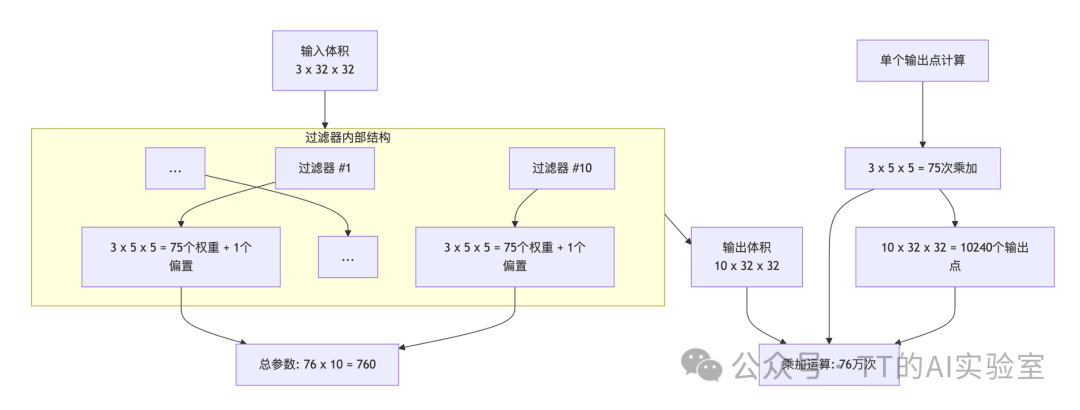
- 输出尺寸:10×32×32
- 可学习参数:每个滤波器有5×5×3=75个权重 + 1个偏置 = 76个参数,10个滤波器共760个参数。
- 计算量:每个输出点需要75次乘加运算,总计算量约为 32×32×10×75 ≈ 768,000 次乘加运算。
可以看到,卷积层通过权重共享(同一滤波器在不同位置使用相同的权重)极大地减少了参数量,但由于需要在空间上滑动计算,实际计算量仍然可观。
卷积层小结
在CNN中,卷积层处理三维张量输入:Cin × H × W(输入通道×高度×宽度)。其行为由超参数和可学习参数共同决定。


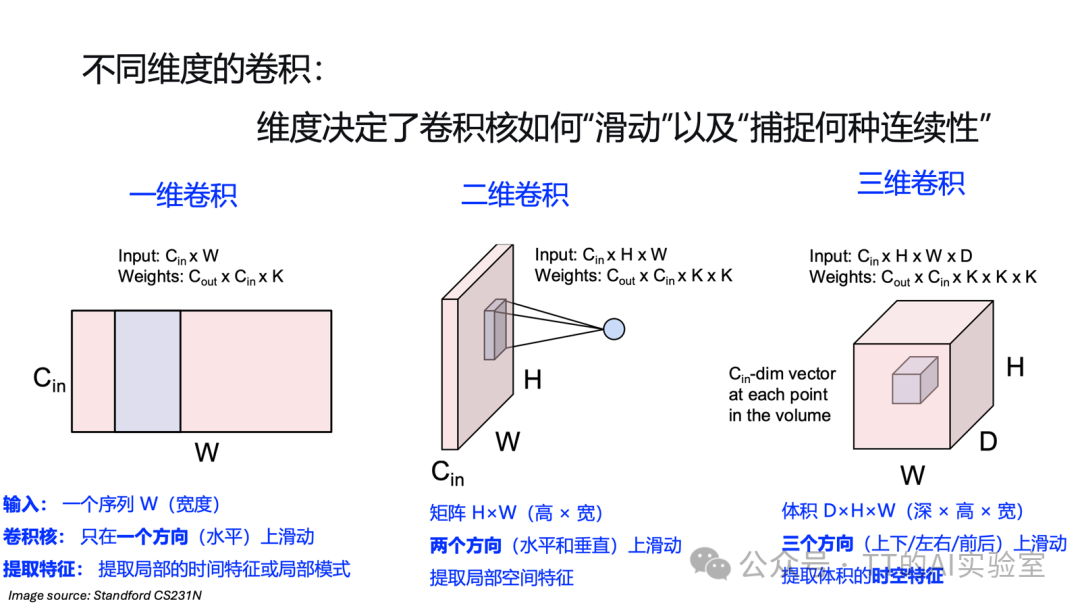
综上所述,卷积层通过局部感受、权重共享、填充调节、步长控制、多通道堆叠,实现了对图像数据的高效、结构化建模。
四、池化层:降维与平移不变性
在卷积层提取特征之后,我们常常使用池化层进行空间下采样。其主要作用是减小特征图尺寸以降低后续计算量,并赋予网络一定的平移不变性。
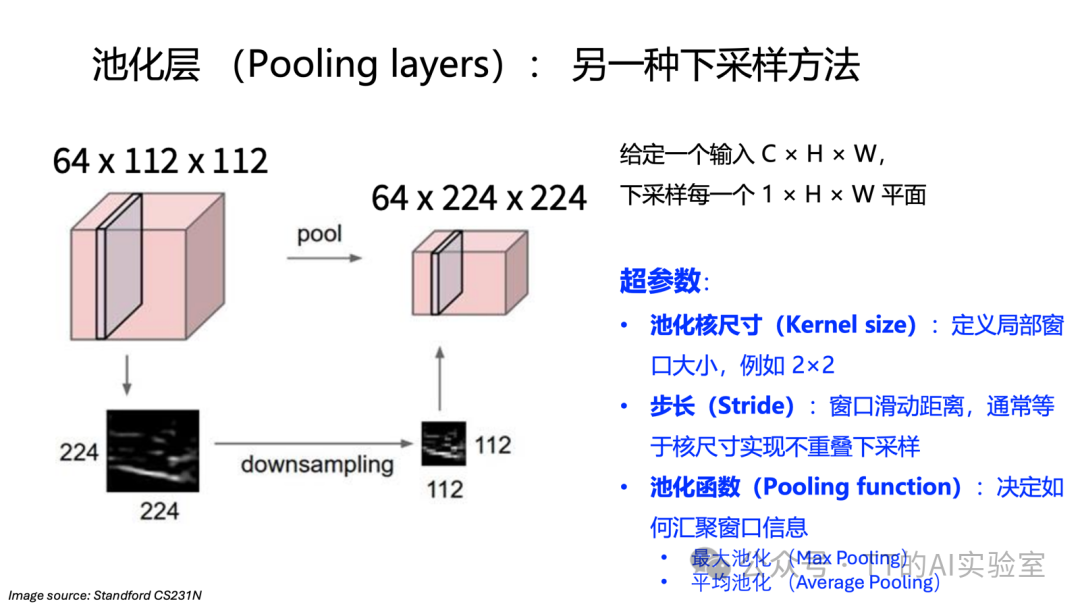
直观来看,池化层不改变通道数(C),但会将特征图的空间尺寸(H, W)缩小。例如,输入为64×224×224,经过2×2池化(步长2)后,输出变为64×112×112。
池化操作通常是逐通道独立进行的。最常用的是最大池化,它在每个局部窗口中选取最大值作为输出。
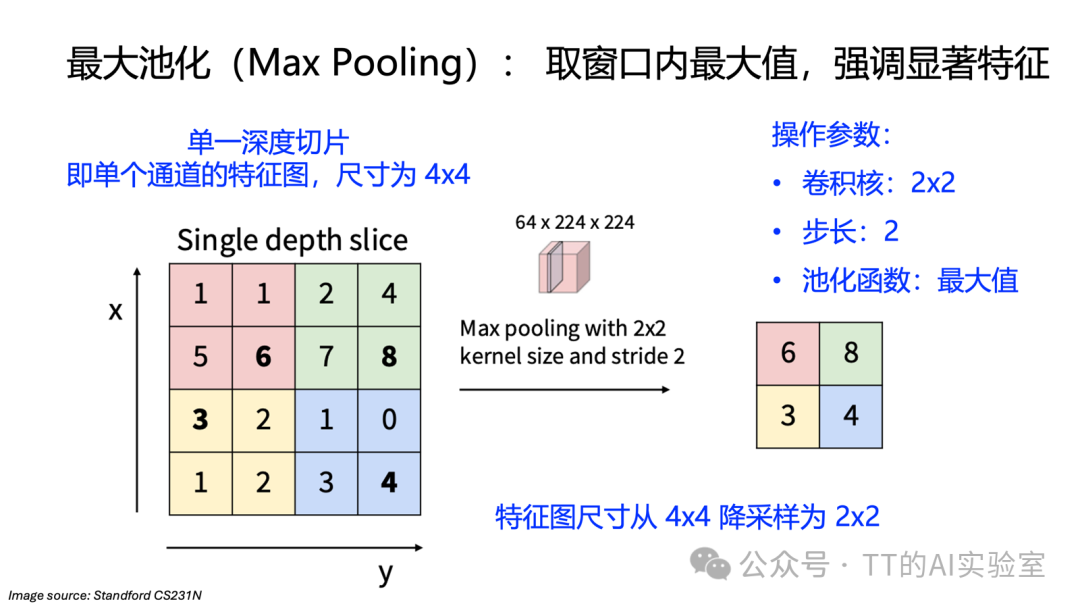
池化层的核心特性:
- 无可学习参数:池化规则(如取最大值、平均值)是固定的。
- 逐通道操作:每个通道独立池化,不混合通道间信息。
- 平移不变性:输入特征发生小幅平移时,池化后的输出基本保持不变。这使得网络更关注“特征是否存在”,而非其精确位置。
池化是CNN中一种轻量且高效的下采样方式。需要注意的是,卷积本身具有的是平移等变性:当输入图像平移时,卷积输出的特征图也会发生相应的平移。这保留了精确的空间位置信息,对于目标检测等任务至关重要。
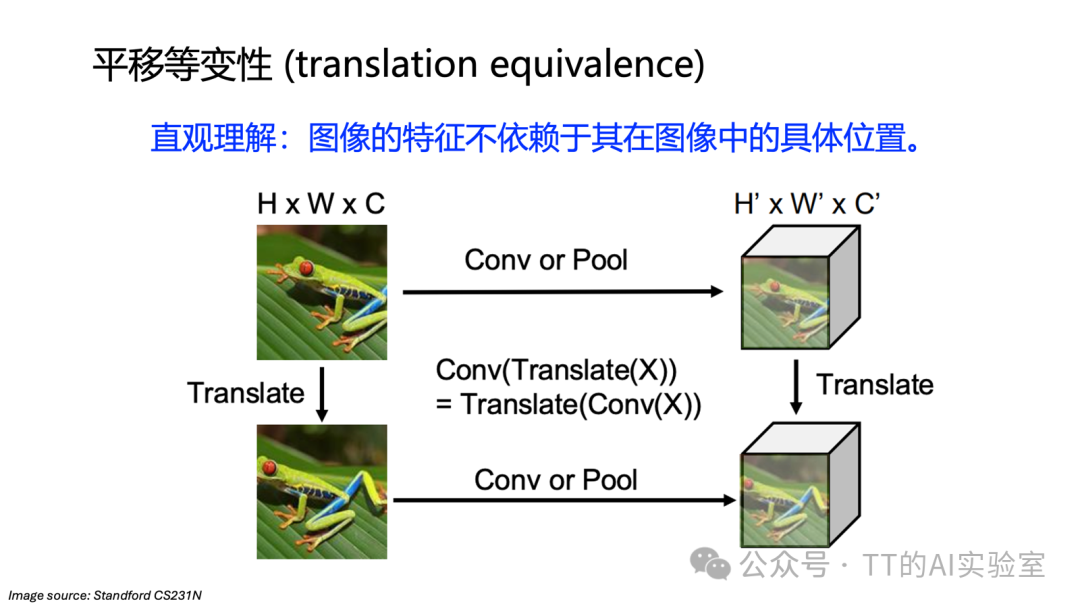
简单总结:
- 池化 → 平移不变性(对小幅移动不敏感,利于分类)
- 卷积 → 平移等变性(保留空间对应关系,利于检测、分割)
两者结合,使得CNN既能稳定地识别图像中的模式,又能保留必要的空间结构信息。
本篇小结
卷积神经网络从LeNet的诞生,到AlexNet引发的革命,再到成为主流视觉任务的基石,完成了从实验模型到工程范式的成功演进。其核心优势在于能够端到端地从数据中自动学习有效的视觉特征,从而摆脱了对人工特征工程的依赖。
本节我们重点剖析了CNN的两个关键模块:卷积层与池化层。卷积层通过其独特的局部连接和权重共享机制,实现了对图像空间结构的层级化特征提取;池化层则通过下采样提供了计算效率和平移不变性。理解这两大组件,是掌握CNN工作原理、进而设计或应用现代视觉神经网络模型的基础。
在掌握了这些核心“原语”之后,我们便可以在云栈社区与更多开发者一起,探索如何将它们组合成完整的网络架构,并进行有效的训练,将理论转化为解决实际视觉问题的能力。
 发表于 2026-2-9 07:43:41
|
查看: 279|
回复: 0
发表于 2026-2-9 07:43:41
|
查看: 279|
回复: 0
