DeepSeek一直以其原创性给技术社区带来新的启发和思路。近期,其发布的两项重大更新——OCR 2模型和mHC(Manifold-Constrained Hyper-Connections)架构,再次引发了广泛讨论。本文将深入解析这两项技术的核心原理与创新价值。
突破一:DeepSeek-OCR 2 —— 教AI像人一样阅读
昨天,DeepSeek发布了升级后的OCR 2模型。其核心优化在于引入了模拟人类视觉的“因果推理”机制,并用大模型架构替换了传统的CLIP模型,旨在突破传统OCR固定栅格扫描的局限。
两代OCR的演进思路
- DeepSeek-OCR 1:在2025年10月发布,其核心价值在于证明了视觉压缩是解决LLM处理长上下文效率低下的可行且高效路径,实现了“一图胜万言”。
- DeepSeek-OCR 2:于2026年1月27日发布,它试图证明视觉语言模型可以通过“因果流”和动态语义阅读顺序,实现人类级别的文档逻辑理解。
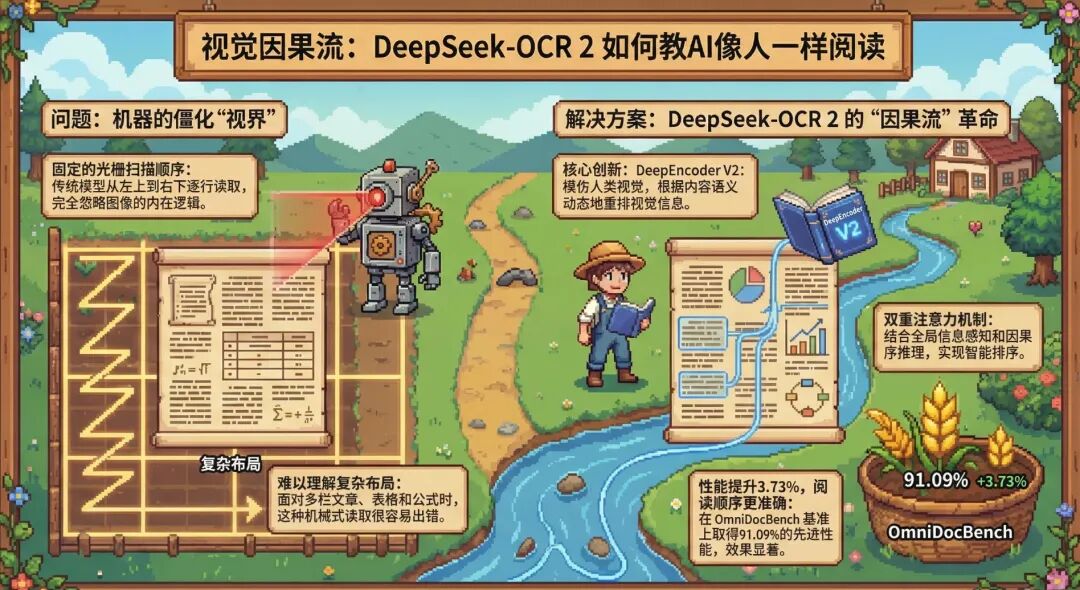
OCR 2彻底抛弃了CLIP等传统ViT骨干网络,转而采用Qwen2-0.5B作为视觉编码器(称为DeepEncoder V2),并引入了Visual Causal Flow机制。简单来说,模型会先全局理解图像布局,再根据语义内容动态决定“先看哪块、再看哪块”,这类似于人类阅读报纸时会跳过广告、优先阅读标题和正文,而非机械地从左上角到右下角进行扫描。
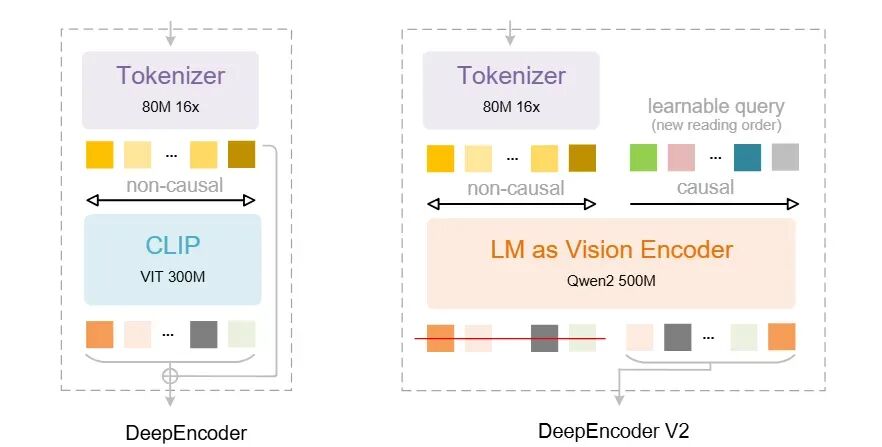
上图清晰地展示了DeepSeek-OCR 2的核心架构创新:
- DeepEncoder:使用CLIP ViT作为视觉编码器。这是一种传统的“非因果”架构,视觉Token之间通常是全向交互,处理顺序固定(如光栅扫描)。
- DeepEncoder V2:将CLIP替换为LLM风格的架构(Qwen2 500M)。这部分被称为“LM as Vision Encoder”,它引入了关键的因果推理能力。
从“非因果”到“因果”:注意力机制的变革
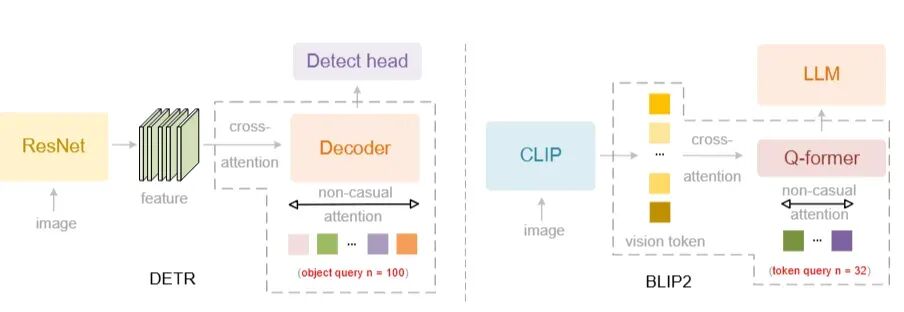
传统的视觉模型普遍采用双向注意力,即Query A可以看到Query B,Query B也可以看到Query A,这被称为 “Non-causal”。
而DeepSeek-OCR 2虽然也使用Query,但强制将其改为 “Causal” ,即单向注意力。例如,Query 2只能看到Query 1的信息,Query 3只能看到Query 1和2的信息。
这样设计的目的,是为了模拟人类阅读复杂文档的方式。当我们阅读报纸、表格时,视线移动是由语义驱动的,而非简单的坐标驱动。因果注意力机制迫使模型打破“位置决定顺序”的传统限制,实现“语义决定顺序”。模型需要学会渐进式地整理信息:Query 1找到第一段话,Query 2基于此结果去寻找逻辑上的第二段话(即使它在图像的左下角),依此类推。
模型架构的三段式设计
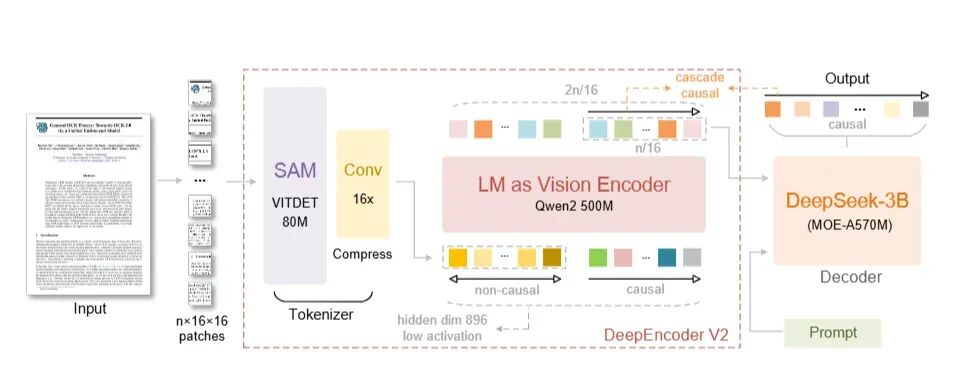
整个模型可以清晰地划分为三个串联的部分:视觉分词器(左侧)、DeepEncoder V2 视觉编码器(中间)、DeepSeek-MoE Decoder 解码器(右侧)。
- 在编码器中,通过DeepEncoder V2,将无序的2D图像特征,转化为有序的、符合人类阅读逻辑的1D序列。
- 在解码器中,解码器无需再处理复杂的视觉位置关系,只需根据已经排好序的语义信息,通过语言模型生成文本即可。
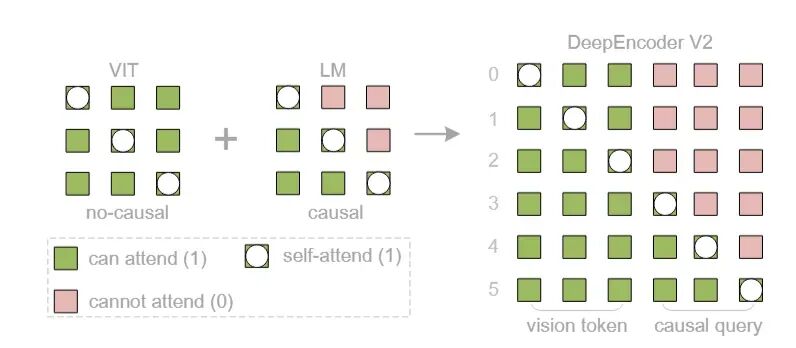
DeepEncoder V2的注意力矩阵被设计为左右两部分,对应不同的处理方式:
- 左侧/上半部分是视觉Token:它们之间可以互相“看见”,保留了传统ViT的全局感受野,确保不因位置先后而丢失上下文信息。
- 右侧/下半部分是因果流查询:强制模型必须按照生成的先后顺序来建立逻辑依赖,模拟人类的渐进式阅读。
性能表现与深远意义
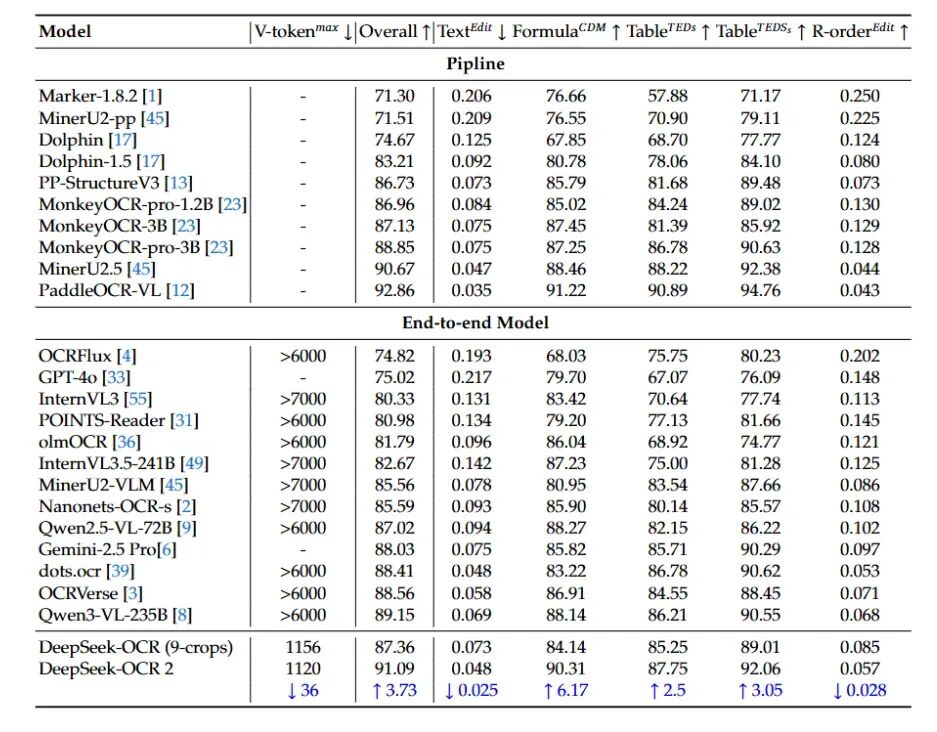
实验结果表明,DeepSeek-OCR 2在仅使用极少视觉Token(计算成本低)的情况下,依然取得了超越现有开源乃至商业闭源模型(如GPT-4o)的SOTA性能。
DeepSeek-OCR 2的架构不仅是OCR技术的革新,更是迈向“通用模态编码器”的重要一步。在这一设计下,我们可以预见一个“参数共享”的超级引擎——共享 Wk,Wv映射和FFN层。当处理图像、音频或文本时,唯一的变量是特定模态的Learnable Query。这种设计有望将不同模态的特征提取与逻辑压缩统一在同一个参数空间内,彻底打破模态间的壁垒。
论文地址:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
突破二:mHC超连接——重塑深度神经网络的稳定之道
在元旦期间,DeepSeek提出的mHC新思路同样震撼了AI社区。要理解mHC,我们首先需要回顾何凯明团队提出的经典ResNet残差网络。
ResNet解决的核心问题是“深度退化”:即当网络层数过深时,训练误差和测试误差不降反升。其关键创新——残差连接,通过公式输出 = F(x) + x,让网络可以轻松学习恒等映射,确保了深层网络的稳定训练。

然而,DeepSeek指出,十年来“通过增加更多层”的残差连接策略,虽然稳定,但也隐含地限制了网络对信息的转换能力。他们提出了一种重写神经网络方案:从简单的加法残差,转向定义在流形上的几何约束。
ResNet, HC, mHC 的对比与演进
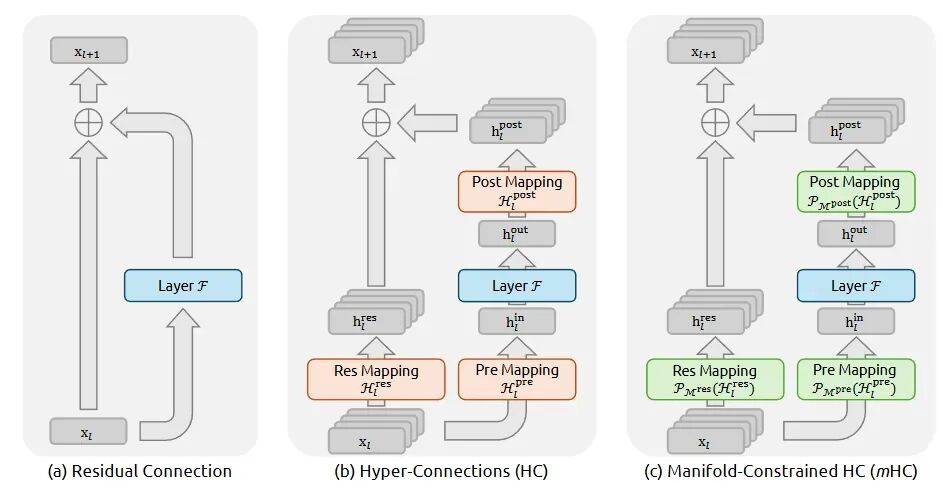
- 普通Transformer/ResNet的残差连接:是“单车道”(
F(x) + x),信号强度稳定,但容量有限。
- Hyper-Connections:由字节跳动提出,旨在将残差变为“多车道”,即一层内有多条并行路径加回输入,以期大幅增加模型容量和训练效率。
- mHC:DeepSeek在HC基础上引入了流形约束。无约束的HC会导致信号强度指数级爆炸、梯度失控,模型难以训练。mHC通过数学约束(如Sinkhorn-Knopp算法强制路径权重归一化),确保多路径下的信号强度严格稳定在≈1.0倍,从而在几乎不损失性能的情况下,获得了HC的容量优势。
mHC的工作原理:压缩、加工、扩张
具体来说,mHC通过三个步骤实现稳定高效的信息流动:
-
压缩
初始输入被复制为多份(例如代表语法、上下文等不同语义的向量)。mHC使用一个可学习的预映射矩阵 H_pre,将这些向量通过加权求和压缩成1个向量,从而大幅降低后续计算开销。
-
加工
将压缩后的这1个向量送入标准的Transformer层进行计算,这是整个网络中最核心的“思考”过程。
-
扩张
计算完成后,得到1个新的输出向量。此时使用另一个后映射矩阵 H_post,将其“广播”回原来的多个通道。这不是简单复制,而是根据权重将新知识以不同比例分配给各通道,从而产生差异化的语义信息。
mHC稳定性的核心:双随机矩阵约束
mHC的约束是解决HC崩溃问题的关键。DeepSeek强制要求用于混合旧信息的残差映射矩阵 H_res 必须是双随机矩阵。
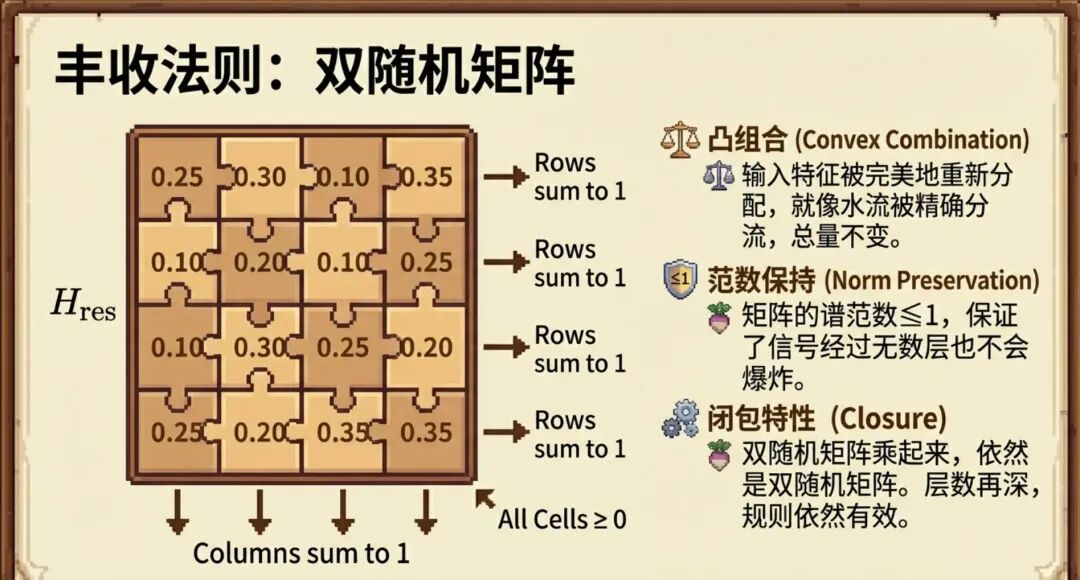
- 规则:矩阵的每一行和每一列的和都必须等于1,且所有元素非负。
- 作用:这保证了无论信息在多个通道间如何重新分配,总信号强度(能量)保持不变,从而有效防止了数值爆炸或消失,确保了深层网络的稳定性。
最后,将“计算路径”产生的新知识,与“残差路径”混合后的旧记忆相加,形成下一层的输入。其核心公式可以表示为:
x_new = H_res · x_old + H_post^T · F(H_pre · x_old)
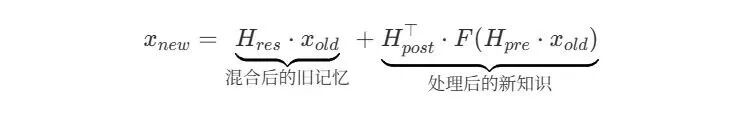
DeepSeek通过mHC证明了,只要辅以恰当的数学约束(流形约束),完全可以驯服更复杂的非线性拓扑结构,从而在保持训练稳定的前提下,获得更大的模型信息容量,这为下一代深度学习模型的架构设计提供了全新思路。
社区复现与相关资源
已有技术博主对mHC进行了复现,并取得了比原论文更优的效果:
结语
DeepSeek-OCR 2和mHC这两项工作,分别从视觉语言模型的应用层面和基础神经网络架构层面提出了创新性解决方案。前者试图让AI真正理解视觉世界的逻辑,后者则为构建更强大、更稳定的深度模型扫清了理论障碍。这些突破不仅是技术上的进步,更为整个AI社区提供了宝贵的思考方向。对这类前沿技术解析感兴趣的朋友,欢迎在云栈社区进行更深入的交流与探讨。
 发表于 2026-2-9 04:30:16
|
查看: 239|
回复: 0
发表于 2026-2-9 04:30:16
|
查看: 239|
回复: 0
