在AI技术快速发展的今天,无论是与大语言模型对话,还是探索图像生成的奥秘,“Token”这个词你肯定不陌生。它频繁出现在技术文档、API计费说明和模型原理讨论中,但对许多开发者或初学者而言,它又像一个熟悉的陌生人——似乎明白,却又难以言明其本质。理解Token究竟是什么,不仅是掌握AI技术核心原理的关键一步,也能帮你清晰地看透:调用API时,你的钱到底是怎么被“算”出去的。
Token 的定义
Token,本质上就是将输入数据切分而成的“微小单元”。你可以把它想象成构建AI认知世界的一块块乐高积木。在不同的AI应用场景中,这块“积木”的形态各不相同:
- 在自然语言处理(NLP)领域,一个Token可能是一个完整的单词(如“apple”)、一个子词(如“un”、“##able”),甚至是一个字符。
- 在计算机视觉(CV)领域,特别是在基于Transformer架构的模型中,一个Token通常对应图像被划分后的一个小方块(Patch)。
简而言之,Token是AI模型用于表示、理解和处理数据的基本信息单元。模型并不直接“读懂”我们的文字或“看见”完整的图片,而是处理这些Token及其相互关系。
Token 的历史来源
早期计算与通信领域起源
“Token”这个概念并非AI原生,它的历史根植于更早的计算机基础与网络通信领域。在计算机网络中,经典的“令牌环网”(Token Ring)拓扑结构就使用了“令牌”机制。网络中的“令牌”是一个特殊的控制帧,在节点间依次传递,只有拿到令牌的节点才有权限发送数据。这有效避免了数据冲突。虽然此“令牌”与AI中的Token在具体形态上相去甚远,但它赋予了Token“代表某种权限或信息的传递单元”这一核心内涵,为后来的概念迁移奠定了基础。
自然语言处理中的发展
随着AI,特别是自然语言处理的兴起,如何让计算机理解人类连续、复杂的语言成了核心挑战。计算机天生擅长处理离散、结构化的数据。于是,研究者们很自然地借鉴了“Token”作为离散单元的思想,将连续的文本流切分成一个个Token(最初就是单词),以便进行词频统计、语法分析等操作。
然而,单纯以单词为Token遇到了瓶颈:如何处理德语中的超长复合词?如何应对中文这种没有明显空格分隔的语言?面对词典中未收录的新词(如“区块链”、“元宇宙”)又该怎么办?为了解决这些问题,更灵活的“子词”(Sub-word)化方法应运而生,例如字节对编码(BPE),它能够根据数据统计规律,自适应地生成最合适的Token单元,极大地提升了模型处理未知词汇和不同语言的能力。
Token 的计算方法
自然语言处理中的 Token 计算
- 基于单词的 Token 化:最简单直接的方法,按空格和标点分割。例如,“I love AI.” 会被切成
["I", "love", "AI", "."] 四个Token。缺点也很明显:无法很好处理“don't”这类缩写,对中文等语言也不适用。
- 字节对编码:这是一种数据驱动的子词分割算法。它从字符级别开始,不断合并出现频率最高的相邻字符对,直到达到预设的词汇表大小。例如,在“low”, “lower”, “newest”, “widest”这个文本集中,算法可能会学习到将“lo”和“w”合并为“low”,将“e”和“r”合并为“er”等。
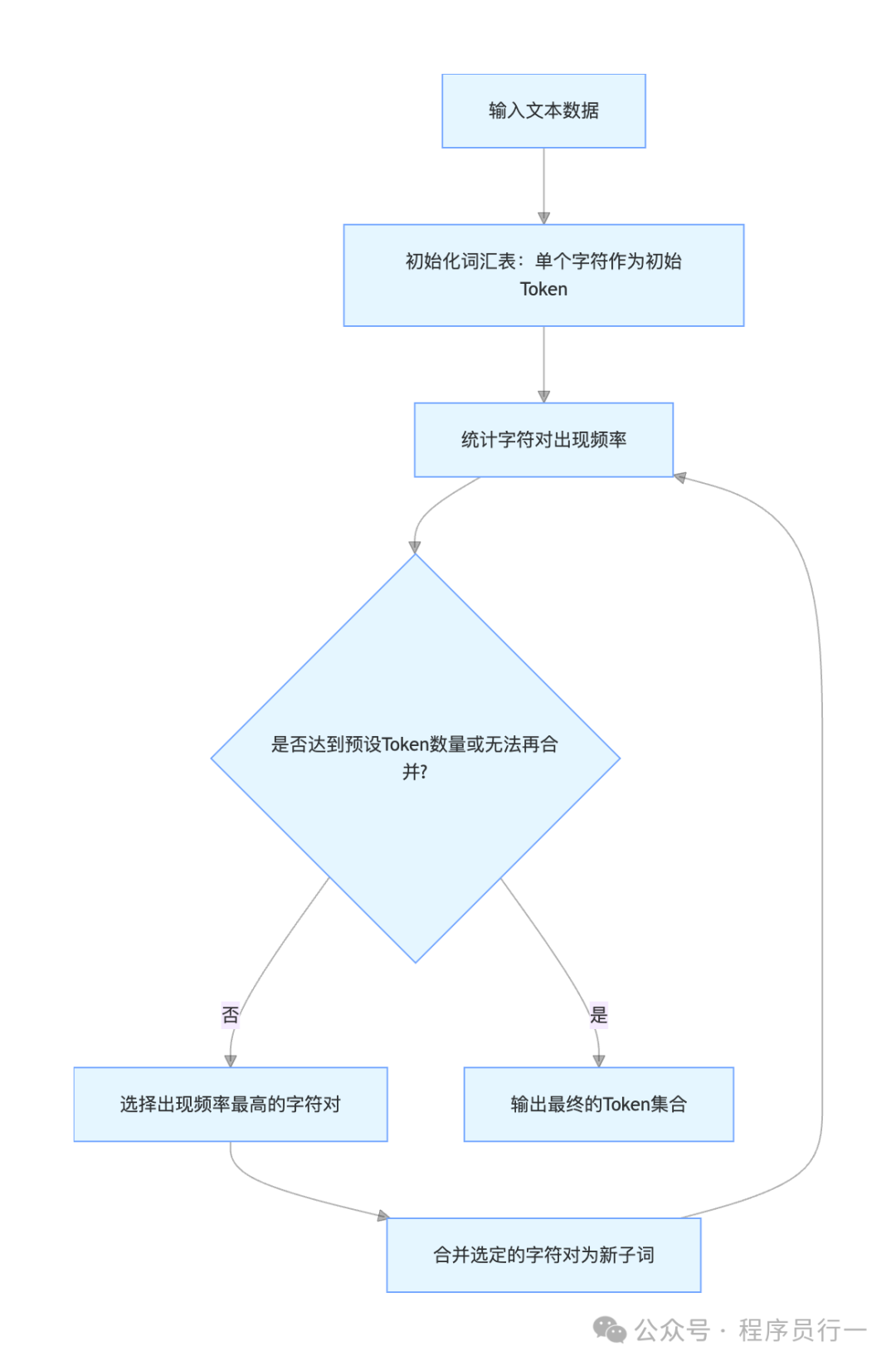
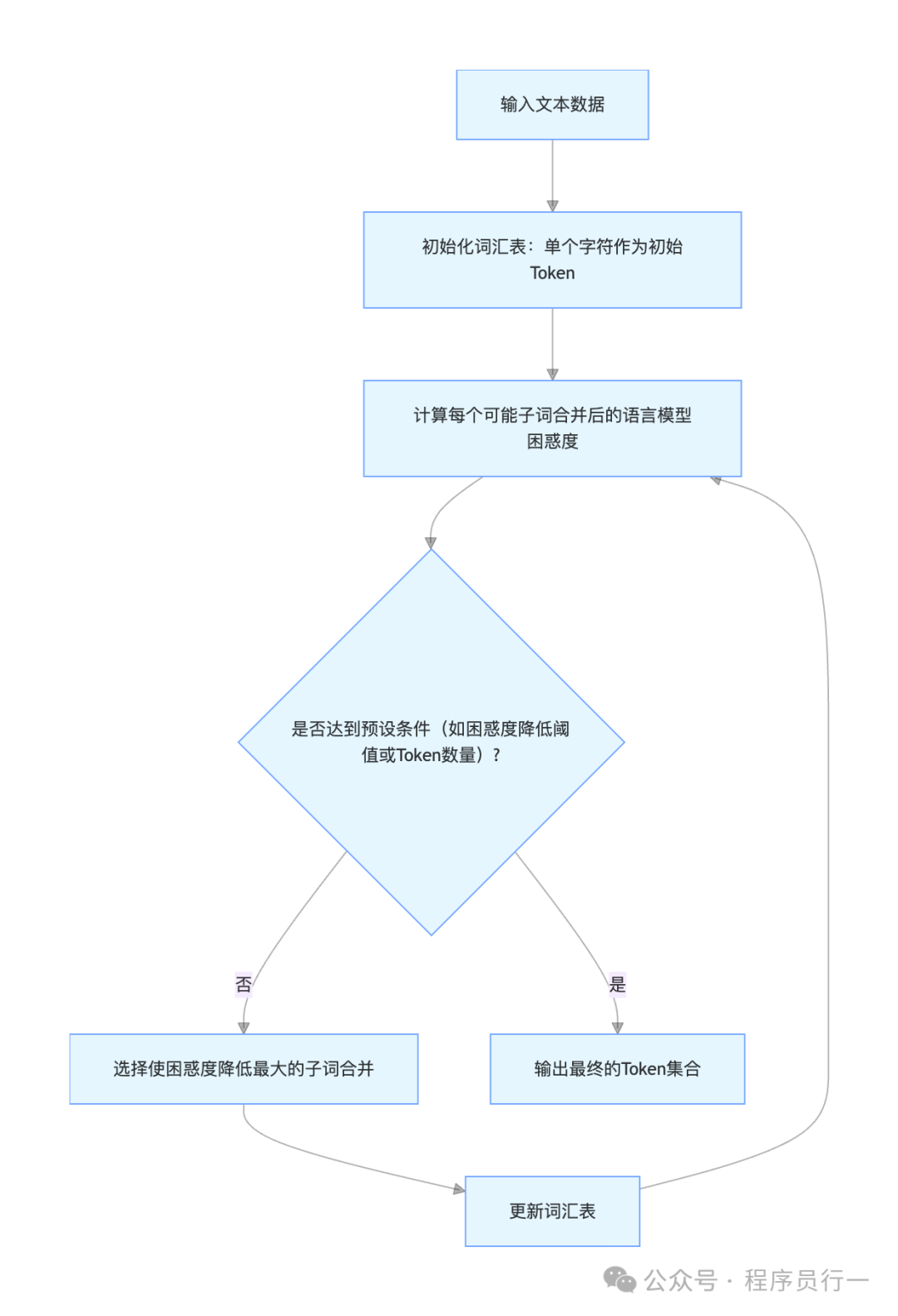
- WordPiece:这是另一种子词算法,被BERT等模型广泛采用。它与BPE类似,但合并子词的标准不是频率,而是看合并后能否最大程度地降低语言模型的困惑度(Perplexity)。例如,“unaffable”可能会被分割为
["un", "##aff", "##able"]。
图像识别中的 Token 计算
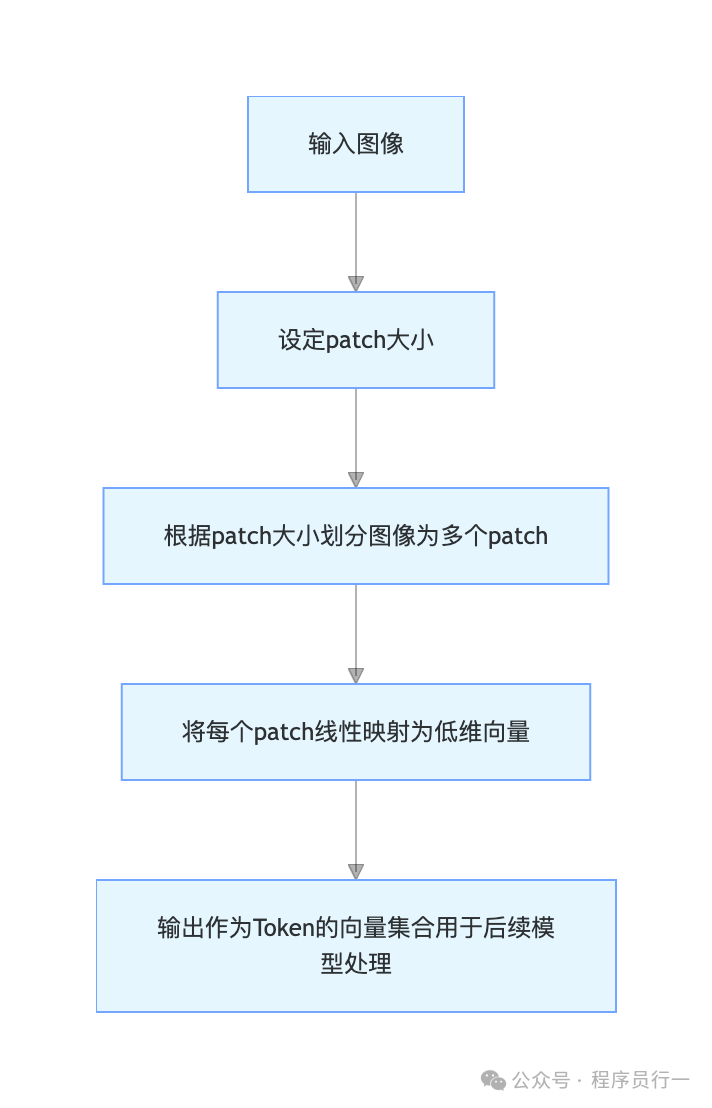
在Vision Transformer等模型中,图像Token化的过程非常直观:
- 输入一张图像(例如224x224像素)。
- 将图像划分为大小固定的方格(Patch),例如16x16像素。
- 这样,一张图就被分成了 (224/16) x (224/16) = 196个图像块(Patch)。
- 每个图像块被展平并通过一个线性投影层,映射成一个低维向量。这个向量,就是模型眼中的“图像Token”。
整体流程是这样的
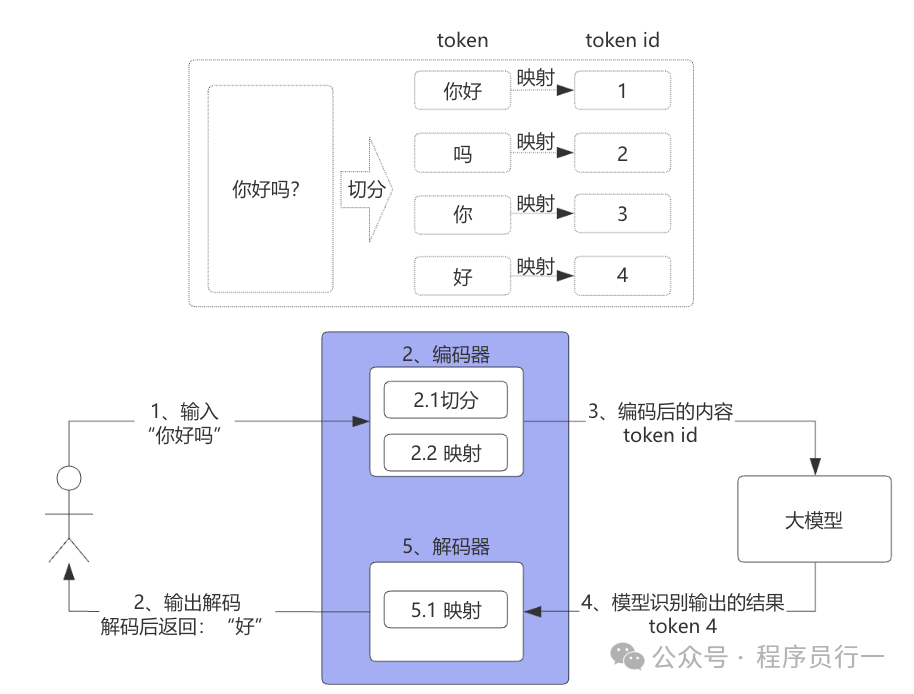
现在,我们把文本和图像的Token化放在一个完整的流程里看,就更容易理解了。模型就像一个只懂“数字语”的天才,Tokenizer(分词器)就是我们的翻译官。
- 输入:你给出“你好吗?”。
- 编码(Tokenizer工作):
- 切分:Tokenizer根据其规则(如BPE)将句子切分成Token序列,例如
[“你好”, “吗”, “?”]。
- 映射:查找内置词表,将每个Token映射为一个唯一的数字ID,例如
[1, 2, 3]。
- 模型推理:大模型接收这些Token ID,在其内部进行复杂的数学计算和概率预测。
- 解码:模型输出一组预测的Token ID(例如
[4])。
- 输出:Tokenizer反向查表,将ID
[4] 映射回Token “好”,并组织成自然语言返回给你:“好”。
所以,模型的核心工作是推理这些Token ID之间的关联和概率,而Tokenizer负责在人类语言和模型“数字语”之间进行双向翻译。当然,实际过程远比这个示意图复杂,但这足以帮助我们建立起对Token工作原理的直观认知。如果你想了解更多关于模型训练和深度学习的底层细节,可以到云栈社区与更多开发者交流探讨。
各 AI 厂商 AI 的 Token 计算方式
OpenAI
- GPT 系列模型:从GPT-3开始,主要采用字节对编码(BPE)进行Token化。这种方法的优势在于能有效平衡词汇表大小和处理未知词汇的能力,使其能够灵活应对多语言和多样化的文本内容。
- CLIP 模型:这是一个多模态模型。对于文本侧,同样使用BPE;对于图像侧,则采用划分Patch作为Token的方式。通过对比学习,模型将图像和文本的Token映射到同一语义空间,从而实现“图文互懂”。
谷歌
- BERT 模型:使用WordPiece算法进行Token化。该方法在构建词汇表时,倾向于合并那些能最大程度提升语言模型概率的子词单元,这使得BERT在理解词汇的语法和语义细微差别方面表现优异。
- ViT(Vision Transformer)模型:是图像领域应用Transformer架构的里程碑。它严格遵循“图像分块”Token化的范式,将图像均匀分割成Patch,线性嵌入后送入Transformer结构进行处理。
百度
- ERNIE 模型:针对中文语言特点,ERNIE的Token化策略更具综合性。它融合了基于词典的分词知识和子词分割技术,既考虑中文词汇的整体性,也对复杂词汇进行智能切分,以增强对中文语义的理解。
- 飞桨图像识别相关模型:在图像Token处理上,同样基于Patch划分的思想,并在此基础上结合自研技术对特征进行优化,以适应分类、检测等多种视觉任务。
总结
Token,这个从网络通信领域走来的概念,如今已成为AI大厦不可或缺的基石。它通过将连续、复杂的世界(文本、图像、语音)离散化为模型可处理的单元,架起了人类信息与机器智能之间的桥梁。从简单的单词拆分,到数据驱动的BPE、WordPiece,再到图像Patch,Token化技术的演进本身也反映了AI从规则驱动到数据驱动的深度学习发展脉络。
现在你明白了,当一款AI模型宣称支持“100万Token上下文”时,它指的不是100万个汉字或英文单词,而是其分词器所能产生的Token单元总数上限。理解这一点,无论是进行技术选型、成本估算还是性能优化,都将让你更加心中有数。 |  发表于 2026-2-8 10:30:01
|
查看: 269|
回复: 0
发表于 2026-2-8 10:30:01
|
查看: 269|
回复: 0
