AI浪潮一波接一波,似乎还没等你摆好姿势,下一个巨浪就已拍在脸上。但作为一名内核工程师,我觉得首先要做到两点:别焦虑,也别随波逐流。
首先要明确,AI的兴起并不意味着内核的工作就结束了。无论有没有AI,内核本身都有一大堆亟待解决的“顽疾”。比如在调度器领域,功耗与性能的终极平衡、调度延迟导致的UI卡顿、优先级翻转,以及用户态锁引发的更深层次调度问题,每一项都值得投入大量精力去深挖。
内存管理的挑战同样艰巨:内存申请的延迟、内存回收的延迟与开销、内存碎片、LRU回收的精准度(如何有效降低refault)、大页内存(large folios)如何稳定发挥效能、文件预读与换入预读的命中率提升、换出与换入的性能优化……这里面的优化空间,可以说是“卷”无止境。特别是在当前内存与存储成本持续攀升的背景下,内核工程师能做的、值得去做的事情,依然非常多。
现在AI来了,相关的学术论文也如雨后春笋般涌现——有用AI优化内核的,有试图让AI自己写调度器的,有做I/O算法优化的,还有用AI自动调节Linux系统参数的。我们可以把这些都笼统地归为“用AI改造kernel”。这些论文漫天飞舞,一个接一个。
这本身不难理解:学术圈需要不断提出新概念、发表论文来驱动研究,并维持其评价体系的运转。但问题在于,我们这些一线的工程师,是否要像无头苍蝇一样,紧跟着每一篇新论文乱转呢?
其实大可不必。Linux内核社区的工程实践有其自身非常稳定且保守的演进规律。总体上,这些论文对主线内核的实际影响相当有限。在我看来,主要原因有两个:
- 写这些论文的研究者,通常并非长期深度参与内核社区开发的一线工程师。
- 内核社区整体秉持一种稳态、保守、工程优先的推进方式——不会因为某篇论文在某个特定负载、某个特定基准测试上取得了提升,就立刻全盘采纳、大规模铺开尝试。
换句话说,论文可以提供思路和启发,但从一个想法到最终被主线内核接纳、影响真实的千万级系统,中间还有非常漫长的工程化与验证路径。可以说,超过99%的相关论文,最终都无法成为mainline的一部分。
前段时间我摘要《Paper摘要:Linux内核调度器的LLM Agent框架》这篇论文时,就有同学留言说这类工作是“KPI工程”。我对这个抱怨不太认同,因为学术圈和工程圈的评价体系、价值导向本就不同。但我非常认同的是,学术圈与内核工程社区之间的Gap确实非常巨大。
举个具体例子,2021年学术界曾诞生一篇颇具影响力的论文:KML: Using Machine Learning to Improve Storage Systems。它提出了一种在内核态进行机器学习推理的框架,旨在优化I/O预读、NFS rsize等存储子系统。
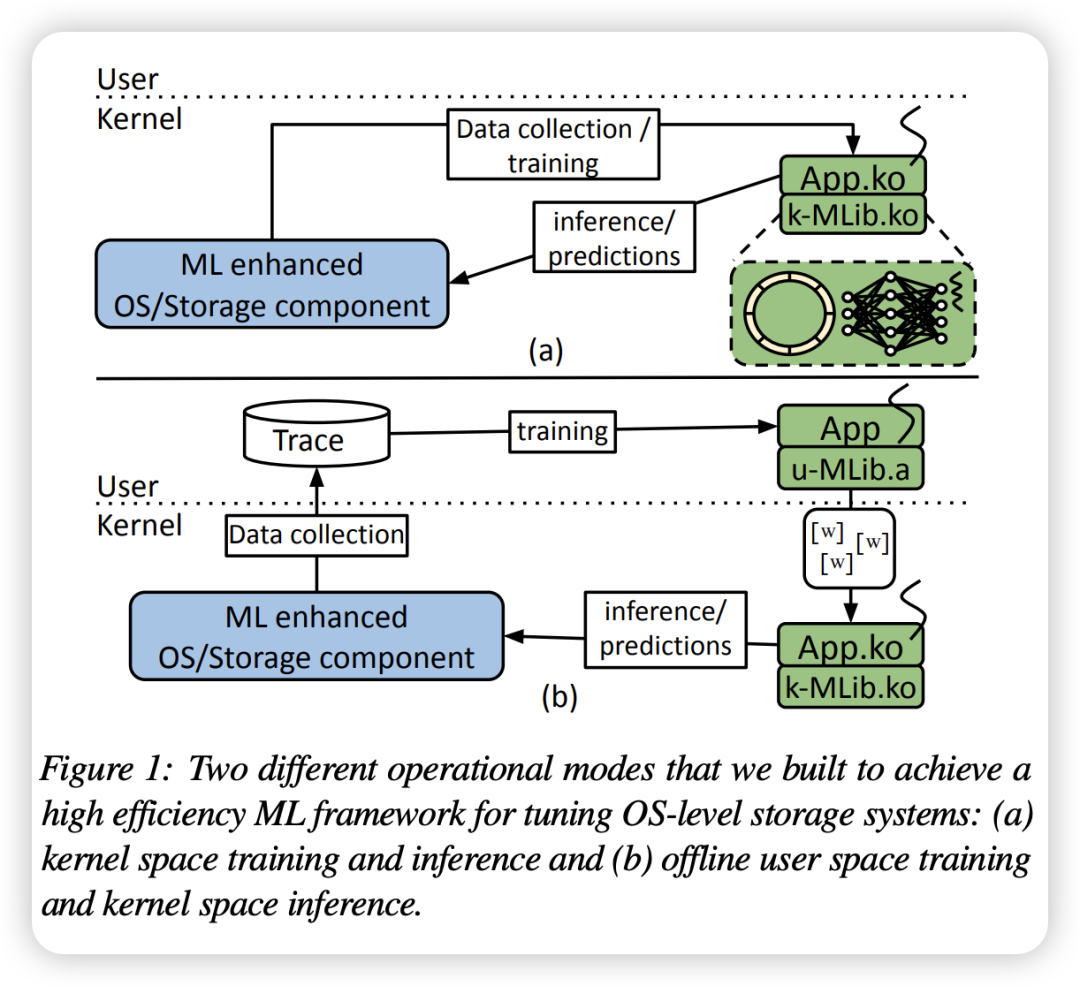
如今五年过去了,它依然是一篇优秀的论文,而非一个被广泛接受的内核工程。一个补丁或框架想要进入主线,通常需要满足:
- 经历长期的补丁评审(patch review)
- 获得对应子系统维护者的接收
- 在社区内达成广泛共识(涵盖性能、安全、可维护性等多方面)
社区共识的建立往往非常困难。例如,社区可能会质疑:为什么不直接优化现有的启发式预读算法,而非要引入机器学习到内核?其实用价值究竟有多大?引入的开销是多少?通用性如何?未来的可维护性又怎样?
所以,什么东西能进入社区、以什么方式进入、难度有多大,作为一名工作多年的内核开发者,我们需要培养这种基本的直觉。不能看到一篇新论文就过度兴奋,毕竟“花繁柳密处拨得开,方见手段”。
我的看法是,如果一个技术方向长远来看都无法进入mainline,那就不要投入过多精力去折腾。因为最终结果很可能是消亡:out-of-tree的代码维护成本本身就能拖垮它,而未来进入mainline的、功能相似的替代品,更会直接宣告其“死亡”。可以说,内核开发者写出的代码,其寿命与其进入mainline的可能性成正比。
但这并不意味着“用AI改造kernel”这个方向本身是错误的。目前这个方向确实产生了一些探索性的成果,例如用AI自适应地调整Linux内核参数,或者研究利用强化学习来提升文件预读、换入预读的准确性等。这些探索是必要的,但也需要强有力的、持久的社区投入,才可能看到未来。
对于内核工程师而言,现阶段或许有一个更紧迫、也更容易产生实际价值的方向,不是“用AI改造kernel”,而是“为AI改造kernel”。
因为大模型要高效运行,必然对系统资源提出前所未有的新需求:CPU、GPU、NPU之间如何更合理地调度与协同;在大模型负载下,如何降低内存占用、减少冗余的内存拷贝;模型加载与数据I/O的路径如何加速——这里面蕴藏着海量的优化机会。
内核工程师完全可以与AI框架及应用侧的工程师紧密协同,在整个端到端的AI应用链路中寻找优化点。上层的应用工程师在卷Agent、卷大模型,我们内核开发者也不能闲着。我们需要与他们“打成一片”,打通上下的技术栈。例如,在Agent/LLM运行时,整条AI流水线上,不同的大模型如何与摄像头、屏幕、GPU、NPU、DMA引擎等多种异构硬件资源高效协同?如何更合理地利用内存带宽,实现零拷贝,优化存储I/O?怎样才能让AI应用跑得更快、同时更省电?这些课题,其实大有可为。
总结一下我的观点:
- 即便不谈AI,内核本身仍有无数基础性问题值得深挖和优化,不能放弃对基本功的持续追求,毕竟“风狂雨骤时立得定,才是脚跟”。
- AI的兴起为内核创造了新机会——打造一个更适合AI负载运行的内核,在这个方向上可以大胆探索和投入。
- 用AI去优化内核内部机制,有机会,但需保持清醒,看准方向再行动,避免盲目跟风。
以上就是我的一些粗浅看法,欢迎在云栈社区与更多开发者交流讨论。
 发表于 2026-2-9 05:31:22
|
查看: 239|
回复: 0
发表于 2026-2-9 05:31:22
|
查看: 239|
回复: 0
